數據集與語料
- 語料是NLP的生命之源,所有NLP問題都是從語料中學到數據分布的規律
- 語料的分類:單語料,平行語料,復雜結構

- 語料的例子:Penn Treebank, Daily Dialog, WMT-1x翻譯數據集,中文閑聊數據集,中國古詩數據集
- 語料來源:公開數據集,爬蟲,社交工具埋點,數據庫,上述數據集如何獲取?這里 (吐槽一下,B站的這個視頻講得很一般,浪費好幾個小時時間,收獲甚微,作為科普快速拉一下可以)
句子理解
用計算機處理一個句子,主要包含以下幾個方面:分詞、詞性識別、命名實體識別、依存句法分析
分詞
分詞與NLP的關系
-
分詞是中文語言特有的需求,是中文NLP的基礎,沒有中文分詞,我們對于語言很難量化,進而很難運用數學的知識去解決問題。而對于拉丁語系是不需要分詞的,因為它們有空格天然的隔開
-
中分分詞(Chinese Word Segmentation)指的是將一個漢字序列切分成一個一個單獨的詞。分詞就是將連續的字序列按照一定的規范重新組合成詞序列的過程。分詞操作的輸入是句子,輸出是詞序列,如

-
關于分詞,可參閱B站上一個視頻動手學中文分詞,(這個視頻還不錯,理論部分講得不是很細,但代碼部分很細,通過debug幫助理解算法)該系列課程講解了三種分詞算法及其實現、中文分詞工具
Jieba分詞的用法,最后實現了一個簡單的在線分詞工具,內嵌了自研的三種算法以及調用Jieba分詞工具,原視頻給的百度鏈接無效,我跟做的Flask項目online_fenci資源:鏈接:百度網盤 提取碼:ci07 。由于缺少原視頻中css, js等樣式文件,所有頁面畫風有點。。。丑,只能將就看。
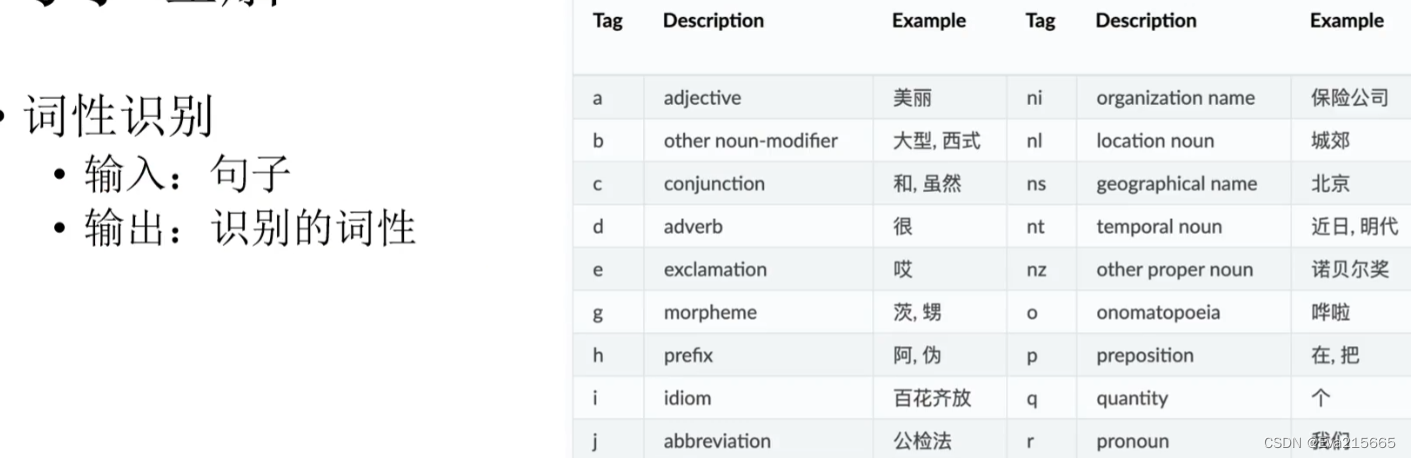
詞性識別
詞性識別的輸入是一個句子,輸出是識別出的詞性,例如,對于特朗普昨天在推特上攻擊拜登這句話,在對其進行分詞后,緊接著做詞性識別,得出與詞序列一一對應的詞性序列,如:特朗普-名詞人名(nh), 昨天-名詞時間(nt),在-介詞(p)

命名實體識別
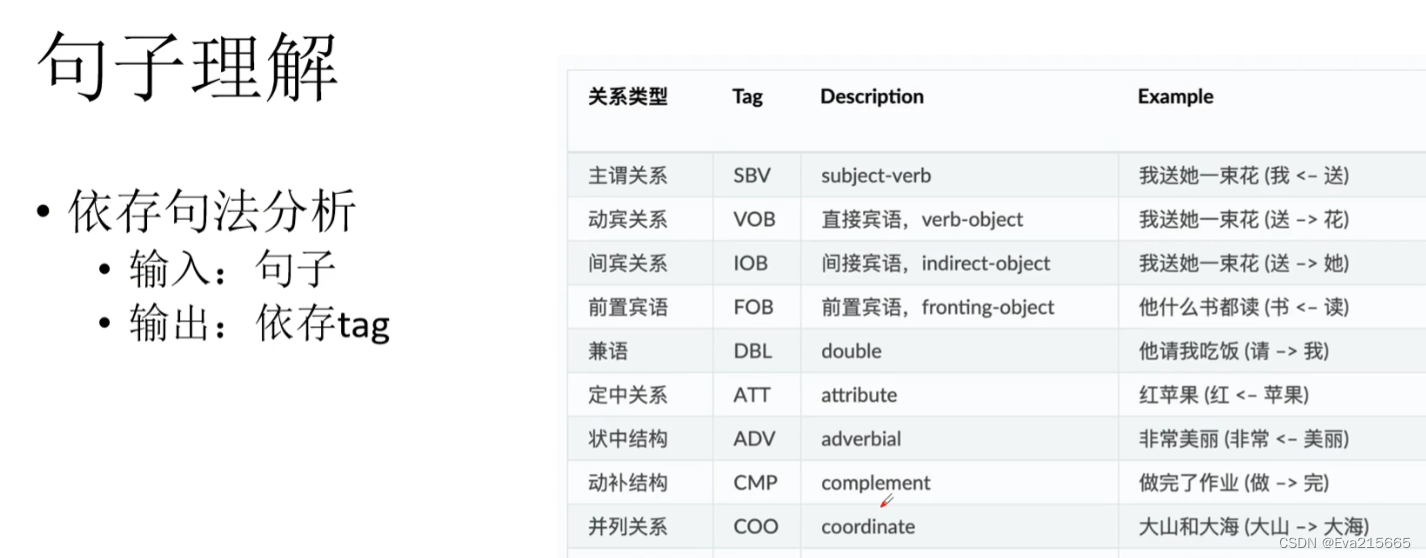
依存句法分析
預處理
- tokenize:把詞向量化,例如,把一個詞“apple”向量化成一個長度512的向量,以便用計算機能夠處理的方式進行計算處理
- 命名實體識別:把詞中的實體找出來
一些預處理工具:
預處理的工具包括: - NLTK:官網地址,基本的英文操作都支持
- SnowNLP:https://github.com/isnowfy/snowlp,中文NLP處理工具,可以進行一些基本操作,如情感分析(積極or消極),簡繁轉換,分詞,標注,計算指標等
- Pyrouge:測評文本摘要好壞
- LTP: https://ltp.ai/, https://github.com/HIT-SCIR.ltp, 哈工大做的開源工具
- Gensim: 實現Tf-ldf, LSA, LDA, Word2vec等技能
- TF-IDF,統計詞頻,詞的文檔頻率,制作詞云
詞向量模型——word2vec
詞向量的通俗理解,如果用CBOW和Skip-gram模型訓練詞向量,參閱這里
兩種構建詞向量的模式:CBOW模型與Skip-gram模型
Skip-gram模型
Skip-gram模型構建訓練數據的方法如圖,對于Thou shalt not make a machine in the likeness of a human mind這句話,用一個長度為5(一般為奇數)的滑窗在句中掃過,將input_word前2個詞與后2個詞作為output_word(或者叫target_word),構建出的數據集如下所示。




 CUDA 硬件實現)











| 最簡單的實例升級)

-三維堆積柱形圖(3D Stacked Bar Chart))

