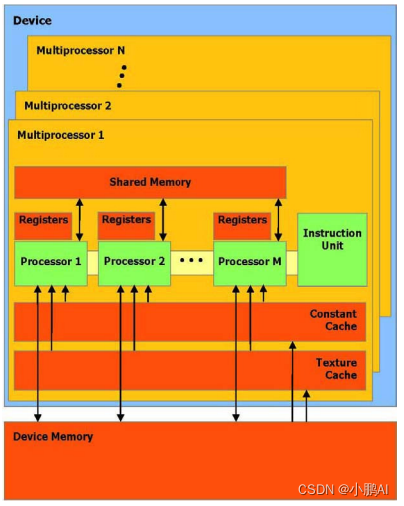
一組帶有on-chip 共享內存的SIMD多處理器
GPU可以被看作一組多處理器, 每個多處理器使用單一指令,多數據架構(SIMD)【單指令流多數據流】
在任何給定的時鐘周期內,多處理器的每個處理器執行同一指令,但操作不同的數據
每個多處理器使用以下四種類型的on-chip(集成的)內存:
- 每個處理器一組本地32位寄存器
- 并行數據緩存或共享內存,被所有處理器共享實現內存空間共享
- 通過設備內存的一個只讀區域,一個只讀常量緩沖器被所有處理器共享
- 通過設備內存的一個只讀區域,一個只讀紋理緩沖器被所有處理器共享
本地和全局內存空間作為設備內存的讀寫區域,而不被緩沖
每個多處理器通過紋理單元訪問紋理緩沖器,它執行各種各樣的尋址模式和數據過濾
執行模式
一個線程塊柵格是通過多處理器規劃執行的
一個塊只被一個多處理器處理,因此可以對駐留在on-chip 共享內存中的共享內存空間形成非常快速的訪問
一個批處理中每一個多處理器可以處理多少個塊,取決于每個線程中分配了多少個寄存器和已知內核中每個時鐘需要多少的共享內存
因為多處理器的寄存器和內存在所有的線程中是分開的
如果在至少一個塊中,每個多處理器沒有足夠的寄存器或共享內存可用,那么內核將無法啟動
線程塊在一個批處理中被一個多處理器執行,被稱作active
每個active 塊被劃分成為SIMD 線程組,稱為warps
每一條這樣的warp 包含數量相同的線程,叫做warp 大小,并且在SIMD 方式下通過多處理器執行
線程調度程序周期性地從一條warp 切換到另一條warp,以達到多處理器計算資源使用的最大化!
塊被劃分成為warp 的方式是相同的
每條warp 包含連續的線程,線程索引從第一個warp 包含著的線程0 開始遞增
一個多處理器可以處理并發地幾個塊,通過劃分在它們之中的寄存器和共享內存
更準確地說,每條線程可使用的寄存器數量,等于每個多處理器寄存器總數除以并發的線程數量
并發線程的數量等于并發塊的數量乘以每塊線程的數量
在一個塊內的warp 次序是未定義的,但通過協調全局或者共享內存的存取,它們可以同步的執行
如果一個通過warp 線程執行的指令寫入全局或共享內存的同一位置,寫的次序是未定義的
在一個線程塊柵格內的塊次序是未定義的,并且在塊之間不存在同步機制
因此來自同一個柵格的二個不同塊的線程不能通過全局內存彼此安全地通訊
計算兼容性
設備的計算兼容性由兩個參數定義,主要版本號和次要版本號
設備擁有相同的主要版本號代表相同的核心架構
次要版本號代表一些改進的核心架構,比如新的特性
多設備
為一個應用程序使用多GPU 作為CUDA 設備,必須保證這些GPU 是一樣的類型
如果系統工作在SLI 模式下,那么只有一個GPU 可以作為CUDA 設備
因為所有的GPU 在驅動堆棧中被底層的融合了
SLI 模式需要在關閉,這樣才能使用多個GPU 作為CUDA設備
模式切換
GPU 指定一些DRAM 來存儲被稱作primary surface 的內容,這些內容被用于顯示輸出
如果用戶改變顯示的分辨率或者色差,那么primary surface 的存儲需求量將改變
如果用戶將顯示分辨率從1280x1024x32bit 到1600x1200x32bit
那么,系統必須指定7.68MB 的primary surface 而不在是5.24MB
(使全屏抗鋸齒的應用程序需要更多的primary surface空間)
如果模式切換增加了primary surface 的內存空間,系統將會占用CUDA 所指定的內存空間,導致OOM。
什么是紋理緩沖器
紋理存儲器(texture memory)是一種只讀存儲器,由GPU用于紋理渲染的的圖形專用單元發展而來,因此也提供了一些特殊功能。
紋理緩存的優勢:
紋理緩存具備硬件插值特性,可以實現最近鄰插值和線性插值。紋理緩存針對二維空間的局部性訪問進行了優化,所以通過紋理緩存訪問二維矩陣的鄰域會獲得加速。紋理緩存不需要滿足全局內存的合并訪問條件。
紋理可以是一段連續的設備內存,也可以是一個CUDA數組。但是CUDA數組對局部尋址有優化,稱為“塊線性”,原理是將鄰域元素緩存在同一條cache線上,這將加快鄰域內的尋址,但是對于設備內存,并沒有“塊線性”。所以,選擇采用CUDA數組,還是設備內存,需要根據實際情況決定,將數據copy至CUDA數組是很耗時的。











| 最簡單的實例升級)

-三維堆積柱形圖(3D Stacked Bar Chart))


——使用docker-compose安裝redis)


