簡述yolo1-yolo3
重點 (Top highlight)
目錄: (Table Of Contents:)
- Introduction 介紹
- Why YOLO? 為什么選擇YOLO?
- How does it work? 它是如何工作的?
- Intersection over Union (IoU) 聯合路口(IoU)
- Non-max suppression 非最大抑制
- Network Architecture 網絡架構
- Training 訓練
- Limitation of YOLO YOLO的局限性
- Conclusion 結論
介紹: (Introduction:)
You Only Look Once (YOLO) is a new and faster approach to object detection. Traditional systems repurpose classifiers to perform detection. Basically, to detect any object, the system takes a classifier for that object and then classifies its presence at various locations in the image. Other systems generate potential bounding boxes in an image using region proposal methods and then run a classifier on these potential boxes. This results in a slightly efficient method. After classification, post-processing is used to refine the bounding boxes, eliminate duplicate detection, etc. Due to these complexities, the system becomes slow and hard to optimize because each component has to be trained separately.
“只看一次”(YOLO)是一種新的且更快的對象檢測方法。 傳統系統重新利用分類器來執行檢測。 基本上,要檢測任何物體,系統會對該物體進行分類,然后將其在圖像中各個位置的存在進行分類。 其他系統使用區域提議方法在圖像中生成潛在的邊界框,然后在這些潛在的框上運行分類器。 這導致一種稍微有效的方法。 分類后,使用后處理來完善邊界框,消除重復檢測等。由于這些復雜性,系統變得緩慢且難以優化,因為每個組件都必須單獨訓練。

為什么選擇YOLO? (Why YOLO?)
The base model can process images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO can process images at 155 frames per second while achieving double the mAP of other real-time detectors. It outperforms other detection methods, including DPM (Deformable Parts Models) and R-CNN.
基本模型可以每秒45幀的速度實時處理圖像。 Fast YOLO是網絡的較小版本,可以每秒155幀的速度處理圖像,同時使其他實時檢測器的mAP達到兩倍。 它優于其他檢測方法,包括DPM(可變形零件模型)和R-CNN。
它是如何工作的? (How Does It Work?)
YOLO reframes object detection as a single regression problem instead of a classification problem. This system only looks at the image once to detect what objects are present and where they are, hence the name YOLO.
YOLO將對象檢測重新構造為單個回歸問題,而不是分類問題。 該系統僅查看圖像一次即可檢測出存在的物體及其位置,因此命名為YOLO。
The system divides the image into an S x S grid. Each of these grid cells predicts B bounding boxes and confidence scores for these boxes. The confidence score indicates how sure the model is that the box contains an object and also how accurate it thinks the box is that predicts. The confidence score can be calculated using the formula:
系統將圖像劃分為S x S網格。 這些網格單元中的每一個都預測B邊界框和這些框的置信度得分。 置信度得分表明模型對盒子是否包含對象的確信程度,以及模型認為盒子預測的準確性。 置信度得分可以使用以下公式計算:
C = Pr(object) * IoU
C = Pr(對象)* IoU
IoU: Intersection over Union between the predicted box and the ground truth.
IoU:預測框與地面實況之間的并集交集。
If no object exists in a cell, its confidence score should be zero.
如果單元格中不存在任何對象,則其置信度得分應為零。
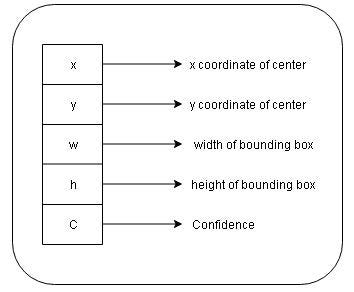
Each bounding box consists of five predictions: x, y, w, h, and confidence where,
每個邊界框均包含五個預測: x,y,w,h和置信度,其中,
(x,y): Coordinates representing the center of the box. These coordinates are calculated with respect to the bounds of the grid cells.
(x,y):表示框中心的坐標。 這些坐標是相對于網格單元的邊界計算的。
w: Width of the bounding box.
w:邊框的寬度。
h: Height of the bounding box.
h:邊框的高度。
Each grid cell also predicts C conditional class probabilities Pr(Classi|Object). It only predicts one set of class probabilities per grid cell, regardless of the number of boxes B. During testing, these conditional class probabilities are multiplied by individual box confidence predictions which give class-specific confidence scores for each box. These scores show both the probability of that class and how well the box fits the object.
每個網格單元還預測C個條件類別概率Pr(Classi | Object) 。 不管框B的數量如何,它僅預測每個網格單元的一組類別概率。在測試期間,這些條件類別概率乘以各個框的置信度預測,從而為每個框提供特定于類別的置信度得分。 這些分數既顯示了該類別的可能性,也顯示了盒子適合對象的程度。
Pr(Class i|Object)*Pr(Object)*IoU = Pr(Class i)*IoU.
Pr(類i |對象)* Pr(對象)* IoU = Pr(類i)* IoU。
The final predictions are encoded as an S x S x (B*5 + C) tensor.
最終預測被編碼為S x S x(B * 5 + C)張量。
聯合路口(IoU): (Intersection Over Union (IoU):)
IoU is used to evaluate the object detection algorithm. It is the overlap between the ground truth and the predicted bounding box, i.e it calculates how similar the predicted box is with respect to the ground truth.
IoU用于評估對象檢測算法。 它是基本事實和預測邊界框之間的重疊,即,它計算了預測框相對于基本事實的相似程度。




Usually, the threshold for IoU is kept as greater than 0.5. Although many researchers apply a much more stringent threshold like 0.6 or 0.7. If a bounding box has an IoU less than the specified threshold, that bounding box is not taken into consideration.
通常,IoU的閾值保持大于0.5。 盡管許多研究人員采用了更為嚴格的閾值,例如0.6或0.7。 如果邊界框的IoU小于指定的閾值,則不考慮該邊界框。
非最大抑制: (Non-Max Suppression:)
The algorithm may find multiple detections of the same object. Non-max suppression is a technique by which the algorithm detects the object only once. Consider an example where the algorithm detected three bounding boxes for the same object. The boxes with respective probabilities are shown in the image below.
該算法可以找到同一物體的多個檢測。 非最大抑制是一種算法,算法僅將對象檢測一次。 考慮一個示例,該算法檢測到同一對象的三個邊界框。 下圖顯示了具有相應概率的框。

The probabilities of the boxes are 0.7, 0.9, and 0.6 respectively. To remove the duplicates, we are first going to select the box with the highest probability and output that as a prediction. Then eliminate any bounding box with IoU > 0.5 (or any threshold value) with the predicted output. The result will be:
框的概率分別為0.7、0.9和0.6。 要刪除重復項,我們首先選擇具有最高概率的框,然后將其輸出作為預測。 然后,用預測輸出消除IoU> 0.5(或任何閾值)的任何邊界框。 結果將是:

網絡架構: (Network Architecture:)
The base model has 24 convolutional layers followed by 2 fully connected layers. It uses 1 x 1 reduction layers followed by a 3 x 3 convolutional layer. Fast YOLO uses a neural network with 9 convolutional layers and fewer filters in those layers. The complete network is shown in the figure.
基本模型具有24個卷積層,然后是2個完全連接的層。 它使用1 x 1縮小層,然后是3 x 3卷積層。 Fast YOLO使用具有9個卷積層和較少層過濾器的神經網絡。 完整的網絡如圖所示。

Note:
注意:
- The architecture was designed for use in the Pascal VOC dataset, where S = 7, B = 2, and C = 20. This is the reason why final feature maps are 7 x 7, and also the output tensor is of the shape (7 x 7 x (2*5 + 20)). To use this network with a different number of classes or different grid size you might have to tune the layer dimensions. 該體系結構設計用于Pascal VOC數據集,其中S = 7,B = 2和C =20。這就是為什么最終特征圖為7 x 7以及輸出張量為(7 x 7 x(2 * 5 + 20)。 若要將此網絡用于不同數量的類或不同的網格尺寸,則可能必須調整圖層尺寸。
- The final layer uses a linear activation function. The rest uses a leaky ReLU. 最后一層使用線性激活函數。 其余使用泄漏的ReLU。
訓練: (Training:)
- Pre train the first 20 convolutional layers on the ImageNet 1000-class competition dataset followed by average — pooling layer and a fully connected layer. 在ImageNet 1000類競賽數據集上訓練前20個卷積層,然后進行平均-池化層和完全連接的層。
- Since detection requires better visual information, increase the input resolution from 224 x 224 to 448 x 448. 由于檢測需要更好的視覺信息,因此將輸入分辨率從224 x 224增加到448 x 448。
- Train the network for 135 epochs. Throughout the training, use a batch size of 64, a momentum of 0.9, and a decay of 0.0005. 訓練網絡135個紀元。 在整個訓練過程中,請使用64的批量大小,0.9的動量和0.0005的衰減。
- Learning Rate: For first epochs raise the learning rate from 10–3 to 10–2, else the model diverges due to unstable gradients. Continue training with 10–2 for 75 epochs, then 10–3 for 30 epochs, and then 10–4 for 30 epochs. 學習率:首先,將學習率從10–3提高到10–2,否則模型由于不穩定的梯度而發散。 繼續訓練10–2代表75個時期,然后10–3代表30個時期,然后10–4代表30個時期。
- To avoid overfitting, use dropout and data augmentation. 為避免過度擬合,請使用輟學和數據擴充。
YOLO的局限性: (Limitations Of YOLO:)
- Spatial constraints on bounding box predictions as each grid cell only predicts two boxes and can have only one class. 邊界框預測的空間約束,因為每個網格單元僅預測兩個框,并且只能具有一個類別。
- It is difficult to detect small objects that appear in groups. 很難檢測出現在組中的小物體。
- It struggles to generalize objects in new or unusual aspect ratios as the model learns to predict bounding boxes from data itself. 當模型學習從數據本身預測邊界框時,它很難以新的或不尋常的寬高比來概括對象。
結論: (Conclusion:)
This was a brief explanation of the research paper as well as details obtained from various other sources. I hope I made this concept easier for you to understand.
這是對研究論文的簡要說明,以及從其他各種來源獲得的詳細信息。 希望我使這個概念更容易理解。
Although if you really want to check your understanding, the best way is to implement the algorithm. In the next section, we will do exactly that. Many details cannot be explained via text and can only be understood while implementing it.
盡管如果您真的想檢查自己的理解,最好的方法是實現算法。 在下一節中,我們將完全做到這一點。 許多細節無法通過文本解釋,只能在實施過程中理解。
Thank you for reading. Click here to go to the next part.
感謝您的閱讀。 單擊此處轉到下一部分。
翻譯自: https://towardsdatascience.com/object-detection-part1-4dbe5147ad0a
簡述yolo1-yolo3
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391220.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391220.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391220.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

django:資源網站匯總
集群配置)
Kubernetes 入門(4)集群配置

【例9.8】合唱隊形

scrum流程 規劃 沖刺_Scrum –困難的部分2:更快地沖刺

JAVA基礎知識|lambda與stream

數據庫:存儲過程_數據科學過程:摘要

)
leetcode 137. 只出現一次的數字 II(位運算)

【p081】ISBN號碼

gitlab bash_如何編寫Bash一線式以克隆和管理GitHub和GitLab存儲庫
)

svm和k-最近鄰_使用K最近鄰的電影推薦和評級預測

Oracle:時間字段模糊查詢
![cogs2109 [NOIP2015] 運輸計劃](http://pic.xiahunao.cn/cogs2109 [NOIP2015] 運輸計劃)
cogs2109 [NOIP2015] 運輸計劃
)
leetcode 690. 員工的重要性(dfs)

組件分頁_如何創建分頁組件


cnn對網絡數據預處理_CNN中的數據預處理和網絡構建

leetcode 554. 磚墻
