一、概述
HDFS是Hadoop的分布式文件系統(Hadoop Distributed File System),實現大規模數據可靠的分布式讀寫。HDFS針對的使用場景是數據讀寫具有“一次寫,多次讀”的特征,而數據“寫”操作是順序寫,也就是在文件創建時的寫入或者在現有文件之后的添加操作。HDFS保證一個文件在一個時刻只被一個調用者執行寫操作,而可以被多個調用者執行讀操作。
二、HDFS結構
HDFS包含主、備NameNode和多個DataNode,如下圖所示。
HDFS是一個Master/Slave的架構,在Master上運行NameNode,而在每一個Slave上運行DataNode,ZKFC需要和NameNode一起運行。
NameNode和DataNode之間的通信都是建立在TCP/IP的基礎之上的。NameNode、DataNode、ZKFC和JournalNode能部署在運行Linux的服務器上。
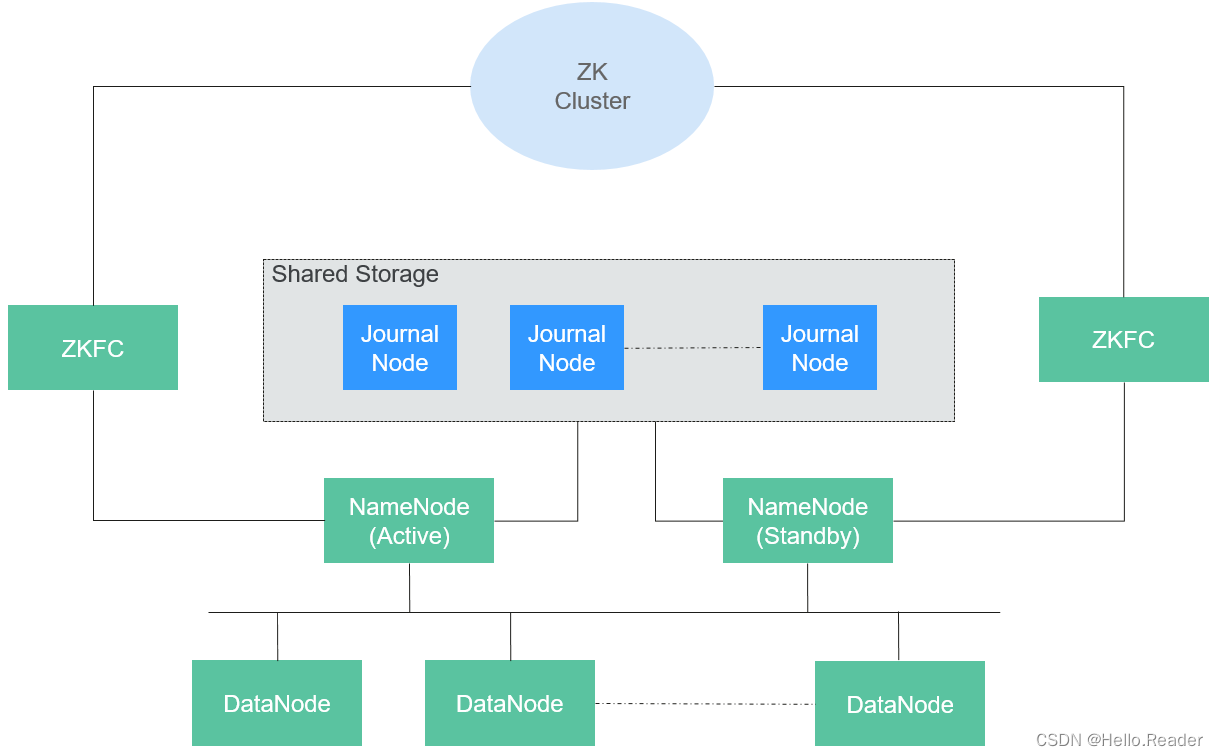
| 名稱 | 描述 |
|---|---|
| NameNode | 用于管理文件系統的命名空間、目錄結構、元數據信息以及提供備份機制等,分為:1. Active NameNode:管理文件系統的命名空間、維護文件系統的目錄結構樹以及元數據信息;記錄寫入的每個“數據塊”與其歸屬文件的對應關系。2. Standby NameNode:與Active NameNode中的數據保持同步;隨時準備在Active NameNode出現異常時接管其服務。3.Observer NameNode:與Active NameNode中的數據保持同步,處理來自客戶端的讀請求。 |
| DataNode | 用于存儲每個文件的“數據塊”數據,并且會周期性地向NameNode報告該DataNode的數據存放情況。 |
| JournalNode | HA集群下,用于同步主備NameNode之間的元數據信息。 |
| ZKFC | ZKFC是需要和NameNode一一對應的服務,即每個NameNode都需要部署ZKFC。它負責監控NameNode的狀態,并及時把狀態寫入ZooKeeper。ZKFC也有選擇誰作為Active NameNode的權利。 |
| ZK Cluster | ZooKeeper是一個協調服務,幫助ZKFC執行主NameNode的選舉。 |
| HttpFS gateway | HttpFS是個單獨無狀態的gateway進程,對外提供webHDFS接口,對HDFS使用FileSystem接口對接。可用于不同Hadoop版本間的數據傳輸,及用于訪問在防火墻后的HDFS(HttpFS用作gateway)。 |
HttpFS是個單獨無狀態的gateway進程,對外提供webHDFS接口,對HDFS使用FileSystem接口對接。可用于不同Hadoop版本間的數據傳輸,及用于訪問在防火墻后的HDFS(HttpFS用作gateway)。
三、HDFS原理
使用HDFS的副本機制來保證數據的可靠性,HDFS中每保存一個文件則自動生成1個備份文件,即共2個副本。HDFS副本數可通過“dfs.replication”參數查詢。
- 當集群中Core節點規格選擇為非本地盤(hdd)時,若集群中只有一個Core節點,則HDFS默認副本數為1。若集群中Core節點數大于等于2,則HDFS默認副本數為2。
- 當集群中Core節點規格選擇為本地盤(hdd)時,若集群中只有一個Core節點,則HDFS默認副本數為1。若集群中有兩個Core節點,則HDFS默認副本數為2。若集群中Core節點數大于等于3,則HDFS默認副本數為3。
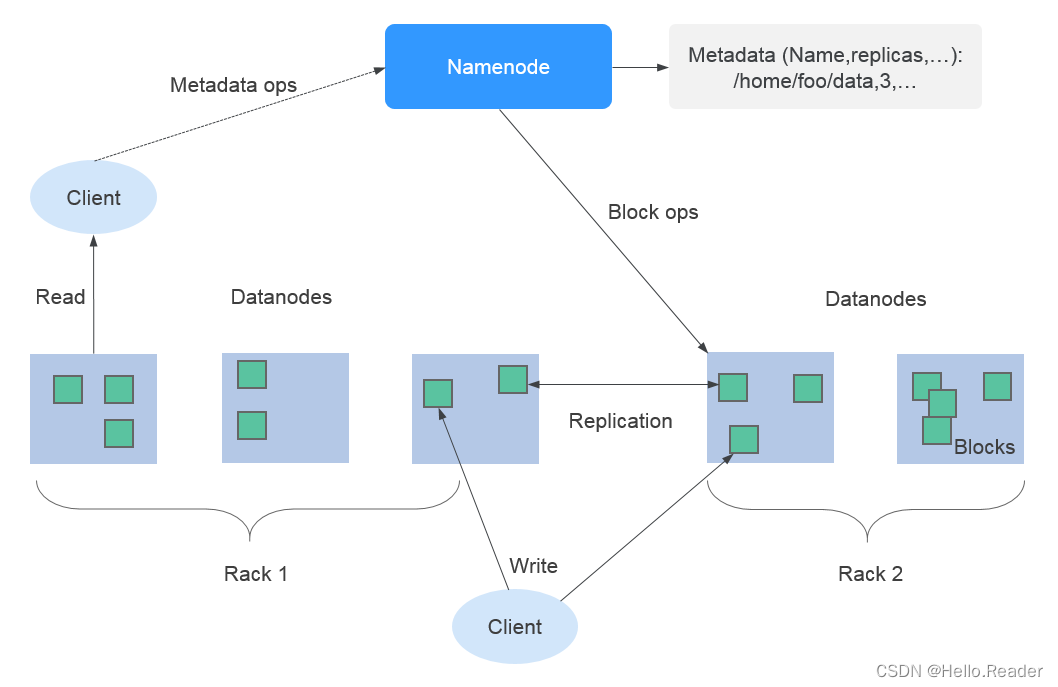
HDFS組件支持以下部分特性:
- HDFS組件支持糾刪碼,使得數據冗余減少到50%,且可靠性更高,并引入條帶化的塊存儲結構,最大化的利用現有集群單節點多磁盤的能力,使得數據寫入性能在引入編碼過程后,仍和原來多副本冗余的性能接近。
- 支持HDFS組件上節點均衡調度和單節點內的磁盤均衡調度,有助于擴容節點或擴容磁盤后的HDFS存儲性能提升。
關于Hadoop的架構和詳細原理介紹,請參見:http://hadoop.apache.org/。
四、HDFS HA方案背景
在Hadoop2.0.0之前,HDFS集群中存在單點故障問題。由于每個集群只有一個NameNode,如果NameNode所在機器發生故障,將導致HDFS集群無法使用,除非NameNode重啟或者在另一臺機器上啟動。這在兩個方面影響了HDFS的整體可用性:
- 當異常情況發生時,如機器崩潰,集群將不可用,除非重新啟動NameNode。
- 計劃性的維護工作,如軟硬件升級等,將導致集群停止工作。
針對以上問題,HDFS高可用性方案通過自動或手動(可配置)的方式,在一個集群中為NameNode啟動一個熱替換的NameNode備份。當一臺機器故障時,可以迅速地自動進行NameNode主備切換。或者當主NameNode節點需要進行維護時,通過集群管理員控制,可以手動進行NameNode主備切換,從而保證集群在維護期間的可用性。
有關HDFS自動故障轉移功能,請參閱:
https://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoophdfs/HDFSHighAvailabilityWithQJM.html#Automatic_Failover
五、HDFS HA實現方案
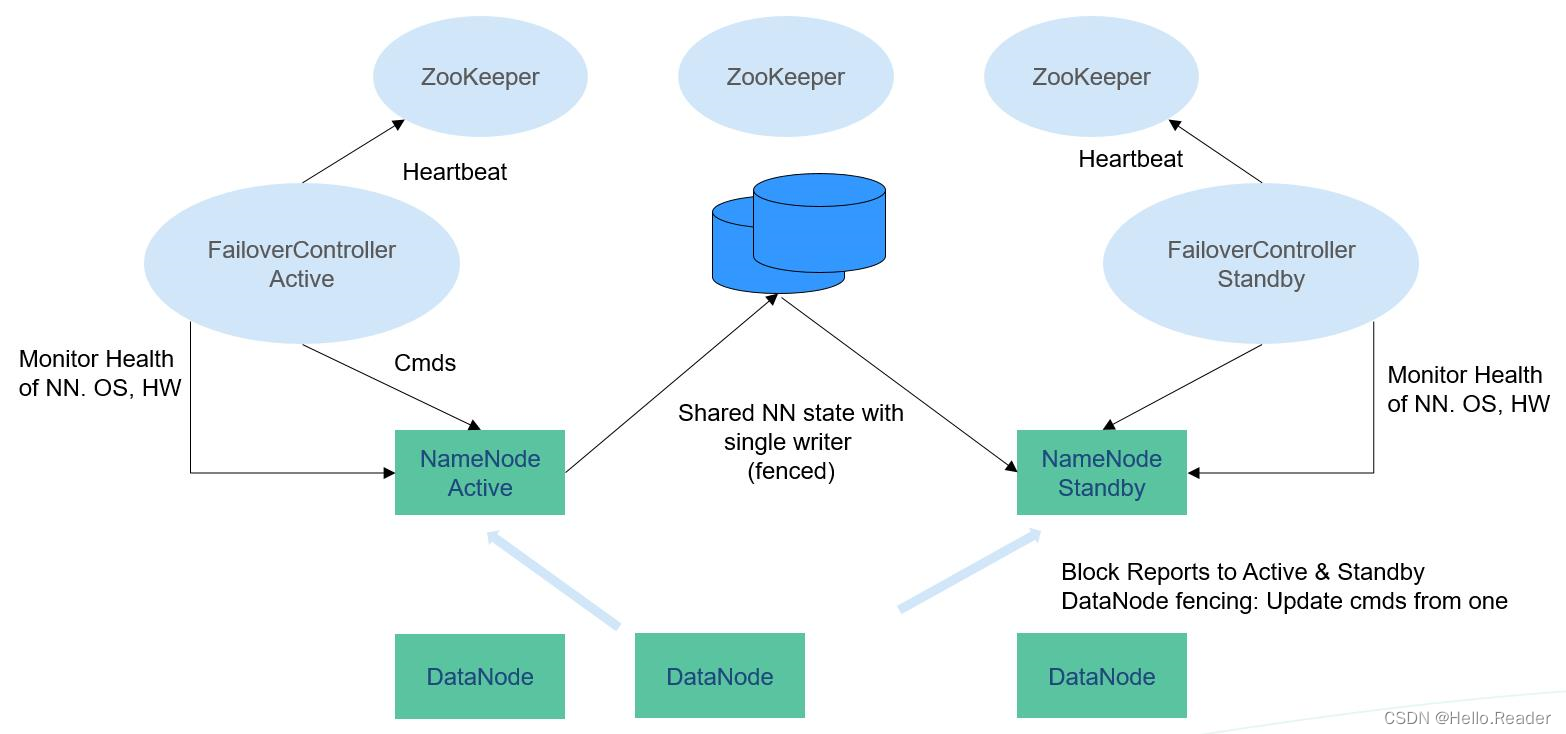
在一個典型的HA集群中(如上圖所示),需要把兩個NameNodes配置在兩臺獨立的機器上。在任何一個時間點,只有一個NameNode處于Active狀態,另一個處于Standby狀態。Active節點負責處理所有客戶端操作,Standby節點時刻保持與Active節點同步的狀態以便在必要時進行快速主備切換。
為保持Active和Standby節點的數據一致性,兩個節點都要與一組稱為JournalNode的節點通信。當Active對文件系統元數據進行修改時,會將其修改日志保存到大多數的JournalNode節點中,例如有3個JournalNode,則日志會保存在至少2個節點中。Standby節點監控JournalNodes的變化,并同步來自Active節點的修改。根據修改日志,Standby節點將變動應用到本地文件系統元數據中。一旦發生故障轉移,Standby節點能夠確保與Active節點的狀態是一致的。這保證了文件系統元數據在故障轉移時在Active和Standby之間是完全同步的。
為保證故障轉移快速進行,Standby需要時刻保持最新的塊信息,為此DataNodes同時向兩個NameNodes發送塊信息和心跳。
對一個HA集群,保證任何時刻只有一個NameNode是Active狀態至關重要。否則,命名空間會分為兩部分,有數據丟失和產生其他錯誤的風險。為保證這個屬性,防止“split-brain”問題的產生,JournalNodes在任何時刻都只允許一個NameNode寫入。在故障轉移時,將變為Active狀態的NameNode獲得寫入JournalNodes的權限,這會有效防止其他NameNode的Active狀態,使得切換安全進行。
關于HDFS高可用性方案的更多信息,可參考如下鏈接:
https://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoophdfs/HDFSHighAvailabilityWithQJM.html
六、HDFS和HBase的關系
HDFS是Apache的Hadoop項目的子項目,HBase利用Hadoop HDFS作為其文件存儲系統。HBase位于結構化存儲層,Hadoop HDFS為HBase提供了高可靠性的底層存儲支持。除了HBase產生的一些日志文件,HBase中的所有數據文件都可以存儲在Hadoop HDFS文件系統上。
七、HDFS和MapReduce的關系
- HDFS是Hadoop分布式文件系統,具有高容錯和高吞吐量的特性,可以部署在價格低廉的硬件上,存儲應用程序的數據,適合有超大數據集的應用程序。
- 而MapReduce是一種編程模型,用于大數據集(大于1TB)的并行運算。在MapReduce程序中計算的數據可以來自多個數據源,如Local FileSystem、HDFS、數據庫等。最常用的是HDFS,可以利用HDFS的高吞吐性能讀取大規模的數據進行計算。同時在計算完成后,也可以將數據存儲到HDFS。
八、HDFS和Spark的關系
通常,Spark中計算的數據可以來自多個數據源,如Local File、HDFS等。最常用的是HDFS,用戶可以一次讀取大規模的數據進行并行計算。在計算完成后,也可以將數據存儲到HDFS。
分解來看,Spark分成控制端(Driver)和執行端(Executor)。控制端負責任務調度,執行端負責任務執行。
讀取文件的過程如下圖所示。
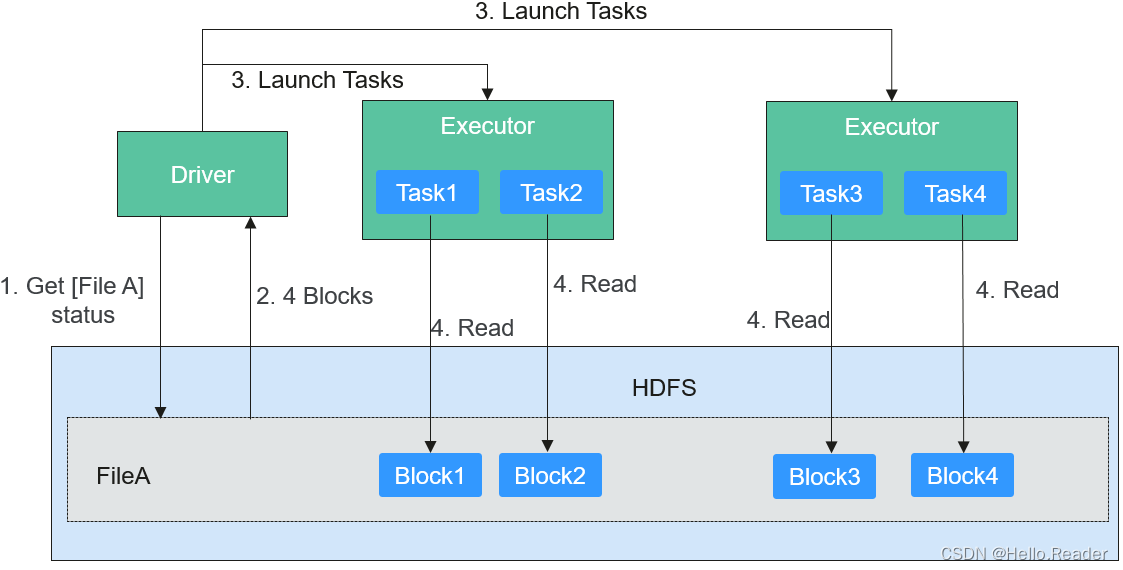
讀取文件步驟的詳細描述如下所示:
- Driver與HDFS交互獲取File A的文件信息。
- HDFS返回該文件具體的Block信息。
- Driver根據具體的Block數據量,決定一個并行度,創建多個Task去讀取這些文件Block。
- 在Executor端執行Task并讀取具體的Block,作為RDD(彈性分布數據集)的一部分。
寫入文件的過程如下圖所示。
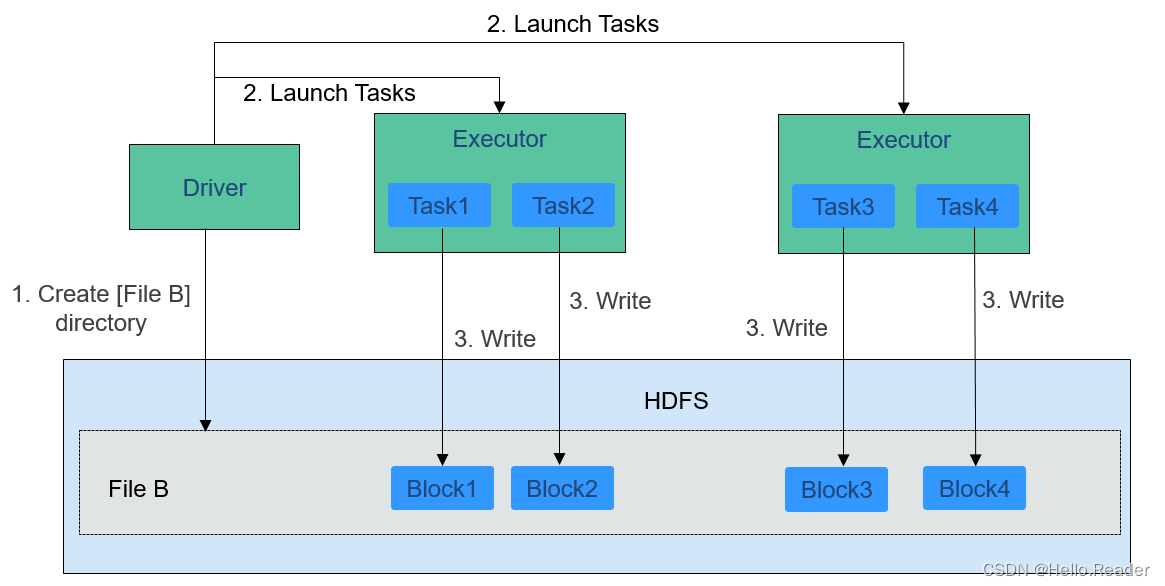
HDFS文件寫入的詳細步驟如下所示:
- Driver創建要寫入文件的目錄。
- 根據RDD分區分塊情況,計算出寫數據的Task數,并下發這些任務到Executor。
- Executor執行這些Task,將具體RDD的數據寫入到步驟1創建的目錄下。
九、HDFS和ZooKeeper的關系
ZooKeeper與HDFS的關系如下圖所示
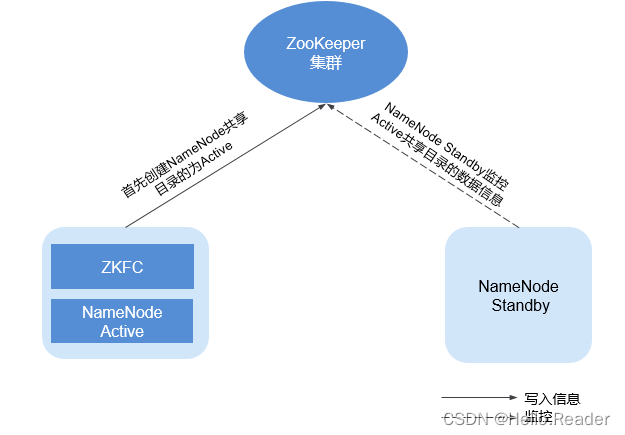
ZKFC(ZKFailoverController)作為一個ZooKeeper集群的客戶端,用來監控NameNode的狀態信息。ZKFC進程僅在部署了NameNode的節點中存在。HDFS NameNode的Active和Standby節點均部署有zkfc進程。
- HDFS NameNode的ZKFC連接到ZooKeeper,把主機名等信息保存到ZooKeeper中,即“/hadoop-ha”下的znode目錄里。先創建znode目錄的NameNode節點為主節點,另一個為備節點。HDFS NameNode Standby通過ZooKeeper定時讀取NameNode信息。
- 當主節點進程異常結束時,HDFS NameNode Standby通過ZooKeeper感知“/hadoop-ha”目錄下發生了變化,NameNode會進行主備切換。


:區別詳解)





“安全認證”的.dll從何而來?)

)

)






