
今日錦囊
特征錦囊:如何在Python中處理不平衡數據
? Index
1、到底什么是不平衡數據
2、處理不平衡數據的理論方法
3、Python里有什么包可以處理不平衡樣本
4、Python中具體如何處理失衡樣本
印象中很久之前有位朋友說要我寫一篇如何處理不平衡數據的文章,整理相關的理論與實踐知識(可惜本人太懶了,現在才開始寫),于是乎有了今天的文章。失衡樣本在我們真實世界中是十分常見的,那么我們在機器學習(ML)中使用這些失衡樣本數據會出現什么問題呢?如何處理這些失衡樣本呢?以下的內容希望對你有所幫助!
? 到底什么是不平衡數據
失衡數據發生在分類應用場景中,在分類問題中,類別之間的分布不均勻就是失衡的根本,假設有個二分類問題,target為y,那么y的取值范圍為0和1,當其中一方(比如y=1)的占比遠小于另一方(y=0)的時候,就是失衡樣本了。
那么到底是需要差異多少,才算是失衡呢,根本Google Developer的說法,我們一般可以把失衡分為3個程度:
- 輕度:20-40%
- 中度:1-20%
- 極度:<1%
一般來說,失衡樣本在我們構建模型的時候看不出什么問題,而且往往我們還可以得到很高的accuracy,為什么呢?假設我們有一個極度失衡的樣本,y=1的占比為1%,那么,我們訓練的模型,會偏向于把測試集預測為0,這樣子模型整體的預測準確性就會有一個很好看的數字,如果我們只是關注這個指標的話,可能就會被騙了。
? 處理不平衡數據的理論方法
在我們開始用Python處理失衡樣本之前,我們先來了解一波關于處理失衡樣本的一些理論知識,前輩們關于這類問題的解決方案,主要包括以下:
- 從數據角度:通過應用一些欠采樣or過采樣技術來處理失衡樣本。欠采樣就是對多數類進行抽樣,保留少數類的全量,使得兩類的數量相當,過采樣就是對少數類進行多次重復采樣,保留多數類的全量,使得兩類的數量相當。但是,這類做法也有弊端,欠采樣會導致我們丟失一部分的信息,可能包含了一些重要的信息,過采樣則會導致分類器容易過擬合。當然,也可以是兩種技術的相互結合。
- 從算法角度:算法角度的解決方案就是可以通過對每類的訓練實例給予一定權值的調整。比如像在SVM這樣子的有參分類器中,可以應用grid search(網格搜索)以及交叉驗證(cross validation)來優化C以及gamma值。而對于決策樹這類的非參數模型,可以通過調整樹葉節點上的概率估計從而實現效果優化。
此外,也有研究員從數據以及算法的結合角度來看待這類問題,提出了兩者結合體的AdaOUBoost(adaptive over-sampling and undersampling boost)算法,這個算法的新穎之處在于自適應地對少數類樣本進行過采樣,然后對多數類樣本進行欠采樣,以形成不同的分類器,并根據其準確度將這些子分類器組合在一起從而形成強大的分類器,更多的請參考:
AdaOUBoost:https://dl.acm.org/doi/10.1145/1743384.1743408
? Python里有什么包可以處理不平衡樣本
這里介紹一個很不錯的包,叫 imbalanced-learn,大家可以在電腦上安裝一下使用。
官方文檔:https://imbalanced-learn.readthedocs.io/en/stable/index.html
pip?install?-U?imbalanced-learn
使用上面的包,我們就可以實現樣本的欠采樣、過采樣,并且可以利用pipeline的方式來實現兩者的結合,十分方便,我們下一節來簡單使用一下吧!
? Python中具體如何處理失衡樣本
為了更好滴理解,我們引入一個數據集,來自于UCI機器學習存儲庫的營銷活動數據集。(數據集大家可以自己去官網下載:https://archive.ics.uci.edu/ml/machine-learning-databases/00222/ ?下載bank-additional.zip 或者到公眾號后臺回復關鍵字“bank”來獲取吧。)
我們在完成imblearn庫的安裝之后,就可以開始簡單的操作了(其余更加復雜的操作可以直接看官方文檔),以下我會從4方面來演示如何用Python處理失衡樣本,分別是:
? 1、隨機欠采樣的實現
? 2、使用SMOTE進行過采樣
? 3、欠采樣和過采樣的結合(使用pipeline)
? 4、如何獲取最佳的采樣率?
??? 那我們開始吧!
#?導入相關的庫(主要就是imblearn庫)
from?collections?import?Counter
from?sklearn.model_selection?import?train_test_split
from?sklearn.model_selection?import?cross_val_score
import?pandas?as?pd
import?numpy?as?np
import?warnings
warnings.simplefilter(action='ignore',?category=FutureWarning)
from?sklearn.svm?import?SVC
from?sklearn.metrics?import?classification_report,?roc_auc_score
from?numpy?import?mean
#?導入數據
df?=?pd.read_csv(r'./data/bank-additional/bank-additional-full.csv',?';')?#?'';''?為分隔符
df.head()
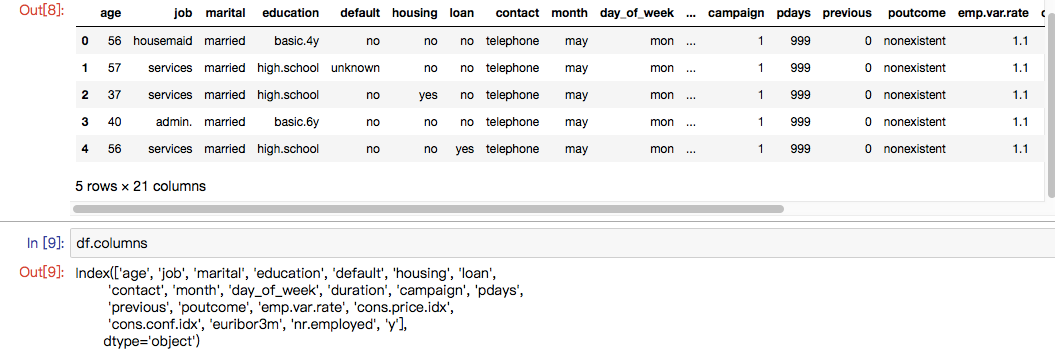
數據集是葡萄牙銀行的某次營銷活動的數據,其營銷目標就是讓客戶訂閱他們的產品,然后他們通過與客戶的電話溝通以及其他渠道獲取到的客戶信息,組成了這個數據集。
關于字段釋義,可以看下面的截圖:

我們可以大致看看數據集是不是失衡樣本:
df['y'].value_counts()/len(df)
#no?????0.887346
#yes????0.112654
#Name:?y,?dtype:?float64
可以看出少數類的占比為11.2%,屬于中度失衡樣本。
#?只保留數值型變量(簡單操作)
df?=?df.loc[:,
['age',?'duration',?'campaign',?'pdays',
???????'previous',?'emp.var.rate',?'cons.price.idx',
???????'cons.conf.idx',?'euribor3m',?'nr.employed','y']]
#?target由?yes/no?轉為?0/1
df['y']?=?df['y'].apply(lambda?x:?1?if?x=='yes'?else?0)
df['y'].value_counts()
#0????36548
#1?????4640
#Name:?y,?dtype:?int64
? 1、隨機欠采樣的實現
欠采樣在imblearn庫中也是有方法可以用的,那就是 under_sampling.RandomUnderSampler,我們可以使用把方法引入,然后調用它。可見,原先0的樣本有21942,欠采樣之后就變成了與1一樣的數量了(即2770),實現了50%/50%的類別分布。
#?1、隨機欠采樣的實現
#?導入相關的方法
from?imblearn.under_sampling?import?RandomUnderSampler
#?劃分因變量和自變量
X?=?df.iloc[:,:-1]
y?=?df.iloc[:,-1]
#?劃分訓練集和測試集
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,y,test_size=0.40)
#?統計當前的類別占比情況
print("Before?undersampling:?",?Counter(y_train))
#?調用方法進行欠采樣
undersample?=?RandomUnderSampler(sampling_strategy='majority')
#?獲得欠采樣后的樣本
X_train_under,?y_train_under?=?undersample.fit_resample(X_train,?y_train)
#?統計欠采樣后的類別占比情況
print("After?undersampling:?",?Counter(y_train_under))
#?調用支持向量機算法?SVC
model=SVC()
clf?=?model.fit(X_train,?y_train)
pred?=?clf.predict(X_test)
print("ROC?AUC?score?for?original?data:?",?roc_auc_score(y_test,?pred))
clf_under?=?model.fit(X_train_under,?y_train_under)
pred_under?=?clf_under.predict(X_test)
print("ROC?AUC?score?for?undersampled?data:?",?roc_auc_score(y_test,?pred_under))
# Output:
#Before?undersampling:??Counter({0:?21942,?1:?2770})
#After?undersampling:??Counter({0:?2770,?1:?2770})
#ROC?AUC?score?for?original?data:??0.603521152028
#ROC?AUC?score?for?undersampled?data:??0.829234085179
? 2、使用SMOTE進行過采樣
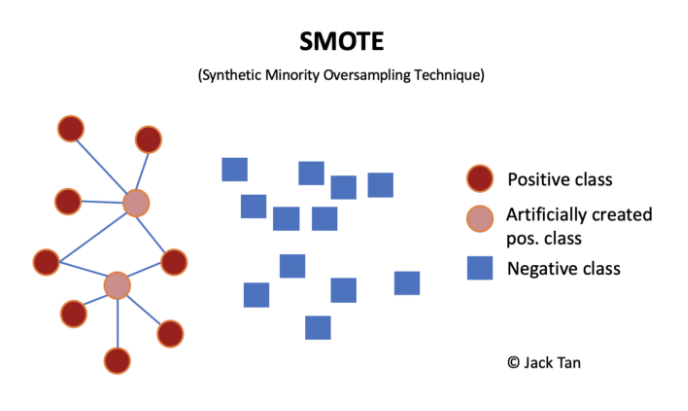
過采樣技術中,SMOTE被認為是最為流行的數據采樣算法之一,它是基于隨機過采樣算法的一種改良版本,由于隨機過采樣只是采取了簡單復制樣本的策略來進行樣本的擴增,這樣子會導致一個比較直接的問題就是過擬合。因此,SMOTE的基本思想就是對少數類樣本進行分析并合成新樣本添加到數據集中。
算法流程如下:
(1)對于少數類中每一個樣本x,以歐氏距離為標準計算它到少數類樣本集中所有樣本的距離,得到其k近鄰。
(2)根據樣本不平衡比例設置一個采樣比例以確定采樣倍率N,對于每一個少數類樣本x,從其k近鄰中隨機選擇若干個樣本,假設選擇的近鄰為xn。
(3)對于每一個隨機選出的近鄰xn,分別與原樣本按照如下的公式構建新的樣本。
#?2、使用SMOTE進行過采樣
#?導入相關的方法
from?imblearn.over_sampling?import?SMOTE
#?劃分因變量和自變量
X?=?df.iloc[:,:-1]
y?=?df.iloc[:,-1]
#?劃分訓練集和測試集
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,y,test_size=0.40)
#?統計當前的類別占比情況
print("Before?oversampling:?",?Counter(y_train))
#?調用方法進行過采樣
SMOTE?=?SMOTE()
#?獲得過采樣后的樣本
X_train_SMOTE,?y_train_SMOTE?=?SMOTE.fit_resample(X_train,?y_train)
#?統計過采樣后的類別占比情況
print("After?oversampling:?",Counter(y_train_SMOTE))
#?調用支持向量機算法?SVC
model=SVC()
clf?=?model.fit(X_train,?y_train)
pred?=?clf.predict(X_test)
print("ROC?AUC?score?for?original?data:?",?roc_auc_score(y_test,?pred))
clf_SMOTE=?model.fit(X_train_SMOTE,?y_train_SMOTE)
pred_SMOTE?=?clf_SMOTE.predict(X_test)
print("ROC?AUC?score?for?oversampling?data:?",?roc_auc_score(y_test,?pred_SMOTE))
# Output:
#Before?oversampling:??Counter({0:?21980,?1:?2732})
#After?oversampling:??Counter({0:?21980,?1:?21980})
#ROC?AUC?score?for?original?data:??0.602555700614
#ROC?AUC?score?for?oversampling?data:??0.844305732561
? 3、欠采樣和過采樣的結合(使用pipeline)
那如果我們需要同時使用過采樣以及欠采樣,那該怎么做呢?其實很簡單,就是使用 pipeline來實現。
#??3、欠采樣和過采樣的結合(使用pipeline)
#?導入相關的方法
from?imblearn.over_sampling?import?SMOTE
from?imblearn.under_sampling?import?RandomUnderSampler
from?imblearn.pipeline?import?Pipeline
#?劃分因變量和自變量
X?=?df.iloc[:,:-1]
y?=?df.iloc[:,-1]
#??定義管道
model?=?SVC()
over?=?SMOTE(sampling_strategy=0.4)
under?=?RandomUnderSampler(sampling_strategy=0.5)
steps?=?[('o',?over),?('u',?under),?('model',?model)]
pipeline?=?Pipeline(steps=steps)
#?評估效果
scores?=?cross_val_score(pipeline,?X,?y,?scoring='roc_auc',?cv=5,?n_jobs=-1)
score?=?mean(scores)
print('ROC?AUC?score?for?the?combined?sampling?method:?%.3f'?%?score)
# Output:
#ROC?AUC?score?for?the?combined?sampling?method:?0.937
? 4、如何獲取最佳的采樣率?
在上面的栗子中,我們都是默認經過采樣變成50:50,但是這樣子的采樣比例并非最優選擇,因此我們引入一個叫 最佳采樣率的概念,然后我們通過設置采樣的比例,采樣網格搜索的方法去找到這個最優點。
# 4、如何獲取最佳的采樣率?
#?導入相關的方法
from?imblearn.over_sampling?import?SMOTE
from?imblearn.under_sampling?import?RandomUnderSampler
from?imblearn.pipeline?import?Pipeline
#?劃分因變量和自變量
X?=?df.iloc[:,:-1]
y?=?df.iloc[:,-1]
#?values?to?evaluate
over_values?=?[0.3,0.4,0.5]
under_values?=?[0.7,0.6,0.5]
for?o?in?over_values:
??for?u?in?under_values:
????#?define?pipeline
????model?=?SVC()
????over?=?SMOTE(sampling_strategy=o)
????under?=?RandomUnderSampler(sampling_strategy=u)
????steps?=?[('over',?over),?('under',?under),?('model',?model)]
????pipeline?=?Pipeline(steps=steps)
????#?evaluate?pipeline
????scores?=?cross_val_score(pipeline,?X,?y,?scoring='roc_auc',?cv=5,?n_jobs=-1)
????score?=?mean(scores)
????print('SMOTE?oversampling?rate:%.1f,?Random?undersampling?rate:%.1f?,?Mean?ROC?AUC:?%.3f'?%?(o,?u,?score))
????
# Output:????
#SMOTE?oversampling?rate:0.3,?Random?undersampling?rate:0.7?,?Mean?ROC?AUC:?0.938
#SMOTE?oversampling?rate:0.3,?Random?undersampling?rate:0.6?,?Mean?ROC?AUC:?0.936
#SMOTE?oversampling?rate:0.3,?Random?undersampling?rate:0.5?,?Mean?ROC?AUC:?0.937
#SMOTE?oversampling?rate:0.4,?Random?undersampling?rate:0.7?,?Mean?ROC?AUC:?0.938
#SMOTE?oversampling?rate:0.4,?Random?undersampling?rate:0.6?,?Mean?ROC?AUC:?0.937
#SMOTE?oversampling?rate:0.4,?Random?undersampling?rate:0.5?,?Mean?ROC?AUC:?0.938
#SMOTE?oversampling?rate:0.5,?Random?undersampling?rate:0.7?,?Mean?ROC?AUC:?0.939
#SMOTE?oversampling?rate:0.5,?Random?undersampling?rate:0.6?,?Mean?ROC?AUC:?0.938
#SMOTE?oversampling?rate:0.5,?Random?undersampling?rate:0.5?,?Mean?ROC?AUC:?0.938
從結果日志來看,最優的采樣率就是過采樣0.5,欠采樣0.7。
最后,想和大家說的是沒有絕對的套路,只有合適的套路,無論是欠采樣還是過采樣,只有合適才最重要。還有,欠采樣的確會比過采樣“省錢”哈(從訓練時間上很直觀可以感受到)。
? References
[1] SMOTE算法 https://www.jianshu.com/p/13fc0f7f5565
[2] How to deal with imbalanced data in Python
往 期 錦 囊
特征錦囊:特征無量綱化的常見操作方法
特征錦囊:怎么進行多項式or對數的數據變換?
特征錦囊:常用的統計圖在Python里怎么畫?
特征錦囊:怎么去除DataFrame里的缺失值?
特征錦囊:怎么把被錯誤填充的缺失值還原?
特征錦囊:怎么定義一個方法去填充分類變量的空值?
特征錦囊:怎么定義一個方法去填充數值變量的空值?
特征錦囊:怎么把幾個圖表一起在同一張圖上顯示?
特征錦囊:怎么把畫出堆積圖來看占比關系?
特征錦囊:怎么對滿足某種條件的變量修改其變量值?
特征錦囊:怎么通過正則提取字符串里的指定內容?
特征錦囊:如何利用字典批量修改變量值?
特征錦囊:如何對類別變量進行獨熱編碼?
特征錦囊:如何把“年齡”字段按照我們的閾值分段?
特征錦囊:如何使用sklearn的多項式來衍生更多的變量?
特征錦囊:如何根據變量相關性畫出熱力圖?
特征錦囊:如何把分布修正為類正態分布?
特征錦囊:怎么找出數據集中有數據傾斜的特征?
特征錦囊:怎么盡可能地修正數據傾斜的特征?
特征錦囊:怎么簡單使用PCA來劃分數據且可視化呢?
特征錦囊:怎么簡單使用LDA來劃分數據且可視化呢?
特征錦囊:怎么來管理我們的建模項目文件?
特征錦囊:怎么批量把特征中的離群點給“安排一下”?特征錦囊:徹底了解一下WOE和IV特征錦囊:一文介紹特征工程里的卡方分箱,附代碼實現特征錦囊:今天一起搞懂機器學習里的L1與L2正則化
特征錦囊:金融風控里的WOE前的分箱一定要單調嗎?
?? GitHub傳送門?
https://github.com/Pysamlam/Tips-of-Feature-engineering

原創不易,如果覺得這種學習方式有用,希望可以幫忙隨手轉發or點下“在看”,這是對我的極大鼓勵!阿里嘎多!?

算法)




函數)





- 背景圖設置)






卡方檢驗(python))