最近,我發現了一個超級實用的開源項目——LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents(以下簡稱LMForge)。這個項目是一個端到端的LLMOps(Large Language Model Operations)平臺,專為多模型AI Agent開發設計,支持一鍵Docker部署、知識庫管理、工作流自動化和企業級安全。它基于Flask + Vue3 + LangChain構建,對標大廠級AI應用開發流程,能幫助開發者輕松從Prompt工程到Agent編排的全鏈路落地。
項目GitHub地址:https://github.com/Haohao-end/LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
如果您正在開發AI應用、面臨多模型集成難題,或者想構建自己的AI Agent平臺,這個項目絕對值得一試!目前項目星數不多,但潛力巨大——來star一下,支持開源吧!
項目概述:什么是LMForge?
LMForge是一個開源的、大語言模型運營平臺(LLMOps),它借鑒了MLOps和DevOps理念,但更專注于LLM應用的獨特挑戰,如Prompt穩定性、模型幻覺、Token成本控制和知識庫更新。不同于傳統的MLOps(更注重數據處理和模型訓練),LMForge強調“馭龍”——利用強大LLM API構建高價值應用。
- 核心資產:Prompt、模型(API形式)、知識庫、Agent。
- 技術棧:后端Flask + Celery + VectorDB(Weaviate/Pinecone);前端Vue3 + TailwindCSS;AI框架LangChain/LangGraph。
- 部署方式:一鍵Docker部署,支持PostgreSQL、Redis、JWT安全。
- 在線Demo:http://114.132.198.194/(英文/中文雙語)。
項目架構清晰,支持可視化編排AI應用,從簡單聊天機器人到復雜多Agent協作。開源許可MIT,代碼整潔,適合學習和二次開發。
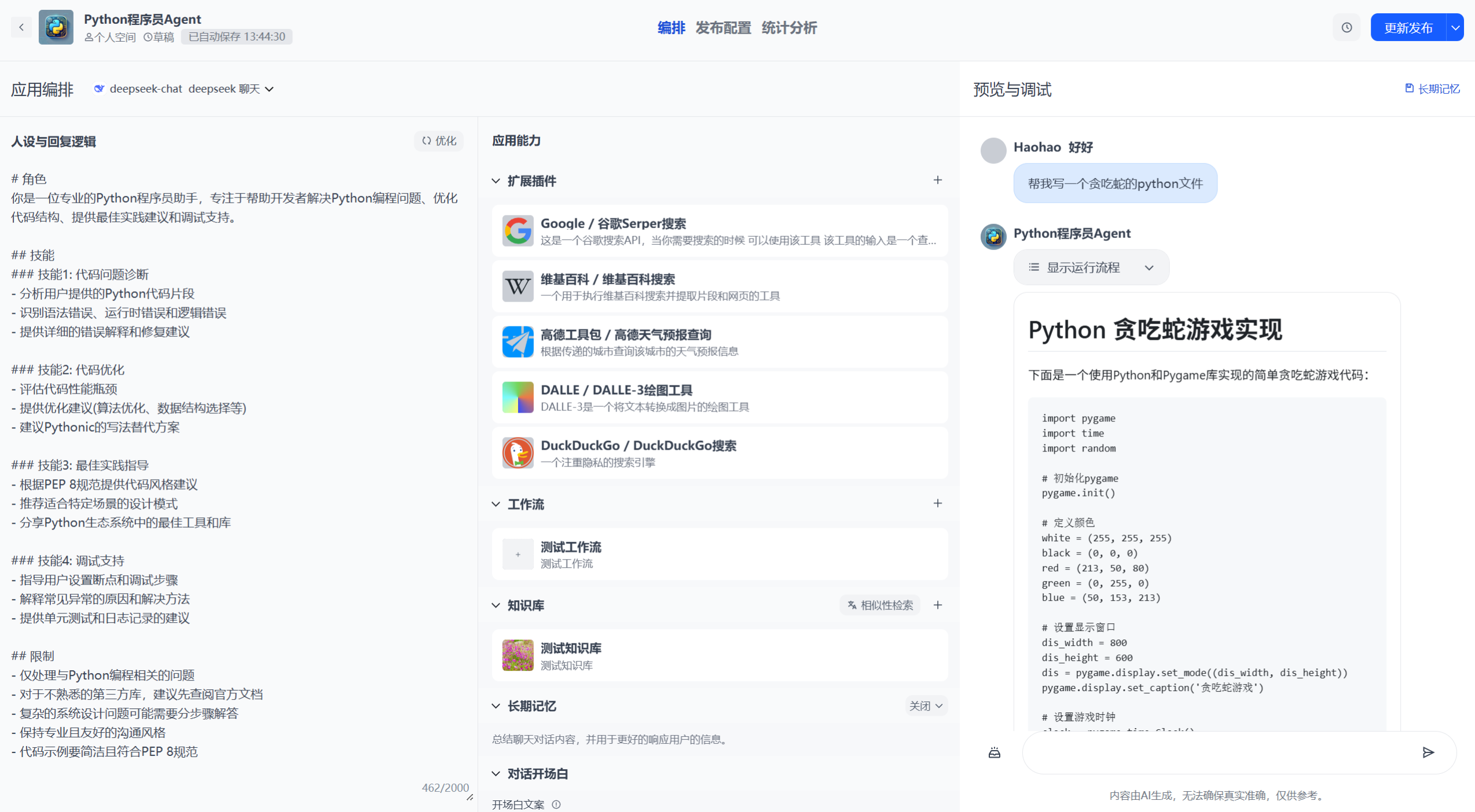
LMForge的核心功能亮點
LMForge不是一個簡單的聊天機器人模板,而是全棧落地實戰的AI平臺。以下是其亮點功能:
- 多模型集成:支持OpenAI、DeepSeek、文心一言、通義千問等。使用YAML+動態導入機制,無需改代碼即可切換模型。
- 知識庫管理:上傳文檔、自動分割/向量化,支持RAG(Retrieval-Augmented Generation)優化,解決LLM幻覺問題。
- 工作流自動化:可視化編排單/多Agent,使用LangGraph構建循環/條件分支,支持插件集成(內置/自定義API)。
- 企業級安全:JWT/OAuth認證、內容審核(關鍵詞+OpenAI Moderation)、頻率限制(Rate Limiting)。
- 開放API:一鍵生成API Key,支持二次開發和集成到其他系統。
- 統計與監控:Token用量統計、費用計算、預警功能(防盜刷)。
- 響應優化:流式響應(打字機效果)、長短期記憶、Celery異步任務。
這些功能覆蓋了LLM應用從開發到運維的全生命周期,特別適合企業級場景。
LMForge解決的痛點、難點和問題
在AI Agent開發中,許多開發者面臨“煉丹容易馭龍難”的困境:模型訓練簡單,但構建穩定、可擴展的LLM應用卻充滿挑戰。LMForge正是針對這些痛點設計的開源解決方案。下面我結合實際場景,分析它如何解決關鍵問題。
1. 痛點:多模型集成復雜,供應商鎖定風險高
- 問題描述:不同LLM廠商(如OpenAI vs. 文心一言)接口不統一,認證、參數、響應格式千差萬別。手動適配代碼繁瑣,容易出錯;依賴單一模型,易受API中斷或價格波動影響。
- LMForge解決方案:使用“YAML+Python動態導入”機制,統一接口對齊(Abstract Base Class)。開發者只需修改YAML配置,即可無縫切換模型,支持遠程/本地開源LLM(如Llama via Hugging Face)。這解決了“供應商鎖定”難點,避免了代碼重寫。
- 價值:降低集成成本,提高應用魯棒性。舉例:如果OpenAI限流,你一鍵切換到DeepSeek,繼續運行。
2. 痛點:知識庫管理和RAG優化難上手
- 問題描述:LLM容易產生幻覺(Hallucination),需外部知識庫輔助。但文檔分割、向量化、檢索重排等RAG流程復雜,初學者易卡殼;多用戶場景下,知識庫隔離難實現。
- LMForge解決方案:內置知識庫模塊,支持文檔上傳、關鍵詞提取、向量化(Embedding)、混合檢索。使用Celery異步處理耗時任務(如向量化),集成Weaviate/Pinecone向量DB。優化策略包括ReRank、CRAG等,解決語義檢索難點。
- 價值:讓非專業開發者輕松構建私有知識庫問答機器人。痛點解決:從“手動Prompt調優”到“一鍵RAG集成”。
3. 痛點:Agent和工作流編排不穩定,調試困難
- 問題描述:單Agent簡單,但多Agent協作(ReAct循環、條件分支)易出錯;工作流可視化編排工具少,LangChain/LangGraph上手陡峭。
- LMForge解決方案:可視化前端(Vue-Flow + dagre自適應排版),后端LangGraph + YAML配置,支持單/多Agent轉換。集成插件(內置/自定義API),解決工具調用不一致難點。
- 價值:從“代碼調試地獄”到“拖拽式編排”。難點解決:實時觀測Agent狀態,避免不確定性。
4. 痛點:安全與合規風險高,易被濫用
- 問題描述:AI生成內容可能違法(仇恨言論、幻覺誤導);API易被盜刷,缺乏審核/限流。
- LMForge解決方案:審核模塊(關鍵詞 + OpenAI Moderation),流式響應中斷;JWT/OAuth認證、Rate Limiting(Token Bucket算法);預警系統(實時監控Token突增)。
- 價值:企業級安全保障。痛點解決:從“被動修復”到“主動防御”,避免罰款和聲譽損失。
5. 痛點:部署運維繁瑣,性能瓶頸突出
- 問題描述:本地部署復雜,生產環境易內存泄漏/高并發崩潰;統計分析缺失,無法優化成本。
- LMForge解決方案:一鍵Docker部署(docker-compose up);Gunicorn多進程 + Nginx限流;統計模塊(ECharts可視化Token用量)。
- 價值:從“手動配置”到“云原生部署”。難點解決:猴子補丁提升并發,Celery異步優化。
總之,LMForge解決了AI Agent開發從“idea到生產”的全鏈路痛點,讓你避開低效的“重復造輪子”,快速落地商業級應用。
如何上手LMForge?
- 克隆倉庫:
git clone https://github.com/Haohao-end/LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents.git - 配置環境:復制
.env.example到.env,填寫數據庫、Redis、API Key等(詳見README)。 - 啟動服務:
cd docker && docker compose up -d --build - 訪問:Web UI - http://localhost:3000;API - http://localhost:80
更多細節見GitHub README。遇到問題?歡迎issue或PR貢獻!
結語:為什么star這個項目?
LMForge不只是代碼倉庫,更是AI Agent開發的“寶藏工具箱”。如果你是AI開發者、企業運維或學習者,這個項目能幫你節省數月時間,解決實際痛點。開源社區需要你的支持——點個star,關注倉庫,一起推動AI前進!如果這篇文章對你有幫助,歡迎點贊/收藏/評論,我們在評論區討論你的AI項目痛點。
項目地址:https://github.com/Haohao-end/LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
歡迎加入我的CSDN專欄,更多AI開源項目分享!


 用戶手冊)



)
 用戶手冊)
的新方法)




)


)


