本系列博文為深度學習/計算機視覺論文筆記,轉載請注明出處
標題:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
鏈接:[1511.06434] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (arxiv.org)
摘要
近年來,卷積網絡(CNNs)的監督學習在計算機視覺應用中得到了廣泛的應用。相比之下,CNNs的無監督學習受到的關注較少。在這項工作中,我們希望彌補CNNs在監督學習和無監督學習之間的差距。我們引入了一類稱為深度卷積生成對抗網絡(DCGANs)的CNNs,它們具有某些架構約束,并證明它們是無監督學習的有力候選者。在各種圖像數據集上的訓練中,我們展示了有說服力的證據,證明我們的深度卷積對抗對從對象部分到場景在生成器和鑒別器中都學到了表示的層次結構。此外,我們使用學到的特征進行新的任務——展示它們作為通用圖像表示的適用性。
1 引言
從大型未標記的數據集中學習可重用的特征表示一直是活躍研究的領域。在計算機視覺的背景下,人們可以利用實際上無限量的未標記的圖像和視頻來學習好的中間表示,然后可以用于各種監督學習任務,如圖像分類。我們建議,構建良好的圖像表示的一種方法是通過訓練生成對抗網絡(GANs)(Goodfellow等人,2014),然后重用生成器和鑒別器網絡的部分作為監督任務的特征提取器。GANs為最大似然技術提供了一個有吸引力的替代方案。人們還可以爭辯說,他們的學習過程以及沒有啟發式的代價函數(如像素獨立的均方誤差)對于表示學習來說都很有吸引力。眾所周知,GANs不穩定,經常導致生成器產生無意義的輸出。在試圖理解和可視化GANs學到了什么,以及多層GANs的中間表示方面,發表的研究非常有限。
在本文中,我們做出以下貢獻:
- 我們提出并評估了一套對卷積GANs的架構拓撲的約束,使它們在大多數設置中穩定地進行訓練。我們將這類架構命名為深度卷積生成對抗網絡(DCGAN)。
- 我們使用經過訓練的鑒別器進行圖像分類任務,與其他無監督算法展現了有競爭力的性能。
- 我們可視化了GANs學到的過濾器,并憑經驗顯示特定的過濾器已經學會繪制特定的對象。
- 我們展示了生成器具有有趣的向量算術屬性,允許輕松操縱生成樣本的許多語義質量。
2 相關工作
2.1 從未標記的數據學習表示
無監督表示學習在通用計算機視覺研究中是一個相當研究得很深入的問題,也是在圖像背景下的問題。無監督表示學習的經典方法是對數據進行聚類(例如使用K均值),并利用這些聚類來提高分類分數。在圖像的背景下,可以對圖像塊進行層次性的聚類(Coates & Ng, 2012)來學習強大的圖像表示。另一個流行的方法是訓練自動編碼器(卷積、堆疊(Vincent等人,2010)、分離代碼的什么和哪里組件(Zhao等人,2015)、梯形結構(Rasmus等人,2015)),將圖像編碼為一個緊湊的代碼,并解碼代碼以盡可能準確地重建圖像。這些方法也已被證明可以從圖像像素中學習到好的特征表示。深度信念網絡(Lee等人,2009)也被證明在學習分層表示方面表現良好。
2.2 生成自然圖像
生成圖像模型已經研究得很深入,分為兩類:參數和非參數。非參數模型通常從現有圖像的數據庫中進行匹配,常常是匹配圖像的塊,并已被用于紋理合成(Efros等人,1999)、超分辨率(Freeman等人,2002)和圖像修復(Hays & Efros, 2007)。生成圖像的參數模型已經被廣泛探索(例如在MNIST數字上或用于紋理合成(Portilla & Simoncelli, 2000))。但是,直到最近生成真實世界的自然圖像都沒有取得太大的成功。生成圖像的變分采樣方法(Kingma & Welling, 2013)已經取得了一些成功,但是樣本常常因為模糊而受到影響。另一種方法使用迭代的正向擴散過程(Sohl-Dickstein等人,2015)來生成圖像。生成對抗網絡(Goodfellow等人,2014)生成的圖像受到噪聲和難以理解的影響。這種方法的拉普拉斯金字塔擴展(Denton等人,2015)顯示了更高質量的圖像,但它們仍然受到由于在鏈接多個模型時引入的噪聲導致的對象看起來搖晃不定的影響。遞歸網絡方法(Gregor等人,2015)和反卷積網絡方法(Dosovitskiy等人,2014)最近也在生成自然圖像方面取得了一些成功。然而,他們沒有利用生成器來進行監督任務。
2.3 可視化CNNs的內部結構
使用神經網絡的一個持續的批評是它們是黑盒方法,很少理解網絡以簡單的人類可消化的算法形式所做的事情。在CNNs的背景下,Zeiler等人(Zeiler & Fergus, 2014)表明,通過使用反卷積和過濾最大激活,可以找到網絡中每個卷積濾波器的大致用途。同樣,對輸入進行梯度下降使我們能夠檢查激活某些子集濾波器的理想圖像(Mordvintsev等人)。
3 方法與模型架構
使用CNNs對GANs進行擴展以模擬圖像的歷史嘗試都沒有成功。這促使LAPGAN的作者(Denton等,2015)開發了一種替代方法,迭代地放大可以更可靠地建模的低分辨率生成的圖像。我們也在嘗試使用在監督文獻中常用的CNN架構來擴展GANs時遇到了困難。然而,在廣泛的模型探索之后,我們確定了一系列的架構,這些架構在一系列的數據集上都能穩定地進行訓練,并允許訓練更高分辨率和更深的生成模型。
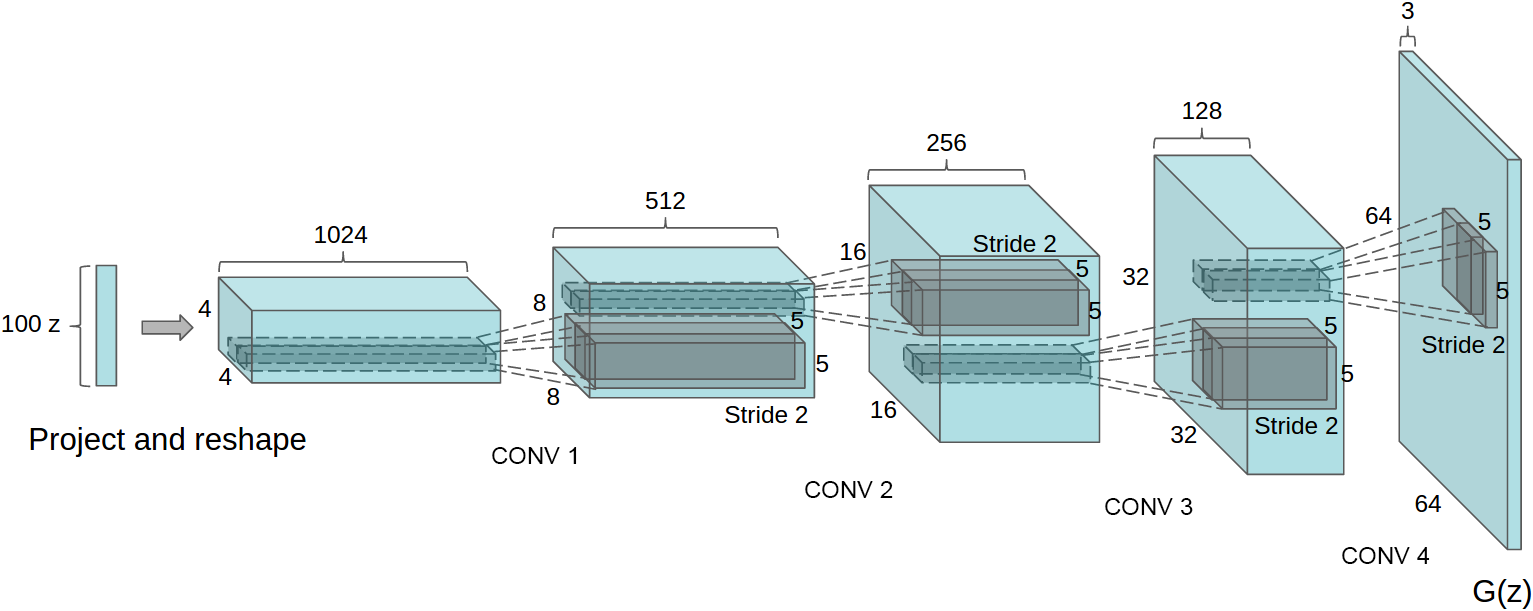
我們的方法的核心是采納并修改了最近對CNN架構展示出的三個變化。第一個是全卷積網絡(Springenberg等,2014),它用帶步長的卷積替換了確定性的空間池化函數(如最大池化),使網絡能夠學習自己的空間下采樣。我們在生成器中使用這種方法,讓它學習自己的空間上采樣,以及判別器。第二是消除卷積特征上面的全連接層的趨勢。這方面最強烈的例子是全局平均池化,它已經被用于最先進的圖像分類模型(Mordvintsev等)。我們發現全局平均池化增加了模型的穩定性,但降低了收斂速度。直接將最高的卷積特征連接到生成器和判別器的輸入和輸出,效果很好。GAN的第一層,將均勻噪聲分布Z作為輸入,可以被稱為全連接,因為它只是一個矩陣乘法,但結果被重塑成一個4維張量,并用作卷積堆棧的開始。對于判別器,最后的卷積層被展平,然后送入一個單一的sigmoid輸出。參見圖1,查看一個示例模型架構的可視化。
圖1:用于LSUN場景建模的DCGAN生成器。一個100維的均勻分布Z被映射到一個具有許多特征圖的小空間范圍的卷積表示。然后,四個分數步幅的卷積(在一些近期的論文中,這些被錯誤地稱為反卷積)將這種高級表示轉換為一個64×64像素的圖像。值得注意的是,沒有使用全連接或池化層。
第三是批量正則化(Ioffe & Szegedy, 2015),它通過將每個單元的輸入標準化為均值為零和單位方差來穩定學習。這有助于處理由于不良初始化而產生的訓練問題,并幫助在更深的模型中的梯度流動。這對于讓深層的生成器開始學習至關重要,防止生成器將所有樣本坍縮到一個點,這是在GANs中觀察到的一個常見的失敗模式。然而,直接將batchnorm應用到所有層上,會導致樣本振蕩和模型不穩定。通過不在生成器的輸出層和判別器的輸入層上應用batchnorm來避免這種情況。在生成器中使用ReLU激活函數(Nair & Hinton, 2010),除了輸出層使用Tanh函數。我們觀察到,使用有界激活允許模型更快地學習飽和和覆蓋訓練分布的顏色空間。在判別器內,我們發現泄漏修正激活(Maas等,2013)(Xu等,2015)工作得很好,特別是對于高分辨率建模。這與原始的GAN論文形成了對比,后者使用了maxout激活(Goodfellow等,2013)。
為穩定的深度卷積GANs的架構指南:
- 用帶步長的卷積(判別器)和分數步長的卷積(生成器)替換任何池化層。
- 在生成器和判別器中都使用批量歸一化(batchnorm)。
- 為了更深的架構,移除全連接的隱藏層。
- 在生成器中,除輸出層外的所有層使用ReLU激活函數,輸出層使用Tanh。
- 在判別器中的所有層使用LeakyReLU激活函數。
4 對抗訓練的詳細信息
我們在三個數據集上訓練了DCGANs,即Large-scale Scene Understanding (LSUN) (Yu et al., 2015)、Imagenet-1k和一個新組裝的人臉數據集。下面給出了這些數據集的使用細節。除了將訓練圖像縮放到tanh激活函數的范圍[-1, 1]外,沒有對訓練圖像進行任何預處理。所有模型都使用小批量隨機梯度下降(SGD)進行訓練,小批量的大小為128。所有權重都是從標準差為0.02的零中心正態分布初始化的。在LeakyReLU中,所有模型的泄漏斜率都設置為0.2。雖然之前的GAN工作已經使用動量來加速訓練,但我們使用了Adam優化器(Kingma & Ba, 2014)并調整了超參數。我們發現建議的學習率0.001太高,改用0.0002。此外,我們發現將動量項β1保留在建議值0.9會導致訓練震蕩和不穩定,而將其減少到0.5有助于穩定訓練。
4.1 LSUN
隨著生成圖像模型的樣本視覺質量的提高,過擬合和訓練樣本的記憶問題引起了關注。為了展示我們的模型如何隨更多的數據和更高分辨率的生成進行擴展,我們在LSUN臥室數據集上進行了訓練,該數據集包含了略超過300萬的訓練樣本。最近的分析顯示,模型學習的速度與其泛化性能之間存在直接關聯 (Hardt et al., 2015)。我們展示了一次訓練周期的樣本 (圖2),模仿在線學習,以及收斂后的樣本 (圖3),以此為機會證明我們的模型不是通過簡單的過擬合/記憶訓練樣本來產生高質量的樣本。圖片上沒有應用任何數據增強。
圖2:通過數據集進行一次訓練后生成的臥室。從理論上講,模型可以學會記憶訓練樣本,但由于我們使用小學習率和小批量SGD進行訓練,這在實驗上是不太可能的。我們不知道之前有任何實證證據顯示使用SGD和小學習率的記憶效應。

圖3:訓練五次后生成的臥室。在多個樣本中,通過重復的噪聲紋理(例如一些床的底板)似乎有視覺上的欠擬合的證據。

4.1.1 去重
為了進一步降低生成器記憶輸入樣本 (圖2) 的可能性,我們執行了一個簡單的圖像去重過程。我們在訓練樣本的32 × 32下采樣中心裁剪上擬合了一個3072-128-3072的去噪dropout正則化ReLU自編碼器。然后通過閾值化ReLU激活來二值化得到的代碼層激活,這已被證明是一種有效的信息保持技術(Srivastava et al., 2014),并提供了一種方便的語義哈希形式,允許線性時間去重。哈希沖突的視覺檢查顯示了高精度,估計的誤報率小于1/100。此外,這種技術檢測并移除了約275,000個近似重復項,表明回憶率很高。
4.2 人臉
我們從隨機的網絡圖片查詢中爬取了包含人臉的圖片。這些人的名字是從dbpedia獲取的,標準是他們出生在現代時代。這個數據集有300萬圖片,來自10000個人。我們在這些圖片上運行了一個OpenCV面部檢測器,保留了足夠高分辨率的檢測結果,這給我們提供了約350,000個臉部框。我們使用這些臉部框進行訓練。圖片上沒有應用任何數據增強。
4.3 IMAGENET-1K
我們使用Imagenet-1k (Deng et al., 2009) 作為無監督訓練的自然圖像來源。我們在32 × 32的中心裁剪上進行最小尺寸的訓練。圖片上沒有應用任何數據增強。
5 DCGANs的實證驗證
5.1 使用GAN作為特征提取器對CIFAR-10進行分類
對于評估無監督表示學習算法的質量的常見技術是將其作為一個特征提取器應用于監督數據集,并評估基于這些特征的線性模型的性能。
在CIFAR-10數據集上,使用K-means作為特征學習算法的單層特征提取流程已經展示了非常強的基線性能。當使用大量的特征圖(4800)時,此技術達到80.6%的準確率。該基礎算法的無監督多層擴展達到了82.0%的準確率 (Coates & Ng, 2011)。為了評估DCGANs對于監督任務學到的表示的質量,我們在Imagenet-1k上進行訓練,然后使用鑒別器的所有層的卷積特征,對每一層的表示進行最大池化,產生一個4 × 4的空間網格。然后這些特征被展平并連接形成一個28672維的向量,之后在其上面訓練一個正則化的線性L2-SVM分類器。這達到了82.8%的準確率,超過了所有基于K-means的方法。值得注意的是,與基于K-means的技術相比,鑒別器具有更少的特征圖(在最高層有512),但由于4 × 4的空間位置的多層,結果在總特征向量大小上有所增加。DCGANs的性能仍然低于示例CNNs(Dosovitskiy et al., 2015),這是一種在無監督的方式下訓練正常的區分性CNNs,以區分來自源數據集的特定選擇的、大幅增強的、示例樣本。通過微調鑒別器的表示可以進行進一步的改進,但我們將其留給未來的工作。此外,由于我們的DCGAN從未在CIFAR-10上進行過訓練,此實驗還展示了學到的特征的領域魯棒性。
表1:使用我們的預訓練模型對CIFAR-10的分類結果。我們的DCGAN并未在CIFAR-10上進行預訓練,而是在Imagenet-1k上進行的,然后使用這些特征來對CIFAR-10的圖像進行分類。

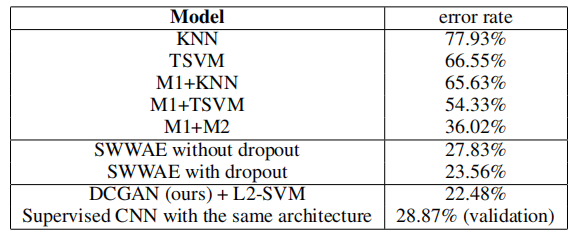
5.2 使用GAN作為特征提取器對SVHN數字進行分類
在街景房屋號碼數據集(SVHN)(Netzer et al., 2011)上,當標記數據稀缺時,我們使用DCGAN的鑒別器的特征進行監督目的。按照CIFAR-10實驗中的類似數據集準備規則,我們從非額外集合中分離出一個包含10,000個樣本的驗證集,并用它進行所有超參數和模型選擇。隨機選擇1000個均勻分布的類別訓練樣本,并在CIFAR-10上使用的同樣的特征提取流程上訓練一個正則化的線性L2-SVM分類器。這達到了22.48%的測試誤差,改進了另一種旨在利用未標記數據的CNNs的修改方法(Zhao et al., 2015)。此外,我們驗證了在DCGAN中使用的CNN架構不是模型性能的主要貢獻因素,通過在同樣的數據上訓練一個純粹的監督CNN,并使用相同的架構,通過對64個超參數試驗進行隨機搜索優化這個模型(Bergstra & Bengio, 2012)。它達到了更高的28.87%的驗證誤差。
6 研究和可視化網絡的內部結構
我們通過多種方式研究已經訓練好的生成器和判別器。我們沒有在訓練集上進行任何類型的最近鄰搜索。像素或特征空間的最近鄰容易被小圖像變換輕易欺騙(Theis等人,2015年)。我們也沒有使用對數似然度量來定量地評估模型,因為它是一個不佳的評估標準(Theis等人,2015年)。
表2:使用1000個標簽對SVHN進行分類
6.1 在潛在空間中行走
我們進行的第一個實驗是為了理解潛在空間的結構。行走在已學習的流形上通常可以告訴我們關于記憶化的跡象(如果存在突然的轉變),以及空間是如何層次化崩潰的。如果在這個潛在空間中的行走導致圖像生成的語義改變(例如對象的添加和刪除),我們可以推理出模型已經學到了相關且有趣的表示。結果展示在圖4中。
圖4:最上面幾行:在Z中9個隨機點之間的插值顯示學到的空間具有平滑的過渡,空間中的每個圖像都像一個臥室。在第6行,你可以看到一個沒有窗戶的房間慢慢變成了一個有巨大窗戶的房間。在第10行,你可以看到一個似乎是電視的東西慢慢變成了一個窗戶。

6.2 可視化判別器特征
以前的工作已經證明,對大型圖像數據集進行CNN的監督訓練可以產生非常強大的學習特征(Zeiler & Fergus, 2014年)。此外,進行場景分類的有監督的CNN可以學習物體探測器(Oquab等人,2014年)。我們證明,一個在大型圖像數據集上無監督訓練的DCGAN也可以學習到一系列有趣的特征。使用(Springenberg等人,2014年)提出的指導反向傳播,我們在圖5中展示了判別器所學的特征在臥室的典型部分(如床和窗戶)上的激活。為了對比,我們在同一圖中給出了隨機初始化特征的基線,這些特征沒有激活任何語義相關或有趣的內容。
圖5:右側顯示的是鑒別器最后一個卷積層中前6個學習到的卷積特征對最大軸向響應的引導反向傳播可視化。請注意,相當一部分特征對床產生響應——這是LSUN臥室數據集中的中心對象。左側是一個隨機濾波器的基線。與前面的響應相比,這里幾乎沒有區分度和隨機結構。

6.3 操縱生成器表示
6.3.1 忘記繪制某些物體
除了判別器學到的表示外,還有生成器學到的表示問題。樣本的質量表明生成器學到了主要場景組件的特定對象表示,如床、窗戶、燈、門和雜項家具。為了探索這些表示的形式,我們進行了一個實驗,試圖完全從生成器中移除窗戶。
在150個樣本上,手工繪制了52個窗戶邊界框。在第二高的卷積層特征上,通過使用在繪制的邊界框內的激活為正和來自同一圖像的隨機樣本為負的標準,對邏輯回歸進行了擬合,以預測特征激活是否在一個窗戶上(或不在)。使用這個簡單的模型,所有權重大于零的特征圖(共200個)都從所有空間位置中刪除。然后,生成了帶有和不帶特征圖移除的隨機新樣本。
帶有和不帶窗戶丟失的生成圖像顯示在圖6中,有趣的是,網絡大部分忘記在臥室中繪制窗戶,用其他物體替換它們。
圖6:頂行:來自模型的未修改樣本。底行:在去除“窗戶”濾鏡后生成的相同樣本。一些窗戶被去除,其他的則被轉化為視覺上相似的對象,如門和鏡子。盡管視覺質量下降,但整體場景組合保持相似,這暗示生成器在從對象表示中分離場景表示方面做得很好。可以進行擴展的實驗,從圖像中去除其他對象,并修改生成器繪制的對象。

6.3.2 面部樣本的向量算術
在評估學習到的單詞表示的上下文中,Mikolov等人(2013)展示了簡單的算術操作在表示空間中揭示了豐富的線性結構。一個經典的例子展示了vector(”King”) - vector(”Man”) + vector(”Woman”)的結果是一個與Queen向量最近鄰的向量。我們研究了我們的生成器的Z表示中是否也有類似的結構。我們對視覺概念的一組典型樣本的Z向量進行了類似的算術操作。只基于每個概念的單個樣本的實驗是不穩定的,但對三個樣例的Z向量取平均后,產生了一致和穩定的生成結果,這些生成結果在語義上遵循了算術。除了在(圖7)中顯示的對象操作外,我們還展示了面部姿勢也在Z空間中被線性地建模(圖8)。
圖7:視覺概念的向量算術。對于每一列,對樣本的Z向量進行平均。然后對平均向量進行算術操作,創建一個新的向量Y。右側中間的樣本是通過將Y作為輸入送入生成器而產生的。為了展示生成器的插值能力,均勻噪聲采樣(尺度為±0.25)被加到Y上,產生了其他8個樣本。在輸入空間(下面兩個示例)應用算術會由于錯位而導致噪聲重疊。

圖8:一個"轉向"向量是由平均了四個樣本所創建的,這些樣本是面部向左看和向右看。通過在這個軸上添加插值到隨機樣本,我們能夠可靠地轉變它們的姿勢。

這些演示表明,可以使用我們的模型學習到的Z表示來開發有趣的應用。已經有之前的證明,條件生成模型可以學習說服力地模擬對象屬性,如尺度、旋轉和位置 (Dosovitskiy et al., 2014)。據我們所知,這是首次在純無監督模型中出現的演示。進一步探索和開發上述向量算術可能會大大減少條件生成建模復雜圖像分布所需的數據量。
7 結論與未來工作
我們提出了一套更穩定的用于訓練生成對抗網絡的架構,并提供證據顯示對抗網絡學習了圖像的好的表示,用于有監督的學習和生成建模。還有一些形式的模型不穩定性存在——我們注意到,隨著模型訓練時間的增長,它們有時會將一部分濾波器折疊到一個單一的振蕩模式。需要進一步的工作來解決這種不穩定性。我們認為,將這個框架擴展到其他領域,如視頻(用于幀預測)和音頻(預訓練的用于語音合成的特征)會非常有趣。對所學習的潛在空間的屬性進行進一步的研究也會很有趣。
致謝
在這項工作中,我們非常幸運并感謝收到的所有建議和指導,特別是Ian Goodfellow、Tobias Springenberg、Arthur Szlam和Durk Kingma的建議。此外,我們還要感謝indico的所有同事提供的支持、資源和交流,特別是indico研究團隊的另外兩名成員,Dan Kuster和Nathan Lintz。最后,我們要感謝Nvidia捐贈的在這項工作中使用的Titan-X GPU。
參考文獻
- Bergstra, James & Bengio, Yoshua. (2012). 隨機搜索用于超參數優化。JMLR。
- Coates, Adam & Ng, Andrew. (2011). 在深度網絡中選擇感受野。NIPS。
- Coates, Adam & Ng, Andrew Y. (2012). 使用 k-means 學習特征表示。在 神經網絡:行業訣竅 (第561–580頁)。Springer。
- Deng, Jia, Dong, Wei, Socher, Richard, Li, Li-Jia, Li, Kai, & Fei-Fei, Li. (2009). ImageNet:一個大規模的分層圖像數據庫。在 計算機視覺和模式識別,2009年。IEEE計算機學會 (第248–255頁)。IEEE。
- Denton, Emily, Chintala, Soumith, Szlam, Arthur, & Fergus, Rob. (2015). 使用拉普拉斯金字塔對抗網絡的深度生成圖像模型。arXiv 預印本 arXiv:1506.05751。
- Dosovitskiy, Alexey, Springenberg, Jost Tobias, & Brox, Thomas. (2014). 使用卷積神經網絡生成椅子。arXiv 預印本 arXiv:1411.5928。
- Dosovitskiy, Alexey 等。 (2015). 利用樣本卷積神經網絡進行判別式無監督特征學習。模式分析與機器智能,IEEE 交易,卷99。IEEE。
- Efros, Alexei 等。 (1999). 非參數采樣進行紋理合成。在 計算機視覺,第七屆 IEEE 國際會議論文集,卷2,第1033–1038頁。IEEE。
- Freeman, William T. 等。 (2002). 基于示例的超分辨率。計算機圖形學與應用,IEEE,22(2):56–65。
- Goodfellow, Ian J. 等。 (2013). Maxout 網絡。arXiv 預印本 arXiv:1302.4389。
- Goodfellow, Ian J. 等。 (2014). 生成對抗網絡。NIPS。
- Gregor, Karol 等。 (2015). Draw:一種用于圖像生成的遞歸神經網絡。arXiv 預印本 arXiv:1502.04623。
- Hardt, Moritz 等。 (2015). 更快地訓練,更好地推廣:隨機梯度下降的穩定性。arXiv 預印本 arXiv:1509.01240。
- Hauberg, Sren 等。 (2015). 夢境更多數據:面向學習數據增強的類相關微分流形分布。arXiv 預印本 arXiv:1510.02795。
- Hays, James & Efros, Alexei A. (2007). 使用數百萬張照片進行場景補全。ACM 圖形學交易 (TOG),26(3):4。
- Ioffe, Sergey & Szegedy, Christian. (2015). 批標準化:通過減少內部協變量轉移加速深度網絡訓練。arXiv 預印本 arXiv:1502.03167。
- Kingma, Diederik P. & Ba, Jimmy Lei. (2014). Adam:一種隨機優化方法。arXiv 預印本 arXiv:1412.6980。
- Kingma, Diederik P. & Welling, Max. (2013). 自編碼變分貝葉斯。arXiv 預印本 arXiv:1312.6114。
- Lee, Honglak 等。 (2009). 用于可擴展無監督學習分層表示的卷積深度置信網絡。在 第26屆國際機器學習年會論文集,第609–616頁。ACM。
- Loosli, Ga?lle 等。 (2007). 使用選擇性采樣訓練不變支持向量機。在 大規模核機器,第301–320頁。MIT出版社,劍橋,馬薩諸塞州。
- Maas, Andrew L. 等。 (2013). 整流器非線性改善神經網絡聲學模型。ICML 會議論文集,卷30。
- Mikolov, Tomas 等。 (2013). 單詞和短語的分布表示及其組合性。在 神經信息處理系統的進展,第3111–3119頁。
- Mordvintsev, Alexander 等。 內省主義:更深入地探索神經網絡。谷歌研究博客。[在線]. 訪問日期:2015年06月17日。
- Nair, Vinod & Hinton, Geoffrey E. (2010). 整流線性單元改善受限玻爾茲曼機。第27屆國際機器學習年會論文集 (ICML-10),第807–814頁。
- Netzer, Yuval 等。 (2011). 使用無監督特征學習在自然圖像中讀取數字。在 NIPS 深度學習和無監督特征學習研討會,卷2011,第5頁。格拉納達,西班牙。
- Oquab, M. 等。 (2014). 使用卷積神經網絡學習和傳遞中層圖像表示。在 CVPR。
- Portilla, Javier & Simoncelli, Eero P. (2000). 基于復雜小波系數聯合統計的參數紋理模型。國際計算機視覺雜志,40(1):49–70。
- Rasmus, Antti 等。 (2015). 使用梯度爬梯子網絡的半監督學習。arXiv 預印本 arXiv:1507.02672。
- Sohl-Dickstein, Jascha 等。 (2015). 使用非平衡熱力學進行深度無監督學習。arXiv 預印本 arXiv:1503.03585。
- Springenberg, Jost Tobias 等。 (2014). 追求簡單:全卷積網絡。arXiv 預印本 arXiv:1412.6806。
- Srivastava, Rupesh Kumar 等。 (2014). 理解局部競爭網絡。arXiv 預印本 arXiv:1410.1165。
- Theis, L. 等。 (2015). 有關生成模型評估的注釋。arXiv:1511.01844。
- Vincent, Pascal 等。 (2010). 堆疊去噪自動編碼器:在具有局部去噪標準的深度網絡中學習有用的表示。機器學習研究雜志,11:3371–3408。
- Xu, Bing 等。 (2015). 在卷積網絡中實證評估整流激活。arXiv 預印本 arXiv:1505.00853。
- Yu, Fisher 等。 (2015). 利用人在循環中的深度學習構建大規模圖像數據集。arXiv 預印本 arXiv:1506.03365。
- Zeiler, Matthew D & Fergus, Rob. (2014). 可視化和理解卷積網絡。在 計算機視覺–ECCV 2014,第818–833頁。Springer。
- Zhao, Junbo 等。 (2015). 堆疊 what-where 自動編碼器。arXiv 預印本 arXiv:1506.02351。
REFERENCES
- Bergstra, James & Bengio, Yoshua. (2012). Random search for hyper-parameter optimization. JMLR.
- Coates, Adam & Ng, Andrew. (2011). Selecting receptive fields in deep networks. NIPS.
- Coates, Adam & Ng, Andrew Y. (2012). Learning feature representations with k-means. In Neural Networks: Tricks of the Trade (pp. 561–580). Springer.
- Deng, Jia, Dong, Wei, Socher, Richard, Li, Li-Jia, Li, Kai, & Fei-Fei, Li. (2009). Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on (pp. 248–255). IEEE.
- Denton, Emily, Chintala, Soumith, Szlam, Arthur, & Fergus, Rob. (2015). Deep generative image models using a laplacian pyramid of adversarial networks. arXiv preprint arXiv:1506.05751.
- Dosovitskiy, Alexey, Springenberg, Jost Tobias, & Brox, Thomas. (2014). Learning to generate chairs with convolutional neural networks. arXiv preprint arXiv:1411.5928.
- Dosovitskiy, Alexey et al. (2015). Discriminative unsupervised feature learning with exemplar convolutional neural networks. Pattern Analysis and Machine Intelligence, IEEE Transactions on, volume 99. IEEE.
- Efros, Alexei et al. (1999). Texture synthesis by non-parametric sampling. In Computer Vision, The Proceedings of the Seventh IEEE International Conference on, volume 2, pp. 1033–1038. IEEE.
- Freeman, William T. et al. (2002). Example-based super-resolution. Computer Graphics and Applications, IEEE, 22(2):56–65.
- Goodfellow, Ian J. et al. (2013). Maxout networks. arXiv preprint arXiv:1302.4389.
- Goodfellow, Ian J. et al. (2014). Generative adversarial nets. NIPS.
- Gregor, Karol et al. (2015). Draw: A recurrent neural network for image generation. arXiv preprint arXiv:1502.04623.
- Hardt, Moritz et al. (2015). Train faster, generalize better: Stability of stochastic gradient descent. arXiv preprint arXiv:1509.01240.
- Hauberg, Sren et al. (2015). Dreaming more data: Class-dependent distributions over diffeomorphisms for learned data augmentation. arXiv preprint arXiv:1510.02795.
- Hays, James & Efros, Alexei A. (2007). Scene completion using millions of photographs. ACM Transactions on Graphics (TOG), 26(3):4.
- Ioffe, Sergey & Szegedy, Christian. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167.
- Kingma, Diederik P. & Ba, Jimmy Lei. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Kingma, Diederik P. & Welling, Max. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
- Lee, Honglak et al. (2009). Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th Annual International Conference on Machine Learning, pp. 609–616. ACM.
- Loosli, Ga?lle et al. (2007). Training invariant support vector machines using selective sampling. In Large Scale Kernel Machines, pp. 301–320. MIT Press, Cambridge, MA.
- Maas, Andrew L. et al. (2013). Rectifier nonlinearities improve neural network acoustic models. Proc. ICML, volume 30.
- Mikolov, Tomas et al. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pp. 3111–3119.
- Mordvintsev, Alexander et al. Inceptionism: Going deeper into neural networks. Google Research Blog. [Online]. Accessed: 2015-06-17.
- Nair, Vinod & Hinton, Geoffrey E. (2010). Rectified linear units improve restricted boltzmann machines. Proceedings of the 27th International Conference on Machine Learning (ICML-10), pp. 807–814.
- Netzer, Yuval et al. (2011). Reading digits in natural images with unsupervised feature learning. In NIPS workshop on deep learning and unsupervised feature learning, volume 2011, pp. 5. Granada, Spain.
- Oquab, M. et al. (2014). Learning and transferring mid-level image representations using convolutional neural networks. In CVPR.
- Portilla, Javier & Simoncelli, Eero P. (2000). A parametric texture model based on joint statistics of complex wavelet coefficients. International Journal of Computer Vision, 40(1):49–70.
- Rasmus, Antti et al. (2015). Semi-supervised learning with ladder network. arXiv preprint arXiv:1507.02672.
- Sohl-Dickstein, Jascha et al. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. arXiv preprint arXiv:1503.03585.
- Springenberg, Jost Tobias et al. (2014). Striving for simplicity: The all convolutional net. arXiv preprint arXiv:1412.6806.
- Srivastava, Rupesh Kumar et al. (2014). Understanding locally competitive networks. arXiv preprint arXiv:1410.1165.
- Theis, L. et al. (2015). A note on the evaluation of generative models. arXiv:1511.01844.
- Vincent, Pascal et al. (2010). Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. The Journal of Machine Learning Research, 11:3371–3408.
- Xu, Bing et al. (2015). Empirical evaluation of rectified activations in convolutional network. arXiv preprint arXiv:1505.00853.
- Yu, Fisher et al. (2015). Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365.
- Zeiler, Matthew D & Fergus, Rob. (2014). Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014, pp. 818–833. Springer.
- Zhao, Junbo et al. (2015). Stacked what-where auto-encoders. arXiv preprint arXiv:1506.02351.
8 附加材料
8.1 評估 DCGAN 對捕捉數據分布的能力
我們提出在我們模型的條件版本上應用標準分類指標,評估所學的條件分布。我們在 MNIST 數據集上訓練了一個 DCGAN(將其中的 1 萬個樣本用作驗證集),同時還訓練了一個置換不變的 GAN 基線,并使用最近鄰分類器評估了這些模型,將真實數據與一組生成的條件樣本進行比較。我們發現,從批歸一化中移除尺度和偏置參數可以為這兩個模型帶來更好的結果。我們推測,批歸一化引入的噪聲有助于生成模型更好地探索底層數據分布并從中生成樣本。結果在表 3 中展示了出來,該表將我們的模型與其他技術進行了比較。DCGAN 模型在測試誤差方面達到了與在訓練數據集上擬合的最近鄰分類器相同的水平,這表明 DCGAN 模型在建模該數據集的條件分布方面表現出色。在每個類別一百萬個樣本的情況下,DCGAN 模型的性能超過了 InfiMNIST(Loosli 等,2007),這是一個手工開發的數據增強流程,它使用訓練樣本的平移和彈性變形。DCGAN 在與一種使用了學習的每類別變換的概率生成數據增強技術(Hauberg 等,2015)競爭時表現出色,同時更加通用,因為它直接對數據進行建模,而不是數據的變換。
表3:最近鄰分類結果

圖9:并排示例圖(從左到右)顯示了 MNIST 數據集、基線 GAN 生成以及我們的 DCGAN 生成結果。

圖10:更多來自我們的人臉 DCGAN 的生成圖像。

圖11:在 Imagenet-1k 數據集上訓練的 DCGAN 的生成圖像。






 CUDA 硬件實現)











| 最簡單的實例升級)

-三維堆積柱形圖(3D Stacked Bar Chart))