本系列文章將圍繞東南亞頭部科技集團的真實遷移歷程展開,逐步拆解 BigQuery 遷移至 MaxCompute 過程中的關鍵挑戰與技術創新。本篇為第二篇,跨國數倉遷移背后 MaxCompute 的統一存儲格式創新。
注:客戶背景為東南亞頭部科技集團,文中用 GoTerra 表示。
業務背景和痛點
隨著大數據與AI時代的快速發展,全球數據總量已經突破了百ZB量級,其中半結構化(Json等)和嵌套數據結構(PB等)占比超50%,傳統技術處理此類數據,面臨存儲成本高,計算效率低等問題日益凸顯,亟需高效的性能優化技術。當前主流大數據處理引擎框架普通采用復雜數據類型(struct、map、array)來靈活處理半結構化等數據,相關功能支持和處理性能成為現代數據架構技術競爭焦點。
Google BigQuery和阿里云MaxCompute作為全球領先的商業化數據處理平臺,均歷經十余年產品和技術迭代。其中MaxCompute日均處理EB級數據和數千萬作業,服務覆蓋了全球多行業客戶,因此也一直在持續豐富復雜類型的功能完備和性能優化。在?GOTO項目從BigQuery遷移至MaxCompute?的過程中,?復雜數據類型的處理能力對標?成為關鍵任務,需確保功能和性能?持平甚至超越?BigQuery,以實現作業平滑遷移與資源成本優化。
技術現狀
簡單介紹三種典型復雜數據類型特征和使用場景:
- Array類型: 一組同類型元素的集合(如array<bigint>),支持下標索引訪問元素,廣泛應用于存儲和處理列表形式的數據,例如商品列表,多值屬性等
- Map類型:鍵值對集合(如map<bigint, string>),支持通過鍵直接訪問值,典型場景包括動態屬性、鍵值配置等
- Struct類型: 包含多個字段的復合類型(如struct<id:bigint, value:string>),每個字段具有獨立名稱和類型,支持通過字段名訪問元素,常用于用戶畫像標簽、訂單信息等
MaxCompute支持復雜類型的現有能力和瓶頸:
- 存儲層:支持復雜類型列式存儲(Aliorc文件格式),顯著降低存儲成本,具體用法參考官網介紹。
- 計算層: 支持行式復雜類型數據處理。盡管功能完備,但性能仍有較大優化空間。
由此可見,一條復雜類型數據處理,需經歷列式讀取,換轉成行式計算,再轉換成列式寫入,多次轉換開銷巨大,并且大部分算子行式處理數據性能也較差,導致部分場景性能相比BigQuery存在一定的差距。
為徹底解決優化這些痛點,MaxCompute SQL執行引擎對復雜類型處理進行了全面重構,整體支持復雜類型列式的內存存儲結構,對各個算子進行深度適配優化,整體處理性能實現質的飛躍,部分場景提升超10倍,基本追平Bigquery對復雜類型的計算處理性能,且在某些場景實現性能超越,最終保障了GOTO項目海量作業的平滑遷移,同時大幅節省計算資源。
技術方案簡述
這里主要介紹兩個核心優化重構,一個是復雜數據類型的計算優化重構,另一個是Unnest with subquery的框架優化重構,這兩項優化在復雜類型場景普遍都帶來1-10倍以上的性能提升。
列式復雜數據類型的計算優化重構
優化分成兩個階段:
- 各算子基于當前行式復雜類型結構持續優化計算邏輯,減少不必要的拷貝和計算。
- 將行式結果徹底改造成列式結構,并適配各算子列式計算模式。
行式復雜類型淺拷貝優化
現有算子接收到行式復雜類型的輸入數據,進行計算后輸出,需全量數據深拷貝,對于數據量大的復雜類型,開銷極高。因此數據結構和處理過程進行深入優化,支持絕大部份處理流程進行淺拷貝優化,只要數據不發生變更,只需拷貝數據引用即可,不涉及數據本身的拷貝,優化覆蓋表達式/聚合/Join/Window等主要算子,部分場景提升高達100倍+,效果顯著。
復雜類型列式內存結構和計算優化重構
雖然行式優化取得了不少進展,但部分痛點依然存在,比如計算過程效率低下,無法高效適配向量化計算;計算過程中子元素列裁剪無法生效;每行數據的內存結構復雜,且需存儲重復的輔助結構,嚴重制約整體計算性能。
為了顯著提升性能,徹底改造復雜類型內存存儲和計算框架,由行式轉為列式內存結構,推動各個算子采用高效的列式計算思想適配優化,整體性能得到質的飛躍,部分場景提速超10倍。
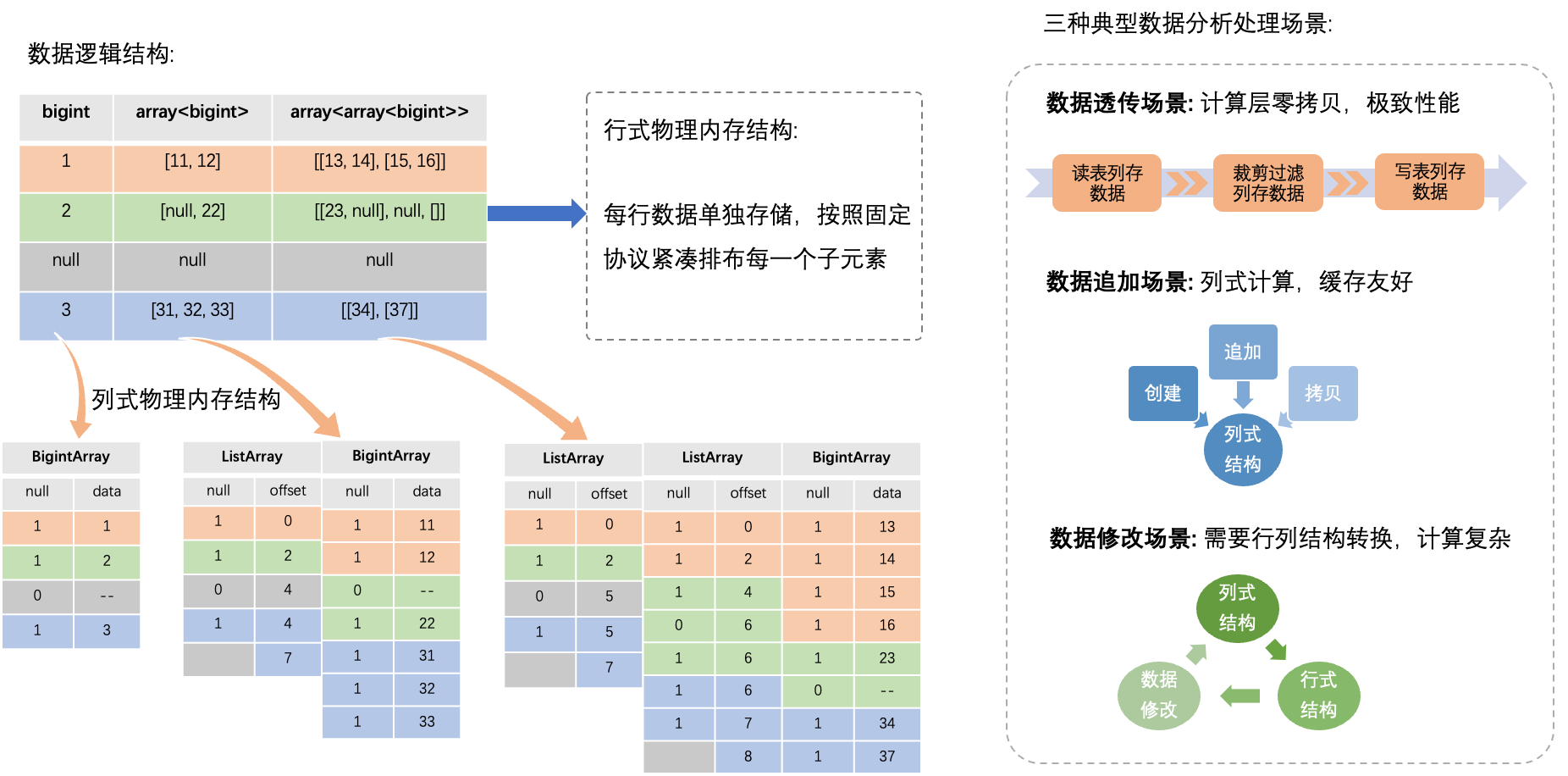
列式內存結構重構
如上圖所示,重構之后,每行復雜類型數據不再單獨存儲,而且采用類arrow結構,對于Batch(多行數據集合)中某一列復雜類型,相同位置的子元素連續內存存儲,因此每個Batch僅需存儲一份輔助結構(如列名等),有效節省內存空間,而且子元素數據連續存儲,內存訪問效率也顯著提升。
算子適配列式復雜類型計算
列式結果改造完成后,各SQL算子需進一步適配優化,由于行式和列式計算方式差異顯著,此部分優化近乎完全重構,并針對不同場景進行了精細化適配。
列式復雜類型計算模式可分為以下三類:
- 數據透傳模式: 數據從源表列式讀取后,中間處理無變更,全程零拷貝傳輸,最后直接列式寫入目標表,性能優化到極致。常見于數據搬遷,簡單列裁剪數據清洗等場景。
- 數據追加模式: 算子一次性處理復雜類型數據后順序輸出到列式結構中,不會再次修改,可有效利用內存緩存優化和向量化處理提升整體性能。常見于表達式/Window/Join等主要算子。
- 數據修改模式: 算子需多次隨機修改復雜類型數據,此模式不太適合列式內存結構,其存儲的多行數據內存是連續的,如果隨機修改中間某一行數據,可能破壞后繼其他行數據的內存結構,因此此場景需退化成行式處理。常見于聚合函數處理等少數算子。
Unnest with subquery 的框架優化重構
BigQuery的Unnest(array)操作極為常見,輸入參數通常是一個Array復雜類型,負責把Array中每一個子元素展開為一個單獨行進行輸出,GOTO項目大量任務使用此操作,遷移到MaxCompute之后,由于缺乏原生支持,需自動轉換成等效的Lateral View + Explode操作來執行。但當Unnest嵌套于SQL子查詢等較為復雜用法時,MaxCompute處理會變得極其復雜,性能急劇下降。
下面舉個例子:
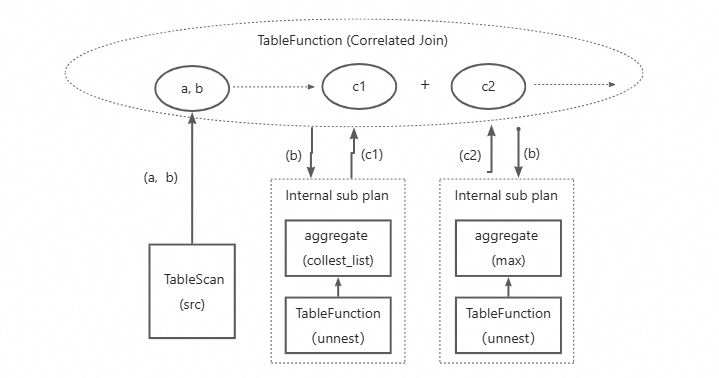
create table src(a bigint, b array<struct<c:bigint, d:string>>);select(select max(c) from unnest(b)),a+100,(select collest_list(d) from unnest(b) where d='test')
from src; 上述SQL示例中,MaxCompute執行時會轉換成如下Plan來執行(示意圖):

可見此Plan主要存在如下問題:
- 同一源表多次讀取
- 相同unnest操作重復執行
- 需多次復雜Join拼接數據
因此如需大幅提升性能,需在語法解析,Plan構建,算子計算等各流程對此場景完全重構優化。
SQL Plan優化
為了優化上述三個問題,重構優化后的Plan如下圖所示(示意圖),
- 僅讀取一次源表,按需把讀取數據列推送至各Subquery計算
- 定義新的CorrelatedJoin操作,負責把每個Subquery定義成一個單獨的internal subplan,然后按行對齊和拼接每個Subquery的計算輸出列,整行輸出,消除計算量很重的多次Join操作
- 定義新的internal subplan結構,本質是一棵OperatorTree, 并做針對性的Plan優化改造,如消除shuffle操作
- 對于多個subquery中相同Unnest操作,支持子樹合并,消除冗余的unnest操作(在優化中)。
經過上述優化后,基本可解決之前的性能痛點,貼近性能最佳的計算Plan,后續還需要SQL執行層進行計算適配。
SQL執行層優化
主要負責執行物理Plan,并發處理數據,輸出結果,優化重構主要分以下幾步:
- 適配優化后的新物理Plan,解析為可執行算子
- 實現新CorrelatedJoin算子,負責驅動internal subplan執行,并且把各subplan執行的結果按行對齊和高效拼接,然后輸出整行結果到后續算子執行
- 實現新的internal subplan數據處理框架,需支持按照每行復雜類型進行一次性處理和輸出的語義,跟通用算子執行框架差異顯著。
上線效果和業務價值
提升效果案例
列式復雜類型重構優化性能提升案例
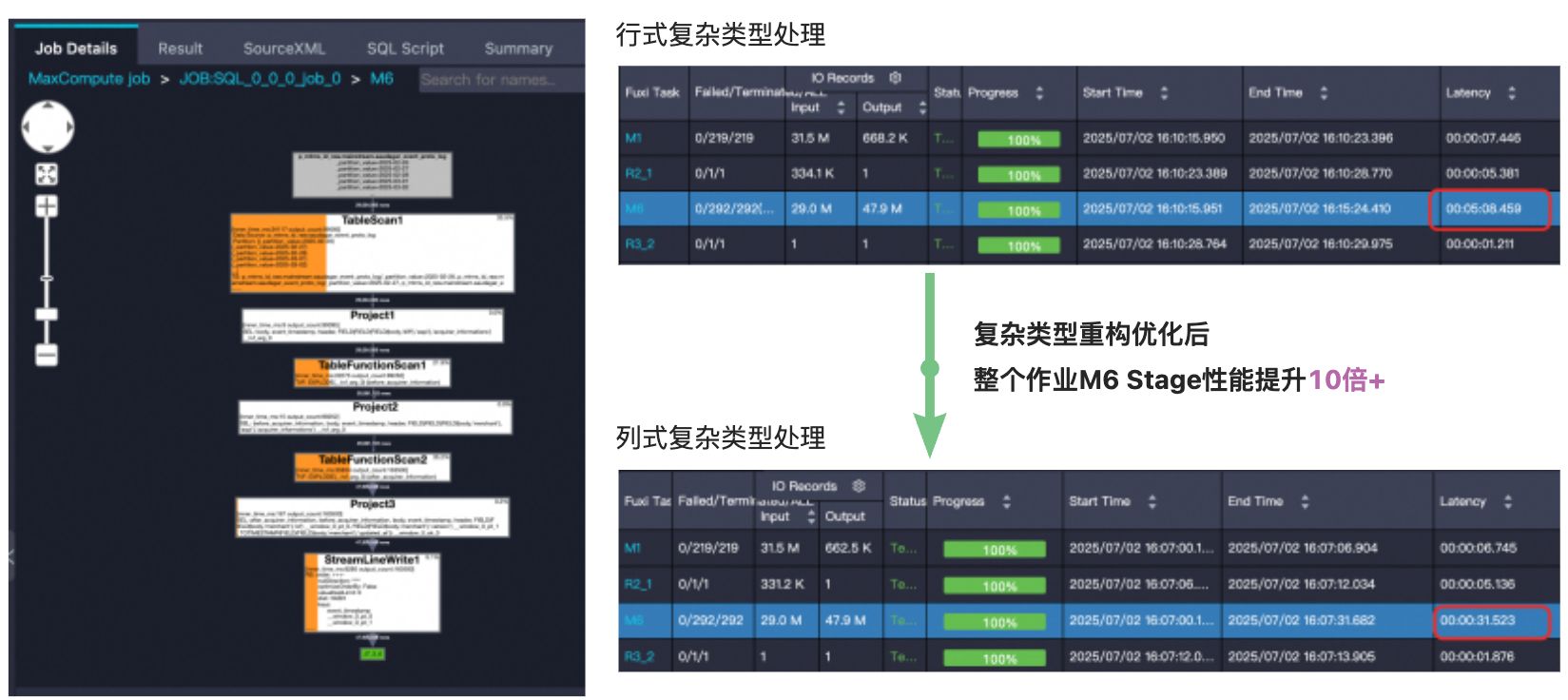
上圖示例展示的是用戶某個作業的其中一個Stage M6的處理過程,TableScan1從源表中讀取了多層嵌套的復雜類型數據,經過了TableScan / Project / TableFunction / Shuffle等算子處理,基于行式復雜類型結構進行處理,M6 Stage整體耗時超過5分鐘,切換到優化后的列式復雜類型處理,整體Stage耗時縮短到31秒,速度提升了10倍+,效果極為顯著。
Unnest with subquery重構優化性能提升案例
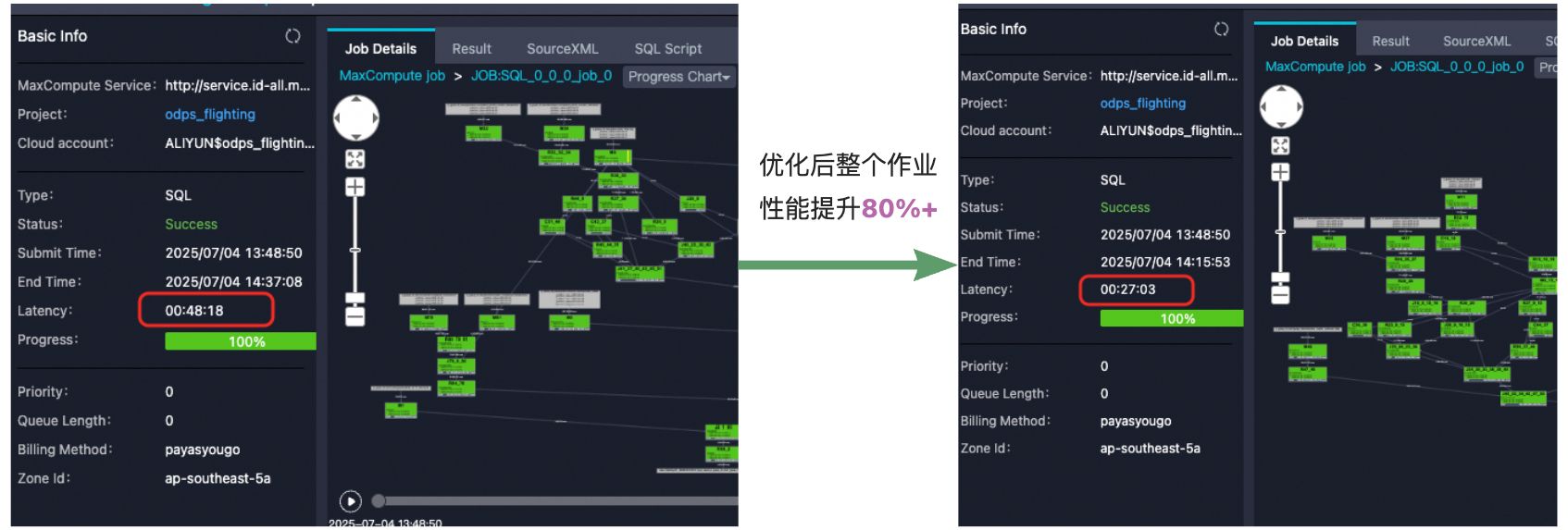
上圖示例展示了用戶某個作業經過Unnest With subquery重構優化后,整體作業性能提升了80%+,由于整體sql比較復雜,這個優化只涉及到其中部分stage,其中命中優化的算子提速3倍+,效果極為顯著。
業務價值
GOTO整體項目,包含復雜類型的表數量超4萬張,日均處理復雜類型的SQL作業超20萬+,通過上述優化重構之后,大部分SQL性能提升20%~10倍+,日均減少2000+ Cpu Core消耗,極大的助力了GOTO項目按時保質的從Bigquery平滑遷移到MaxCompute,實現降本增效的目標。
后續會持續完善打磨列式復雜類型在各個場景的數據處理優化,并全面推廣到MaxCompute平臺所有業務場景中,預計全域上百萬作業將顯著受益,大幅節省業務計算成本,技術普惠到所有用戶。
)
哈希函數、哈希表介紹、優缺點)
什么是渲染)
)
 視頻教程 - snowNLP庫實現中文情感分析)














