高光譜圖像分類
初學者指南 (Beginner’s Guide)
This article provides detailed implementation of different classification algorithms on Hyperspectral Images(HSI).
本文提供了在高光譜圖像(HSI)上不同分類算法的詳細實現。
目錄 (Table of Contents)
Introduction to Hyperspectral Images(HSI)
高光譜圖像(HSI)簡介
Dimensionality Reduction(DR)
降維(DR)
Classification Algorithms
分類算法
Implementation — Classification on HSI
實施-恒指分類
高光譜圖像(HSI)簡介 (Introduction to Hyperspectral Images(HSI))
In Remote Sensing, Hyperspectral remote sensors are widely used for monitoring the earth’s surface with the high spectral resolution. Generally, the HSI contains more than three bands compared to conventional RGB Images. The Hyperspectral Images(HSI) are used to address a variety of problems in diverse areas such as Crop Analysis, Geological Mapping, Mineral Exploration, Defence Research, Urban Investigation, Military Surveillance, etc.
在遙感中 ,高光譜遙感器廣泛用于以高光譜分辨率監視地球表面。 通常,與傳統的RGB圖像相比,HSI包含三個以上的波段。 高光譜圖像(HSI)用于解決作物 分析 , 地質制圖 , 礦物勘探 , 國防研究,城市調查,軍事監視等各個領域的各種問題。
Use the below article which provides information on Data Collection, Data Preprocessing, and Exploratory Data Analysis on HSI.
使用下面的文章,它提供有關HSI上的數據收集 , 數據預處理和探索性數據分析的信息。
There are various open-source sites providing hyperspectral data for learning purposes. Here are the two popular sites:
有許多開放源站點提供高光譜數據用于學習目的。 這是兩個受歡迎的網站:
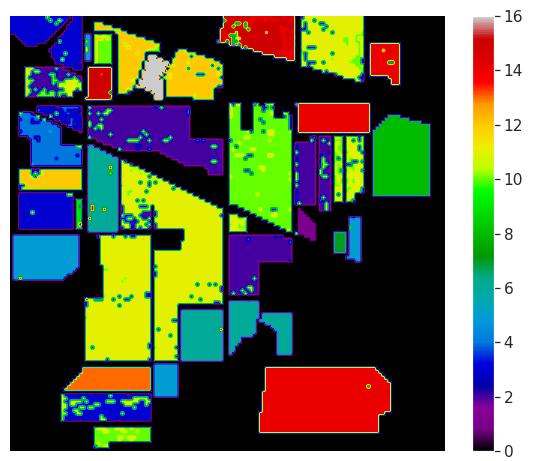
In this article, we use the Indian Pines(IP) Hyperspectral Image Dataset. The Indian Pines(IP) HSI data is gathered using the AVIRIS sensor over the Indian Pines test site in North-western Indiana and it consists of 145 X 145 pixels, 16 classes, and 200 bands. Here are the Ground Truth details of the Indian Pines(IP) Dataset:
在本文中,我們使用“ 印度松(IP)高光譜圖像數據集”。 印度派恩斯(IP)HSI數據是使用AVIRIS傳感器在印第安納州西北部的印度派恩斯測試站點上收集的,它由145 X 145像素,16個類別和200個波段組成。 以下是印度松樹(IP)數據集的地面真相詳細信息:
The code to read the dataset:
讀取數據集的代碼:
from scipy.io import loadmatdef read_HSI():X = loadmat('Indian_pines_corrected.mat')['indian_pines_corrected']y = loadmat('Indian_pines_gt.mat')['indian_pines_gt']print(f"X shape: {X.shape}\ny shape: {y.shape}")return X, yX, y = read_HSI()The visualization of the Ground Truth of the Indian Pines dataset is shown below:
印度松樹數據集的地面真相的可視化如下所示:

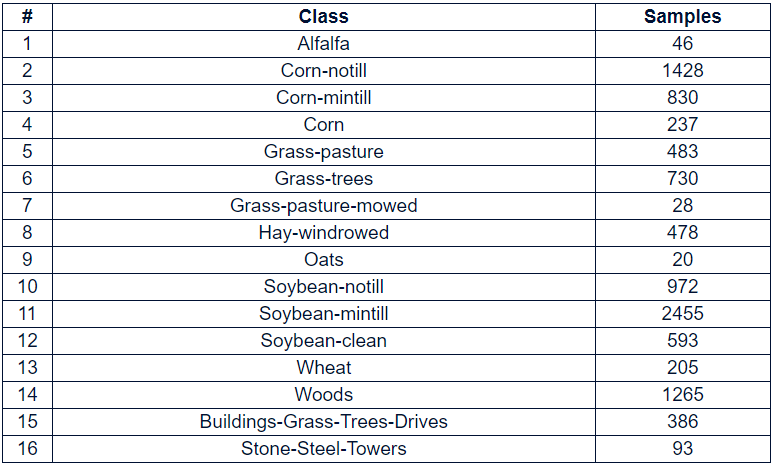
The visualization of the six randomly selected bands over 200 is shown below:
下面顯示了200多個隨機選擇的六個波段的可視化:

降維(DR) (Dimensionality Reduction(DR))
Dimensionality Reduction is used to reduce the number of dimensions of the data, thereby paving the way for the classifiers to generate comprehensive models at a low computational cost. Hence, Dimensionality Reduction (DR) has become more prominent to improve the accuracy of pixel classification in Hyperspectral Images(HSI).
降維用于減少數據的維數,從而為分類器以較低的計算成本生成綜合模型鋪平了道路。 因此,降維(DR)在提高高光譜圖像(HSI)中像素分類的準確性方面變得更加突出。
Dimensionality Reduction can be done in two types. They are:
降維可以采用兩種類型。 他們是:
- Feature Selection 功能選擇
- Feature Extraction 特征提取
Feature Selection is the process of selecting dimensions of features of the dataset which contributes mode to the machine learning tasks such as classification, clustering, e.t.c. This can be achieved by using different methods such as correlation analysis, univariate analysis, e.t.c.
特征選擇是選擇數據集特征維度的過程,該特征維度有助于機器學習任務的模式,例如分類,聚類等。這可以通過使用不同的方法(例如相關分析,單變量分析等)來實現
Feature Extraction Feature Extraction is a process of finding new features by selecting and/or combining existing features to create reduced feature space, while still accurately and completely describing the data set without loss of information.
特征提取特征提取是通過選擇和/或組合現有特征以創建縮小的特征空間來查找新特征的過程,同時仍能準確,完整地描述數據集而不會丟失信息。
Based on the criterion function and process of convergence, dimensionality reduction techniques are also classified as Convex and Non-Convex. Some popular dimensionality reduction techniques include PCA, ICA, LDA, GDA, Kernel PCA, Isomap, Local linear embedding(LLE), Hessian LLE, etc.
基于準則函數和收斂過程,降維技術也分為凸和非凸。 一些流行的降維技術包括PCA,ICA,LDA,GDA,內核PCA,Isomap,局部線性嵌入(LLE),Hessian LLE等。
Use the below article “Dimensionality Reduction in Hyperspectral Images using Python” to get a better understanding.
使用下面的文章“使用Python減少高光譜圖像的維數”以獲得更好的理解。
In this article, we are going to use Principal Component Analysis(PCA) to reduce the dimensionality of the data.
在本文中,我們將使用主成分分析(PCA)來減少數據的維數。
主成分分析(PCA) (Principal Component Analysis(PCA))
Principal Component Analysis(PCA) is one of the standard algorithms used to reduce the dimensions of the data. PCA is a non-parametric algorithm that increases the interpretability at the same time reducing the minimizing the loss of information(Reconstruction Error).
主成分分析(PCA)是用于減少數據量的標準算法之一。 PCA是一種非參數算法,可在提高解釋性的同時減少信息損失(重構錯誤)。
Use the below two papers for better understanding the math behind the PCA.
使用以下兩篇論文可以更好地理解PCA背后的數學原理。
Based on the explained variance ratio the number of components is taken as 40. The below code explains —
根據解釋的方差比,組件個數為40。以下代碼說明了-
pca = PCA(n_components = 40)dt = pca.fit_transform(df.iloc[:, :-1].values)q = pd.concat([pd.DataFrame(data = dt), pd.DataFrame(data = y.ravel())], axis = 1)q.columns = [f'PC-{i}' for i in range(1,41)]+['class']The first eight principal components or eight bands are shown below:
前八個主要成分或八個頻段如下所示:
分類算法 (Classification Algorithms)
Classification refers to a predictive modeling problem where a class label is predicted for the given input data. The classification can be divided as :
分類是指預測建模問題,其中針對給定輸入數據預測類別標簽。 分類可分為:
- Classification Predictive Modeling 分類預測建模
- Binary Classification 二進制分類
- Multi-Class Classification 多類別分類
- Multi-Label Classification 多標簽分類
- Imbalanced Classification 分類不平衡
Today, we are dealing with the Multi-Class Classification problem. There are different classification algorithms that are used for the classification of Hyperspectral Images(HSI) such as :
今天,我們正在處理“多類分類”問題。 高光譜圖像(HSI)的分類有不同的分類算法,例如:
- K-Nearest Neighbors K最近鄰居
- Support Vector Machine 支持向量機
- Spectral Angle Mapper 光譜角映射器
- Convolutional Neural Networks 卷積神經網絡
- Decision Trees e.t.c 決策樹等
In this article, we are going to use the Support Vector Machine(SVM) to classify the Hyperspectral Image(HSI).
在本文中,我們將使用支持向量機(SVM)對高光譜圖像(HSI)進行分類。
支持向量機(SVM) (Support Vector Machine(SVM))
Support Vector Machine is a supervised classification algorithm that maximizes the margin between data and hyperplane. Different kernel functions are used to project the data into higher dimensions such as Linear, polynomial, Radial Basis Function(RBF), e.t.c.
支持向量機是一種監督分類算法,可最大化數據和超平面之間的余量。 使用不同的內核函數將數據投影到更高的維度,例如線性,多項式,徑向基函數(RBF)等
For better understanding, the concept behind SVM refer the below lectures:
為了更好地理解,SVM背后的概念請參考以下講座:
實施-恒指分類 (Implementation — Classification on HSI)
The below code serves the purpose of implementing the support vector machine to classify the Hyperspectral Image.
以下代碼用于實現支持向量機以對高光譜圖像進行分類的目的。
x = q[q['class'] != 0]X = x.iloc[:, :-1].valuesy = x.loc[:, 'class'].values names = ['Alfalfa', 'Corn-notill', 'Corn-mintill', 'Corn', 'Grass-pasture','Grass-trees',
'Grass-pasture-mowed','Hay-windrowed','Oats','Soybean-notill','Soybean-mintill',
'Soybean-clean', 'Wheat', 'Woods', 'Buildings Grass Trees Drives', 'Stone Steel Towers']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=11, stratify=y)svm = SVC(C = 100, kernel = 'rbf', cache_size = 10*1024)svm.fit(X_train, y_train)ypred = svm.predict(X_test)The confusion matrix is generated using the code:
混淆矩陣是使用以下代碼生成的:
data = confusion_matrix(y_test, ypred)df_cm = pd.DataFrame(data, columns=np.unique(names), index = np.unique(names))df_cm.index.name = 'Actual'df_cm.columns.name = 'Predicted'plt.figure(figsize = (10,8))sn.set(font_scale=1.4)#for label sizesn.heatmap(df_cm, cmap="Reds", annot=True,annot_kws={"size": 16}, fmt='d')plt.savefig('cmap.png', dpi=300)
The generated Classification Report which consists of the Classwise Accuracy, Accuracy Precision, Recall, F1 Score, and Support is shown below:
生成的分類報告由分類準確性,準確性準確性,召回率,F1得分和支持組成,如下所示:

Finally, the classification Map is shown below:
最后,分類圖如下所示:
The entire code that I have written in this article can be accessed using the below notebook in GitHub and CoLab.
可以使用GitHub和CoLab中的以下筆記本訪問本文中編寫的全部代碼。
翻譯自: https://towardsdatascience.com/hyperspectral-image-analysis-classification-c41f69ac447f
高光譜圖像分類
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391015.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391015.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391015.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

在Java里如何給一個日期增加一天

CentOS 7安裝和部署Docker

JavaScript字符串方法終極指南-拆分
)
機器人的動力學和動力學聯系_通過機器學習了解幸福動力學(第2部分)

在Java里怎將字節數轉換為我們可以讀懂的格式?

ubuntu 16.04 安裝mysql

shell:多個文件按行合并

form子句語法錯誤_用示例語法解釋SQL的子句
)
leetcode 1310. 子數組異或查詢(位運算)

大樣品隨機雙盲測試_訓練和測試樣品生成

vue組件命名指南,不為取名而糾結

JavaScript 基礎,登錄驗證

使用final類的作用是什么?

photoshop cc_如何使用Photoshop CC將圖片變成卡通

從數據角度探索在新加坡的非法毒品

Android 自定義View實現QQ運動積分抽獎轉盤

瑞立視:厚積薄發且具有“工匠精神”的中國品牌

蘋果系統使用svg 動畫_為什么要使用SVG圖像:如何為SVG設置動畫并使其快速閃電化

