👨?🎓作者簡介:一位即將上大四,正專攻機器學習的保研er
🌌上期文章:機器學習&&深度學習——從編碼器-解碼器架構到seq2seq(機器翻譯)
📚訂閱專欄:機器學習&&深度學習
希望文章對你們有所幫助
在理解了seq2seq以后,開始用它來實現一個機器翻譯的模型。我們先要進行機器翻譯的數據集的選擇以及處理,在之后將正式使用seq2seq來進行訓練。
seq2seq實現機器翻譯
- 機器翻譯與數據集
- 下載和預處理數據集
- 詞元化
- 詞表
- 加載數據集
- 訓練模型
機器翻譯與數據集
語言模型是自然語言處理的關鍵,而機器翻譯是語言模型最成功的基準測試。因為機器翻譯正是將輸入序列轉換成輸出序列的序列轉換模型的核心問題。
機器翻譯指的是將序列從一種語言自動翻譯成另一種語言。我們這里的關注點是神經網絡機器翻譯方法,強調的是端到端的學習。機器翻譯的數據集是由源語言和目標語言的文本序列對組成的。我們需要將預處理后的數據加載到小批量中用于訓練。
import os
import torch
from d2l import torch as d2l
下載和預處理數據集
下載一個“英-法”數據集,數據集中每一行都是都是制表符分隔的文本序列對,序列對由英文文本序列和翻譯后的法語文本序列組成(每個文本序列可以是一個句子, 也可以是包含多個句子的一個段落)。在這個將英語翻譯成法語的機器翻譯問題中, 英語是源語言,法語是目標語言。
#@save
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip','94646ad1522d915e7b0f9296181140edcf86a4f5')#@save
def read_data_nmt():"""載入“英語-法語”數據集"""data_dir = d2l.download_extract('fra-eng')with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding='utf-8') as f:return f.read()raw_text = read_data_nmt()
我們可以打印查看一下:
print(raw_text[:75])
輸出結果:
Go. Va !
Hi. Salut !
Run! Cours?!
Run! Courez?!
Who? Qui ?
Wow! ?a alors?!
下載數據集后,原始文本數據需要經過幾個預處理步驟。例如,我們用空格代替不間斷空格,使用小寫字母替換大寫字母,并在單詞和標點符號之間插入空格。
#@save
def preprocess_nmt(text):"""預處理“英語-法語”數據集"""def no_space(char, prev_char):return char in set(',.!?') and prev_char != ' '# 使用空格替換不間斷空格# 使用小寫字母替換大寫字母text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()# 在單詞和標點符號之間插入空格out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else charfor i, char in enumerate(text)]return ''.join(out)text = preprocess_nmt(raw_text)
可以輸出查看:
print(text[:80])
運行結果:
go . va !
hi . salut !
run ! cours !
run ! courez !
who ? qui ?
wow ! ?a alors !
詞元化
在機器翻譯中,我們更喜歡單詞級詞元化。下面的tokenize_nmt函數對前num_examples個文本序列對進行詞元,其中每個詞元要么是一個詞,要么是一個標點符號。
此數返回兩個詞元列表:source和target,source[i]是源語言(也就是這里的英語)第i個文本序列的詞元列表,target[i]是目標語言(這里是法語)第i個文本序列的詞元列表。
#@save
def tokenize_nmt(text, num_examples=None):"""詞元化“英語-法語”數據數據集"""source, target = [], []for i, line in enumerate(text.split('\n')):if num_examples and i > num_examples:breakparts = line.split('\t')if len(parts) == 2:source.append(parts[0].split(' '))target.append(parts[1].split(' '))return source, targetsource, target = tokenize_nmt(text)
可以輸出查看驗證:
print(source[:6], target[:6])
運行結果:
[[‘go’, ‘.’], [‘hi’, ‘.’], [‘run’, ‘!’], [‘run’, ‘!’], [‘who’, ‘?’], [‘wow’, ‘!’]]
[[‘va’, ‘!’], [‘salut’, ‘!’], [‘cours’, ‘!’], [‘courez’, ‘!’], [‘qui’, ‘?’], [‘?a’, ‘alors’, ‘!’]]
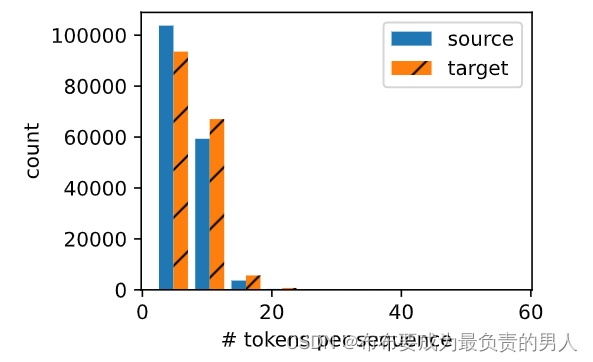
我們可以繪制每個文本序列所包含的詞元數量的直方圖,在這個數據集中,大多數文本序列的詞元數量少于20個。
#@save
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):"""繪制列表長度對的直方圖"""d2l.set_figsize()_, _, patches = d2l.plt.hist([[len(l) for l in xlist], [len(l) for l in ylist]])d2l.plt.xlabel(xlabel)d2l.plt.ylabel(ylabel)for patch in patches[1].patches:patch.set_hatch('/')d2l.plt.legend(legend)show_list_len_pair_hist(['source', 'target'], '# tokens per sequence','count', source, target)
d2l.plt.show()
詞表
由于機器翻譯數據集由語言對組成,因此我們可以分別為源語言和目標語言構建兩個詞表。
使用單詞級詞元化時,詞表大小將明顯大于使用字符級詞元化時的詞表大小。為了緩解這一問題,我們做一個處理方法,將一些低頻率的詞元視為相同的未知詞元unk,在這里我們將出現次數少于2次視為低頻率詞元。
此外,我們還指定了額外的特定詞元,例如在小批量時用于將序列填充到相同長度的填充詞元pad,以及序列的開始詞元bos和結束詞元eos。
例如:
src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])
print(len(src_vocab))
輸出結果:
10012
加載數據集
在之前,我們做過語言模型的處理,而語言模型中的序列樣本都有一個固定的長度,這個固定長度由num_steps(時間步數或詞元數量)來決定的。而在機器翻譯中,每個樣本都是由源和目標組成的文本序列對,其中的每個文本序列可能具有不同的長度。
為了提高計算效率,我們仍然可以通過截斷和填充方式實現一次只處理一個小批量的文本序列。假設同一個小批量中的每個序列都應該具有相同的長度num_steps。那么若詞元數目數目少于num_steps,我們就在末位填充pad詞元;否則我們就截斷詞元取前num_steps個。只要每個文本序列具有相同的長度,就方便以相同形狀的小批量進行加載。
我們定義一個函數來實現對文本序列的截斷或填充。
#@save
def truncate_pad(line, num_steps, padding_token):"""截斷或填充文本序列"""if len(line) > num_steps:return line[:num_steps] # 截斷return line + [padding_token] * (num_steps - len(line)) # 填充
驗證一下:
print(truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>']))
運行結果:
[47, 4, 1, 1, 1, 1, 1, 1, 1, 1]
可以分析一下這個運行結果,source[0]里面有兩個詞元,按照詞元的出現頻率來進行排序,分別是第47和第4,此時我們需要10個詞元,那就需要填充,理所當然要填充最常見的那種詞,造成的概率是最小的,所以其對應著詞表中的都是頻率最高的。
如果語料corpus、詞表這類概念忘記了,可以看我之前的這篇文章:
機器學習&&深度學習——文本預處理
現在我們定義一個函數,可以將文本序列轉換成小批量數據集用于訓練。我們將eos詞元添加到所有序列的末尾,用于表示序列的結束。當模型通過一個詞元接一個詞元地生成序列進行預測時,生成的eos詞元說明完成了序列的輸出工作。此外,我們還記錄了每個文本序列的初始長度(排除了填充詞元的長度),后序會用到。
#@save
def build_array_nmt(lines, vocab, num_steps):"""將機器翻譯的文本序列轉換成小批量"""lines = [vocab[l] for l in lines]lines = [l + [vocab['<eos>']] for l in lines]array = torch.tensor([truncate_pad(l, num_steps, vocab['<pad>']) for l in lines])valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1) # 統計原始長度return array, valid_len
訓練模型
接下來就可以定義load_data_nmt函數來返回數據迭代器,以及源語言和目標語言的兩種詞表:
#@save
def load_data_nmt(batch_size, num_steps, num_examples=600):"""返回翻譯數據集的迭代器和詞表"""text = preprocess_nmt(read_data_nmt())source, target = tokenize_nmt(text, num_examples)src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])tgt_vocab = d2l.Vocab(target, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)data_iter = d2l.load_array(data_arrays, batch_size)return data_iter, src_vocab, tgt_vocab
我們可以讀出數據集中的第一個小批量數據:
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for X, X_valid_len, Y, Y_valid_len in train_iter:print('X:', X.type(torch.int32))print('X的有效長度:', X_valid_len)print('Y:', Y.type(torch.int32))print('Y的有效長度:', Y_valid_len)break
運行結果:
X: tensor([[ 17, 119, 4, 3, 1, 1, 1, 1],
[ 6, 124, 4, 3, 1, 1, 1, 1]], dtype=torch.int32)
X的有效長度: tensor([4, 4])
Y: tensor([[11, 0, 4, 3, 1, 1, 1, 1],
[ 6, 27, 7, 0, 4, 3, 1, 1]], dtype=torch.int32)
Y的有效長度: tensor([4, 6])

)








)





)
)

