1. 什么是 Hash
1.1 Hash 函數
Hash 本身其實是一個函數,又被稱為散列函數,它可以大幅提高我們對數據的檢索效率。因為它是散列的,所以在存儲數據的時候,它也是無序的。
Hash 算法是通過某種確定性的算法(例如MD5,SHA1,SHA2,SHA3)將輸入轉變成輸出,相同的輸入結果永遠會得到相同的輸出。
1.2 Hash 碰撞
熟悉Java中 HashMap 的同學應該都知道,我們在往Map集合中存放元素的時候,它會先對要往集合中存放的元素的key值做一個哈希運算,從而確定它要存入的位置。理論上每一個對象都會存放在不同的地方,但當存放的對象越來越多時,有可能后來添加的元素的key值計算得出的結果與之前已經存入的元素的key的哈希值相等,這種現象就被稱為哈希碰撞。當產生哈希碰撞的時候,我們會將后添加的元素與之前就已經存在的元素形成一個鏈表,當再次發生哈希碰撞時,就繼續在鏈表尾部添加即可。
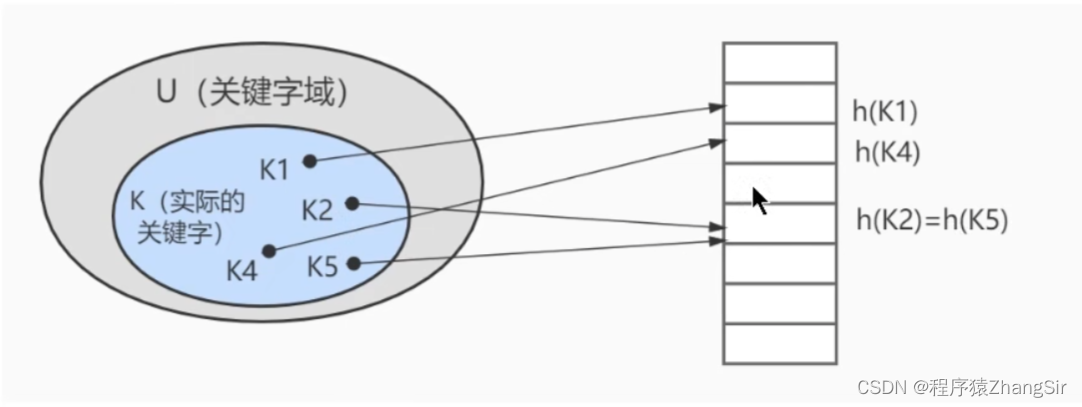
如下圖所示,我們也可以采取這種方式將數據庫中的數據以哈希的方式存儲到哈希表中,可以看到h(k2)與h(k5)?就產生了哈希碰撞。
1.3 HashMap 的時間復雜度
我們知道,HashMap 其實就是一個數組,它是有下標的,我們在 查詢/刪除/修改 元素的時候,都可以直接通過哈希函數計算出來的哈希值精確到某個元素的位置,這里我們不考慮哈希碰撞形成的鏈表,因此 HashMap 的查詢/刪除/修改 元素的時間復雜度都是O(1),也就是常量級別的,可以說是非常非常快。
2. AVL樹
2.1 簡單了解AVL樹
AVL樹,其實也叫平衡二叉樹,或叫平衡二叉搜索樹,它通常滿足一個特點,左子節點的值都比父節點小,右子節點的值都比父節點大,如下圖所示
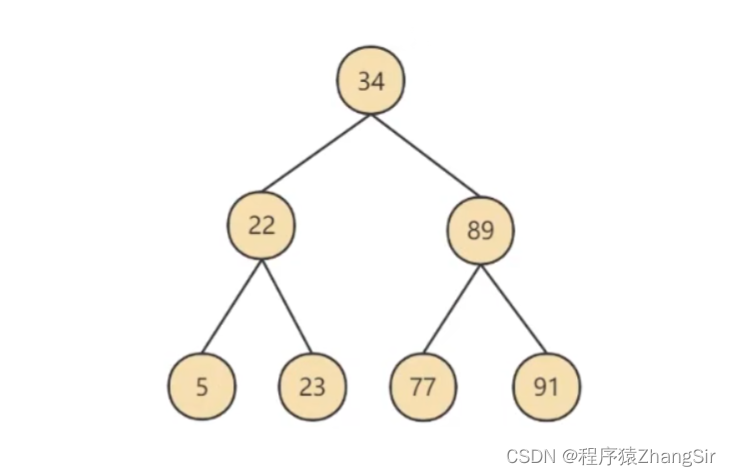
在這種情況下,我們去尋找數據91,只需要查找三次即可得出結果。
2.2 AVL樹的時間復雜度
從上面我舉得例子不難看出,在AVL樹中查找數據時,每查找一次,砍掉一半的數據,再查找一次,再砍掉一半的數據,所以不難看出,AVL樹的時間復雜度是 O(log2n)。
2.3 AVL樹的缺點
AVL樹時間復雜度雖然低,但也存在一些缺點,因為AVL樹要保持高度的平衡,所以需要經常性旋轉,旋轉也是非常耗費時間,并且,隨著數據越來越多,AVL樹的深度也會越來越大,如下圖所示,當數據達到31個的時候,樹的高度已經有5層了。我們知道,每多一層,與磁盤就要多進行一次IO操作,非常耗費時間,所以我們就在想,能不能把樹的高度降低一些,但同時又能存足量的元素呢?這就有了下面要說M叉樹,也可以理解為B樹。

3. B 樹
經過了上面對AVL樹的分析,我們也知道了,當樹的叉越多時,存儲的數據也越多,與磁盤交互的次數也越少,我們把上方的二叉樹轉換成三叉樹,當然也可以轉換成四叉樹,五叉樹都是可以的,這里我就以三叉樹為例。

這個時候,我們還是能存儲31個元素,并且樹的高度由原來的5層降低到了4層,提高了我們數據的查找效率,這就是我們索引的雛形,我們就可以將數據庫中的數據存儲在樹中,得到如下簡易模型
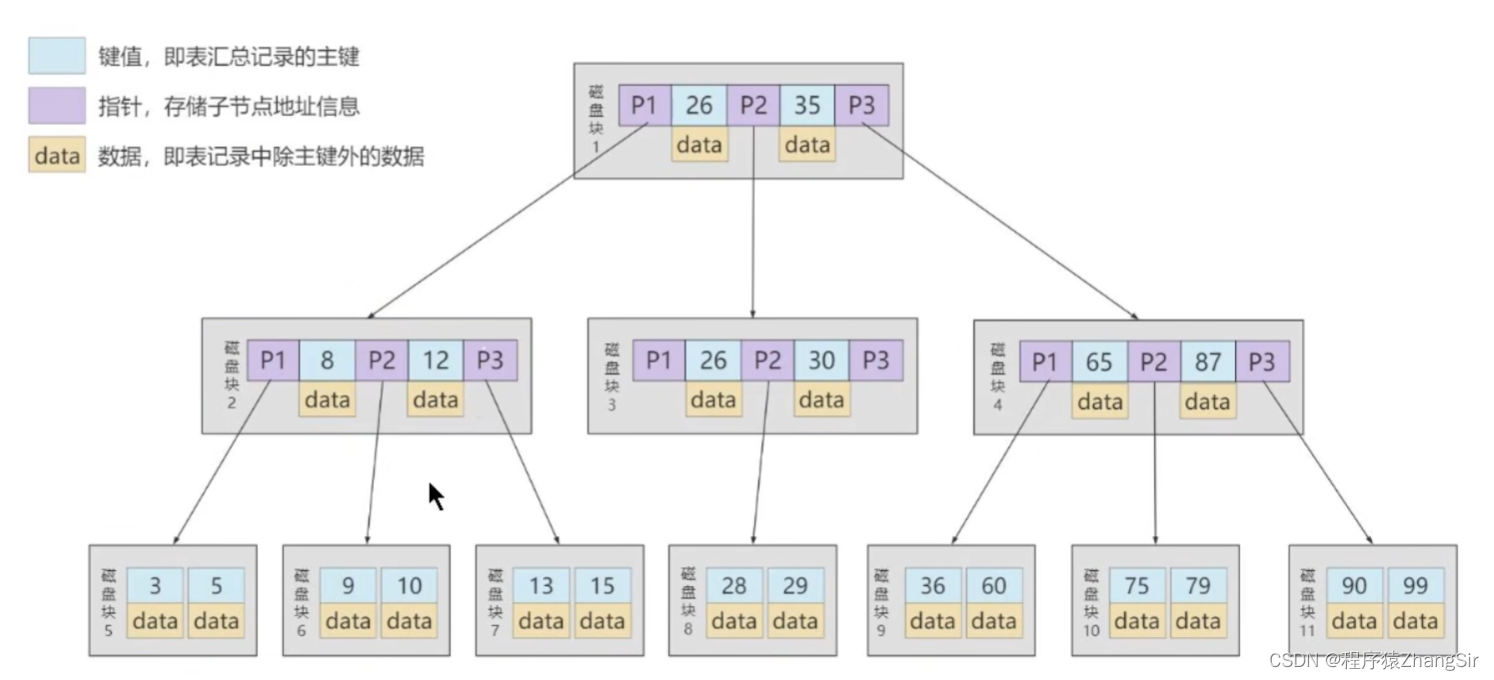
上圖中就是索引最開始形成的B樹結構圖,左上角也有標注,這個時候我們可以看到,在原始B樹中,磁盤塊1234這幾個非根節點中還存放著數據呢,P1是地址值指向磁盤塊2,并且里面記錄的主鍵值都是小于26的;P3是地址值指向磁盤塊4,里面記錄的數據主鍵值都是大于35的;P2是地址值指向磁盤塊3,里面記錄的數據主鍵值都是在26與35之間的。下方的磁盤塊2,3,4中都是同理,依次往下類推。
這種數據的存儲方式和查找方式性能已經非常優秀了,但是還有一個缺點,我們將原來的2叉樹轉變成M多叉樹,目的就是為了存儲更多的數據,但大家看,在磁盤塊2,3,4中,P1,P2,P3都是指針,不會占用多少空間,但8和12的data存儲的是真實的數據,會占用部分磁盤空間,而且這個時候還有分成了三段,如果分的段更多,也會存儲更多的數據,這就會導致我們無法存儲更多的指針數據,違背了我們的初衷。于是,我們就可以對這個B樹做進一步的升級(當然也不只是因為這一個原因,后面我們還會說到,這里先說這一點就)演化成了我們現在的 B+ 樹結構。
4. B+ 樹
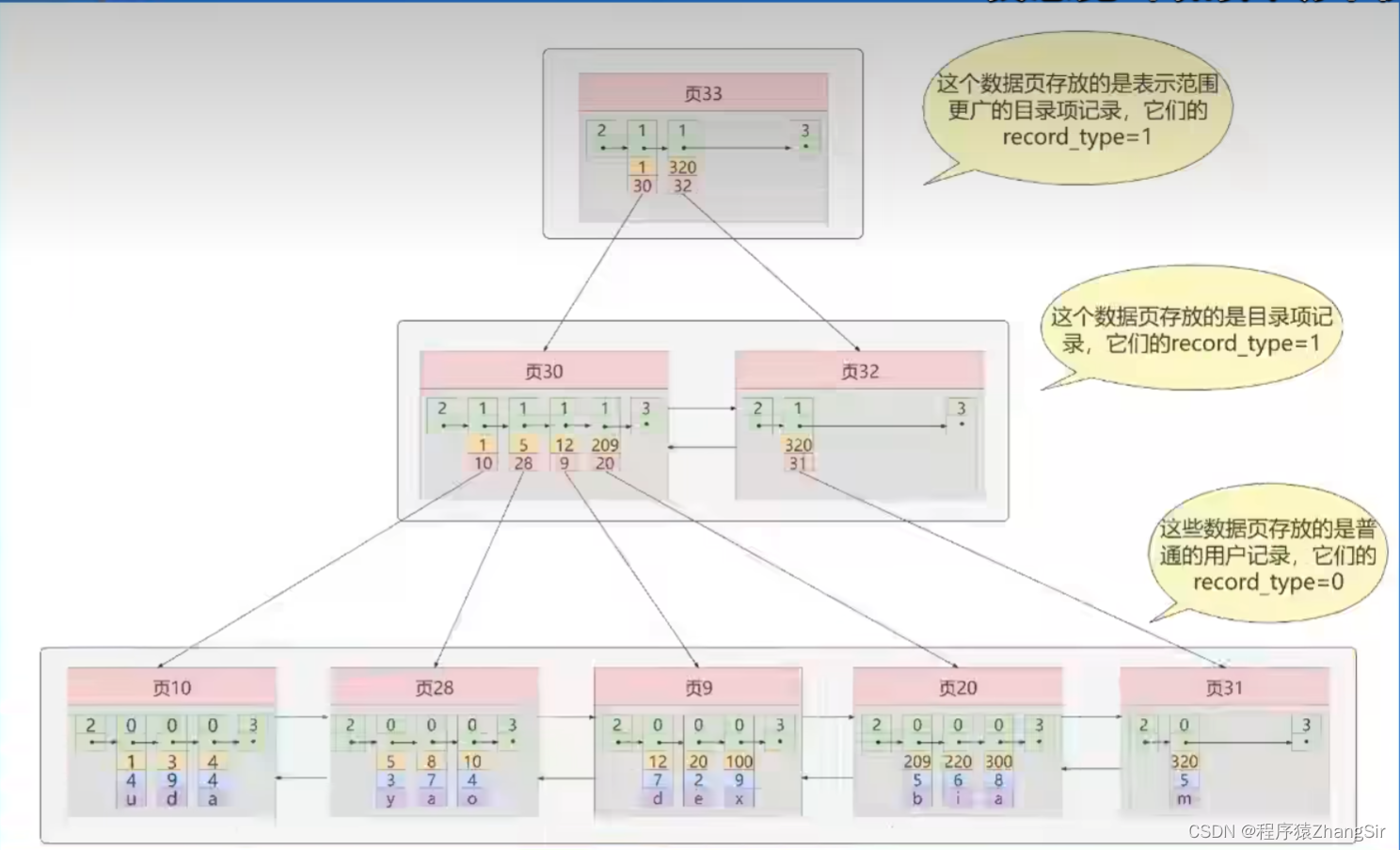
如上圖所示,就是從B樹演化形成的 B+ 樹,在 B+ 書中,我們舍棄了B書中非葉子節點也存儲真實數據做法,將所有的真實數據全部存放在葉子節點中,這樣我們的目錄頁就可以存放更多的指針數據。并在每一頁都會添加一個數組,數組中記錄著該頁中的所有元素并按照從小到大的順序排列。
例如上圖,頂層目錄頁33記錄了數據1,320,下方對應著頁30與頁33的地址值;中間目錄頁30中存儲著 1,5,12,209,數據下方各自對應著該頁的地址值;當我們想要查找(100,9,x)這條數據時,做判斷,發現(100,9,x)的相關信息應存儲在中間頁30中,在進入中間頁30尋找,經過判斷發現該數據存放在頁9中,根據對應的地址值找到頁9,然后在頁9中就可以獲取到數據(100,9,x)了,不管查詢那個數據,都是這樣的一個過程,查詢速度非常穩定,并且中間目錄頁不存儲真實數據只存儲地址值,可以存儲更多的葉子節點頁數據。
5. 為什么不采用哈希表存儲數據呢?
這其實是一個面試題,剛才我們也分析過了,哈希表的時間復雜度為O(1),常量級別,是最快的,那么數據庫存儲數據時為什么不采用哈希表的形式存儲呢?原因有以下幾點:
(1)范圍查找顯得無力
如果我們采用哈希表的結構存儲,你會發現,它只能滿足我們對精準值得查找,當我們在數據庫中加入了BETWEEN...AND...或IN這些范圍查找關鍵字的時候,哈希表就沒有優勢了,而且哈希表還是亂序的,這就導致我們在進行范圍查找時,時間復雜度為會從O(1)退化成O(n),而我們的樹形結構時間復雜度穩定在O(log2n),這個時候我們就會發現,哈希表就沒有優勢了。
(2)排序浪費時間
因為哈希表是亂序存儲,當我們需要進行ORDER BY 的時候,每次ORDER BY底層都要排一次序,而我們的樹形結構在存儲是就是有序的,不管什么時候取數據都省去了排序的時間。我們存儲。
(3)不太支持聯合索引
我們知道,B+樹中是支持聯合索引的,并會對多因進行排序,如果我們使用哈希表存儲數據,當我們將字段C1與字段C2聯合作為主鍵時,哈希存儲就會把C1和C2作為一個整體計算哈希值,不會單個做哈希值計算。這樣就亂套了,因為兩個不一樣的字段加在一起哈希值是可能相同的。
(4)索引列重復時效率低
我們知道計算哈希值就是為了避免哈希碰撞,如果一些字段肯定會出現碰撞,例如性別,年齡這些字段,那么哈希碰撞的概率就會非常大,它會遍歷哈希桶中的每一個元素作比較,非常耗時,所以哈希索引通常不會用在容易出現重復的字段上。
6. 自適應 Hash 索引
在 InnoDB 引擎中,雖然本身不支持哈希索引,但是它提供了一個自適應的哈希索引,這個是默認開啟的,當我們經常性地對數據庫中的同一些數據做查詢操作時,它就會將這些數據存放到哈希表中,以便我們以后更加快速的查找。
經過自適應哈希索引優化之后,之前我們需要進行一層層目錄的查找,但是哈希表就可以讓我們一步到位,省去檢索的時間。










| 最簡單的實例升級)

-三維堆積柱形圖(3D Stacked Bar Chart))


——使用docker-compose安裝redis)



分析內存)