struts實現分頁
If you want to get started on 3D Object Detection and more specifically on Point Pillars, I have a series of posts written on it just for that purpose. Here’s the link. Also, going through the Point Pillars paper directly will be really helpful to understand this post better, however, it’s not a prerequisite.
如果您想開始使用3D對象檢測,更具體地說是關于“點Struts”,那么我就為此目的撰寫了一系列文章。 這是鏈接 。 另外,直接閱讀Point Pillars論文對于更好地理解此文章確實很有幫助,但是,這不是前提條件。
Github Repo for this tutorial: https://github.com/tyagi-iiitv/PointPillars. Thanks to Francesco Ferroni for the initial code.
本教程的Github Repo: https : //github.com/tyagi-iiitv/PointPillars 。 感謝Francesco Ferroni的初始代碼。
內容 (Contents)
- Defining Initial Configurations 定義初始配置
- Building Point Pillars Network 建筑點Struts網絡
- Loss functions 損失函數
- Data Readers for Kitti Dataset Kitti數據集的數據讀取器
- Training 訓練
- Inference 推理
定義初始配置(config.py) (Defining Initial Configurations (config.py))
We define initial configurations that include the limits for x,y,z dimensions. These limits define the region of interest in which we will be predicting the bounding boxes. Since the range of LiDARs is generally very high, we focus on a smaller region in this space which is defined by these limits. Other configurations include the maximum number of Pillars, maximum points per pillar, etc.
我們定義了包括x,y,z尺寸限制的初始配置。 這些限制定義了我們將在其中預測邊界框的感興趣區域。 由于LiDAR的范圍通常很高,因此我們將重點放在由這些限制定義的該空間中的一個較小區域。 其他配置包括最大Struts數量,每個Struts的最大點數等。

These configurations are generally used to transfer the point cloud from 3D coordinates to Pillar coordinates in the Point Pillars detection pipeline as discussed in the next section. For now, just remember that all the configurations are defined in this file.
這些配置通常用于將點云從3D坐標傳遞到點Struts檢測管道中的Struts坐標,如下一節所述。 現在,請記住,所有配置都在此文件中定義。
建立點Struts網絡(network.py) (Building the Point Pillars Network (network.py))
The overall architecture of Point Pillars contains three components: A pillar feature net, A Backbone 2D CNN, and a Detection Head. We will discuss these three components individually.
點Struts的整體體系結構包含三個組件:Struts特征網,骨干2D CNN和檢測頭。 我們將分別討論這三個組成部分。

Struts特征網 (Pillar Feature Net)

pillars/input (Input Layer) (4,12000,100,7) refers to — Batch Size (4), Maximum Number of Pillars (12000), Maximum number of Points per Pillar (100), 7 dim vector: [x,y,z,intensity,Xc,Yc,Zc]. X,y,z are the 3D coordinates of a point inside a point cloud and its intensity as measured by the LiDAR device is stored inside “intensity”, Xc, Yc, Zc stores the distance of that point from the Pillar Center in each dimension.
Struts/輸入(輸入層)(4,12000,100,7)指代— 批大小(4),最大Struts數(12000),每個Struts的最大點數(100),7個暗矢量:[x, y,z,強度,Xc,Yc,Zc]。 X,y,z是點云中點的3D坐標,由LiDAR設備測量的點的強度存儲在“強度”內部,Xc,Yc,Zc存儲該點到各個維度中距柱心的距離。
- This input is now transformed from 7 dimensions to a 64-dimensional vector with features extracted using a CNN. 現在,此輸入已從7維轉換為具有使用CNN提取的特征的64維矢量。
pillars/indices (InputLayer) (4,12000,3) refers to — Batch Size, Maximum number of Pillars, and the center of each pillar, i.e. the x,y and z coordinates. This layer contains the center of each pillar, which is used to map the features learned for each pillar back to the x-y grid in pillars/scatter_nd (Lambda) layer.
Struts/索引(InputLayer)(4,12000,3)指- 批大小,最大Struts數以及每個Struts的中心,即x,y和z坐標。 該層包含每個Struts的中心,該中心用于將為每個Struts學習的特征映射回Struts/ scatter_nd(Lambda)層中的xy網格。
- pillars/scatter_nd (Lambda) — Using the x,y coordinates from the above layer, the point cloud space is divided into (504 X 504) x-y grid with each grid cell containing the 64 features of the corresponding pillar. Struts/散點圖(Lambda)-使用來自上一層的x,y坐標,將點云空間劃分為(504 X 504)xy柵格,每個柵格單元包含對應Struts的64個要素。
骨干2D CNN (Backbone 2D CNN)
This is a practically simple layer with input being the pillar features encoded in an x-y grid, as described in the previous section. This grid is treated as an image and is transformed into different scales with features extracted at those scales and finally concatenated. We are trying to capture features from different scales of the point cloud and concatenate them into a single tensor.
如上一節所述,這是一個實際上簡單的圖層,輸入是在xy網格中編碼的Struts特征。 該網格被視為圖像,并轉換為不同的比例,并以這些比例提取特征并最終進行連接。 我們正在嘗試從不同比例的點云中捕獲特征,并將它們連接為單個張量。


檢測頭 (Detection Head)

In this part, we are predicting the regression targets for the anchor boxes as described below. All of these predictions are for each grid cell in the x-y coordinates (252 X 252). The bounding boxes are not directly predicted in this case, but the initial anchor boxes are resized to generate the predicted bounding box. The initial anchor boxes are provided inside the config.py file.
在這一部分中,我們將預測錨框的回歸目標,如下所述。 所有這些預測都是針對xy坐標(252 X 252)中的每個網格單元。 在這種情況下,不會直接預測邊界框,但是會調整初始錨點框的大小以生成預測的邊界框。 初始錨框位于config.py文件中。
- Occupancy — Whether the predicted label contains an element. 1 — Yes and No Otherwise. So we only need to check other predictions (loc, size, angle, heading, and clf) only when occupancy is 1. 占用率—預測的標簽是否包含元素。 1-是,否則,否。 因此,僅當占用率為1時,我們才需要檢查其他預測(位置,大小,角度,航向和clf)。
- Loc — Contains the delta x,y,z for the corresponding anchor box. Loc —包含相應錨點框的增量x,y,z。
- Size — Contains delta length, width, and height for the corresponding anchor box. 大小-包含相應錨點框的增量長度,寬度和高度。
- Angle — Contains the delta yaw value. 角度—包含增量偏航值。
- Heading — Contains if Angle is > 90 to check the heading angle of the object. 航向—包含“角度”是否大于90,以檢查對象的航向角。
- Clf — Contains the classification id and the confidence score for each prediction. Clf —包含每個預測的分類ID和置信度分數。
Note that the Detection head predicts 4 bounding boxes per grid cell, and each bounding box has the properties listed above.
請注意,檢測頭會為每個網格單元預測4個邊界框,并且每個邊界框都具有上面列出的屬性。
損失函數(loss.py) (Loss Functions (loss.py))
Once we have decided on the network architecture, we create the loss functions to complete the training process definitions. As you can see in the loss.py file, we are calculating the loss values for each of our regression targets and adding them with weights assigned to each error. So, the final loss value will be a weighted sum of each loss value.
一旦確定了網絡體系結構,就創建損失函數以完成訓練過程定義。 正如您在loss.py文件中看到的那樣,我們正在計算每個回歸目標的損失值,并將它們與分配給每個錯誤的權重相加。 因此,最終損失值將是每個損失值的加權和。

focal_weight*focal_loss + loc_weight*loc_loss + size_weight*size_loss + angle_weight*angle_loss +
...Kitti數據集的數據讀取器(readers.py) (Data Readers for Kitti Dataset (readers.py))
We have designed a class to read the files in the Kitti Dataset and extract the 3D bounding box dimensions from the label (txt) files. Every row in the labels file contain the following information:
我們設計了一個類來讀取Kitti數據集中的文件,并從標簽(txt)文件中提取3D邊框尺寸。 標簽文件中的每一行都包含以下信息:

- Type of object (Car, Truck, etc.) 對象類型(汽車,卡車等)
- Truncated Float, 0 means truncated and 1 means non-truncated 截斷浮點,0表示被截斷,1表示不截斷
- Occlusion State, 0=Fully Visible, 1=Partly Occluded, 2=Largely Occluded, 3=Unknown 遮擋狀態,0 =完全可見,1 =部分遮擋,2 =大遮擋,3 =未知
- Alpha Observation angle 阿爾法觀察角
- 4 2D bounding box parameters (center, length, width) 4個2D邊界框參數(中心,長度,寬度)
- 3D object dimensions (height, width, length) 3D對象尺寸(高度,寬度,長度)
- 3D object location (x,y,z) in camera coordinates 相機坐標中的3D對象位置(x,y,z)
- Yaw angle 偏航角
培訓(point_pillars_training_run.py,processors.py,src / point_pillars.cpp) (Training (point_pillars_training_run.py, processors.py, src/point_pillars.cpp))
After defining loss functions, configurations, and data generators for each data point in the Kitti dataset, the SimpleDataGenerator in the processor.py file, generates the training examples. The main steps in this process are:
在為Kitti數據集中的每個數據點定義損失函數,配置和數據生成器之后, processor.py文件中的SimpleDataGenerator會生成訓練示例。 此過程的主要步驟是:
Generate Pillars and Pillar Ids (DataProcessor.make_point_pillars inside processor.py file)
生成Struts和StrutsID( processor.py文件中的DataProcessor.make_point_pillars )
Generate the regression targets (discussed above) from the label files and given anchor boxes in the config.py file. (DataProcessor.make_ground_truth inside processor.py file)
從標簽文件和config.py文件中給定的錨定框生成回歸目標(如上所述)。 (processor.py文件中的DataProcessor.make_ground_truth )
The helper functions for these two tasks are provided inside the src/point_pillars.cpp file which is included with the current python code using Pybind.
這兩個任務的幫助程序功能在src / point_pillars.cpp文件中提供,該文件包含在使用Pybind的當前python代碼中。
- createPillars (src/point_pillars.cpp) — Generates the maximum number of pillars and assign pillar centers to each pillar. Use zero-padding if the number of points inside a pillar is less than the maximum points and random sampling otherwise. Each pillar will have 100 points and 7 values for each point (x, y, z, intensity, Xc, Yc, Zc). We start from the (0,0) LiDAR coordinates and expand radially in the field of view until we reach a maximum number of pillars. createPillars(src / point_pillars.cpp)-生成最大數量的Struts并將Struts中心分配給每個Struts。 如果Struts內的點數少于最大點數,請使用零填充,否則使用隨機抽樣。 每個Struts將具有100個點和每個點7個值(x,y,z,強度,Xc,Yc,Zc)。 我們從(0,0)LiDAR坐標開始,在視場中徑向擴展,直到達到最大柱數為止。

- createPillarsTarget (src/point_pillars.cpp) — Generates the regression targets which can be used to calculate the loss values later. For each 3D bounding box given inside the labels file, it is compared to the anchor boxes. First, a search radius is created around the original bounding box based on object dimensions (red circle on the grid below). Then for each grid cell inside that radius, the anchor boxes are placed and IoU is calculated between each anchor box and the original bounding box. createPillarsTarget(src / point_pillars.cpp)-生成可用于以后計算損失值的回歸目標。 對于標簽文件中給定的每個3D邊界框,將其與錨定框進行比較。 首先,根據對象尺寸(下面的網格上的紅色圓圈)在原始邊界框周圍創建搜索半徑。 然后,對于該半徑內的每個網格單元,放置錨框,并在每個錨框和原始邊界框之間計算IoU。
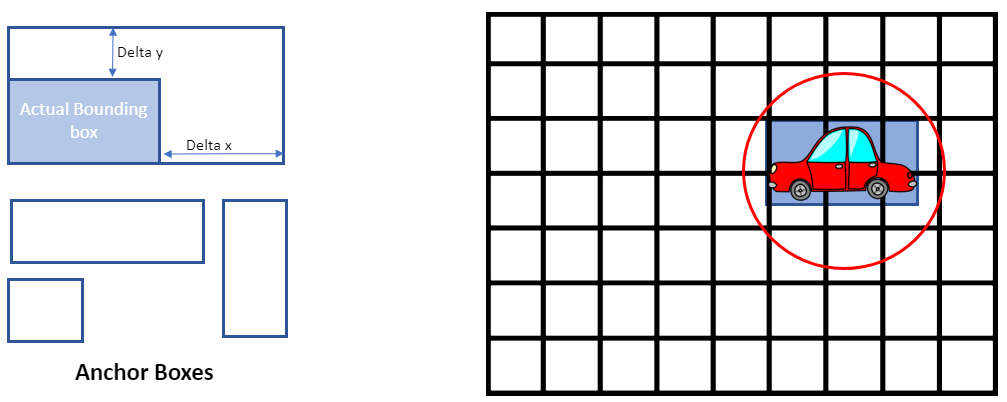

If the IoU value is above a certain threshold, then the targets (delta - x, y, z, length, width height, yaw, etc.) are stored for that bounding box. Otherwise, if no anchor passed the threshold, the best anchor based on IoU scores is chosen for that grid cell and is stored. These values are then used to calculate the loss values as described above.
如果IoU值高于某個閾值,則將為該邊界框存儲目標(δ-x,y,z,長度,寬度,高度,偏航等)。 否則,如果沒有錨點超過閾值,則為該網格單元選擇基于IoU分數的最佳錨點并將其存儲。 然后,將這些值用于計算如上所述的損耗值。
推論(point_pillars_prediction.py) (Inference (point_pillars_prediction.py))
The last part of this codebase is the point_pillars_prediction.py file used for inferencing. After we have trained the network based on the loss functions described before, during the inference stage, the output of the network is the regression targets, occupancy index, and the classification confidence value for each prediction. You can verify that for each grid cell, the network outputs 4 bounding boxes with their respective parameters.
該代碼庫的最后一部分是用于推理的point_pillars_prediction.py文件。 在根據之前所述的損失函數對網絡進行訓練之后,在推理階段,網絡的輸出是每個預測的回歸目標,占用指數和分類置信度值 。 您可以驗證網絡是否為每個網格單元輸出4個邊界框及其各自的參數。
We can remove most of the predicted boxes based on the occupancy index since we only want the boxes with occupancy 1, which means that the network has actually predicted a bounding box on that grid cell. Still, there can be many bounding boxes that are predicted by the network for the same object. To filter these, we can use Non-Maximum Suppression and come up with final bounding box predictions. Non-Maximum Suppression ranks the bounding boxes on the basis of IoU and their classification confidence values and selects the one with the best value as the final bounding box. Refer to this post to read more on Non-Maximum Suppression.
由于我們只希望占用率為1的框,因此我們可以根據占用率索引刪除大多數預測框,這意味著網絡實際上已經預測了該網格單元上的邊界框。 但是,網絡仍然可以為同一對象預測許多邊界框。 為了過濾這些,我們可以使用非最大抑制,并給出最終的邊界框預測。 非最大抑制基于IoU及其分類置信度對邊界框進行排序,并選擇具有最佳值的邊界框作為最終邊界框。 請參閱這篇文章,以了解有關非最大抑制的更多信息。

結論 (Conclusion)
This post covered the details of Point Pillars implementation on Tensorflow. All the code details including configuration files, model implementation, data generators, training, and inference are explained with code examples. The code is available in this Github repo and can be used to experiment with the details given in this article. As the next steps, we are working on generating inference results on the Kitti data which will be posted on the Github repo.
這篇文章涵蓋了在Tensorflow上實現Point Pillars的細節。 所有代碼細節(包括配置文件,模型實現,數據生成器,培訓和推斷)均通過代碼示例進行了說明。 該代碼可在該Github存儲庫中使用 ,并可用于試驗本文給出的詳細信息。 下一步,我們正在根據Kitti數據生成推斷結果,該結果將發布在Github存儲庫中。
If you are interested in contributing to this project, please check out the issues on the GitHub repo.
如果您有興趣為該項目做貢獻,請在GitHub存儲庫上查看問題。
翻譯自: https://towardsdatascience.com/implementing-point-pillars-in-tensorflow-c38d10e9286
struts實現分頁
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391593.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391593.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391593.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

封裝jQuery下載文件組件

7.13. parallel - build and execute shell command lines from standard input in parallel

MySQL-InnoDB索引實現

Go語言-基本的http請求操作

釘釘設置jira機器人_這是當您機器學習JIRA票證時發生的事情
)
python的賦值與參數傳遞(python和linux切換)

vscode 標準庫位置_如何在VSCode中使用標準

leetcode 1603. 設計停車系統

IBM量子計算新突破:成功構建50個量子比特原型機

ChromeDriver與chrome對應關系
算法)
快速排序和快速選擇(quickSort and quickSelect)算法

小程序點擊地圖氣泡獲取氣泡_氣泡上的氣泡
)
leetcode 150. 逆波蘭表達式求值(棧)

WebLogic常見問題

PopTheBubble —測量媒體偏差的產品創意

linux-Centos7安裝nginx

javascript原型_JavaScript原型初學者指南

leetcode 73. 矩陣置零

elasticsearch,elasticsearch-service安裝
