一.前言
近期, ChatGLM-6B 的第二代版本ChatGLM2-6B已經正式發布,引入了如下新特性:
①. 基座模型升級,性能更強大,在中文C-Eval榜單中,以51.7分位列第6;
②. 支持8K-32k的上下文;
③. 推理性能提升了42%;
④. 對學術研究完全開放,允許申請商用授權。
目前大多數部署方案采用的是fastapi+uvicorn+transformers,這種方式適合快速運行一些demo,在生產環境中使用還是推薦使用專門的深度學習推理服務框架,如Triton。本文將介紹我利用集團9n-triton工具部署ChatGLM2-6B過程中踩過的一些坑,希望可以為有部署需求的同學提供一些幫助。
二.硬件要求
部署的硬件要求可以參考如下:
| 量化等級 | 編碼 2048 長度的最小顯存 | 生成 8192 長度的最小顯存 |
|---|---|---|
| FP16 / BF16 | 13.1 GB | 12.8 GB |
| INT8 | 8.2 GB | 8.1 GB |
| INT4 | 5.5 GB | 5.1 GB |
我部署了2個pod,每個pod的資源:CPU(4核)、內存(30G)、1張P40顯卡(顯存24G)。
三.部署實踐
Triton默認支持的PyTorch模型格式為TorchScript,由于ChatGLM2-6B模型轉換成TorchScript格式會報錯,本文將以Python Backend的方式進行部署。
1. 模型目錄結構
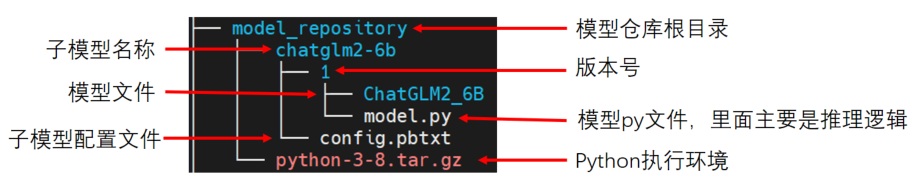
9N-Triton使用集成模型,如上圖所示模型倉庫(model_repository), 它內部可以包含一個或多個子模型(如chatglm2-6b)。下面對各個部分進行展開介紹:
2. python執行環境
該部分為模型推理時需要的相關python依賴包,可以使用conda-pack將conda虛擬環境打包,如python-3-8.tar.gz。如對打包conda環境不熟悉的,可以參考 https://conda.github.io/conda-pack/。然后在config.pbtxt中配置執行環境路徑:
parameters: {key: "EXECUTION_ENV_PATH",value: {string_value: "$$TRITON_MODEL_DIRECTORY/../python-3-8.tar.gz"}
}在當前示例中,$ T R I T O N _ M O D E L _ D I R E C T O R Y = " TRITON\_MODEL\_DIRECTORY=" TRITON_MODEL_DIRECTORY="pwd/model_repository/chatglm2-6b"。
注意:當前python執行環境為所有子模型共享,如果想給不同子模型指定不同的執行環境,則應該將tar.gz文件放在子模型目錄下,如下所示:
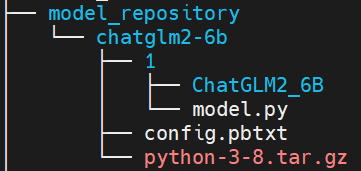
同時,在config.pbtxt中配置執行環境路徑如下:
parameters: {key: "EXECUTION_ENV_PATH",value: {string_value: "$$TRITON_MODEL_DIRECTORY/python-3-8.tar.gz"}
}3. 模型配置文件
模型倉庫庫中的每個模型都必須包含一個模型配置文件config.pbtxt,用于指定平臺和或后端屬性、max_batch_size 屬性以及模型的輸入和輸出張量等。ChatGLM2-6B的配置文件可以參考如下:
name: "chatglm2-6b" // 必填,模型名,需與該子模型的文件夾名字相同
backend: "python" // 必填,模型所使用的后端引擎max_batch_size: 0 // 模型每次請求最大的批數據量,張量shape由max_batch_size和dims組合指定,對于 max_batch_size 大于 0 的模型,完整形狀形成為 [ -1 ] + dims。 對于 max_batch_size 等于 0 的模型,完整形狀形成為 dims。
input [ // 必填,輸入定義{name: "prompt" //必填,名稱data_type: TYPE_STRING //必填,數據類型dims: [ -1 ] //必填,數據維度,-1 表示可變維度},{name: "history"data_type: TYPE_STRINGdims: [ -1 ]},{name: "temperature"data_type: TYPE_STRINGdims: [ -1 ]},{name: "max_token"data_type: TYPE_STRINGdims: [ -1 ]},{name: "history_len"data_type: TYPE_STRINGdims: [ -1 ]}
]
output [ //必填,輸出定義{name: "response"data_type: TYPE_STRINGdims: [ -1 ]},{name: "history"data_type: TYPE_STRINGdims: [ -1 ]}
]
parameters: { //指定python執行環境key: "EXECUTION_ENV_PATH",value: {string_value: "$$TRITON_MODEL_DIRECTORY/../python-3-8.tar.gz"}
}
instance_group [ //模型實例組{ count: 1 //實例數量kind: KIND_GPU //實例類型gpus: [ 0 ] //指定實例可用的GPU索引}
]其中必填項為最小模型配置,模型配置文件更多信息可以參考: https://github.com/triton-inference-server/server/blob/r22.04/docs/model_configuration.md
4. 自定義python backend
主要需要實現model.py 中提供的三個接口:
①. initialize: 初始化該Python模型時會進行調用,一般執行獲取輸出信息及創建模型的操作
②. execute: python模型接收請求時的執行函數;
③. finalize: 刪除模型時會進行調用;
如果有 n 個模型實例,那么會調用 n 次initialize 和 finalize這兩個函數。
ChatGLM2-6B的model.py文件可以參考如下:
import os
# 設置顯存空閑block最大分割閾值
os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'max_split_size_mb:32'
# 設置work目錄os.environ['TRANSFORMERS_CACHE'] = os.path.dirname(os.path.abspath(__file__))+"/work/"
os.environ['HF_MODULES_CACHE'] = os.path.dirname(os.path.abspath(__file__))+"/work/"import json# triton_python_backend_utils is available in every Triton Python model. You
# need to use this module to create inference requests and responses. It also
# contains some utility functions for extracting information from model_config
# and converting Triton input/output types to numpy types.
import triton_python_backend_utils as pb_utils
import sys
import gc
import time
import logging
import torch
from transformers import AutoTokenizer, AutoModel
import numpy as npgc.collect()
torch.cuda.empty_cache()logging.basicConfig(format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s',level=logging.INFO)class TritonPythonModel:"""Your Python model must use the same class name. Every Python modelthat is created must have "TritonPythonModel" as the class name."""def initialize(self, args):"""`initialize` is called only once when the model is being loaded.Implementing `initialize` function is optional. This function allowsthe model to intialize any state associated with this model.Parameters----------args : dictBoth keys and values are strings. The dictionary keys and values are:* model_config: A JSON string containing the model configuration* model_instance_kind: A string containing model instance kind* model_instance_device_id: A string containing model instance device ID* model_repository: Model repository path* model_version: Model version* model_name: Model name"""# You must parse model_config. JSON string is not parsed hereself.model_config = json.loads(args['model_config'])output_response_config = pb_utils.get_output_config_by_name(self.model_config, "response")output_history_config = pb_utils.get_output_config_by_name(self.model_config, "history")# Convert Triton types to numpy typesself.output_response_dtype = pb_utils.triton_string_to_numpy(output_response_config['data_type'])self.output_history_dtype = pb_utils.triton_string_to_numpy(output_history_config['data_type'])ChatGLM_path = os.path.dirname(os.path.abspath(__file__))+"/ChatGLM2_6B"self.tokenizer = AutoTokenizer.from_pretrained(ChatGLM_path, trust_remote_code=True)model = AutoModel.from_pretrained(ChatGLM_path,torch_dtype=torch.bfloat16,trust_remote_code=True).half().cuda()self.model = model.eval()logging.info("model init success")def execute(self, requests):"""`execute` MUST be implemented in every Python model. `execute`function receives a list of pb_utils.InferenceRequest as the onlyargument. This function is called when an inference request is madefor this model. Depending on the batching configuration (e.g. DynamicBatching) used, `requests` may contain multiple requests. EveryPython model, must create one pb_utils.InferenceResponse for everypb_utils.InferenceRequest in `requests`. If there is an error, you canset the error argument when creating a pb_utils.InferenceResponseParameters----------requests : listA list of pb_utils.InferenceRequestReturns-------listA list of pb_utils.InferenceResponse. The length of this list mustbe the same as `requests`"""output_response_dtype = self.output_response_dtypeoutput_history_dtype = self.output_history_dtype# output_dtype = self.output_dtyperesponses = []# Every Python backend must iterate over everyone of the requests# and create a pb_utils.InferenceResponse for each of them.for request in requests:prompt = pb_utils.get_input_tensor_by_name(request, "prompt").as_numpy()[0]prompt = prompt.decode('utf-8')history_origin = pb_utils.get_input_tensor_by_name(request, "history").as_numpy()if len(history_origin) > 0:history = np.array([item.decode('utf-8') for item in history_origin]).reshape((-1,2)).tolist()else:history = []temperature = pb_utils.get_input_tensor_by_name(request, "temperature").as_numpy()[0]temperature = float(temperature.decode('utf-8'))max_token = pb_utils.get_input_tensor_by_name(request, "max_token").as_numpy()[0]max_token = int(max_token.decode('utf-8'))history_len = pb_utils.get_input_tensor_by_name(request, "history_len").as_numpy()[0]history_len = int(history_len.decode('utf-8'))# 日志輸出傳入信息in_log_info = {"in_prompt":prompt,"in_history":history,"in_temperature":temperature,"in_max_token":max_token,"in_history_len":history_len}logging.info(in_log_info)response,history = self.model.chat(self.tokenizer,prompt,history=history[-history_len:] if history_len > 0 else [],max_length=max_token,temperature=temperature)# 日志輸出處理后的信息out_log_info = {"out_response":response,"out_history":history}logging.info(out_log_info)response = np.array(response)history = np.array(history)response_output_tensor = pb_utils.Tensor("response",response.astype(self.output_response_dtype))history_output_tensor = pb_utils.Tensor("history",history.astype(self.output_history_dtype))final_inference_response = pb_utils.InferenceResponse(output_tensors=[response_output_tensor,history_output_tensor])responses.append(final_inference_response)# Create InferenceResponse. You can set an error here in case# there was a problem with handling this inference request.# Below is an example of how you can set errors in inference# response:## pb_utils.InferenceResponse(# output_tensors=..., TritonError("An error occured"))# You should return a list of pb_utils.InferenceResponse. Length# of this list must match the length of `requests` list.return responsesdef finalize(self):"""`finalize` is called only once when the model is being unloaded.Implementing `finalize` function is OPTIONAL. This function allowsthe model to perform any necessary clean ups before exit."""print('Cleaning up...')5. 部署測試
① 選擇9n-triton-devel-gpu-v0.3鏡像創建notebook測試實例;
② 把模型放在/9n-triton-devel/model_repository目錄下,模型目錄結構參考3.1;
③ 進入/9n-triton-devel/server/目錄,拉取最新版本的bin并解壓:wget http://storage.jd.local/com.bamboo.server.product/7196560/9n_predictor_server.tgz
④ 修改/9n-triton-devel/server/start.sh 為如下:
mkdir logs
\rm -rf /9n-triton-devel/server/logs/*
\rm -rf /tmp/python_env_*
export LD_LIBRARY_PATH=/9n-triton-devel/server/lib/:$LD_LIBRARY_PATH
nohup ./bin/9n_predictor_server --flagfile=./conf/server.gflags 2>&1 >/dev/null &
sleep 2
pid=`ps x |grep "9n_predictor_server" | grep -v "grep" | grep -v "ldd" | grep -v "stat" | awk '{print $1}'`
echo $pid⑤ 運行 /9n-triton-devel/server/start.sh 腳本
⑥ 檢查服務啟動成功(ChatGLM2-6B模型啟動,差不多13分鐘左右)
方法1:查看8010端口是否啟動:netstat -natp | grep 8010
方法2:查看日志:cat /9n-triton-devel/server/logs/predictor_core.INFO
⑦ 編寫python grpc client訪問測試服務腳本,放于/9n-triton-devel/client/目錄下,訪問端口為8010,ip為127.0.0.1,可以參考如下:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import sys
sys.path.append('./base')
from multi_backend_client import MultiBackendClient
import triton_python_backend_utils as python_backend_utils
import multi_backend_message_pb2import time
import argparse
import io
import os
import numpy as np
import json
import structdef print_result(response, batch_size ):print("outputs len:" + str(len(response.outputs)))if (response.error_code == 0):print("response : ", response)print(f'res shape: {response.outputs[0].shape}')res = python_backend_utils.deserialize_bytes_tensor(response.raw_output_contents[0])for i in res:print(i.decode())print(f'history shape: {response.outputs[1].shape}')history = python_backend_utils.deserialize_bytes_tensor(response.raw_output_contents[1])for i in history:print(i.decode())def send_one_request(sender, request_pb, batch_size):succ, response = sender.send_req(request_pb)if succ:print_result(response, batch_size)else:print('send_one_request fail ', response)def send_request(ip, port, temperature, max_token, history_len, batch_size=1, send_cnt=1):request_sender = MultiBackendClient(ip, port)request = multi_backend_message_pb2.ModelInferRequest()request.model_name = "chatglm2-6b"# 輸入占位input0 = multi_backend_message_pb2.ModelInferRequest().InferInputTensor()input0.name = "prompt"input0.datatype = "BYTES"input0.shape.extend([1])input1 = multi_backend_message_pb2.ModelInferRequest().InferInputTensor()input1.name = "history"input1.datatype = "BYTES"input1.shape.extend([-1])input2 = multi_backend_message_pb2.ModelInferRequest().InferInputTensor()input2.name = "temperature"input2.datatype = "BYTES"input2.shape.extend([1])input3 = multi_backend_message_pb2.ModelInferRequest().InferInputTensor()input3.name = "max_token"input3.datatype = "BYTES"input3.shape.extend([1])input4 = multi_backend_message_pb2.ModelInferRequest().InferInputTensor()input4.name = "history_len"input4.datatype = "BYTES"input4.shape.extend([1])query = '請給出一個具體示例'input0.contents.bytes_contents.append(bytes(query, encoding="utf8"))request.inputs.extend([input0])history_origin = np.array([['你知道雞兔同籠問題么', '雞兔同籠問題是一個經典的數學問題,涉及到基本的代數方程和解題方法。問題描述為:在一個籠子里面,有若干只雞和兔子,已知它們的總數和總腿數,問雞和兔子的數量各是多少?\n\n解法如下:假設雞的數量為x,兔子的數量為y,則總腿數為2x+4y。根據題意,可以列出方程組:\n\nx + y = 總數\n2x + 4y = 總腿數\n\n通過解方程組,可以求得x和y的值,從而確定雞和兔子的數量。']]).reshape((-1,))history = [bytes(item, encoding="utf8") for item in history_origin]input1.contents.bytes_contents.extend(history)request.inputs.extend([input1])input2.contents.bytes_contents.append(bytes(temperature, encoding="utf8"))request.inputs.extend([input2])input3.contents.bytes_contents.append(bytes(max_token, encoding="utf8"))request.inputs.extend([input3])input4.contents.bytes_contents.append(bytes(history_len, encoding="utf8"))request.inputs.extend([input4])# 輸出占位output_tensor0 = multi_backend_message_pb2.ModelInferRequest().InferRequestedOutputTensor()output_tensor0.name = "response"request.outputs.extend([output_tensor0])output_tensor1 = multi_backend_message_pb2.ModelInferRequest().InferRequestedOutputTensor()output_tensor1.name = "history"request.outputs.extend([output_tensor1])min_ms = 0max_ms = 0avg_ms = 0for i in range(send_cnt):start = time.time_ns()send_one_request(request_sender, request, batch_size)cost = (time.time_ns()-start)/1000000print ("idx:%d cost ms:%d" % (i, cost))if cost > max_ms:max_ms = costif cost < min_ms or min_ms==0:min_ms = costavg_ms += costavg_ms /= send_cntprint("cnt=%d max=%dms min=%dms avg=%dms" % (send_cnt, max_ms, min_ms, avg_ms))if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument( '-ip', '--ip_address', help = 'ip address', default='127.0.0.1', required=False)parser.add_argument( '-p', '--port', help = 'port', default='8010', required=False)parser.add_argument( '-t', '--temperature', help = 'temperature', default='0.01', required=False)parser.add_argument( '-m', '--max_token', help = 'max_token', default='16000', required=False)parser.add_argument( '-hl', '--history_len', help = 'history_len', default='10', required=False)parser.add_argument( '-b', '--batch_size', help = 'batch size', default=1, required=False, type = int)parser.add_argument( '-c', '--send_count', help = 'send count', default=1, required=False, type = int)args = parser.parse_args()send_request(args.ip_address, args.port, args.temperature, args.max_token, args.history_len, args.batch_size, args.send_count)通用predictor請求格式可以參考: https://github.com/kserve/kserve/blob/master/docs/predict-api/v2/grpc_predict_v2.proto
6. 模型部署
九數算法中臺提供了兩種部署模型服務方式,分別為界面部署和SDK部署。利用界面中的模型部署只支持JSF協議接口,若要提供JSF服務接口,則可以參考 http://easyalgo.jd.com/help/%E4%BD%BF%E7%94%A8%E6%8C%87%E5%8D%97/%E6%A8%A1%E5%9E%8B%E8%AE%A1%E7%AE%97/%E6%A8%A1%E5%9E%8B%E9%83%A8%E7%BD%B2.html 直接部署。
由于我后續需要將ChatGLM2-6B模型集成至langchain中使用,所以對外提供http協議接口比較便利,經與算法中臺同學請教后使用SDK方式部署可以滿足。由于界面部署和SDK部署目前研發沒有對齊,用界面部署時直接可以使用3.1中的模型結構,使用SDK部署則需要調整模型結構如下:
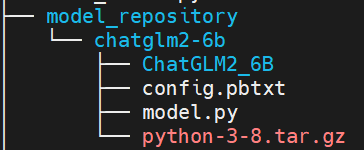
同時需要在config.pbtxt中將執行環境路徑設置如下:
parameters: {key: "EXECUTION_ENV_PATH",value: {string_value: "$$TRITON_MODEL_DIRECTORY/1/python-3-8.tar.gz"}
}模型部署代碼可以參考如下:
from das.triton.model import TritonModelmodel = TritonModel("chatglm2-6b")predictor = model.deploy(path="$pwd/model_repository/chatglm2-6b", # 模型文件所在的目錄protocol='http',endpoint = "9n-das-serving-lf2.jd.local",cpu=4,memory=30,use_gpu=True, # 根據是否需要gpu加速推理來配置override = True,instances=2)四.集成至langchain
使用langchain可以快速基于LLM模型開發一些應用。使用LLMs模塊封裝ChatGLM2-6B,請求我們的模型服務,主要實現_call函數,可以參考如下代碼:
import json
import time
import base64
import struct
import requests
import numpy as np
from pathlib import Path
from abc import ABC, abstractmethod
from langchain.llms.base import LLM
from langchain.llms import OpenAI
from langchain.llms.utils import enforce_stop_tokens
from typing import Dict, List, Optional, Tuple, Union, Mapping, Anyimport warnings
warnings.filterwarnings("ignore")class ChatGLM(LLM):max_token = 32000temperature = 0.01history_len = 10url = ""def __init__(self):super(ChatGLM, self).__init__()@propertydef _llm_type(self):return "ChatGLM2-6B"@propertydef _history_len(self) -> int:return self.history_len@propertydef _max_token(self) -> int:return self.max_token@propertydef _temperature(self) -> float:return self.temperaturedef _deserialize_bytes_tensor(self, encoded_tensor):"""Deserializes an encoded bytes tensor into annumpy array of dtype of python objectsParameters----------encoded_tensor : bytesThe encoded bytes tensor where each elementhas its length in first 4 bytes followed bythe contentReturns-------string_tensor : np.arrayThe 1-D numpy array of type object containing thedeserialized bytes in 'C' order."""strs = list()offset = 0val_buf = encoded_tensorwhile offset < len(val_buf):l = struct.unpack_from("<I", val_buf, offset)[0]offset += 4sb = struct.unpack_from("<{}s".format(l), val_buf, offset)[0]offset += lstrs.append(sb)return (np.array(strs, dtype=np.object_))@classmethoddef _infer(cls, url, query, history, temperature, max_token, history_len):query = base64.b64encode(query.encode('utf-8')).decode('utf-8')history_origin = np.asarray(history).reshape((-1,))history = [base64.b64encode(item.encode('utf-8')).decode('utf-8') for item in history_origin]temperature = base64.b64encode(temperature.encode('utf-8')).decode('utf-8')max_token = base64.b64encode(max_token.encode('utf-8')).decode('utf-8')history_len = base64.b64encode(history_len.encode('utf-8')).decode('utf-8')data = {"model_name": "chatglm2-6b","inputs": [{"name": "prompt", "datatype": "BYTES", "shape": [1], "contents": {"bytes_contents": [query]}},{"name": "history", "datatype": "BYTES", "shape": [-1], "contents": {"bytes_contents": history}},{"name": "temperature", "datatype": "BYTES", "shape": [1], "contents": {"bytes_contents": [temperature]}},{"name": "max_token", "datatype": "BYTES", "shape": [1], "contents": {"bytes_contents": [max_token]}},{"name": "history_len", "datatype": "BYTES", "shape": [1], "contents": {"bytes_contents": [history_len]}}],"outputs": [{"name": "response"},{"name": "history"}]}response = requests.post(url = url, data = json.dumps(data, ensure_ascii=True), headers = {"Content_Type": "application/json"}, timeout=120)return response def _call(self, query: str, history: List[List[str]] =[], stop: Optional[List[str]] =None):temperature = str(self.temperature)max_token = str(self.max_token)history_len = str(self.history_len)url = self.urlresponse = self._infer(url, query, history, temperature, max_token, history_len)if response.status_code!=200:return "查詢結果錯誤"if stop is not None:response = enforce_stop_tokens(response, stop)result = json.loads(response.text)# 處理responseres = base64.b64decode(result['raw_output_contents'][0].encode('utf-8'))res_response = self._deserialize_bytes_tensor(res)[0].decode()return res_responsedef chat(self, query: str, history: List[List[str]] =[], stop: Optional[List[str]] =None):temperature = str(self.temperature)max_token = str(self.max_token)history_len = str(self.history_len)url = self.urlresponse = self._infer(url, query, history, temperature, max_token, history_len)if response.status_code!=200:return "查詢結果錯誤"if stop is not None:response = enforce_stop_tokens(response, stop)result = json.loads(response.text)# 處理responseres = base64.b64decode(result['raw_output_contents'][0].encode('utf-8'))res_response = self._deserialize_bytes_tensor(res)[0].decode()# 處理historyhistory_shape = result['outputs'][1]["shape"]history_enc = base64.b64decode(result['raw_output_contents'][1].encode('utf-8'))res_history = np.array([i.decode() for i in self._deserialize_bytes_tensor(history_enc)]).reshape(history_shape).tolist()return res_response, res_history@propertydef _identifying_params(self) -> Mapping[str, Any]:"""Get the identifying parameters."""_param_dict = {"url": self.url}return _param_dict注意:模型服務調用url等于在模型部署頁面調用信息URL后加上" MutilBackendService/Predict "
五.總結
本文詳細介紹了在集團9n-triton工具上部署ChatGLM2-6B過程,希望可以為有部署需求的同學提供一些幫助。
作者:京東保險?趙風龍
來源:京東云開發者社區 轉載請注明出處
的區別)










)
)






