如何建立搜索引擎
This article outlines one of the most important search algorithms used today and demonstrates how to implement it in Python in just a few lines of code.
本文概述了當今使用的最重要的搜索算法之一,并演示了如何僅用幾行代碼就可以在Python中實現它。
搜索的價值 (The value of search)
The ability to search data is something we take for granted. Modern search engines are now so sophisticated that most of our searches ‘just work’. In fact, we often only notice a search on a website or app when it does not perform. Our expectations in this space have never been higher.
搜索數據的能力是我們理所當然的。 現在,現代搜索引擎非常復雜,以至于我們的大多數搜索“都行得通”。 實際上,我們通常只會在網站或應用無法執行搜索時才會注意到該搜索。 我們對這個領域的期望從未如此高。
The intelligence of search engines has been increasing for a very simple reason, the value that an effective search tool can bring to a business is enormous; a key piece of intellectual property. Often a search bar is the main interface between customers and the business. A good search engine can, therefore, create a competitive advantage by delivering an improved user experience.
搜索引擎的智能一直在增加,原因很簡單,有效的搜索工具可以為企業帶來巨大的價值。 關鍵的知識產權。 搜索欄通常是客戶和企業之間的主要界面。 因此,好的搜索引擎可以通過提供改進的用戶體驗來創造競爭優勢。
MckKinsey estimated that this value, aggregated globally, amounted to $780Bn a year in 2009. This would put the value of each search performed at $0.50[1]. Of course, this value has no doubt increased substantially since 2009…
麥肯錫(MckKinsey)估計,2009年,全球每年的價值總計為7800億美元。這使得每次搜索的價值為0.50美元[1]。 當然,自2009年以來,這一價值無疑已大幅提高。
With this in mind, you would be forgiven that creating a modern search engine would be out of reach of most development teams, requiring huge resources and complex algorithms. However, somewhat surprisingly, a large number of enterprise business search engines are actually powered by very simple and intuitive rules which can be easily implemented using open source software.
考慮到這一點,您會原諒創建現代搜索引擎對于大多數開發團隊來說是遙不可及的,這需要大量的資源和復雜的算法。 但是,令人驚訝的是,實際上,許多企業業務搜索引擎由非常簡單直觀的規則提供支持,可以使用開源軟件輕松實現這些規則。
For example, Uber, Udemy Slack and Shopify (along with 3,000 other business and organisations [2]) all use Elasticsearch. This search engine was powered by incredibly simple term-frequency, inverse document frequency (or tf-idf) word scores up until 2016.[3] (For more details on what this is, I have written about tf-idf here and here).
例如,Uber,Udemy Slack和Shopify(以及3,000個其他企業和組織[2])都使用Elasticsearch。 該搜索引擎由令人難以置信的簡單詞頻,反文檔頻度 (或tf-idf)單詞得分提供支持,直到2016年。[3] (有關這是什么的更多詳細信息,我在這里和這里已經寫過關于tf-idf的信息 )。
After this point, it switched to the more sophisticated (but still very simple) BM25 which is still used today. This is also the algorithm implemented within Azure Cognitive Search[4].
此后,它切換到了今天仍在使用的更復雜(但仍然非常簡單)的BM25。 這也是Azure認知搜索中實現的算法[4]。
BM25:您從未聽說過的最重要的算法 (BM25: the most important algorithm you have never heard of)
So what is BM25? It stands for ‘Best match 25’ (the other 24 attempts were clearly not very successful). It was released in 1994 at the third Text Retrieval Conference, yes there really was a conference dedicated to text retrieval…
那么什么是BM25? 它代表“最佳比賽25”(其他24次嘗試顯然不是很成功)。 它于1994年在第三次文本檢索會議上發布 ,是的,確實有一個專門針對文本檢索的會議…
It is probably best thought of as tf-idf ‘on steroids’, implementing two key refinements:
最好將其視為“類固醇上的tf-idf”,它實現了兩個關鍵改進:
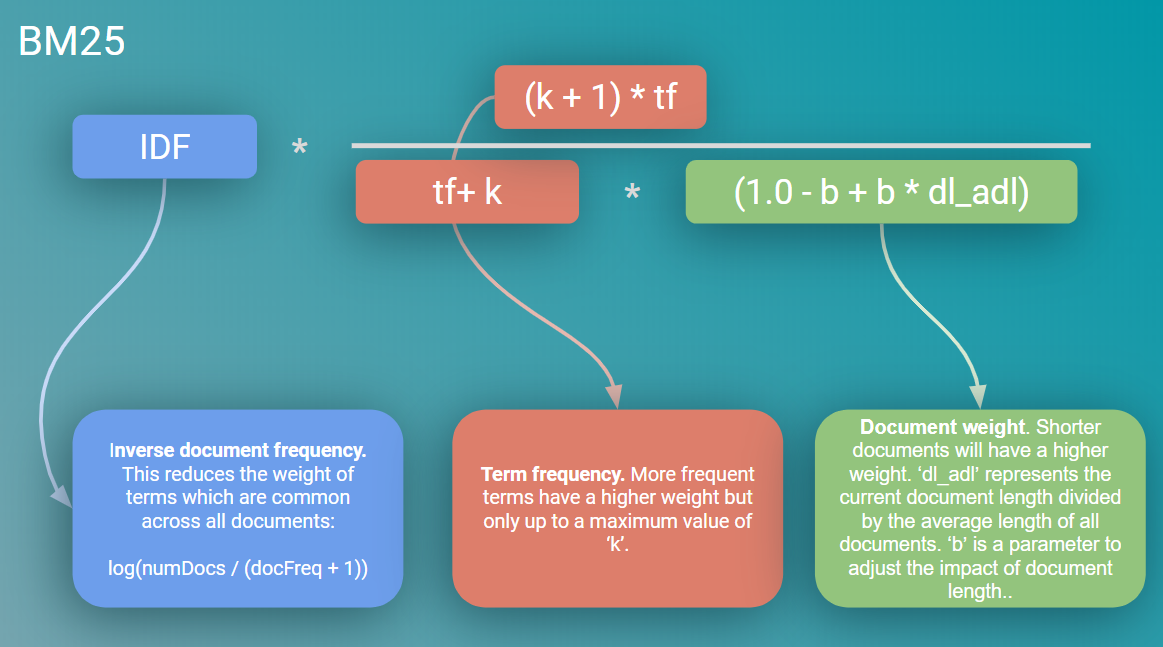
Term frequency saturation. BM25 provides diminishing returns for the number of terms matched against documents. This is fairly intuitive, if you looking to search for a specific term which is very common in documents then there should become a point where the number of occurrences of this term become less useful to the search.
術語頻率飽和 。 BM25提供與文檔匹配的條款數量遞減的回報。 這是非常直觀的,如果您要搜索在文檔中非常常見的特定術語,那么應該出現一個問題,即該術語的出現次數對搜索沒有太大用處。
Document length. BM25 considers document length in the matching process. Again, this is intuitive; if a shorter article contains the same number of terms that match as a longer article, then the shorter article is likely to be more relevant.
文件長度。 BM25在匹配過程中考慮文檔長度。 再次,這很直觀; 如果較短的文章包含與較長的文章匹配的相同數量的術語,則較短的文章可能更相關。
These refinements also introduce two hyper-parameters to adjust the impact of these items on the ranking function. ‘k’ to tune the impact of term saturation and ‘b’ to tune document length.
這些改進還引入了兩個超參數,以調整這些項目對排名功能的影響。 “ k”用于調整術語飽和度的影響,“ b”用于調整文檔長度。
Bringing this all together, BM25 is calculated as:
綜上所述,BM25的計算公式為:
實施BM25,一個可行的例子 (Implementing BM25, a worked example)
Implementing BM25 is incredibly simple. Thanks to the rank-bm25 Python library this can be achieved in a handful of lines of code.
實施BM25非常簡單。 多虧了rank-bm25 Python庫,這可以用幾行代碼來實現。
In our example, we are going to create a search engine to query contract notices that have been published by UK public sector organisations.
在我們的示例中,我們將創建一個搜索引擎來查詢由英國公共部門組織發布的合同通知。
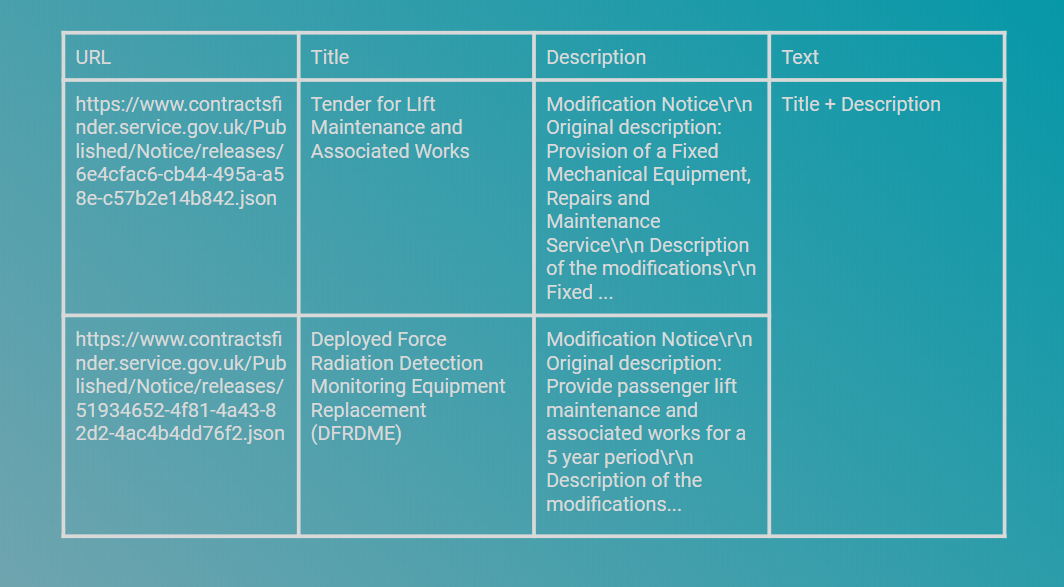
Our starting point is a dateset which contains the title of a contract notice, the description along with the link to the notice itself. To keep things simple, we have combined the title and description together to create the ‘text’ column in the dataset. It is this column that we will use to search. There are 50,000 documents which we want to search across:
我們的出發點是一個日期集,其中包含合同通知書的標題,說明以及通知書本身的鏈接。 為了簡單起見,我們將標題和描述結合在一起以在數據集中創建“文本”列。 我們將使用此列進行搜索。 我們要搜索50,000個文檔:
A link to the data and the code can be found at the bottom of this article.
可以在本文底部找到數據和代碼的鏈接。
The first step in this exercise is to extract all the words within the ‘text’ column of this dataset to create a ‘list of lists’ consisting of each document and the words within them. This is known as tokenization and can be handled by the excellent spaCy library:
此練習的第一步是提取此數據集的“文本”列中的所有單詞,以創建一個“列表列表”,其中包括每個文檔及其中的單詞。 這被稱為標記化,可以通過出色的spaCy庫進行處理:
import spacy
from rank_bm25 import BM25Okapi
from tqdm import tqdm
nlp = spacy.load("en_core_web_sm")text_list = df.text.str.lower().values
tok_text=[] # for our tokenised corpus#Tokenising using SpaCy:
for doc in tqdm(nlp.pipe(text_list, disable=["tagger", "parser","ner"])):
tok = [t.text for t in doc if t.is_alpha]
tok_text.append(tok)Building a BM25 index can be done in a single line of code:
建立BM25索引可以用單行代碼完成:
bm25 = BM25Okapi(tok_text)Querying this index just requires a search input which has also been tokenized:
查詢該索引僅需要搜索輸入,該輸入也已被標記化:
query = "Flood Defence"tokenized_query = query.lower().split(" ")import timet0 = time.time()
results = bm25.get_top_n(tokenized_query, df.text.values, n=3)
t1 = time.time()print(f'Searched 50,000 records in {round(t1-t0,3) } seconds \n')for i in results:
print(i)This returns the following top 3 results that are clearly highly relevant to the search query of ‘Flood Defence’:
這將返回以下與搜索“防洪”高度相關的前3個結果:
Searched 50,000 records in 0.061 seconds:Forge Island Flood Defence and Public Realm Works Award of Flood defence and public realm works along the canal embankment at Forge Island, Market Street, Rotherham as part of the Rotherham Renaissance Flood Alleviation Scheme. Flood defence maintenance works for Lewisham and Southwark College **AWARD** Following RfQ NCG contracted with T Gunning for Flood defence maintenance works for Lewisham and Southwark College Freckleton St Byrom Street River Walls Freckleton St Byrom Street River Walls, Strengthening of existing river wall parapets to provide flood defence measuresWe could fine-tune the values for ‘k’ and ‘b’ based on the expected preferences of the users performing the searches, however the defaults of k=1.5 and b=0.75 seem to work well here.
我們可以根據執行搜索的用戶的期望偏好來微調“ k”和“ b”的值,但是默認設置k = 1.5和b = 0.75在這里似乎很好。
在結束時 (In closing)
Hopefully this example highlights how simple it is to implement a robust full text search in Python. This could easily be used to power a simple web app or a smart document search tool. There is also significant scope to improve the performance of this further , which may form the topic of a future post!
希望該示例突出顯示在Python中實現健壯的全文本搜索有多么簡單。 這可以輕松地用于驅動簡單的Web應用程序或智能文檔搜索工具。 還有很大的空間可以進一步改善此性能,這可能會成為將來帖子的主題!
The code and data to this article can be found in this Colab notebook.
可在此Colab筆記本中找到本文的代碼和數據。
[1] McKinsey review of web search: https://www.mckinsey.com/~/media/mckinsey/dotcom/client_service/High%20Tech/PDFs/Impact_of_Internet_technologies_search_final2.aspx
[1]麥肯錫網絡搜索評論: https : //www.mckinsey.com/~/media/mckinsey/dotcom/client_service/High%20Tech/PDFs/Impact_of_Internet_technologies_search_final2.aspx
[2] According to StackShare, August 2020.
[2] 根據StackShare,2020年8月。
[3] BM25 became the default search from Elasticsearch v5.0 onward: https://www.elastic.co/blog/elasticsearch-5-0-0-released
[3] BM25從Elasticsearch v5.0開始成為默認搜索: https : //www.elastic.co/blog/elasticsearch-5-0-0-released
[4] https://docs.microsoft.com/en-us/azure/search/index-ranking-similarity
[4] https://docs.microsoft.com/zh-CN/azure/search/index-ranking-similarity
翻譯自: https://towardsdatascience.com/how-to-build-a-search-engine-9f8ffa405eac
如何建立搜索引擎
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390664.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390664.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390664.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

用Docker自動構建紙殼CMS

Linux學習筆記15—RPM包的安裝OR源碼包的安裝

leetcode 518. 零錢兌換 II

軟件測試中什么是正交實驗法_軟件工程中的正交性
)
leetcode 279. 完全平方數(dp)

github代碼_GitHub啟動代碼空間


js將base64做UrlEncode轉碼

引用自己創建的css樣式表_如何使用CSS創建聯系表
)
leetcode 1449. 數位成本和為目標值的最大數字(dp)

風能matlab仿真_風能產量預測—深度學習項目
(轉))
android JNI調用(Android Studio 3.0.1)(轉)

安卓源碼 代號,標簽和內部版本號

git 列出標簽_Git標簽介紹:如何在Git中列出,創建,刪除和顯示標簽
)
leetcode 278. 第一個錯誤的版本(二分)

騰訊哈勃_用Python的黑客統計資料重新審視哈勃定律

JAVA中動態編譯的簡單使用

程序員實用小程序_我從閱讀《實用程序員》中學到了什么
)
leetcode 5786. 可移除字符的最大數目(二分法)
