Numpy基礎應用
Numpy 是一個開源的 Python 科學計算庫,用于快速處理任意維度的數組。Numpy 支持常見的數組和矩陣操作,對于同樣的數值計算任務,使用 NumPy 不僅代碼要簡潔的多,而且 NumPy 的性能遠遠優于原生 Python,基本是一個到兩個數量級的差距,而且數據量越大,NumPy 的優勢就越明顯。
Numpy 最為核心的數據類型是ndarray,使用ndarray可以處理一維、二維和多維數組,該對象相當于是一個快速而靈活的大數據容器。NumPy 底層代碼使用 C 語言編寫,解決了 GIL 的限制,ndarray在存取數據的時候,數據與數據的地址都是連續的,這確保了可以進行高效率的批量操作,遠遠優于 Python 中的list;另一方面ndarray對象提供了更多的方法來處理數據,尤其是和統計相關的方法,這些方法也是 Python 原生的list沒有的。
全部文章請訪問專欄:《Python全棧教程(0基礎)》
再推薦一下最近熱更的:《大廠測試高頻面試題詳解》 該專欄對近年高頻測試相關面試題做詳細解答,結合自己多年工作經驗,以及同行大佬指導總結出來的。旨在幫助測試、python方面的同學,順利通過面試,拿到自己滿意的offer!
文章目錄
- Numpy基礎應用
- 準備工作
- 創建數組對象
- 一維數組
- 二維數組
- 多維數組
- 數組對象的屬性
- 數組的索引和切片
- 案例:通過數組切片處理圖像
- 數組對象的方法
- 統計方法
- 其他方法
準備工作
-
啟動Notebook
jupyter notebook提示:在啟動Notebook之前,建議先安裝好數據分析相關依賴項,包括之前提到的三大神器以及相關依賴項,包括:
numpy、pandas、matplotlib、openpyxl等。如果使用Anaconda,則無需單獨安裝。 -
導入
import numpy as np import pandas as pd import matplotlib.pyplot as plt說明:如果已經啟動了 Notebook 但尚未安裝相關依賴庫,例如尚未安裝
numpy,可以在 Notebook 的單元格中輸入!pip install numpy并運行該單元格來安裝 NumPy,也可以一次性安裝多個三方庫,需要在單元格中輸入%pip install numpy pandas matplotlib。注意上面的代碼,我們不僅導入了NumPy,還將 pandas 和 matplotlib 庫一并導入了。
創建數組對象
創建ndarray對象有很多種方法,下面就如何創建一維數組、二維數組和多維數組進行說明。
一維數組
-
方法一:使用
array函數,通過list創建數組對象代碼:
array1 = np.array([1, 2, 3, 4, 5]) array1輸出:
array([1, 2, 3, 4, 5]) -
方法二:使用
arange函數,指定取值范圍創建數組對象代碼:
array2 = np.arange(0, 20, 2) array2輸出:
array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18]) -
方法三:使用
linspace函數,用指定范圍均勻間隔的數字創建數組對象代碼:
array3 = np.linspace(-5, 5, 101) array3輸出:
array([-5. , -4.9, -4.8, -4.7, -4.6, -4.5, -4.4, -4.3, -4.2, -4.1, -4. ,-3.9, -3.8, -3.7, -3.6, -3.5, -3.4, -3.3, -3.2, -3.1, -3. , -2.9,-2.8, -2.7, -2.6, -2.5, -2.4, -2.3, -2.2, -2.1, -2. , -1.9, -1.8,-1.7, -1.6, -1.5, -1.4, -1.3, -1.2, -1.1, -1. , -0.9, -0.8, -0.7,-0.6, -0.5, -0.4, -0.3, -0.2, -0.1, 0. , 0.1, 0.2, 0.3, 0.4,0.5, 0.6, 0.7, 0.8, 0.9, 1. , 1.1, 1.2, 1.3, 1.4, 1.5,1.6, 1.7, 1.8, 1.9, 2. , 2.1, 2.2, 2.3, 2.4, 2.5, 2.6,2.7, 2.8, 2.9, 3. , 3.1, 3.2, 3.3, 3.4, 3.5, 3.6, 3.7,3.8, 3.9, 4. , 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 4.7, 4.8,4.9, 5. ]) -
方法四:使用
numpy.random模塊的函數生成隨機數創建數組對象產生10個 [ 0 , 1 ) [0, 1) [0,1)范圍的隨機小數,代碼:
array4 = np.random.rand(10) array4輸出:
array([0.45556132, 0.67871326, 0.4552213 , 0.96671509, 0.44086463,0.72650875, 0.79877188, 0.12153022, 0.24762739, 0.6669852 ])產生10個 [ 1 , 100 ) [1, 100) [1,100)范圍的隨機整數,代碼:
array5 = np.random.randint(1, 100, 10) array5輸出:
array([29, 97, 87, 47, 39, 19, 71, 32, 79, 34])產生20個 μ = 50 \mu=50 μ=50, σ = 10 \sigma=10 σ=10的正態分布隨機數,代碼:
array6 = np.random.normal(50, 10, 20) array6輸出:
array([55.04155586, 46.43510797, 20.28371158, 62.67884053, 61.23185964,38.22682148, 53.17126151, 43.54741592, 36.11268017, 40.94086676,63.27911699, 46.92688903, 37.1593374 , 67.06525656, 67.47269463,23.37925889, 31.45312239, 48.34532466, 55.09180924, 47.95702787])
說明:創建一維數組還有很多其他的方式,比如通過讀取字符串、讀取文件、解析正則表達式等方式,這里我們暫不討論這些方式,有興趣的讀者可以自行研究。
二維數組
-
方法一:使用
array函數,通過嵌套的list創建數組對象代碼:
array7 = np.array([[1, 2, 3], [4, 5, 6]]) array7輸出:
array([[1, 2, 3],[4, 5, 6]]) -
方法二:使用
zeros、ones、full函數指定數組的形狀創建數組對象使用
zeros函數,代碼:array8 = np.zeros((3, 4)) array8輸出:
array([[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]])使用
ones函數,代碼:array9 = np.ones((3, 4)) array9輸出:
array([[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]])使用
full函數,代碼:array10 = np.full((3, 4), 10) array10輸出:
array([[10, 10, 10, 10],[10, 10, 10, 10],[10, 10, 10, 10]]) -
方法三:使用eye函數創建單位矩陣
代碼:
array11 = np.eye(4) array11輸出:
array([[1., 0., 0., 0.],[0., 1., 0., 0.],[0., 0., 1., 0.],[0., 0., 0., 1.]]) -
方法四:通過
reshape將一維數組變成二維數組代碼:
array12 = np.array([1, 2, 3, 4, 5, 6]).reshape(2, 3) array12輸出:
array([[1, 2, 3],[4, 5, 6]])提示:
reshape是ndarray對象的一個方法,使用reshape方法時需要確保調形后的數組元素個數與調形前數組元素個數保持一致,否則將會產生異常。 -
方法五:通過
numpy.random模塊的函數生成隨機數創建數組對象產生 [ 0 , 1 ) [0, 1) [0,1)范圍的隨機小數構成的3行4列的二維數組,代碼:
array13 = np.random.rand(3, 4) array13輸出:
array([[0.54017809, 0.46797771, 0.78291445, 0.79501326],[0.93973783, 0.21434806, 0.03592874, 0.88838892],[0.84130479, 0.3566601 , 0.99935473, 0.26353598]])產生 [ 1 , 100 ) [1, 100) [1,100)范圍的隨機整數構成的3行4列的二維數組,代碼:
array14 = np.random.randint(1, 100, (3, 4)) array14輸出:
array([[83, 30, 64, 53],[39, 92, 53, 43],[43, 48, 91, 72]])
多維數組
-
使用隨機的方式創建多維數組
代碼:
array15 = np.random.randint(1, 100, (3, 4, 5)) array15輸出:
array([[[94, 26, 49, 24, 43],[27, 27, 33, 98, 33],[13, 73, 6, 1, 77],[54, 32, 51, 86, 59]],[[62, 75, 62, 29, 87],[90, 26, 6, 79, 41],[31, 15, 32, 56, 64],[37, 84, 61, 71, 71]],[[45, 24, 78, 77, 41],[75, 37, 4, 74, 93],[ 1, 36, 36, 60, 43],[23, 84, 44, 89, 79]]]) -
將一維二維的數組調形為多維數組
一維數組調形為多維數組,代碼:
array16 = np.arange(1, 25).reshape((2, 3, 4)) array16輸出:
array([[[ 1, 2, 3, 4],[ 5, 6, 7, 8],[ 9, 10, 11, 12]],[[13, 14, 15, 16],[17, 18, 19, 20],[21, 22, 23, 24]]])二維數組調形為多維數組,代碼:
array17 = np.random.randint(1, 100, (4, 6)).reshape((4, 3, 2)) array17輸出:
array([[[60, 59],[31, 80],[54, 91]],[[67, 4],[ 4, 59],[47, 49]],[[16, 4],[ 5, 71],[80, 53]],[[38, 49],[70, 5],[76, 80]]]) -
讀取圖片獲得對應的三維數組
代碼:
array18 = plt.imread('guido.jpg') array18輸出:
array([[[ 36, 33, 28],[ 36, 33, 28],[ 36, 33, 28],...,[ 32, 31, 29],[ 32, 31, 27],[ 31, 32, 26]],[[ 37, 34, 29],[ 38, 35, 30],[ 38, 35, 30],...,[ 31, 30, 28],[ 31, 30, 26],[ 30, 31, 25]],[[ 38, 35, 30],[ 38, 35, 30],[ 38, 35, 30],...,[ 30, 29, 27],[ 30, 29, 25],[ 29, 30, 25]],...,[[239, 178, 123],[237, 176, 121],[235, 174, 119],...,[ 78, 68, 56],[ 75, 67, 54],[ 73, 65, 52]],[[238, 177, 120],[236, 175, 118],[234, 173, 116],...,[ 82, 70, 58],[ 78, 68, 56],[ 75, 66, 51]],[[238, 176, 119],[236, 175, 118],[234, 173, 116],...,[ 84, 70, 61],[ 81, 69, 57],[ 79, 67, 53]]], dtype=uint8)說明:上面的代碼讀取了當前路徑下名為
guido.jpg的圖片文件,計算機系統中的圖片通常由若干行若干列的像素點構成,而每個像素點又是由紅綠藍三原色構成的,所以能夠用三維數組來表示。讀取圖片用到了matplotlib庫的imread函數。
數組對象的屬性
-
size屬性:數組元素個數代碼:
array19 = np.arange(1, 100, 2) array20 = np.random.rand(3, 4) print(array19.size, array20.size)輸出:
50 12 -
shape屬性:數組的形狀代碼:
print(array19.shape, array20.shape)輸出:
(50,) (3, 4) -
dtype屬性:數組元素的數據類型代碼:
print(array19.dtype, array20.dtype)輸出:
int64 float64ndarray對象元素的數據類型可以參考如下所示的表格。
-
ndim屬性:數組的維度代碼:
print(array19.ndim, array20.ndim)輸出:
1 2 -
itemsize屬性:數組單個元素占用內存空間的字節數代碼:
array21 = np.arange(1, 100, 2, dtype=np.int8) print(array19.itemsize, array20.itemsize, array21.itemsize)輸出:
8 8 1說明:在使用
arange創建數組對象時,通過dtype參數指定元素的數據類型。可以看出,np.int8代表的是8位有符號整數,只占用1個字節的內存空間,取值范圍是 [ ? 128 , 127 ] [-128,127] [?128,127]。 -
nbytes屬性:數組所有元素占用內存空間的字節數代碼:
print(array19.nbytes, array20.nbytes, array21.nbytes)輸出:
400 96 50 -
flat屬性:數組(一維化之后)元素的迭代器代碼:
from typing import Iterableprint(isinstance(array20.flat, np.ndarray), isinstance(array20.flat, Iterable))輸出:
False True -
base屬性:數組的基對象(如果數組共享了其他數組的內存空間)代碼:
array22 = array19[:] print(array22.base is array19, array22.base is array21)輸出:
True False說明:上面的代碼用到了數組的切片操作,它類似于 Python 中
list類型的切片,但在細節上又不完全相同,下面會專門講解這個知識點。通過上面的代碼可以發現,ndarray切片后得到的新的數組對象跟原來的數組對象共享了內存中的數據,因此array22的base屬性就是array19對應的數組對象。
數組的索引和切片
和 Python 中的列表類似,NumPy 的ndarray對象可以進行索引和切片操作,通過索引可以獲取或修改數組中的元素,通過切片可以取出數組的一部分。
-
索引運算(普通索引)
一維數組,代碼:
array23 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9]) print(array23[0], array23[array23.size - 1]) print(array23[-array23.size], array23[-1])輸出:
1 9 1 9二維數組,代碼:
array24 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) print(array24[2]) print(array24[0][0], array24[-1][-1]) print(array24[1][1], array24[1, 1])輸出:
[7 8 9] 1 9 5 5 [[ 1 2 3][ 4 10 6][ 7 8 9]]代碼:
array24[1][1] = 10 print(array24) array24[1] = [10, 11, 12] print(array24)輸出:
[[ 1 2 3][ 4 10 6][ 7 8 9]] [[ 1 2 3][10 11 12][ 7 8 9]] -
切片運算(切片索引)
切片是形如
[開始索引:結束索引:步長]的語法,通過指定開始索引(默認值無窮小)、結束索引(默認值無窮大)和步長(默認值1),從數組中取出指定部分的元素并構成新的數組。因為開始索引、結束索引和步長都有默認值,所以它們都可以省略,如果不指定步長,第二個冒號也可以省略。一維數組的切片運算跟 Python 中的list類型的切片非常類似,此處不再贅述,二維數組的切片可以參考下面的代碼,相信非常容易理解。代碼:
print(array24[:2, 1:])輸出:
[[2 3][5 6]]代碼:
print(array24[2]) print(array24[2, :])輸出:
[7 8 9] [7 8 9]代碼:
print(array24[2:, :])輸出:
[[7 8 9]]代碼:
print(array24[:, :2])輸出:
[[1 2][4 5][7 8]]代碼:
print(array24[1, :2]) print(array24[1:2, :2])輸出:
[4 5] [[4 5]]代碼:
print(array24[::2, ::2])輸出:
[[1 3][7 9]]代碼:
print(array24[::-2, ::-2])輸出:
[[9 7][3 1]]關于數組的索引和切片運算,大家可以通過下面的兩張圖來增強印象,這兩張圖來自《利用Python進行數據分析》一書,它是
pandas庫的作者 Wes McKinney 撰寫的 Python 數據分析領域的經典教科書,有興趣的讀者可以購買和閱讀原書。

-
花式索引(fancy index)
花式索引(Fancy indexing)是指利用整數數組進行索引,這里所說的整數數組可以是 NumPy 的
ndarray,也可以是 Python 中list、tuple等可迭代類型,可以使用正向或負向索引。一維數組的花式索引,代碼:
array25 = np.array([50, 30, 15, 20, 40]) array25[[0, 1, -1]]輸出:
array([50, 30, 40])二維數組的花式索引,代碼:
array26 = np.array([[30, 20, 10], [40, 60, 50], [10, 90, 80]]) # 取二維數組的第1行和第3行 array26[[0, 2]]輸出:
array([[30, 20, 10],[10, 90, 80]])代碼:
# 取二維數組第1行第2列,第3行第3列的兩個元素 array26[[0, 2], [1, 2]]輸出:
array([20, 80])代碼:
# 取二維數組第1行第2列,第3行第2列的兩個元素 array26[[0, 2], 1]輸出:
array([20, 90]) -
布爾索引
布爾索引就是通過布爾類型的數組對數組元素進行索引,布爾類型的數組可以手動構造,也可以通過關系運算來產生布爾類型的數組。
代碼:
array27 = np.arange(1, 10) array27[[True, False, True, True, False, False, False, False, True]]輸出:
array([1, 3, 4, 9])代碼:
array27 >= 5輸出:
array([False, False, False, False, True, True, True, True, True])代碼:
# ~運算符可以實現邏輯變反,看看運行結果跟上面有什么不同 ~(array27 >= 5)輸出:
array([ True, True, True, True, False, False, False, False, False])代碼:
array27[array27 >= 5]輸出:
array([5, 6, 7, 8, 9])
提示:切片操作雖然創建了新的數組對象,但是新數組和原數組共享了數組中的數據,簡單的說,如果通過新數組對象或原數組對象修改數組中的數據,其實修改的是同一塊數據。花式索引和布爾索引也會創建新的數組對象,而且新數組復制了原數組的元素,新數組和原數組并不是共享數據的關系,這一點通過前面講的數組的
base屬性也可以了解到,在使用的時候要引起注意。
案例:通過數組切片處理圖像
學習基礎知識總是比較枯燥且沒有成就感的,所以我們還是來個案例為大家演示下上面學習的數組索引和切片操作到底有什么用。前面我們說到過,可以用三維數組來表示圖像,那么通過圖像對應的三維數組進行操作,就可以實現對圖像的處理,如下所示。
讀入圖片創建三維數組對象。
guido_image = plt.imread('guido.jpg')
plt.imshow(guido_image)
對數組的0軸進行反向切片,實現圖像的垂直翻轉。
plt.imshow(guido_image[::-1])

對數組的1軸進行反向切片,實現圖像的水平翻轉。
plt.imshow(guido_image[:,::-1])
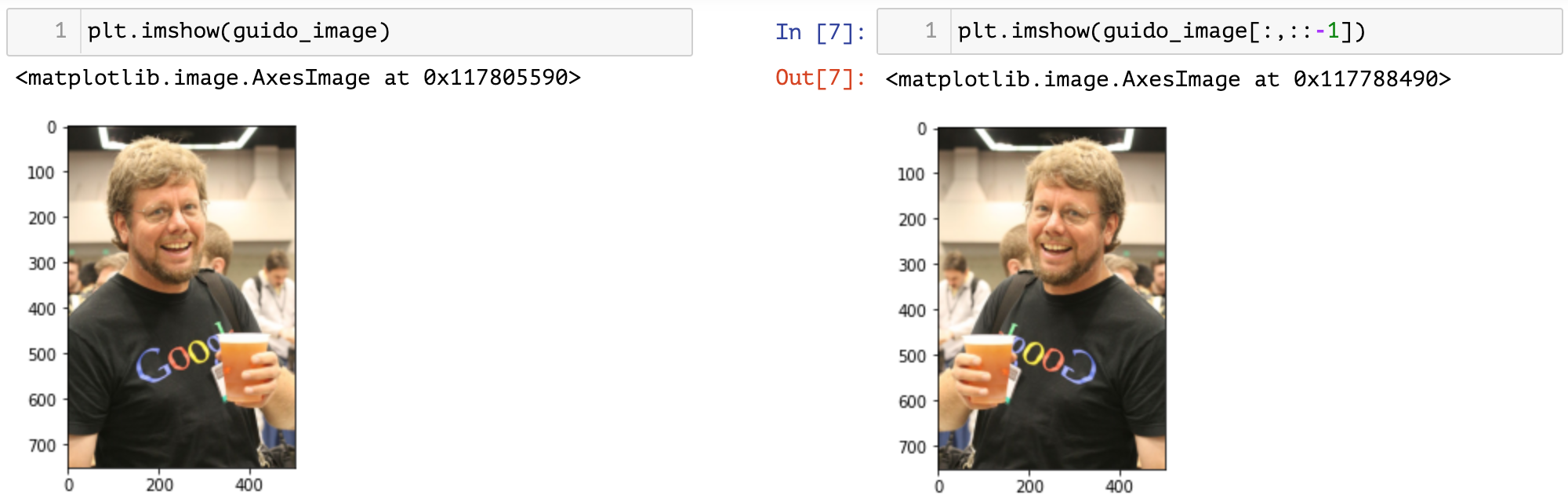
將 Guido 的頭切出來。
plt.imshow(guido_image[30:350, 90:300])

數組對象的方法
統計方法
統計方法主要包括:sum()、mean()、std()、var()、min()、max()、argmin()、argmax()、cumsum()等,分別用于對數組中的元素求和、求平均、求標準差、求方差、找最大、找最小、求累積和等,請參考下面的代碼。
array28 = np.array([1, 2, 3, 4, 5, 5, 4, 3, 2, 1])
print(array28.sum())
print(array28.mean())
print(array28.max())
print(array28.min())
print(array28.std())
print(array28.var())
print(array28.cumsum())
輸出:
30
3.0
5
1
1.4142135623730951
2.0
[ 1 3 6 10 15 20 24 27 29 30]
其他方法
-
all()/any()方法:判斷數組是否所有元素都是True/ 判斷數組是否有為True的元素。 -
astype()方法:拷貝數組,并將數組中的元素轉換為指定的類型。 -
dump()方法:保存數組到文件中,可以通過 NumPy 中的load()函數從保存的文件中加載數據創建數組。代碼:
array31.dump('array31-data') array32 = np.load('array31-data', allow_pickle=True) array32輸出:
array([[1, 2],[3, 4],[5, 6]]) -
fill()方法:向數組中填充指定的元素。 -
flatten()方法:將多維數組扁平化為一維數組。代碼:
array32.flatten()輸出:
array([1, 2, 3, 4, 5, 6]) -
nonzero()方法:返回非0元素的索引。 -
round()方法:對數組中的元素做四舍五入操作。 -
sort()方法:對數組進行就地排序。代碼:
array33 = np.array([35, 96, 12, 78, 66, 54, 40, 82]) array33.sort() array33輸出:
array([12, 35, 40, 54, 66, 78, 82, 96]) -
swapaxes()和transpose()方法:交換數組指定的軸。代碼:
# 指定需要交換的兩個軸,順序無所謂 array32.swapaxes(0, 1)輸出:
array([[1, 3, 5],[2, 4, 6]])代碼:
# 對于二維數組,transpose相當于實現了矩陣的轉置 array32.transpose()輸出:
array([[1, 3, 5],[2, 4, 6]]) -
tolist()方法:將數組轉成Python中的list。


 CUDA 硬件實現)











| 最簡單的實例升級)

-三維堆積柱形圖(3D Stacked Bar Chart))


——使用docker-compose安裝redis)