文章目錄
- 1 前言:藍色是天的機器學習筆記專欄
- 1.1 專欄初衷與定位
- 1.2 本文主要內容
- 2 機器學習的定義
- 2.1 機器學習的本質
- 2.2 機器學習的分類
- 3 機器學習的基本術語
- 4 探索"沒有免費的午餐"定理(NFL)
- 5 結語

1 前言:藍色是天的機器學習筆記專欄
尊敬的讀者們,大家好!歡迎來到我的全新專欄:《藍色是天的機器學習筆記》。我感到無比興奮,能夠在這里與各位分享我對機器學習的熱愛與探索。這個專欄將成為我記錄機器學習知識、交流心得的溫馨角落,而這篇文章正是專欄的第一步。
1.1 專欄初衷與定位
作為機器學習領域的狂熱愛好者,我一直堅信知識的分享與傳播是推動技術進步的關鍵。《藍色是天的機器學習筆記》專欄將會是一個持續更新的平臺,我將在這里分享我對機器學習領域的理解、學習過程中的心得體會以及實踐經驗。我希望通過這個專欄,能夠與志同道合的你一起探討機器學習的種種奧秘,共同成長、共同進步。
1.2 本文主要內容
-
機器學習的定義與意義
在機器學習的世界里,計算機不再是被動地執行預設的指令,而是能夠通過數據和經驗來自主學習、優化性能。機器學習已經滲透到我們生活的方方面面,從智能助理到推薦算法,無不展現出其強大的應用潛力。在本文中,我將為大家詳細介紹機器學習的定義及其在現代科技中的重要意義。 -
機器學習的基本術語
在踏入機器學習的領域之前,了解一些基本術語是非常必要的。本文將為大家介紹一些常用的機器學習術語,如監督學習、無監督學習、特征工程等,幫助大家建立起對這些概念的初步認識,為后續的學習打下堅實基礎。 -
探索NFL理論
NFL理論,即“沒有免費的午餐”定理,是機器學習領域的一項重要原則。它告訴我們,并沒有一種算法能夠在所有情況下都表現最優,不同的問題需要不同的方法。在本文中,我將解析這一理論的內涵,并探討其在實際問題中的應用意義。
2 機器學習的定義
在當今信息爆炸的時代,我們每天都在與各種數據打交道。從社交媒體的點贊、購物網站的推薦,到醫療診斷和智能駕駛,我們的世界越來越多地受到數據和技術的影響。但是,如何從這些海量的數據中提取有價值的信息,并做出智能決策,卻是一個充滿挑戰的問題。在這個背景下,機器學習應運而生,為計算機賦予了像人類一樣學習和適應的能力。
2.1 機器學習的本質
機器學習是一門讓計算機從經驗中學習,從而改進性能的學科。它的核心理念可以用一個簡單的類比來理解:就像我們根據過去的經驗來預測明天的天氣,或者在市場上挑選出一個好瓜,機器學習讓計算機能夠從歷史數據中獲取“經驗”,并通過學習這些經驗生成算法模型,從而在面對新的情況時做出有效的判斷。
Mitchell的形式化定義
Tom Mitchell,在他的經典教材《機器學習》中,給出了機器學習的形式化定義,它將這一概念表達得更加準確和具體。他將機器學習看作是一個性能改善的過程,通過歷史數據的學習來提高計算機程序在某個任務類上的性能。形式化定義中,他引入了三個關鍵要素:
- P(性能):表示計算機程序在某個任務類T上的表現。這可以是分類準確率、回歸誤差等,具體取決于任務的性質。
- T(任務類):指計算機程序所要解決的問題類型。這可以是圖像識別、自然語言處理等多種任務。
- E(經驗):代表歷史的數據集,即過去的經驗。這些數據將用于訓練計算機程序,使其在任務T上表現更好。
根據Mitchell的定義,若計算機程序通過學習經驗E,使得在任務T上的性能P得到了改善,那么就可以說該程序對E進行了學習。
2.2 機器學習的分類
機器學習可以分為多個子領域,其中包括但不限于監督學習、無監督學習和強化學習。在監督學習中,計算機從帶有標簽的數據中學習,以便能夠對新數據進行分類或回歸。而在無監督學習中,計算機從未標記的數據中發現模式和結構,用于聚類、降維等任務。強化學習則是讓計算機在與環境互動的過程中,通過試錯來學習最優策略。
3 機器學習的基本術語
在機器學習領域,有許多基本術語用于描述數據、模型以及學習過程,這些術語幫助我們更準確地理解和交流。讓我們一起深入探討這些關鍵概念。
數據的基本組成
當我們希望讓計算機學習的時候,我們首先需要一組數據來作為學習的基礎。以西瓜數據為例,每一個記錄表示一個西瓜的特征信息:
- 數據集:所有記錄的集合稱為數據集,它是我們學習的源數據。
- 實例/樣本:每一條記錄被稱為一個實例或樣本,它是數據集中的一個單獨數據點。
- 特征/屬性:數據集中的每個單獨特點,比如“色澤”或“敲聲”,被稱為特征或屬性。
- 特征向量:一條記錄可以表示為一個特征向量,它是一個在坐標軸上的點,其中每個維度對應一個特征。
訓練與測試
在機器學習中,我們需要使用一部分數據來訓練模型,然后使用另一部分數據來測試模型的性能:
- 訓練樣本:用于訓練模型的數據樣本被稱為訓練樣本,這些樣本有標記信息。
- 訓練集:所有訓練樣本的集合被稱為訓練集,它是用于訓練模型的數據集。
- 測試樣本:用于測試模型性能的數據樣本被稱為測試樣本,這些樣本通常沒有標記信息。
- 測試集:所有測試樣本的集合被稱為測試集,它是用于評估模型性能的數據集。
泛化能力與預測
一個好的機器學習模型應該具有對新數據的適應能力,這就是泛化能力:
- 泛化能力:模型在訓練集上的學習成果能夠應用到未見過的數據上,這就是模型的泛化能力。
問題類型與學習任務
機器學習可以應用于不同類型的問題,這取決于預測值的性質:
- 分類:當預測值是離散值(如好瓜/差瓜)時,這個問題被稱為分類。它可以分為二分類和多分類。
- 回歸:當預測值是連續值(如人口數量)時,這個問題被稱為回歸。
監督學習與無監督學習
根據訓練數據是否有標記信息,我們可以將機器學習任務劃分為兩大類:
- 監督學習:訓練數據帶有標記信息,包括分類和回歸問題。
- 無監督學習:訓練數據沒有標記信息,包括聚類和關聯規則等任務。
4 探索"沒有免費的午餐"定理(NFL)
在機器學習領域,有一條被廣泛引用的定理,它以簡潔的表述揭示了一種普遍的現實:沒有免費的午餐(No Free Lunch, NFL)。這一定理的精髓,不僅在機器學習領域有著深刻的應用,同樣也適用于我們的個人發展之路。請大家閱讀的之前的一篇博文:機器學習中的人生啟示:“沒有免費的午餐”定理(NFL)的個人發展之道
NFL定理(No Free Lunch Theorem)是機器學習領域的一條基本定理,它通過數學推導提供了深刻的見解。該定理的核心思想是,對于所有問題和所有潛在的學習算法,它們在平均情況下的性能是相同的。這意味著,不存在一種算法可以在所有問題上表現最優。
具體地說,假設我們有一個學習算法集合,表示為A = {A1, A2, … , An},這些算法被應用于不同的問題集合D = {D1, D2, … , Dm}。則NFL定理給出了以下結論:
- 對于特定的問題Di,在某個算法Aj表現良好的情況下,必然存在其他問題Dk,其中算法Aj則表現相對較差。
- 對于任何算法的平均性能,它們在所有問題上的性能都是相同的,即在所有問題上的期望性能相等。
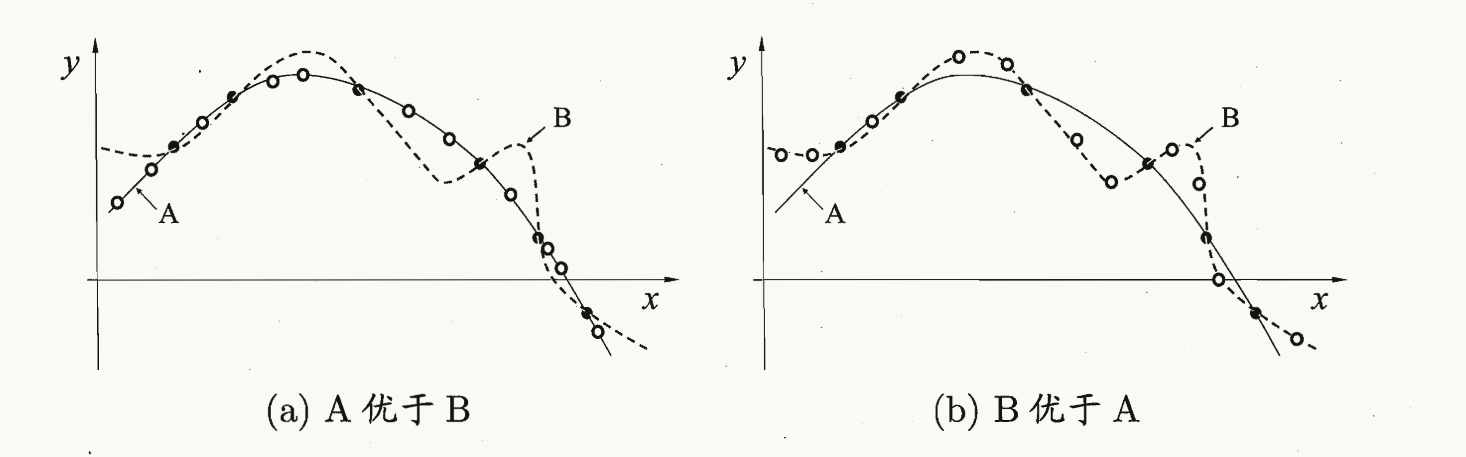
為了更好地理解NFL定理,我們可以通過公式推導進行具體分析。
假設我們有兩個算法,算法a和算法b,它們分別用于假設產生和隨機猜測。考慮一個離散的樣本空間X和假設空間H。我們定義P(h|X,a)為算法a基于訓練數據X產生假設h的概率,并假設我們希望找到一個真實目標函數f。那么,算法a在訓練集之外的誤差可以表示為:

通過公式推導,我們可以清楚地看到NFL定理的數學基礎,并理解其中的含義。它提醒我們,沒有一種算法可以適用于所有問題,因為問題的特征與算法之間存在著固有的聯系。
在個人發展中,我們可以將NFL定理的思想引申到職業選擇和發展上。每個人都有自己獨特的興趣、技能和適應能力,沒有一種職業或領域適用于所有人。我們需要探索自己的優勢并找到適合自己的機會和路徑。
無論是在機器學習還是個人發展中,我們都應該理解和接受NFL定理的啟示,并通過探索多樣的領域來尋找適合自己的機會。這樣,我們才能充分發展自己的潛力,并在個人發展中取得成功。讓我們一起超越NFL定理的界限,開啟個人發展的多彩之旅。
5 結語
在探索機器學習的世界,我們深入研究了"沒有免費的午餐"定理(NFL)的重要性,不僅為機器學習帶來了新的思考,也為個人發展指明了前進的方向。就像每一種算法在不同問題上都有其優勢一樣,每個人在人生舞臺上也都有獨特的閃光點。在機器學習中,我們以數據為驅動,以模型為導航,不斷追求優化與創新;在人生中,我們以努力為動力,以夢想為目標,堅定前行,不斷突破。無論是解決復雜問題還是實現個人價值,堅持不懈的追求和積極的態度都是成功的關鍵。
在這篇博文中,我們深入探討了機器學習的基本術語,剖析了"沒有免費的午餐"定理在機器學習和個人發展中的內涵。無論是在選擇合適的算法,還是在面對個人發展中的差距感,我們都可以從NFL定理中汲取智慧。正如機器學習中每個問題都需要獨特的算法一樣,每個人也都有屬于自己的人生之路。從學習中汲取經驗,不斷成長,逐步邁向成功的道路,正是我們共同的努力方向。
讓我們在機器學習的探索中,勇往直前;在人生的旅程中,秉持NFL定理的智慧,不斷超越自我,創造更加美好的明天。無論是探索科技的邊界還是實現個人的夢想,我們都應該堅信:在知識的指引下,沒有什么是無法實現的。讓我們共同迎接未來的挑戰,為機器學習的發展和人生的進步貢獻力量,書寫屬于自己的精彩篇章。




![[C++] 模板template](http://pic.xiahunao.cn/[C++] 模板template)





)

)







