一、考慮的因素(僅代表個人觀點)
1.首先我們看到他的這篇文章所考慮的不同方面從而做出的不同改進,首先考慮到了對于基因組預測的深度學習方法的設計?,我們設計出來這個方法就是為了基因組預測而使用,這也是主要目的,所以要抓住事物的主要方面。
2.DNNGP相比于其他方法的預測準確性的比較,提出一個新方法當然要比其它方法在某些方面表現的要更好,才證明有可行性,比其他方法有改進才可以。
3.這篇文章的創新之處還有就是輸入數據形式的不同,輸入數據的形式支持多種格式,在這當然也要比較不同輸入形式下的預測準確性。
4.通過使用DNNGP在所有的數據集中捕捉到的非線性關系,能夠找到數據集之間更多的關系。
5.樣本量的大小對預測方法的影響,通常來說的話也是樣本集越大預測方法的準確性便越高,樣本集的大小通常來說都是衡量預測方法性能的一個重要評判標準,要注意觀察隨著樣本量的增加是不是準確率越來越高。
6.SNP的數量對預測方法的影響性也是很大的,所以也要考慮不同SNP數量的影響,結合樣本量的大小的話是不是可以同時考慮樣本量的大小和SNP數量的組合,設置不同的組合來分別進行驗證。
7.假如模型準確性的提升帶來的是計算時間的提升,也要考慮兩個因素的共同影響了,如何才能選擇更優化的方案,準確性高的同時不以犧牲其它指標為代價。
當然無論什么樣的方法可能在某個特定的數據集或者某個品種的數據集下的表現比較好,但是換了其它數據集的表現效果就會因數據集而異了,評判一個方法的好壞需要在多個數據集上得到驗證。
二、不同方法比較?
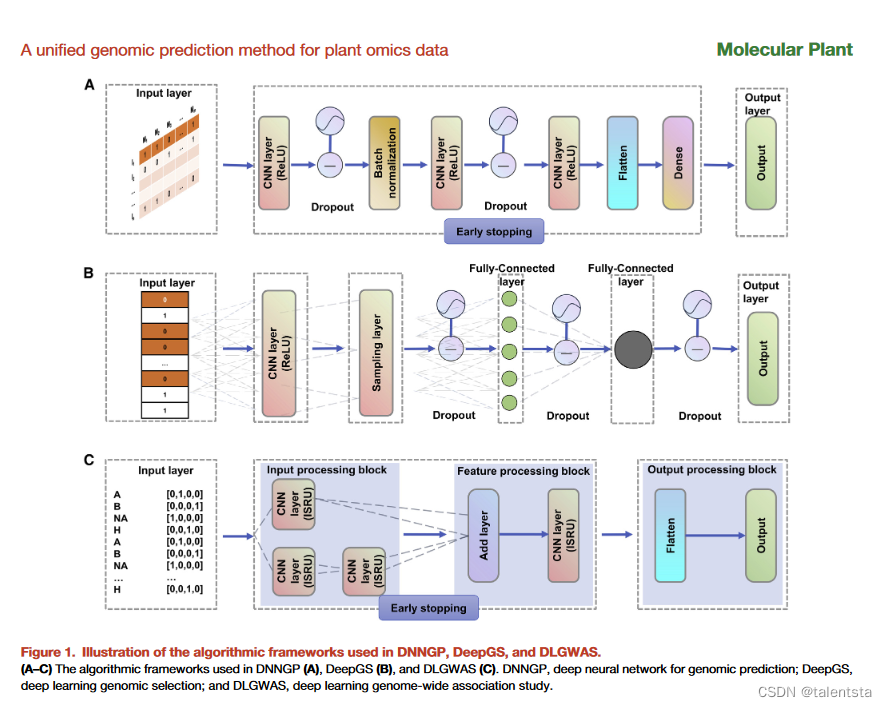
?DNNGP相比DeePGS的亮點是在于多加了 early stopping ,相比于 DLGWAS 的亮點是多加了Batch normalization 結構,根據這個模型是不是可以創造出相對更復雜一些的神經網絡來提升準確率,降維之后的數據是否還能準確反應之前未降維數據的線性關系,考慮進環境和基因組關系后模型表現又如何呢
三、early stopping 結構詳解
early stopping 是一種常用的深度學習regularization技術,可以提前停止神經網絡的訓練,以避免過擬合。它的工作原理是:
1. 劃分出驗證集。一般從訓練數據中劃出一部分作為驗證集。
2. 訓練時同時在訓練集和驗證集上測試模型。
3. 記錄驗證集loss,如果驗證集loss在連續一定Steps(如50)未提升,則停止訓練。
4. 返回最佳模型參數(validation loss最小時的參數)。Early stopping的主要作用是:- 避免模型在訓練集上過擬合,從而提高模型在測試集上的泛化能力。- 提前停止無效的訓練,節省計算資源和時間。- 提取最優模型參數,避免模型退化。
使用Early Stopping的主要注意事項:- 需要設置patience參數,即容忍多少個epoch驗證集loss不下降就停止。- 驗證集大小需要合適,太小難以反映泛化能力,太大影響模型訓練。- 需要保存最佳模型參數。訓練結束后需要加載最佳參數。- 可結合其他正則化方法如L2正則化使用。
總之,Early stopping是深度學習中比較常用并有效的一種正則化技術。
import tensorflow as tf
# 設置early stopping參數
PATIENCE = 20 # 容忍20個epoch視為loss不下降
STOP_DELTA = 0.001 # loss變化小于0.001視為不下降
model = tf.keras.Sequential()
# 構建模型...
# 定義early stopping的回調函數
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_loss', # 監控驗證集losspatience=PATIENCE,min_delta=STOP_DELTA,restore_best_weights=True # 是否將模型恢復到best weights
)model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',metrics=['acc'])history = model.fit(train_data, train_labels, validation_data=(val_data, val_labels),epochs=100, callbacks=[early_stopping])# 加載恢復最優模型參數
model.load_weights(early_stopping.best_weights) # 進行評估和預測1. 設置Early Stopping的參數:- PATIENCE = 20:連續20個epoch驗證集loss不下降,就停止訓練。- STOP_DELTA = 0.001:這個是最小變化程度,如果一個epoch的loss比上個epoch的loss下降了不到0.001,就認為loss沒有下降。- restore_best_weights = True:在停止訓練的時候,是否將模型的參數值恢復到最佳狀態(即驗證集loss最小時的參數)。連續訓練20次后損失函數的值沒有超過下降閾值時便停止訓練,損失之在訓練迭代的時候它的值不是只會下降,也有可能會上升,True就代表返回的值是驗證集 loss 最小時候的值,即代表最佳狀態。
2. 定義回調函數EarlyStopping:- monitor='val_loss':指定要監控驗證集的loss值。- patience=PATIENCE:設置之前定義的PATIENCE值。- min_delta=STOP_DELTA:設置之前定義的最小變化程度。- restore_best_weights=True:恢復最佳參數狀況。
3. 模型訓練:- 通過callbacks參數設置回調函數early_stopping。- 當觸發early stopping條件時,自動停止訓練。
4. 恢復最佳參數:- early_stopping.best_weights儲存了最佳參數值。- 通過model.load_weights()恢復這些最佳參數。這樣就實現了Early Stopping的整個流程,避免模型過擬合,得到最佳參數。
5.compile函數含義
在TensorFlow/Keras中,compile是模型配置和優化的一個過程,主要包括以下作用:1. 指定損失函數:模型將使用何種損失函數來評估當前參數情況下的預測誤差。常見的有mse、binary_crossentropy等。2. 指定優化器:訓練模型時使用的優化算法,如sgd、adam、rmsprop等。優化器負責基于損失函數更新模型參數。3. 指定評估指標:用于監控模型訓練和測試的指標,如accuracy、AUC等。這些指標不會用于訓練,只是進行評估。4. 將損失函數和優化器關聯到模型:將定義的損失函數和優化器“編譯”到模型上,完成模型的配置。5. 編譯計算圖:針對特定的后端(TensorFlow、Theano等)編譯模型的計算圖,為訓練和預測優化計算圖的結構和執行。一個典型的compile示例如下:
model.compile(optimizer='rmsprop',loss='categorical_crossentropy', metrics=['accuracy']
)這里指定了優化器rmsprop、損失函數categorical_crossentropy、評估指標accuracy。綜上,compile對模型進行各種設置,建立模型Optimization的相關計算圖,使模型成為一個可訓練的狀態,這是一個必須的步驟。之后才可以使用model.fit進行訓練。
Early Stopping 主要適用于以下幾種情況:
1. 模型容易過擬合的情況。對于容易在訓練數據上過擬合的模型,使用 Early Stopping 可以避免模型過度復雜化。
2. 需要找到最佳模型的情況。Early Stopping 可以通過保留最佳參數,避免模型在迭代后期發生退化。
3. 計算資源有限的情況。Early Stopping 可以減少不必要的訓練迭代,節省計算時間和資源。
4. 需要調節過擬合和欠擬合的情況。通過設定 Early Stopping 的超參數,可以得到適當的過擬合程度。
隨著迭代次數增加,模型的訓練 loss 和驗證 loss 的變化一般有以下幾種情況:
1. 欠擬合:訓練 loss 和驗證 loss 都在下降,但驗證 loss 下降緩慢或效果不明顯。
2. 過擬合:訓練 loss 持續下降,但驗證 loss 下降緩慢甚至開始上升。
3. 正常:訓練 loss 和驗證 loss 均較快下降,然后變緩。驗證 loss 達到局部最小值時停止迭代。
4. 發散:訓練 loss 和驗證 loss 均再次上升,模型出現問題。Early Stopping 主要用于情況2,避免過擬合。設置合適的 Early Stopping 閾值,可以在情況1、2、3中停止訓練,取得最佳模型。
四、Batch normalization結構詳解
Batch Normalization (批標準化)是深度學習中一個常用的正則化技術。它的主要作用是:
1. 加速訓練過程,模型收斂速度更快。
2. 減少對參數初始化的依賴。
3. 減少過擬合,提高泛化能力。它的工作原理是:在網絡的中間層(通常是卷積層或全連接層)中,對每個batch的數據進行標準化(均值為0,方差為1)。標準化公式如下:x_norm = (x - μ) / (σ+ε)這里 x 是原始數據,μ和σ分別是該batch數據的均值和方差,ε是一個很小的數(防止分母為0)。通過減去batch的均值,然后除以方差,實現標準化。這樣可以減小內部covshift的問題。在測試時,使用整個訓練過程中均值和方差的移動平均值進行標準化。
Batch Normalization的使用注意事項:- 一般只適用于中間層,不要應用在網絡輸出。- 在ReLU之后、激活函數之前使用。- 訓練和測試時的表現可能不太一樣,需要校正。- 可能影響某些優化器的效果。總之,BN通過減小內部covshift,加速訓練過程,對參數初始化和過擬合都有很好的控制效果。是深度學習中非常重要的技術之一。
BN(Batch Normalization)可以減小內部covshift(內部 covariate shift)。covshift指的是在神經網絡的訓練過程中,每一層輸入數據的分布在不斷發生變化。由于每一層的參數會影響后面層的輸入分布,所以會導致后面層的輸入分布隨著訓練的進行而發生變化。這種變化稱為內部covshift。內部covshift會對訓練過程產生負面影響:- 后層需要不斷適應前層分布的變化,造成訓練過程波動和收斂緩慢。- 模型對參數初始化更加敏感。BN的標準化操作可以減小covshift。因為每層輸入進行標準化后,其分布變化會被很大程度抑制,使各層輸入分布相對穩定。這就加快了模型的收斂速度,降低了對參數初始化的依賴。同時也減少了過擬合風險,起到了正則化的作用。總之,減小內部covshift是BN技術的核心作用和數學基礎,這帶來了訓練加速和正則化的雙重收益。
import tensorflow as tf# 創建輸入數據,shape為[batch_size, height, width, channels]
x = tf.placeholder(tf.float32, [None, 32, 32, 3])# 創建BN層
beta = tf.Variable(tf.constant(0.0, shape=[3]))
gamma = tf.Variable(tf.constant(1.0, shape=[3]))
batch_mean, batch_var = tf.nn.moments(x, [0,1,2], keepdims=True)
x_normalized = tf.nn.batch_normalization(x, batch_mean, batch_var, beta, gamma, 0.001)# BN層在訓練和測試中的moving average
ema = tf.train.ExponentialMovingAverage(decay=0.5)
maintain_averages_op = ema.apply([batch_mean, batch_var])with tf.control_dependencies([maintain_averages_op]):training_op = tf.no_op(name='train')mean, variance = ema.average(batch_mean), ema.average(batch_var)
x_normalized_inference = tf.nn.batch_normalization(x, mean, variance, beta, gamma, 0.001)BN層實現的代碼:
1. x 是輸入數據,shape為[batch_size, height, width, channels]。TensorFlow的placeholder,用來定義輸入數據x的形狀和類型。具體來看:1. tf.placeholder: 創建一個占位符tensor,在執行時需要填入實際的tensor。2. tf.float32: 定義placeholder中的數據類型為32位浮點數(float32)。3. [None, 32, 32, 3]: 定義了placeholder的形狀shape,是一個4維tensor。4. None: 第一個維度設置為None,表示batch大小不定,可以是任意正整數。5. 32, 32: 第二和第三個維度固定為32,表示輸入圖像的高度和寬度均為32像素。6. 3: 第四個維度固定為3,表示輸入中的通道數,這里為RGB 3通道圖像。7. 所以整體的shape表示可以輸入batch大小不定的32x32大小的RGB圖像。這樣定義的placeholder x在運行時需要填入實際的輸入tensor,比如一個batch size為128的32x32 RGB圖像,則傳入的tensor應該是[128, 32, 32, 3]的形狀。
這里x表示BN層的輸入數據,它的shape為[batch_size, height, width, channels]:- batch_size:表示一個batch中樣本的數量。- height:輸入圖片的高度。- width:輸入圖片的寬度。- channels:輸入圖片的通道數,例如RGB圖像為3通道。舉個例子,如果輸入是RGB圖像,batch size為128,圖像大小是32x32,那么x的shape就是[128, 32, 32, 3]。其中第一個維度128表示這個batch中有128張圖像,后三個維度表示每張圖像的高、寬和通道數。BN層就是在這種shape的4D輸入數據上進行運算的,先計算這個batch的均值和方差,然后進行標準化。不同batch之間進行標準化使用了移動平均的均值和方差。所以明確輸入x的shape對理解BN的運算對象非常重要。這也是BN層只能在4D張量上進行運算的原因,需要確定樣本、空間和特征維度進行標準化。
2. beta和gamma是可訓練的縮放參數,shape為[channels],分別初始化為0和1。在批標準化(Batch Normalization)層中,beta和gamma是兩個可訓練的參數:- beta: 是一個偏移量,通常初始化為0。shape與特征矩陣的通道維度相同。- gamma:是一個縮放參數,通常初始化為1。shape與特征矩陣的通道維度相同。批標準化的計算公式如下:x_norm = (x - μ) / σ?? # μ和σ為x的均值和方差
out = gamma * x_norm + beta可以看到,beta和gamma分別用來進行偏移和縮放,以便恢復標準化前的數據分布。因此,beta和gamma增加了BN層的表達能力,模型可以學習到適合當前任務的偏移和縮放參數。在BN層實現時,我們需要創建beta和gamma變量,并在訓練過程中更新,以優化模型的效果。
總結一下,beta和gamma是BN層中的可學習參數,起到偏移和縮放的作用,用來校正標準化后的結果,提高模型的適應性。它們和特征維度大小相同,并可以通過反向傳播更新。
3. batch_mean和batch_var計算輸入x在當前batch上的均值和方差。moments函數計算KEEP_DIMS為True的mean和variance。
4. x_normalized利用batch_mean和batch_var對x進行標準化。加上beta和gamma進行縮放。
5. ema對象維護batch_mean和batch_var的移動平均值,decay控制平均的速度。
ema對象在這里是用于維護batch_mean和batch_var的移動平均的。ema代表指數移動平均(Exponential Moving Average),它的計算公式如下:ema_t = decay * ema_{t-1} + (1 - decay) * value_t這里:- ema_t 是時刻t的移動平均值
- ema_{t-1} 是上一時刻的移動平均值
- value_t 是當前時刻的監測值,這里是batch的mean和variance
- decay 是衰減因子,控制平均的速度decay越大,EMA會更多地依賴歷史,變化越緩慢。decay越小,EMA對新的value更敏感。在BN中,訓練時直接使用batch的mean/variance;而測試時使用EMA的mean/variance。這是因為batch mean在訓練時可計算但測試時不可用。EMA可以更平滑地跟蹤訓練過程中的mean/variance變化,用來模擬測試時的mean/variance。所以ema對象在這里的作用就是維護訓練mean/variance的EMA,decay控制EMA的更新速度。這是讓BN層在訓練和測試中獲得一致性的關鍵。
6. maintain_averages_op通過ema.apply更新移動平均值。控制依賴關系確保此操作執行。
7. training_op是一個空操作,但控制依賴關系使moving average得以更新。
8. mean和variance取兩個移動平均值,用于推理時標準化。

?
)











)






