
大家好,我是紀寧。
文章將從C語言出發,深入介紹python的基礎知識,也包括很多python的新增知識點詳解。
文章目錄
- 1.python的輸入輸出,重新認識 hello world,重回那個激情燃燒的歲月
- 1.1 輸出函數print的規則
- 1.2 輸入函數input的規則
- 1.3 用print將數據寫入文件
- 2.數據類型、基本操作符與注釋
- 2.1數據類型
- 2.2 基本操作符
- 2.21 算數操作符
- 2.22 邏輯操作符
- 2.23 位操作符及操作符優先級
- 2.3 注釋
- 3.數據的存儲
- python中數據如何存儲
- 4.分支和循環
- 4.1 分支語句 if-else
- 4.2 循環
- 4.3 pass語句
- 5.python基礎數據結構
- 5.1列表——python中的數組
- 5.1.1 列表的增刪查改
- 5.1.2 對列表進行其他操作
- 5.2 字典——python中的結構體
- 5.2.1 字典常用的操作
- 5.2.2 字典的特點
- 5.3 元組
- 5.4 集合
- 5.4.1集合常用的操作
- 5.5 字符串
- 5.51 字符串常用操作
- 5.52 字符串的比較及字符的Unicode編碼
- 5.53 格式化字符串
- 5.54 字符串的編碼轉化
- 5.6 生成式合集
- 5.6.1 字典生成式
- 5.6.2 列表生成式
- 5.6.3 集合生成式
- 5.7 切片
- 6.函數——新瓶裝舊酒
思維導圖:

1.python的輸入輸出,重新認識 hello world,重回那個激情燃燒的歲月
在C語言中,在進行輸入輸出的時候,通常要遵循一定的格式,如變量名必須與變量的類型嚴格對應,輸出輸入的每一個變量都要在數量和格式上都要一一對應,而 python 變得更加簡潔和方便
1.1 輸出函數print的規則
python 中的輸入函數是print,相比于C語言,少了一個f,但功能卻方便了很多。想輸出什么(變量或者直接輸出),就直接往 print 函數里面塞就行了,不用管什么格式,數據類型。但它的多組輸出還是會有一定的規則,否則使用者也難以很好的把握輸出的格式。
下面是 print 函數輸出不同于 C 的一些規則:
- 在同一個 print 函數的輸出中,通常會默認每個數據之間以空格分開(C中卻是默認不分開),而要去掉這以規則,可以在 print函數內部加上
sep參數。給 sep 參數賦值可以使一個 print 函數打印出的每個數據之間以任意方式隔開,如空字符,逗號等等。 - 而在多個 print 函數的輸出中,通常會默認這些數據之間會自動換行,如果想去掉這一規則,可以在 print 函數內部加上
end參數,給 end 參數賦值,可以是每個 print 輸出的值以給 end 賦的值隔開。

為什么可以這樣呢?其實在python 的 print 函數內部,是有 end 參數和 sep 參數的,只不過在不使用這兩個參數的情況下,系統會默認 end 參數的值為‘\n’,sep 參數的值為‘ ’(空格),所以就出現上述情況。
1.2 輸入函數input的規則
python 中的輸入函數是 input ,相對于C語言,input 函數也是比較方便。input函數可以直接讀取從終端(鍵盤)輸入的數據并存儲到變量中,也可以在給出提示后,將想要的答案通過鍵盤輸入并存儲到變量中。

上面代碼意思是從控制臺輸入一個值,再將這個值賦值給變量,其中input 括號里的文字提示在沒有的情況下,效果是一樣的,但有問題提示就比較人性化一點。
有個問題需要注意的是,因為 input 函數在輸入的時候沒有規定數據類型,所以輸入的數據默認都是以字符串的形式返回并賦值給變量。如果要進行計算,需要及時將輸入的數據進行類型轉化,否則就會報錯。

需要什么類型的數據進行計算就轉化為什么類型的數據。
1.3 用print將數據寫入文件
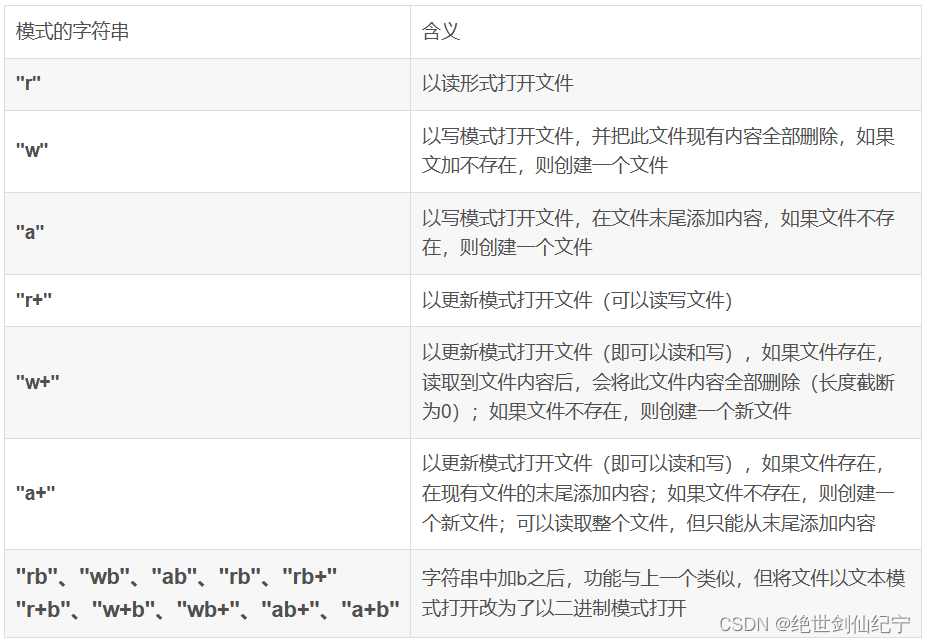
同C一樣,python 中如果要對文件進行操作,也需要先打開文件,操作完關閉文件。python中打開文件的函數為 open 函,關閉文件的函數為 close 。

open 函數的第一個參數為要寫入文件的路徑,第二個參數為對文件進行讀寫的模式。
print 函數的第一個參數是要寫入的數據內容,第二個參數是要寫入的文件對象。
下表為文件操作的一些常用模式
如下圖,打開 D 盤中的 text.txt 文件,即可看到寫入的 hello world。

2.數據類型、基本操作符與注釋
2.1數據類型
python 中的數據類型分為 4 類,整型,浮點型,布爾型,字符串。
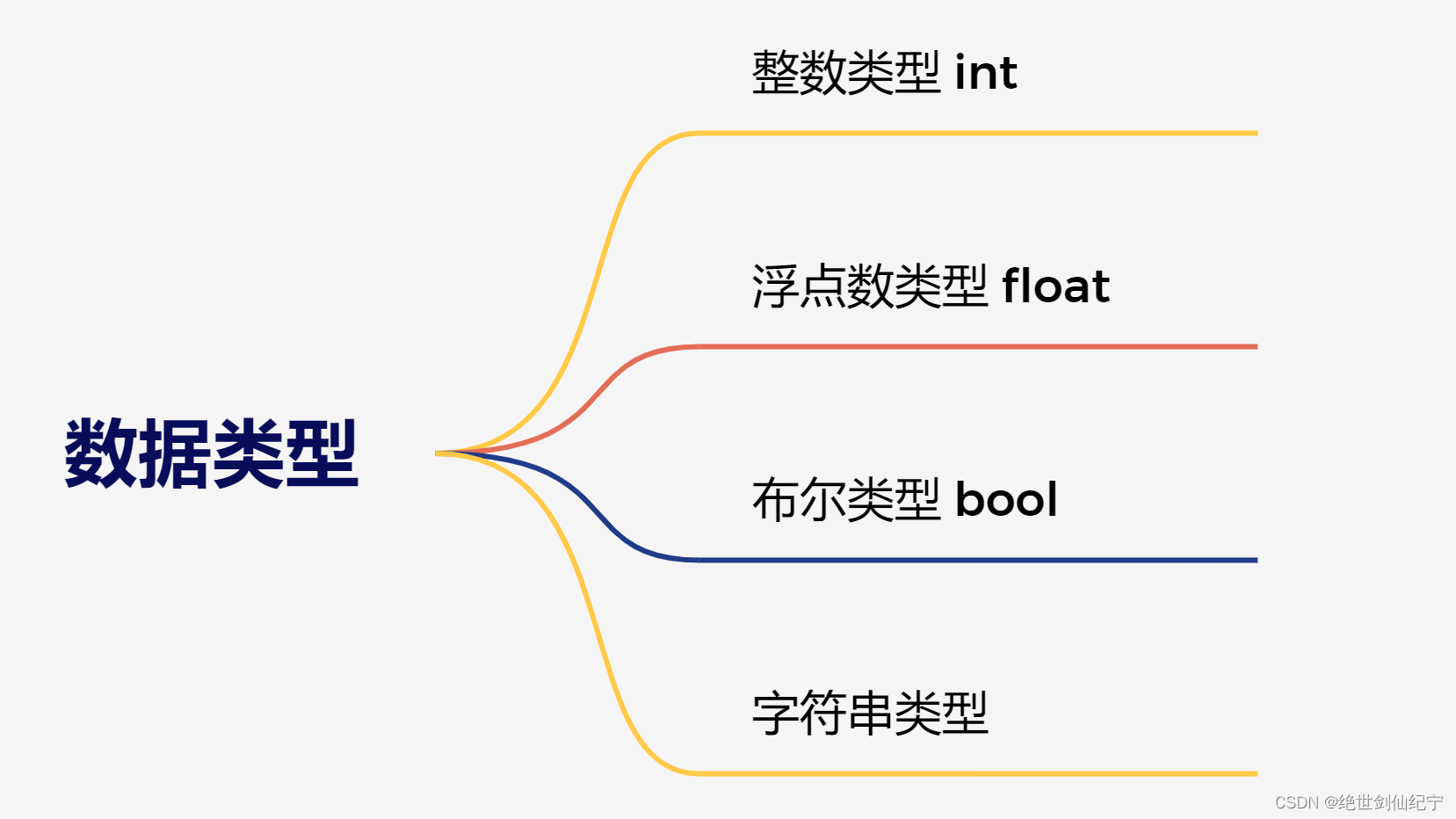
整型、浮點型就不必多說了,和C完全相同。而python的布爾類型則是對真假的判斷,True 為真,False 為假,并且他們True 的值默認為1,False 的值默認為0。
除了以下圖片里的布爾值為False,其余均為True

字符串類型是不可變類型,可以用單引號、雙引號,多引號來定義,其中單、雙引號定義的字符串都必須在同一行,三引號定義的字符串可以在一行或者多行,如下圖。

不同類型的數據如果要一起使用必須轉化為同一種類型,浮點數和整形會自動將結果轉化為浮點型數據,其他的類型在可轉化的前提下可以使用類型轉化函數將數據進行類型轉化。
2.2 基本操作符
2.21 算數操作符
算數操作符中,最基本的加減乘、取模都與C相同。不同的是python中進行了除法分類,并加入了冪運算符。
python 將除法分為了整數除法(//)和普通除法(/),而整數除法就是向下取整,大家應該懂的,和C一樣,而普通除法可以進行正常的運算,兩個整數相除也可以得到浮點數。
冪運算符(**)前面的操作數是冪運算的底數,后面的操作數是冪運算的次數。
2.22 邏輯操作符
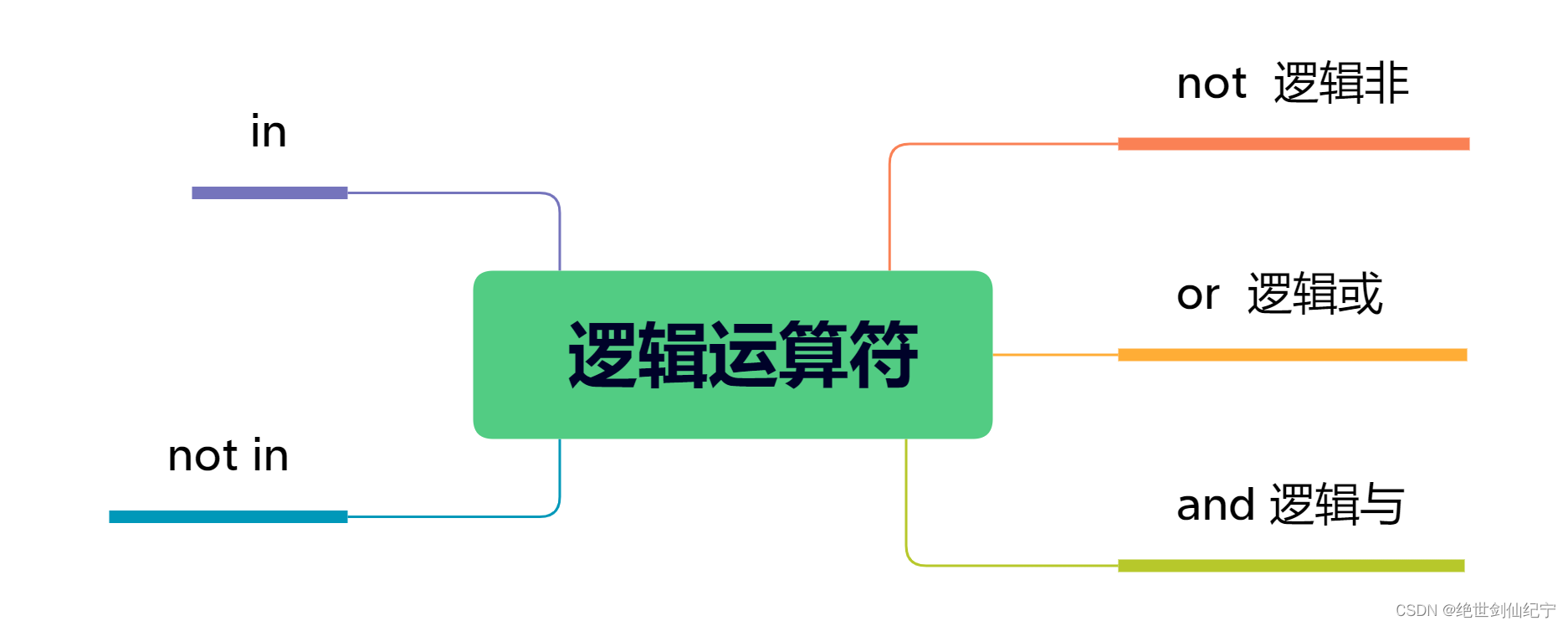
邏輯與and、邏輯或or、邏輯非not,分別對應C語言中的&&,||,!運算符。
而 in 則是用于判斷一個元素是否在一個容器中,具體來說,可以用于判斷元素是否在列表、字符串、元組、集合、字典中,not in 正好相反,是判斷元素是否不在容器中。
2.23 位操作符及操作符優先級
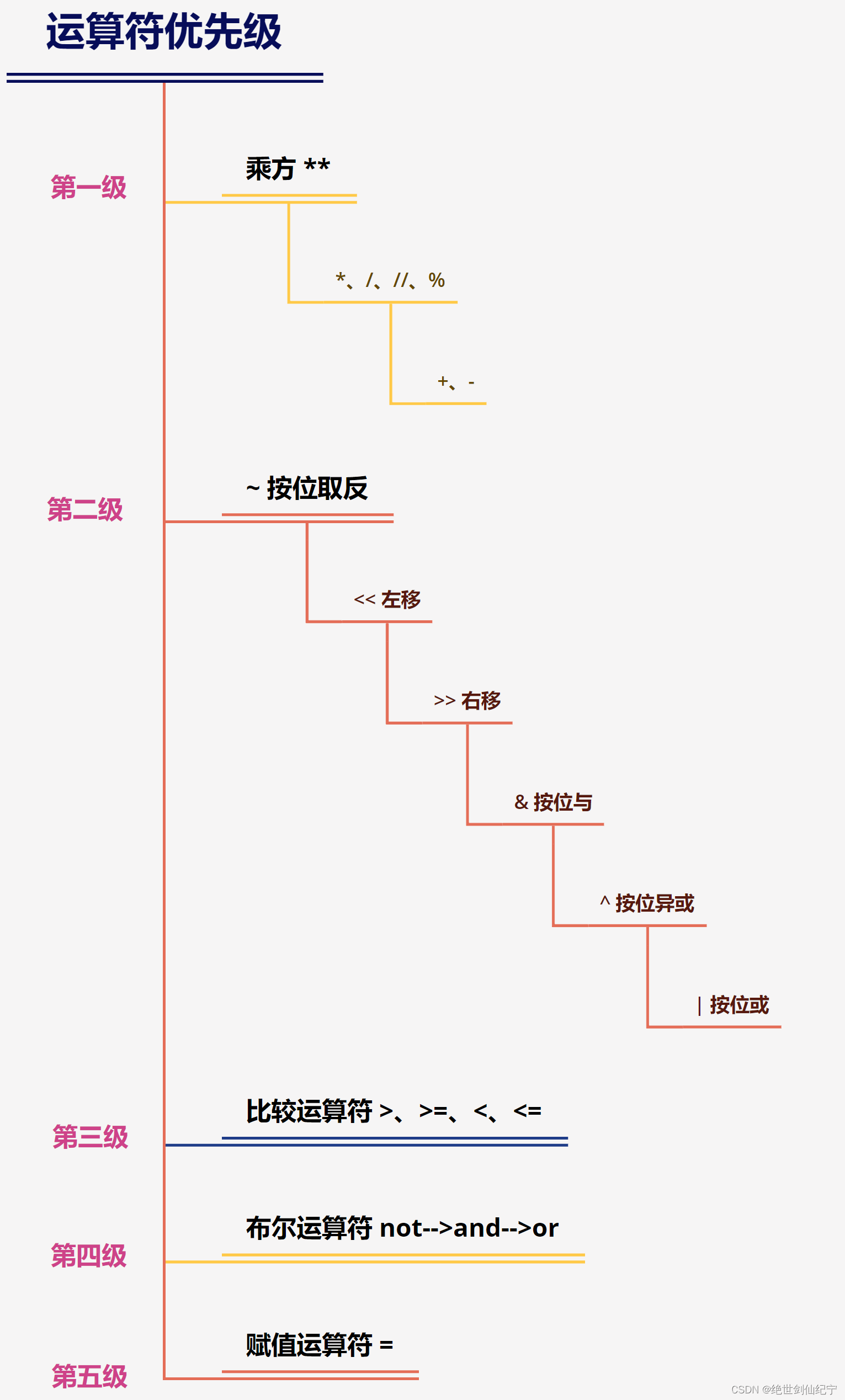
python的位操作符與C是一樣的,有& 按位與 ,| 按位或, ^ 按位異或, ~ 按位取反,<< 左移, >>右移。具體方法與C中是一樣的,這里就不過多贅述。
操作符的優先級
嚴格按照下面的優先級進行運算,如果不確定或者要先計算優先級低的運算記得加括號。
2.3 注釋
python的注釋方式也進行了改變,注釋方式改為在語句前加 # 號
在 PyCharm 中,對多段語句進行整體注釋方式是 Ctrl+ /
3.數據的存儲
python中數據如何存儲
python存儲數據的邏輯圖
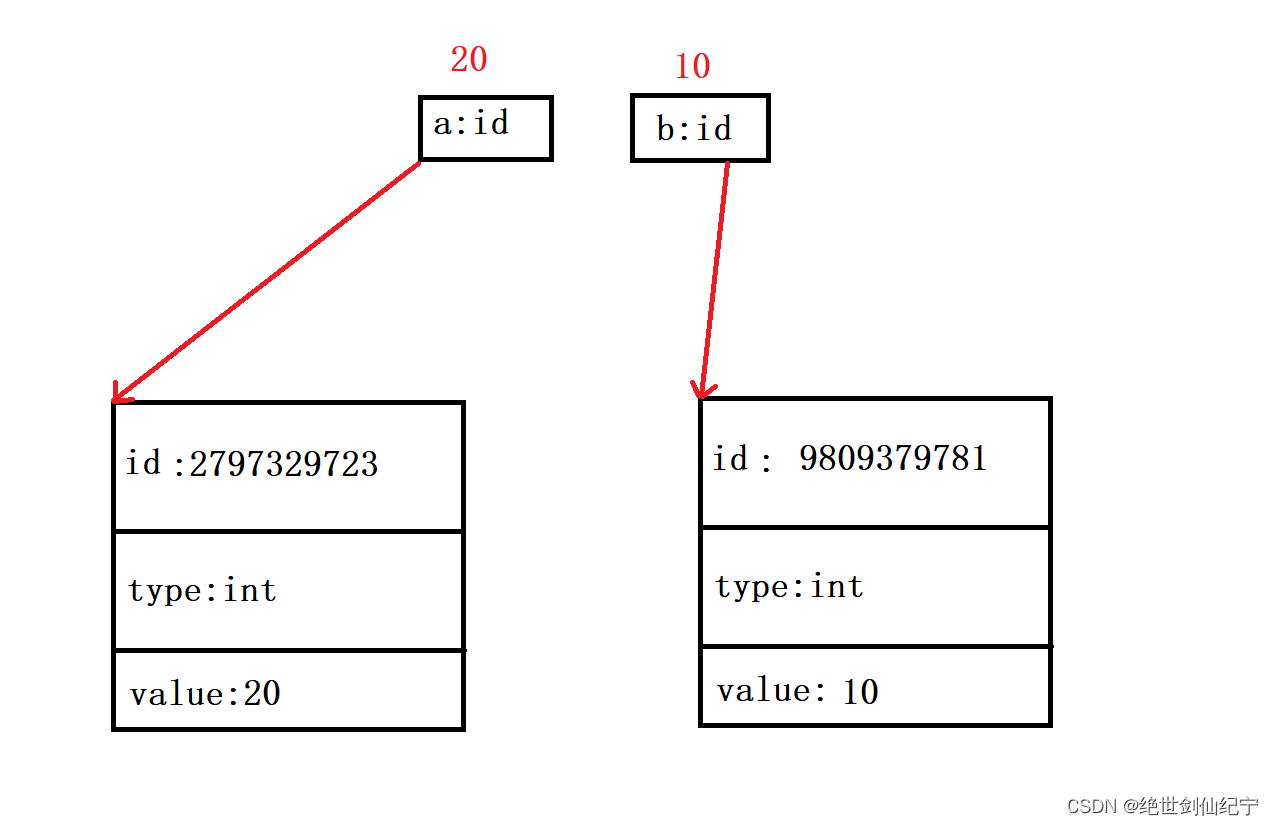
每個數據都有自己的 id,而變量中存儲的僅僅是這個數據的 id,編譯器通過這個 id 就找到了這塊的數據,進而進行一系列操作,這里的 id 類似于C中的地址,而這樣的訪問方式類似于指針。
可以用 is 來比較兩個變量的 id 時候相等
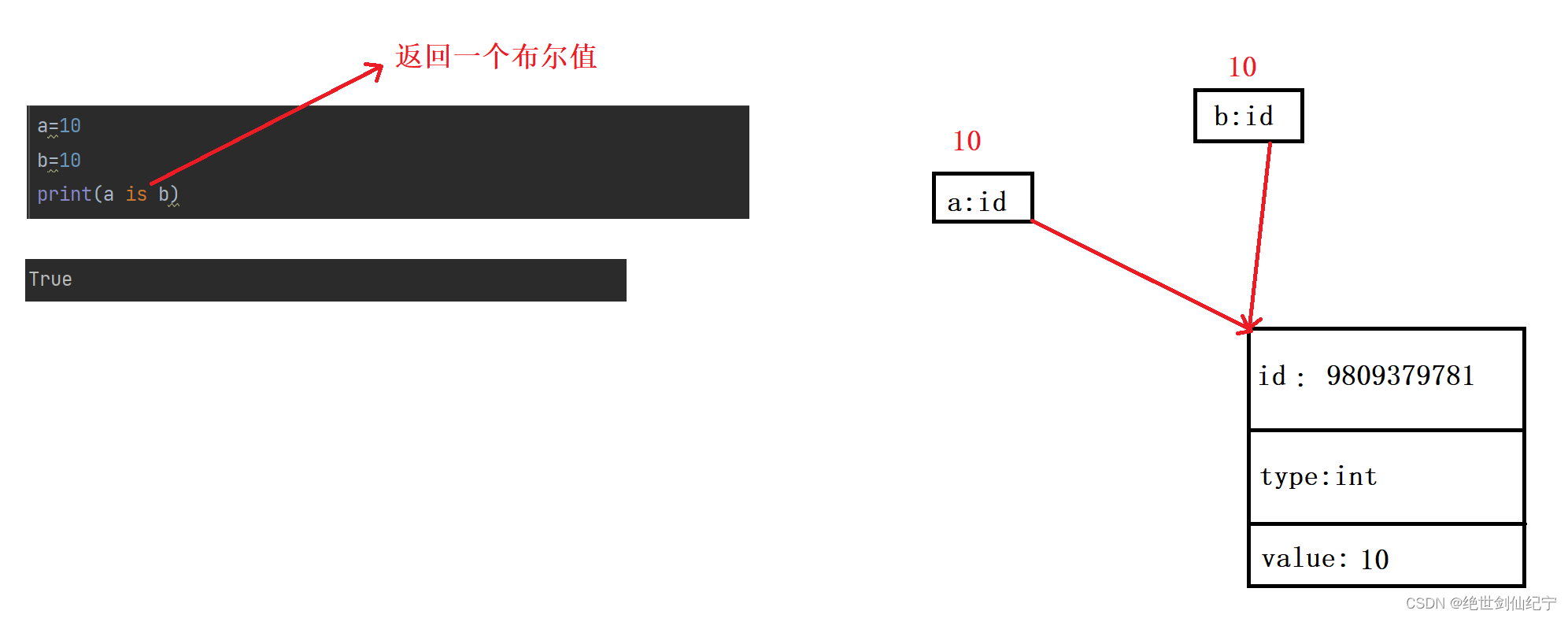
返回True,說明變量 a 和 b 訪問是同一塊內存空間,完全相等。
在C中,數據會被存儲到多個區域中,如堆區,棧區等等,下圖為C中數據存儲的區域
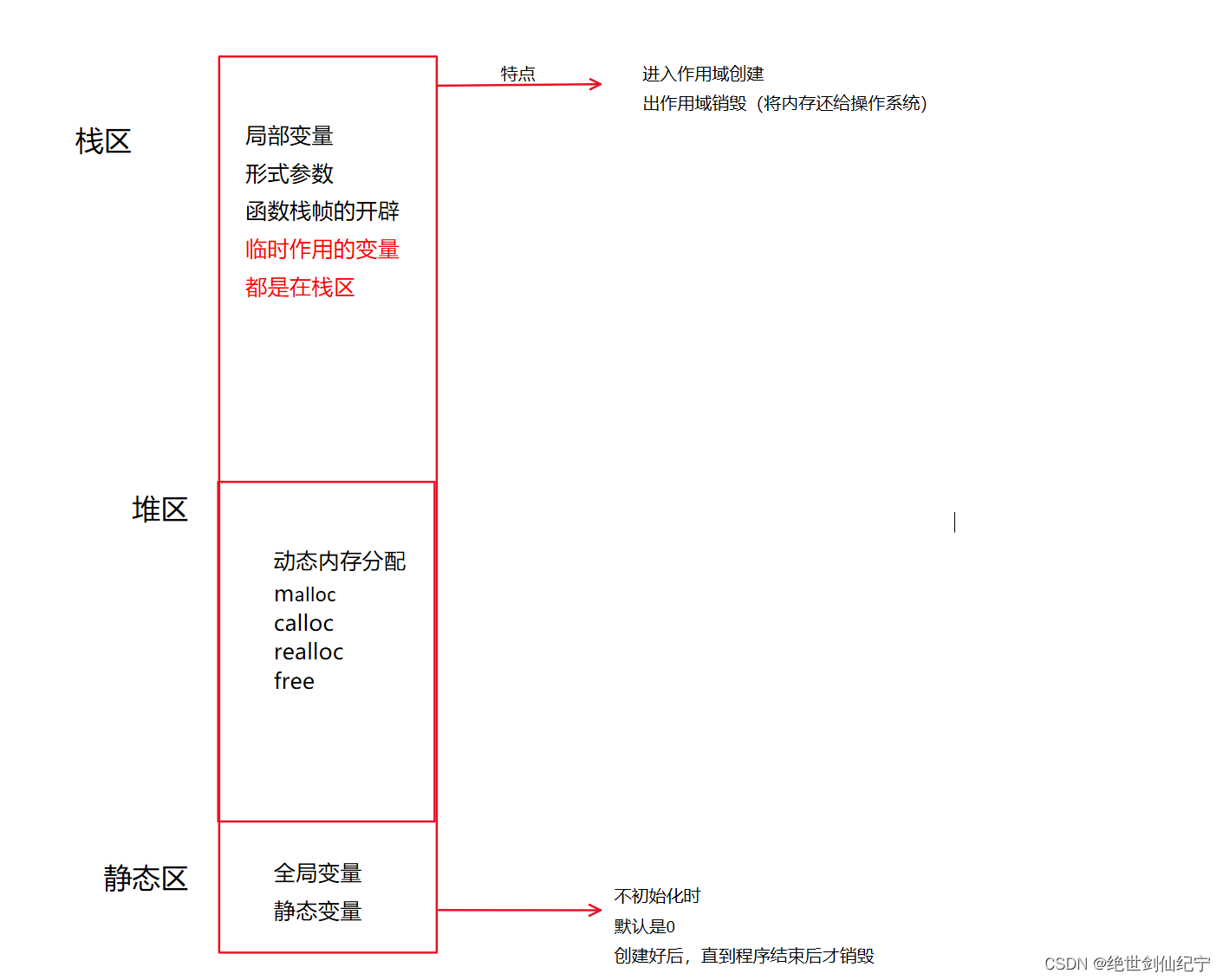
python中也有大量的區域供使用者存儲數據
棧區:存儲基本數據類型及其對象(如int、float、bool等),以及函數調用時的參數、返回值和局部變量等。棧內存自動分配和釋放,具有快速的存取速度。
堆區:存儲復雜對象(如列表、元組、字典等)及其對象。堆內存的分配與釋放由Python解釋器自動進行,可以通過Python中的垃圾回收機制自動釋放內存。
數據區:存儲全局變量和靜態變量,以及常量等數據。
代碼區:存儲Python的字節碼,即轉換成機器碼之前的中間代碼。
在C中,需要手動分配和釋放動態內存,而在Python中,內存管理是自動的,Python解釋器會根據需要自動分配和釋放內存。
4.分支和循環
分支和循環這里與C語言大同小異,邏輯上大同,語法規則上小異。
4.1 分支語句 if-else
python語法如下,與C相比,只是去掉了括號,如果if中包含多條語句,則可使用相同的縮進來代替C中的大括號。
if condition:# code to be executed if condition is True
else:# code to be executed if condition is False
其中,condition是一個表達式,如果結果為True,代碼塊1就會被執行,否則代碼塊2就會被執行。
下面是一個示例:
a = 10
if a > 0:print("a is positive")
else:print("a is not positive")
python 將 else if改成了elif 語句,用于添加多個條件分支。
條件表達式
python中的條件表達式類似于C語言中的三目操作符
例如,以下代碼用條件表達式來檢查變量x是否大于5,如果是,則將變量y的值設置為10,否則將其設置為0:
x = 7
y = 10 if x > 5 else 0
print(y) # 輸出 10
在這個例子中,條件表達式的條件是“x > 5”,如果為True,則返回值為10(即“y = 10”),否則返回值為0(即“y = 0”)。但這種條件表達式只適用于較為簡單的分支情況,更復雜的條件邏輯,應該使用 if 語句來代替。
4.2 循環
while循環基本與C是一樣的,一直循環某種結構,直到滿足特定的條件為止。
while 條件:循環體
代碼示例
i = 0
while i < 5:print(i)i += 1
Python中的for-in循環用于迭代遍歷序列或集合中的每個元素。
for 變量名 in 序列:循環體語句
其中,變量名是循環變量,用于在循環中引用每個元素,序列可以是列表、元組、字符串、集合或字典等可迭代對象,循環體語句是需要重復執行的語句塊
示例代碼:
names = ['Alice', 'Bob', 'Charlie', 'David']
for name in names:print(name)# 輸出結果:
# Alice
# Bob
# Charlie
# David
在循環體中可以結合條件語句,實現更加靈活的控制流程。
4.3 pass語句
pass是一個空語句,它不執行任何操作。但它可以被用作占位符,表示"在這里不做任何事情",通常可以幫助我們搭建語法結構,因為Python需要在代碼塊中有至少一個語句。例如,當你想要先寫下一些代碼的框架但還沒有想好實現時,可以在代碼塊中使用pass語句占位。
def my_function():pass
在上面的代碼中,my_function 函數中沒有任何操作,但由于使用了 pass 語句,它仍然可以正確地定義。如果沒有 pass 語句,代碼將會報錯。
5.python基礎數據結構
python的基礎數據結構有字符串、元組、列表、字典、集合五種。
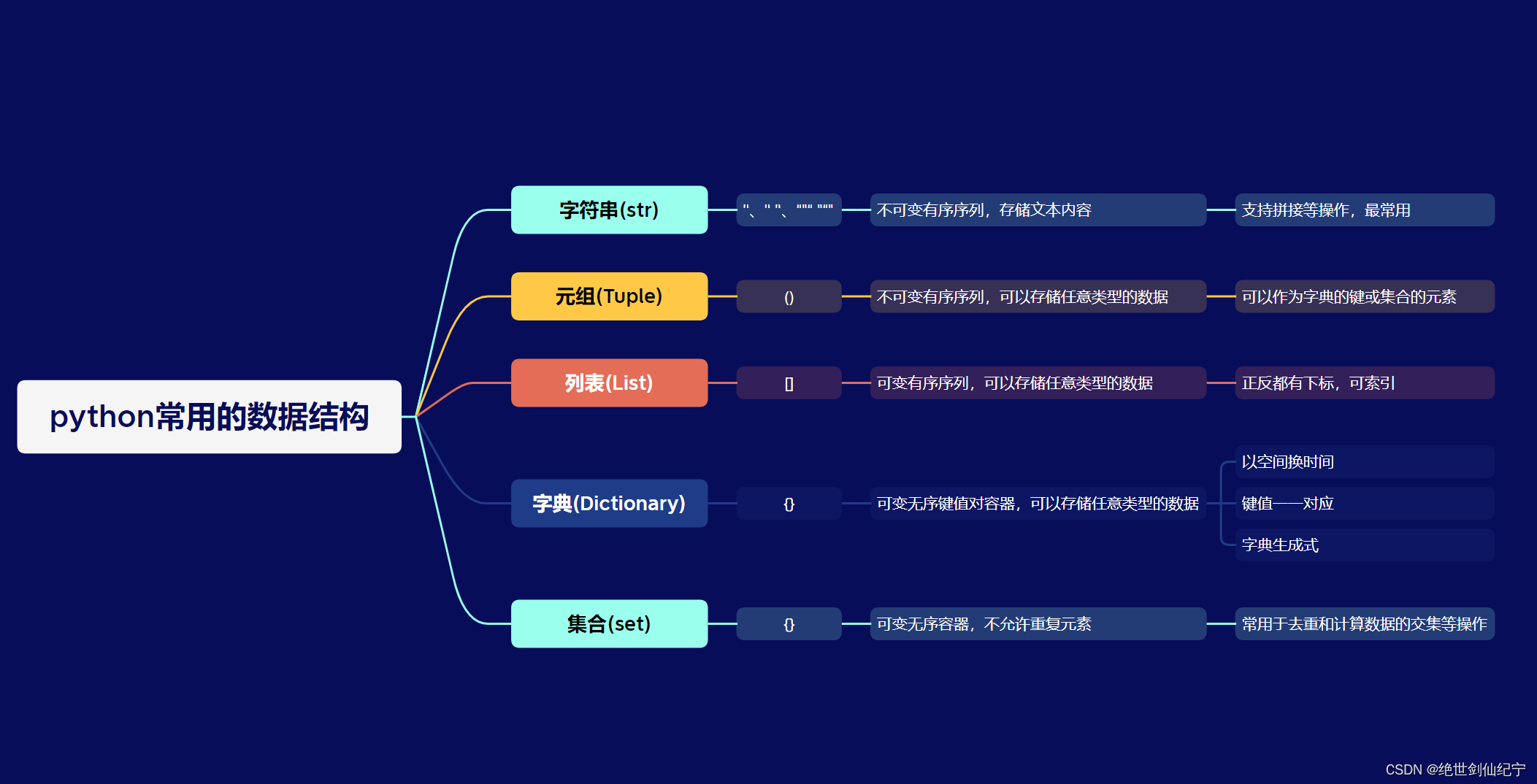
元組、字符串是不可變序列,自身不能進行增刪查改等操作。
有序數列是有下標的
1.下標及索引規則
下標可以從前開始,也可以從后開始
從前開始的規則是從0 開始,依次遞增1
從后開始的規則是從-1開始,依次遞減1

5.1列表——python中的數組
在Python中,與C語言中的數組相對應的數據類型是列表(list)。列表可以用于存儲多個元素,并且可以動態地增加或減少元素的個數。和數組類似,列表的元素可以通過索引訪問,也可以使用循環遍歷所有元素。但是,相比于數組,在Python中使用列表更為方便和靈活。
列表的創建
用一對方括號[]來表示一個空列表,或者在方括號內添加逗號分隔的值列表即可創建一個有元素的列表;還可以使用list()函數來創建一個列表:在list函數內放置多個值,如果是字符串,會將中每個字符單獨作為元素。
5.1.1 列表的增刪查改
列表中查詢元素
在列表中查詢列表元素有兩種方法:第一種是列表名[索引],下標從0開始,第一個元素的索引為0,最后一個元素的索引為列表元素總數 sz-1;還可以‘倒著’索引:最后一個元素的索引為 -1,第一個元素的索引為sz,當然這兩種索引的下標都是從小到大。
第二種是index(列表元素),可用于查找列表中某個元素第一次出現的位置,其基本語法如下:
list.index(x[, start[, end]])
其中,x 是需要查找的元素;start 和 end 是可選參數,表示查找的起始位置和結束位置,如果省略則默認查找整個列表。
如果該元素不存在于列表中,則會引發ValueError異常,可以使用try-except語句來避免程序崩潰。例如下面代碼:
my_list = [1, 2, 3, 4, 5]
try:index = my_list.index(6)print(index)
except ValueError:print("Element not found in list")
增加元素
可以使用append()方法將一個元素添加到列表的末尾。也可以使用extend()方法將另一個列表的元素添加到當前列表的末尾,或者使用insert()方法將元素插入到指定的位置。
my_list = [1, 2, 3]
my_list.append(4) #將一個元素添加到列表的末尾
print(my_list) # [1, 2, 3, 4]
my_list = [1, 2, 3]
my_list.extend([4, 5]) #另一個列表的元素添加到當前列表的末尾
print(my_list) # [1, 2, 3, 4, 5]
my_list = [1, 2, 3]
my_list.insert(1, 4) #將元素插入到指定的位置
print(my_list) # [1, 4, 2, 3]
刪除元素
可以使用remove()方法刪除指定的元素,還可以使用pop函數刪除列表中指定位置的元素,或者使用del語句刪除指定位置上的元素。
my_list = [1, 2, 3]
my_list.remove(2) #刪除列表中的 2 元素
print(my_list) # [1, 3]
my_list = [1, 2, 3]
my_list.pop(0) # 刪除并返回1
print(my_list) # 輸出[2,3]
my_list = [1, 2, 3]
del my_list[1] #刪除索引1位置的元素
print(my_list) # [1, 3]
修改元素
可以直接通過下標來修改指定位置上的元素。
my_list = [1, 2, 3]
my_list[1] = 4 #將索引1位置處的元素改為4
print(my_list) # [1, 4, 3]
5.1.2 對列表進行其他操作
創建列表的副本
列表的副本是創建了一個新的列表,它包含與原始列表相同的元素,但實際上是一個不同的對象。因此,對副本所做的更改不會影響原始列表。 創建副本有下面幾種方法
1.使用切片操作符[:]。例如,如果原列表是my_list,可以使用my_list[:]來創建一個副本,如下所示:
my_list = [1, 2, 3]
my_list_copy = my_list[:]
2.使用copy()方法。例如,如果原列表是my_list,可以使用my_list.copy()來創建一個副本,如下所示:
my_list = [1, 2, 3]
my_list_copy = my_list.copy()
3.使用list()函數。例如,如果原列表是my_list,可以使用list(my_list)來創建一個副本,如下所示:
my_list = [1, 2, 3]
my_list_copy = list(my_list)
對列表進行排序
在C語言中,如果我們要對數組元素進行排序,可能要使用冒泡排序、qsort排序等方法,而在python列表中,有專門的函數對列表進行排序。
降序排列
my_list = [3,1,4,1,5,9,2,6,5,3,5]
my_list.sort(reverse=True)
print(my_list)
升序排列
my_list = [3,1,4,1,5,9,2,6,5,3,5]
my_list.sort()
print(my_list)
求某元素在列表中出現的次數
第一種方法是對列表進行遍歷,設立一個計數器,當出現某元素的時候,count就加1。
count = lst.count(x)
print(count)
也可以使用python的內置函數count來統計
count = lst.count(x)
print(count)
5.2 字典——python中的結構體
Python字典是一種無序的集合數據類型,它由一系列鍵值對組成,每個鍵值對之間用逗號分隔。字典中的鍵必須是唯一的,而值可以是任何類型的數據。字典是Python語言中常用的一種數據結構,可以直接使用,不需要定義或聲明,并且它提供了靈活的數據組織和訪問方式:直接通過鍵就可以訪問鍵對應的值。
字典的創建方式:
1、使用花括號{},用冒號分割鍵值: dict1 = {'key1': 'value1', 'key2': 'value2', ...},key與value是一一對應的。
2、使用內置函數dict()函數創建:dict2 = dict(key1='value1', key2='value2', ...)
3、使用dict.fromkeys()方法創建,鍵可以輸入多種,而值只能是一種:dict3 =dict.fromkeys(['key1', 'key2', ...],100)
4、創建空字典:直接使用花括號{},里面不放值;使用dict()函數里面不放值。
字典定義示例:
person = {"name": "John","age": 30,"city": "New York"
}
其中,鍵分別是"name"、“age"和"city”,對應的值分別是"John"、30和"New York"。可以通過鍵來訪問對應的值。例如:
print(person["name"]) # 輸出:John
print(person["age"]) # 輸出:30
字典的內存是由python解釋器自動管理內存的,在使用過程中不需要考慮內存分配和釋放的問題。
5.2.1 字典常用的操作
-
獲取字典中的值:通過鍵來獲取字典中的值,例如 dict[key]。 -
添加新鍵值對:使用 dict[key] = value,可以向字典中添加新的鍵值對。 -
修改鍵值對:通過鍵來修改字典中的值,例如 dict[key] = new_value。 -
刪除鍵值對:使用 del dict[key] 可以刪除字典中的鍵值對。 -
獲取字典的長度:使用 len(dict) 可以獲取字典中鍵值對的數量。 -
判斷鍵是否存在:可以使用 in 關鍵字判斷一個鍵是否存在于字典中,例如 key in dict。 -
獲取所有鍵或所有值:使用 dict.keys() 可以獲取字典中所有的鍵,使用 dict.values() 可以獲取字典中所有的值。 -
獲取所有鍵值對:使用 dict.items() 可以獲取字典中所有的鍵值對。 -
清空字典:使用 dict.clear() 可以清空整個字典。 -
復制字典:使用 dict.copy() 可以復制一個字典。
5.2.2 字典的特點
字典是無序的:字典中的條目沒有固定的順序,存儲的順序與定義時候的順序無關。
字典是可變的:可以添加、刪除或修改字典中的鍵值對。
字典中的鍵必須是不可變的類型,例如整數、浮點數、字符串或元組,而值可以是任何類型。
每個鍵只能在字典中出現一次,如果同一個鍵被多次賦值,則只有最后一個值被保留。
字典通常用于快速查找和檢索,可以根據鍵快速訪問值,時間復雜度為O(1)。
字典的存儲是’隨機的’,依靠鍵來找值,因此浪費了大量的內存,是一種以空間換時間的數據結構。
5.3 元組
元組是python內置的數據結構之一,是一個不可變序列,可以包含任意類型的數據,如數字、字符串、列表、字典、元組等。
元組的創建
1、使用小括號()將元素括起來,用逗號分隔,例如:
(1,"hello",[3,4],5.6,{"紀寧":"赤明九天圖"})
2、使用內置函數 tuple(),將列表或者其他迭代對象轉化為元組,如 t=tuple([1,2,3])
3、可以省略小括號,逗號分隔的情況下直接創建元組,例如:t=1,“hello”,[3,4],5.6
4、只有一個元素是,加逗號以區分元組和表達式,例如:t=(1,)
5、空元組:()或者 t = tuple()

為什么要將元組設置為不可變序列?
元組被設計為不可變序列,因為它們可以用來表示一組不可變的數據,例如日期、時間、坐標等。一旦元組被創建,它們的值就不能被修改,這使得它們比可變序列更安全,因為它們不能被意外修改。此外,元組也比列表更加高效,因為它們的不可變性使得在處理大量數據時,它們能夠更快速地被創建、操作和釋放。
5.4 集合
集合是一種python內置的數據結構,與列表、字典一樣都屬于可變類型的序列,并且集合里的元素是無序不重復的,所以集合相當于沒有value的字典。
字典的創建
- 直接{},例如s = {‘python’, ‘hello’ , 90}
- 使用內置函數set(),括號里面可以包含多種數據類型的元素
創建空集合也需要使用set()函數,如果直接用大括號初始化空集合會被解釋器認為是空字典。
5.4.1集合常用的操作
集合元素的新增
- add():添加單個元素到集合中
- update():添加多個元素到集合中
add()方法示例
# 定義一個空集合
my_set = set()
# 添加元素
my_set.add(1)
my_set.add(2)
my_set.add(3)
print(my_set) # 輸出:{1, 2, 3}
update()方法示例
# 定義一個空集合
my_set = set()
# 添加元素
my_set.update([1, 2, 3])
my_set.update([4, 5, 6])
print(my_set) # 輸出:{1, 2, 3, 4, 5, 6}
集合元素的刪除
- remove():按照元素值刪除一個元素,如果元素不存在,就觸發KeyError
- discard():按照元素值刪除一個元素,如果元素不存在,不報錯
- pop():隨機刪除集合中一個元素,并返回該元素,集合為空則觸發KeyError
- clear():刪除集合中所有元素
s=set(range(1,6))
print(s) #{1,2,3,4,5}
s.pop() #隨機刪除一個
print(s) # {2,3,4,5}
s.discard(3) #刪除集合元素 3
print(s) #{2, 4, 5}
s.clear() #清空
print(s) #輸出空集合
判斷兩個集合的關系
- issubset()——s2.issubset(s1),判斷s2是否是s1的子集
- issuperset()——s1.issuperset(s2),判斷s1是否是s2的超集
- isdisjoint()——s1.isdisjoint(s2),判斷s1和s2是否沒交集
求兩個集合交并集的方法
- intersection——s1.intersection(s2),等價于 s1&s2,求s1與s2的交集
- union——s1.union(s2),等價于 s1| s2,求s1與s2的并集
- difference——s1.difference(s2),等價于s1-s2,求s1與s2的差集
- symmetric_difference——s1.symmetric_difference(s2),等價于 s1^s2,求s1與s2的對稱差集(并集 - 交集)
5.5 字符串
5.51 字符串常用操作
字符串查詢
- index(),在字符串中查找指定字符串,返回首次出現時候的索引,找不到就報錯。
- find(),在字符串中查找指定字符串,返回首次出現時候的索引,找不到則返回-1
- rindex(),在字符串中查找指定字符串,返回最后一次出現時候的索引,找不到就報錯
- rfind(),在字符串中查找指定字符串,返回最后一次出現時候的索引,找不到就返回-1
字符串大小寫轉化
- upper()——將字符串中所有字符都轉化為大寫字母
- lower()——將字符串中所有字符都轉化為小寫字母
- swapcase()——把字符串所有的大寫轉化為小寫,小寫轉化為大寫
- capitalize()——把第一個字母轉化為大寫,其余字母轉為小寫
- title()——把每個單詞的第一個字母轉化為大寫,把每個單詞的剩余字符轉化為小寫。
字符串對齊
字符串內容對齊是指將字符串中的內容按照一定的方式對齊,使其更加美觀,易于閱讀,并且符合視覺習慣。常見的字符串內容對齊操作包括左對齊、右對齊、居中對齊等。
若傳遞的字符串寬度 width 小于字符串長度,則返回字符串包本身
- ljust()——左對齊
txt = txt.ljust(width,fillchar)
其中,width表示字符串的總寬度;fillchar表示要填充的字符,默認為空格。如果字符串長度小于width,則用fillchar在右側填充,直到達到width長度。
- rjust——右對齊
string.rjust(width, fillchar)
其中,width表示字符串的總寬度;fillchar表示要填充的字符,默認為空格。如果字符串長度小于width,則用fillchar在左側填充,直到達到width長度
- zfill——右對齊(用0填充)
string.zfill(width)
右對齊,只接收一個參數,用于指定字符串對齊的寬度
- center——居中對齊
string.center(width,fillchar)
其中,width表示字符串的總寬度;fillchar表示要填充的字符,默認為空格。如果字符串長度小于width,則用fillchar在左右兩側均勻填充,直到達到width長度
字符串劈分
字符串劈分操作是指根據指定的分隔符將一個字符串拆分成多個子字符串。
- splist(sep=,maxsplit),從字符串左邊開始劈分,sep 是劈分字符,maxsplit 是劈分的最大次數
- rsplit(sep=,maxsplit),從字符串右邊開始劈分,sep 是劈分字符,maxsplit 是劈分的最大次數
在經過最大劈分次數后,剩余的子串將會單獨作為一部分。
判斷字符串的方法
- isidentifier(),判斷字符串是不是合法的標識符
- isspace(),判斷字符串是否全部由空白字符組成(回車、換行、水平制表符等)
- isalpha(),判斷指定的字符串是否全部由字母組成(漢字也算字母)
- isdecimal(),判斷字符串是否全部由十進制數字組成
- isnumeric(),判斷指定的字符串是否全部由數字組成(Unicode編碼中的數字字符)
- isalnum(),判斷指定字符串是否全部由字母和數字組成
isnumeric函數可以判斷Unicode編碼中的數字字符是否是數字,包括阿拉伯數字0-9、羅馬數字、中文數字、泰語數字、藏文數字等,但 isnumeric函數 不能判斷小數、負數、科學計數法等特殊的數字形式。
字符串替換
- replace(),第一個參數是被替換的字符串的子串,第二個參數是替換的字符串,第三個參數是最大替換次數,函數返回替換后的字符串,原字符串不變,如果未找到子串,則不進行替換。
- join(),用于將一個可迭代對象(如list、tuple等)中的元素用某字符連接成一個字符串。
separator = ' ' # 連接符(可以為任意字符)
seq = ['apple', 'banana', 'cherry'] # 可迭代對象,如果只有一個字符串,就默認字符串本身為可迭代對象
result = separator.join(seq) # 將seq中每個元素用separator連接起來
print(result) # 輸出 'apple banana cherry'
5.52 字符串的比較及字符的Unicode編碼
字符的Unicode編碼
每個字符都有對應的Unicode編碼,類似于C語言中的ASCII碼,但更全面。Unicode編碼的前128個就是ASCII,并且Unicode編碼為所有字符都設立的編碼,更全面。
- ord(),ord函數可以將一個字符轉化為其對應的 Unicode編碼。
- chr(),chr函數可以將Unicode編碼轉化為對應的字符。
字符串的比較
先比較兩個字符串中的第一個字符的Unicode編碼,如果相等,則繼續比較下一個字符,依次比較下去,直到兩個字符不相等,其比較結果就是兩個字符串的比較結果,后續字符串中的字符將不再被比較。
字符串相等 is ,比較的是兩個字符串的地址(id)是否相等;而字符串相等 ==,比較的是兩個字符串的值(value)是否相等。
5.53 格式化字符串
為什么要格式化字符串?

如圖,這就是一種‘格式化’,需要改的地方只有 xxx 的部分,極大提高了工作效率。
格式化字符串的方式
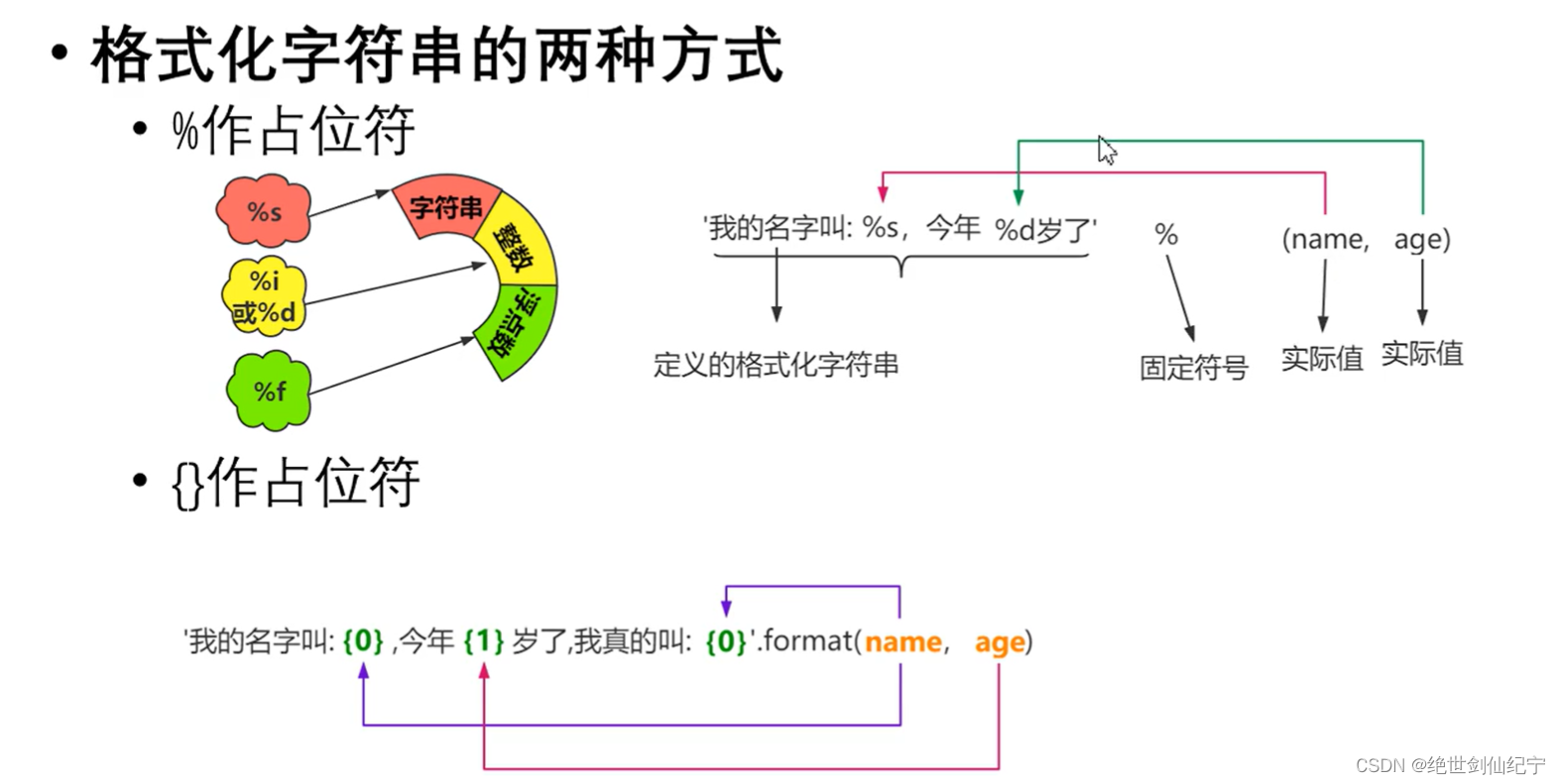
例如:
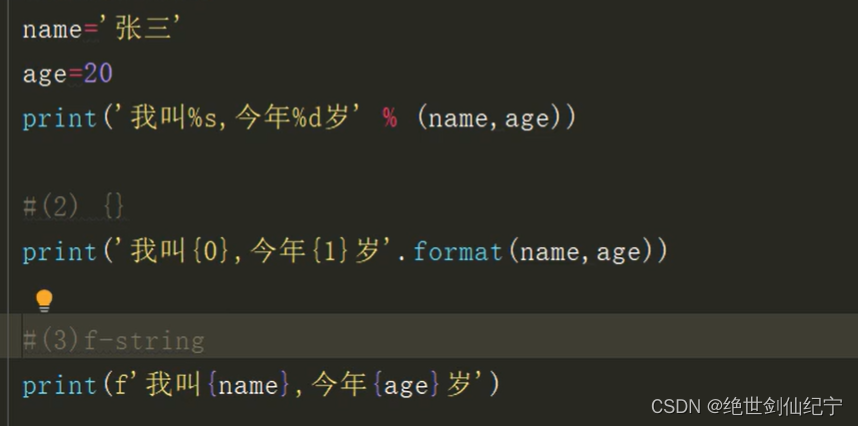
5.54 字符串的編碼轉化
為什么要進行字符串的編碼轉化
傳輸數據:在網絡傳輸和存儲中,需要將字符串編碼轉換為字節流的形式。例如,使用 HTTP 請求和響應傳輸數據時,需要將數據轉換為 UTF-8 或其他編碼格式的字節流。
多語言支持:不同語言使用不同的編碼方式,進行編碼轉換可以確保在不同語言之間傳輸數據時不會出現亂碼。
安全性:某些字符可能被用于編寫惡意代碼或注入攻擊,進行編碼轉換可以保障系統的安全性。
數據庫操作:在將數據存儲到數據庫中時,可能需要將字符串進行編碼轉換,以確保數據庫支持該編碼格式并且能正確存儲和檢索數據。
業務需求:有時候,業務需求需要將字符串轉換為指定的編碼格式,以滿足特定場景的要求。例如在一些人工智能領域中,需要將文本進行編碼轉換以方便進行文本分析和處理。
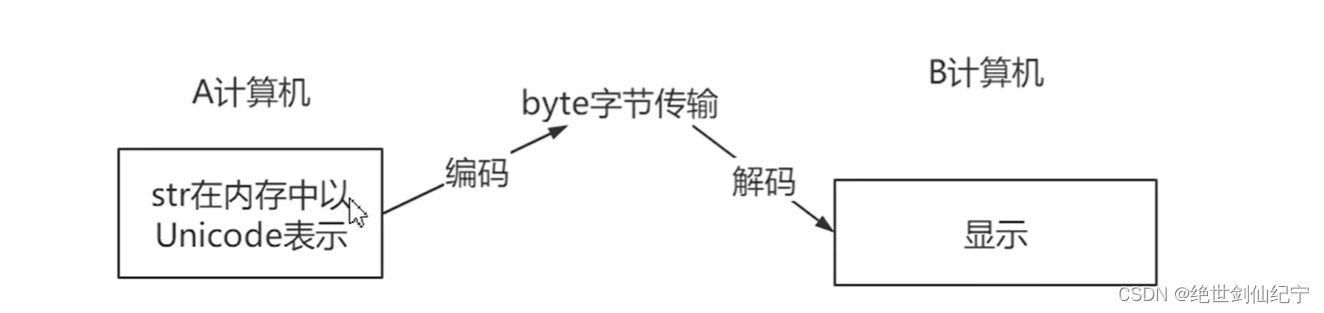
- 編碼:s.encode(ending=‘GBK’) 或者 s.encode(ending=‘UFT-8’),將字符串s轉化為二進制數據
- 解碼:s.decode(ending=‘GBK’) 或者 s.decode(ending=‘UFT-8’),將二進制數據轉化為字符
編和解的字節流必須統一,如用’GBK’編碼,就必須使用’GBK’解碼,使用’UFT-8’編碼就必須使用’UFT-8’解碼。
5.6 生成式合集
5.6.1 字典生成式
內置函數zip():用于將迭代對象作為參數,將對象中對應的元素打包成一個元組,然后返回由這些元組組成的列表。
字典生成式語法格式:
{key: value for key, value in iterable}
其中,key表示字典的鍵,value表示字典的值,iterable表示可迭代對象,例如列表、元組、字典等。生成式會遍歷iterable中的每個元素,根據指定的規則創建一個新的字典。
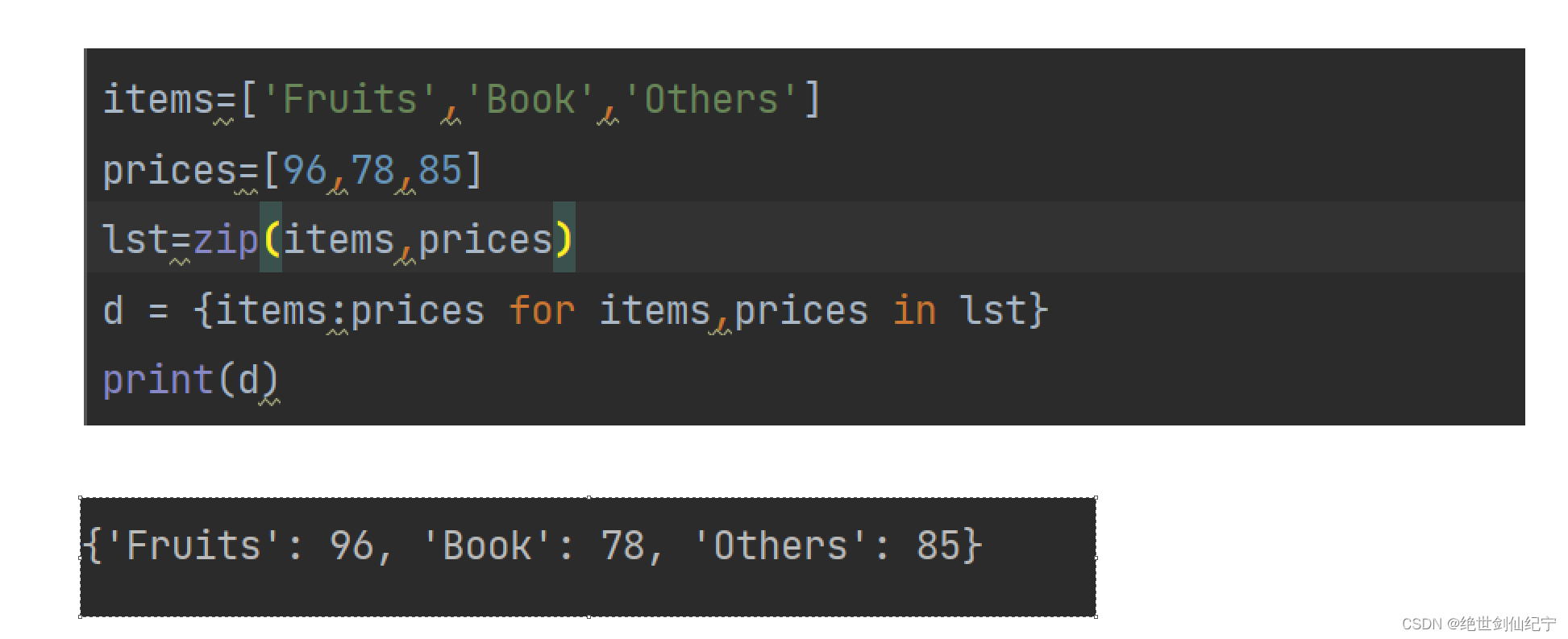
假設我們有兩個列表,先使用 zip 函數將對應元素打包為元組再返回
items=['Fruits','Book','Others']
prices=[96,78,85]
lst=zip(items,prices)
再使用字典生成式生成一個鍵值對應的字典
d = {items:prices for items,prices in lst}
5.6.2 列表生成式
內置函數range():range函數是一個內置函數,用于生成一個整數序列。range函數有三種形式:
-
range(stop) 生成一個從0開始到stop-1的整數序列,默認步長為1。
-
range(start, stop) 生成一個從start開始到stop-1的整數序列,默認步長為1。
-
range(start, stop, step) 生成一個從start開始到stop-1的整數序列,步長為step。
例如,range(5)將生成序列(0, 1, 2, 3, 4),range(2, 7)將生成序列(2, 3, 4, 5, 6),range(1, 10, 2)將生成序列(1, 3, 5, 7, 9)。
range函數一般被用在循環語句中,如for循環,來遍歷一個序列或執行指定次數的循環。
5.6.3 集合生成式
集合生成式的基本語法為:
{expression for item in iterable}
expression通常是某個變量或表達式,item是可迭代對象中的元素,iterable是可迭代對象,例如列表、元組、字典等。
例如:
nums = [1, 2, 3, 4, 5]
squares = {x*x for x in nums}
print(squares)
集合表達式也支持添加條件表達式,例如:
nums = [1, 2, 3, 4, 5]
squares = {x*x for x in nums if x > 2}
print(squares)
添加條件 x>2 后,只有當x.2時,才進行迭代生成集合表達式。
5.7 切片
字符串、列表、元組等有序數據結構中支持切片操作,切片可以獲取這些有序數據結構的子序列。切片操作不會改變原序列,它會返回一個新序列,包含指定范圍的元素。
切片語法:
string=str[start:stop:step]
start為切片的起始位置,stop為切片的結束位置(不包括該位置對應的元素),step為切片的步長。如果省略start,則默認為0;如果省略stop,則默認為序列的長度;如果省略step,則默認為1。
6.函數——新瓶裝舊酒
同C語言一樣,在 Python 中,函數是一種可重用的代碼塊,用于執行某些特定的任務。函數可以帶有參數或不帶參數,也可以返回值或不返回值。C語言函數詳解
函數定義的一般語法:
def add_numbers(num1, num2):"""This function adds two numbers."""result = num1 + num2return result
- def:定義函數的關鍵字;
- function_name:函數名稱,應以字母或下劃線開頭;
- parameters:函數參數,可以是一個或多個,也可以為空;
- docstring:函數文檔字符串,對函數的功能進行描述,可選;
- statements:函數體,函數需要執行的代碼語句。
下面用python實現一個簡易的計算器,幫助大家更好的理解函數
# 加法def add(self, x, y):return x + y# 減法def subtract(self, x, y):return x - y# 乘法def multiply(self, x, y):return x * y# 除法def divide(self, x, y):if y == 0:return "除數不能為0"return x / y
# 獲取用戶輸入
print("請選擇運算:")
print("1、加法")
print("2、減法")
print("3、乘法")
print("4、除法")
choice = input("請輸入需要進行的運算符號(1/2/3/4): ")
num1 = int(input("請輸入第一個數字: "))
num2 = int(input("請輸入第二個數字: "))
# 執行計算,傳遞兩個參數 num1和num2
if choice == '1':print(num1,"+",num2,"=", add(num1,num2))
elif choice == '2':print(num1,"-",num2,"=",subtract(num1,num2))
elif choice == '3':print(num1,"*",num2,"=", multiply(num1,num2))
elif choice == '4':print(num1,"/",num2,"=",divide(num1,num2))
else:print("請輸入正確的選項")
Python函數傳參的特點如下:
- 位置參數:按照形參定義位置傳遞的參數;
- 關鍵字參數:按照形參名稱傳遞的參數;
- 默認參數:在函數定義時給形參指定默認值,如果沒有傳入對應的實參,則使用默認值;
- 可變參數:*args,用來傳遞任意個參數,以元組的形式傳遞;
- 關鍵字可變參數:**kwargs,用來傳遞任意個關鍵字參數,以字典的形式傳遞。
位置實參:和C語言函數傳參的規則相同,實參和形參一一對應
 將10傳給形參a,20傳給形參b
將10傳給形參a,20傳給形參b
關鍵字實參
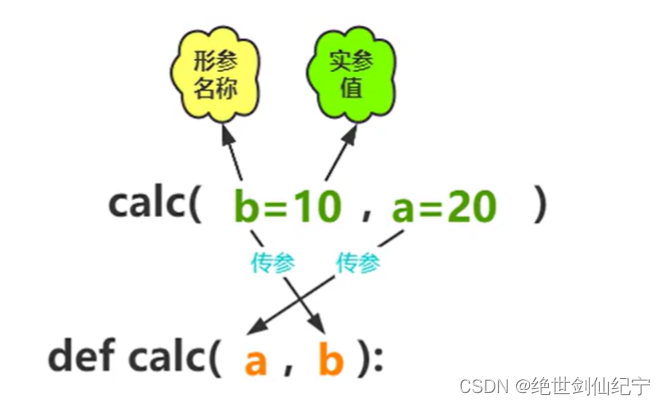 根據形參名進行實參傳
根據形參名進行實參傳
關鍵字實參的傳參規則是,先在形參里找實參關鍵字,將找到的實參傳遞給對應形參,剩余的則進行依次傳參。
可變參數
將形參定義為 *args,可接受任意個實參傳遞,結果為一個元組。
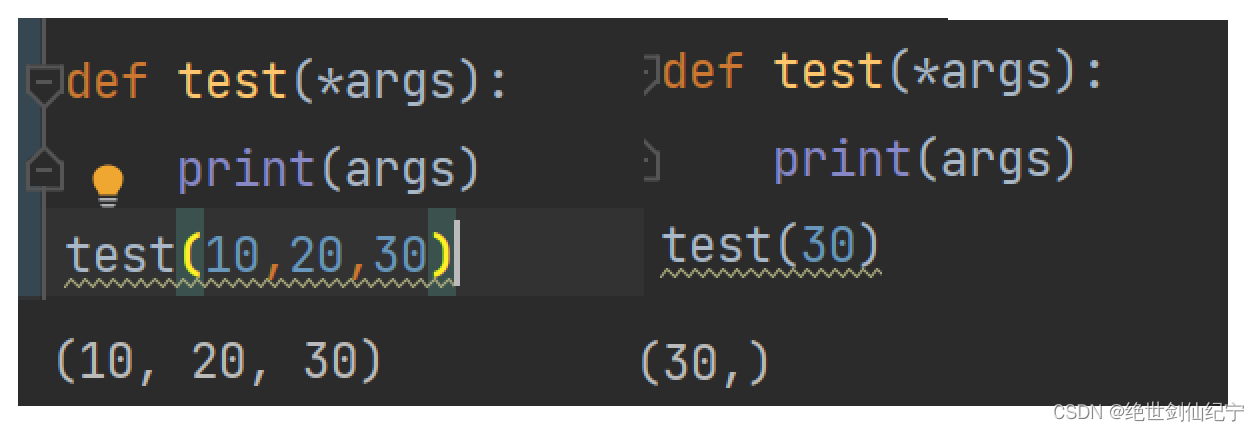
關鍵字可變實參
將形參定義為**args,可接受任意個關鍵字實參,結果為一個字典。

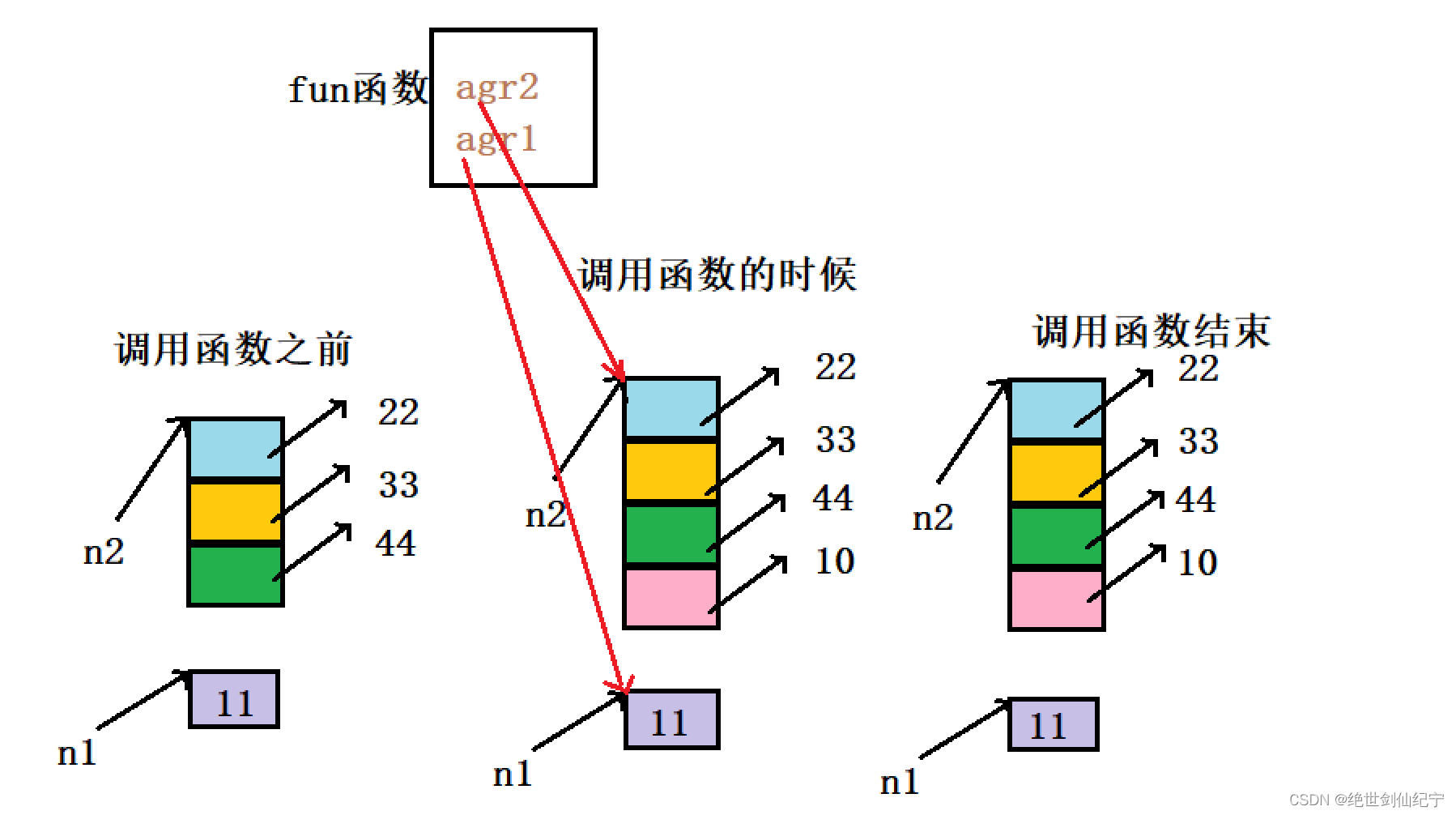
函數傳參的內存圖
例如下面的代碼
def fun(arg1,arg2):print("agr1=",arg1,"agr2=",arg2)arg1=100arg2.append(10)print("agr1=",arg1,"agr2=",arg2)
n1=10
n2=[22,33,44]
print("n1=",n1,"n2=",n2)
fun(n1,n2)
print("n1=",n1,"n2=",n2)
運行結果:

說明同C語言一樣,C中形參是實參的一份臨時拷貝,對實參的改變不影響實參。在python程序中,實參是臨時定義的一個與實參指向相同的變量,改變形參的指向不能改變實參的指向,但在形參指向的首地址后面添加或刪除數據是可以的起到改變實參值的作用的,因為實參也是指向這塊內存的首地址,但絕對改變不了實參的指向。







:區別詳解)





“安全認證”的.dll從何而來?)

)

)

