HADOOP背景介紹
1.1 Hadoop產生背景
- HADOOP最早起源于Nutch。Nutch的設計目標是構建一個大型的全網搜索引擎,包括網頁抓取、索引、查詢等功能,但隨著抓取網頁數量的增加,遇到了嚴重的可擴展性問題——如何解決數十億網頁的存儲和索引問題。
- 2003年、2004年谷歌發表的兩篇論文為該問題提供了可行的解決方案。(谷歌為現代技術做了十分大的貢獻!!)
——分布式文件系統(GFS),可用于處理海量網頁的存儲
——分布式計算框架MAPREDUCE,可用于處理海量網頁的索引計算問題。
Nutch的開發人員完成了相應的開源實現HDFS和MAPREDUCE,并從Nutch中剝離成為獨立項目HADOOP,到2008年1月,HADOOP成為Apache頂級項目,迎來了它的快速發展期。
1.2?什么是HADOOP
- HADOOP是apache旗下的一套開源軟件平臺(apache軟件幾乎都開源)
- HADOOP提供的功能:利用服務器集群,根據用戶的自定義業務邏輯,對海量數據進行分布式處理
- HADOOP的核心組件有
- HDFS(分布式文件系統)
- YARN(運算資源調度系統)
- MAPREDUCE(分布式??運算編程框架)
1.3 HADOOP在大數據、云計算中的位置和關系
1.?云計算是分布式計算、并行計算、網格計算、多核計算、網絡存儲、虛擬化、負載均衡等傳統計算機技術和互聯網技術融合發展的產物。借助IaaS(基礎設施即服務)、PaaS(平臺即服務)、SaaS(軟件即服務)等業務模式,把強大的計算能力提供給終端用戶。?
2.?現階段,云計算的兩大底層支撐技術為“虛擬化”和“大數據技術。?
3.?而HADOOP則是云計算的PaaS層的解決方案之一,并不等同于PaaS,更不等同于云計算本身。
1.4 Hadoop生態系統

HDFS:分布式文件系統(hdfs、MAPREDUCE、yarn)元老級大數據處理技術框架,擅長離線數據分析
MAPREDUCE:分布式運算程序開發框架
HIVE:基于大數據技術(文件系統+運算框架)的SQL數據倉庫工具,使用方便,功能豐富。但基于MR會有很大的延遲。
HBASE:基于HADOOP的分布式海量數據庫,離線分析和在線業務通吃,?是 Google Bigtable 的另一套開源實現。
ZOOKEEPER:分布式協調服務基礎組件,提供的功能包括:配置維護、名字服務、 分布式同步、心跳、組服務等
Mahout:基于mapreduce/spark/flink等分布式運算框架的機器學習算法庫提供可擴展的計算機學習領域的算法實現,旨在幫助開發人員更加快捷地開發智能 應用程序。
Oozie:工作流調度框架
Sqoop:數據導入導出工具
Flume:日志數據采集框架
Avro: 基于JSON的數據序列化的系統。
Cassandra: 一套分布式,非關系型存儲系統,類似Google - BigTable。
Chukwa: 用于監控大型分布式系統的數據采集系統。
Pig:提供一個并行執行的數據流框架。
Spark:類似MapReduce的通用并行框架,繼承了其的分布式優勢,只是中間輸出結果存儲 于內存中,提供了相對實時性的處理能力
Tez:新的一套分布式執行框架,主要以開發人員為最終用戶構建性能更快、擴展性更強的應 用程序。
1.5Hadoop大數據項目流程圖
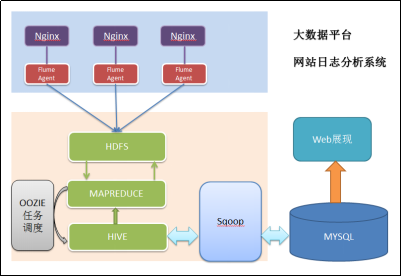
1)?數據采集:定制開發采集程序,或使用開源框架FLUME
2)?數據預處理:定制開發mapreduce程序運行于hadoop集群
3)?數據倉庫技術:基于hadoop之上的Hive
4)?數據導出:基于hadoop的sqoop數據導入導出工具
5)?數據可視化:定制開發web程序或使用kettle等產品
6)?整個過程的流程調度:hadoop生態圈中的oozie工具或其他類似開源產品
1.6Hadoop集群的安裝
提前準備:虛擬機的正常安裝,網卡啟動成功,Xshell和ftp軟件。jdk的壓縮包,和Hadoop的壓縮包。
HadoopMaster1 ? NameNode ?SecondaryNameNode ? ? 192.168.242.110
HadoopYarn? ? ?ResourceManager 192.168.242.111
HadoopSlaver1 ?DataNode ???NodeManager 192.168.242.112
HadoopSlaver2 ??DataNode ???NodeManager 192.168.242.113
HadoopSlaver3 ??DataNode ???NodeManager 192.168.242.114
1.6.1上傳jdk安裝包(用xftp上傳文件)
解壓到相應目錄:rpm -ivh ./xxxxx.jdk ?./user/java
編輯環境變量:為了在各個目錄下能運行JAVA代碼
vim /etc/profile
export JAVA_HOME=/usr/java/jvm/jdk1.7.0_79
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
wq后保存:?source ?/etc/profile 配置更新
echo java 檢驗 或者 javac java-version
1.6.2 Hadoop的安裝
1、解壓到相應目錄:cd /usr/local ??? tar –zxvf ./hadoop-2.7.2.tar.gz
把目錄修改為hadoop ? mv hadoop-2... hadoop
2、修改hadoop-env.sh
vim ?/usr/local/hadoop/etc/hadoop/hadoop-env.sh
修改export JAVA_HOME 語句為 export JAVA_HOME=/usr/java/default
3、修改core-site.xml 配置端口
cd /usr/local/hadoop/etc/hadoop
vi core-site.xml?
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file://usr/hadoop/hadoop-2.6.4/tmp</value> ?//文件存儲的目錄。需要創建
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value> //集群Master的端口號
</property>
</configuration>
###修改secondaryNamenode中的core-site.xml 配置冷備份
<property>
<name>fs.checkpoint.period</name>
<value>60</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:/usr/hadoop/hadoop-2.8.0/dfs/fsimage/</value> //需要把映射文件考到這個目錄
</property>
<property>
<name>fs.checkpoint.edits.ir</name>
<value>file:/usr/hadoop/hadoop-2.8.0/dfs/edits/</value>
</property>
4、修改集群hdfs-site.xml配置
vi??hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name> //冷備份
<value>HadoopMaster1?:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/name</value>//主文件的存儲目錄需要在相應目錄創建
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/data</value>//data文件的存儲目錄需要在相應目錄創建
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hdp-node-01:50090</value>
</property>
</configuration>
5、配hadoop的環境變量?把/usr/hadoop/bin和/usr/hadoop/sbin設到PATH中
vi /etc/profile
export PATH=$PATH:/usr/hadoop/bin:/usr/hadoop/sbin
更新:source etc/profile
測試hadoop命令是否可以直接執行,任意目錄下敲hadoop
1.6.3Yarn的搭建
?配置計算調度系統Yarn和計算引擎Map/Reduce
1 ?namenode上配置 mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2 yarn-site.xml的配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>?
<name>yarn.nodemanager.aux-services</name>?
<value>mapreduce_shuffle</value>?
</property>?
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
3啟動yarn集群start-yarn.sh
4 jps觀察啟動結果
1.6.4搭建五臺機器,集群
1、關閉虛擬機,完全克隆復制5份(一個個啟動 修改IP和hostname)
分別修改虛擬機的ip vim/etc/sysconfig/network-scripts/ifcfg-env33跟之前的圖對應
修改hostname ?vim /etc/hostname ?對應之前的名?
2、確認互相能夠ping通,用ssh登陸
在主機創建 .shh目錄?
ssh-keygen ?-t rsa
ssh-copy-id (子機IP和自己IP)一直確定完成免密,hosts修改可以改名
3,同時修改所有虛擬機的/etc/hosts,確認使用名字可以ping通
HadoopMaster1 ? ?192.168.242.110
HadoopYarn? ? 192.168.242.111
HadoopSlaver1 ?192.168.242.112
HadoopSlaver2 192.168.242.113
HadoopSlaver3 ? 192.168.242.114
4,修改master上/etc/hadoop/slaves文件,每一個slave占一行(子機的名)
HadoopSlaver1 ??
HadoopSlaver2 ?
HadoopSlaver3
現在集群namenode ?datanode已經可以啟動了
使用start-dfs.sh啟動集群,jps并觀察結果
配置文件詳細信息以后慢慢搭建時會慢慢更改。
現在這個集群完全搭建完畢,過程較長。建議初學者一點一點搭環境。配置文件可能會有問題。后續慢慢更改。
?
?
?








![Building a WAMP Dev Environment [3/4] - Installing and Configuring PHP](http://pic.xiahunao.cn/Building a WAMP Dev Environment [3/4] - Installing and Configuring PHP)








函數)

