uni-app清理緩存數據
It turns out that Data Scientists and Data Analysts will spend most of their time on data preprocessing and EDA rather than training a machine learning model. As one of the most important job, Data Cleansing is very important indeed.
事實證明,數據科學家和數據分析師將把大部分時間花在數據預處理和EDA上,而不是訓練機器學習模型。 作為最重要的工作之一,數據清理確實非常重要。
We all know that we need to clean the data. I guess most people know that. But where to start? In this article, I will provide a generic guide/checklist. So, once we start on a new dataset, we can start the Data Cleansing as such.
我們都知道我們需要清理數據。 我想大多數人都知道。 但是從哪里開始呢? 在本文中,我將提供通用指南/清單。 因此,一旦我們開始一個新的數據集,我們就可以像這樣開始數據清洗。
方法論(CRAI) (Methodology (C-R-A-I))
If we ask ourselves “why do we need to clean the data?”, I think it is obvious that it is because we want our data to follow some standards in order to be fed into some algorithm or visualised on a consistent scale. Therefore, let’s firstly summarise what are the “standards” that we want our data to have.
如果我們問自己“為什么需要清理數據?”,我認為很明顯是因為我們希望我們的數據遵循某些標準,以便輸入某種算法或以一致的規模可視化。 因此,讓我們首先總結一下我們希望數據具有的“標準”。
Here, I summarised 4 major criteria/standards that a cleansed dataset should have. I would call it “CRAI”.
在這里,我總結了清洗后的數據集應具有的4個主要標準/標準。 我稱之為“ CRAI”。
Consistency
一致性
Every column of the data should be consistent on the same scale.
數據的每一列都應在相同范圍內保持一致。
Rationality
理性
All the values in each column should comply with common sense.
每列中的所有值均應符合常識。
Atomicity
原子性
The data entries should not be duplicated and the data column should not be dividable.
數據條目不應該重復,并且data列不能分開。
Integrity
廉潔
The data entries should have all the features available unless null value makes sense.
數據條目應具有所有可用功能,除非使用空值有意義。
OK. Just bear in mind with these 4 criteria. I will explain them with more examples so that hopefully they will become something that you can remember.
好。 只要記住這四個標準即可。 我將通過更多示例來說明它們,以便希望它們將成為您可以記住的東西。
一致性 (Consistency)

It will be helpful to plot a histogram of a column regardless it is continuous or categorical. We need to pay attention to the min/max values, average values and the shape of the distribution. Then, use common sense to find out whether there is any potential inconsistency.
無論列是連續的還是分類的,繪制柱狀圖都是有幫助的。 我們需要注意最小值/最大值,平均值和分布形狀。 然后,使用常識找出是否存在任何潛在的不一致之處。
For example, if we sampled some people and one column of the data is for their weights. Let’s say the histogram is as follows.
例如,如果我們對一些人進行了抽樣,則數據的一列是他們的體重。 假設直方圖如下。
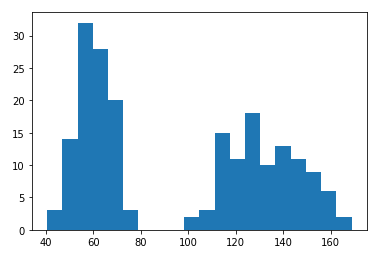
It is obvious that there is almost nothing between 80 and 100. Using our common sense is quite enough to find out the problem. That is, some of the weights are in kg while the others are in lbs.
顯然,在80到100之間幾乎沒有任何東西。使用我們的常識就足以找出問題所在。 也就是說,一些重量以千克為單位,而另一些重量以磅為單位。
This kind of issue is commonly found when we have multiple data sources. Some of them might use different units for the same data fields.
當我們有多個數據源時,通常會發現這種問題。 他們中的一些人可能對相同的數據字段使用不同的單位。
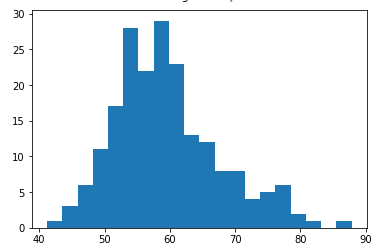
After cleansing, we may end up with distribution like this, which looks good.
清洗后,我們可能最終會得到這樣的分布,看起來不錯。
理性 (Rationality)

This also relies on our common sense, but it is usually easier to be found. Some common example:
這也依賴于我們的常識,但通常更容易找到。 一些常見的例子:
- Human age, weight and height should not be negative. 人的年齡,體重和身高不應為負數。
- Some categorical data such as gender will have a certain enumeration of values. otherwise, it is not valid. 一些分類數據(例如性別)將具有一定的值枚舉。 否則無效。
- Most types of textual values such as human names and product names should not have leading and tailing spaces. 大多數類型的文本值(例如,人名和產品名)都不應使用前導和尾部空格。
- Sometimes we may also need to pay attention to special characters. Most of the time they should be stripped out. 有時我們可能還需要注意特殊字符。 在大多數情況下,應將其剝離。
原子性 (Atomicity)
This is easy to understand. We should not have any duplicated rows in our dataset. It happens commonly when we have multiple data sources, where different data source may store overlapped data.
這很容易理解。 我們的數據集中不應有任何重復的行。 當我們有多個數據源時,通常會發生這種情況,其中不同的數據源可能會存儲重疊的數據。
It is important to leave uniqueness checking later than the consistency and rationality because it will difficult to find out the duplicated rows if we didn’t fix the consistency and rationality issues. For example, a person’s name might be presented in different ways in different data sources, such as González and Gonzalez. Once we realise that there are some non-English names existing, we need to pay attention to this kind of problems.
在一致性和合理性之后保留唯一性檢查很重要,因為如果我們不解決一致性和合理性問題,將很難找出重復的行。 例如,可以在不同的數據源(例如González和Gonzalez以不同的方式顯示一個人的名字。 一旦意識到存在一些非英語名稱,就需要注意這種問題。
Therefore, although it is usually not difficult to get rid of duplicated rows, the other of doing it may impact the final quality of the cleansed data.
因此,盡管通常不難擺脫重復的行,但另一步可能會影響已清理數據的最終質量。
Another type of violation of the atomicity is that one column may be dividable, which means that there are actually multiple features hidden in one column. To maximise the value of the dataset, we should divide them.
違反原子性的另一種類型是,一列可能是可分割的,這意味著實際上一列中隱藏了多個特征。 為了最大化數據集的價值,我們應該將它們分開。
For example, we may have a column that represents customer names. Sometimes it might necessary to split it into first name and last name.
例如,我們可能有一個代表客戶名稱的列。 有時可能需要將其拆分為名字和姓氏。
廉潔 (Integrity)

Depending on the data source and how the data structure was designed, we may have some data missing in our raw dataset. This data missing sometimes doesn’t mean we lose some data entries, but we may lose some values for certain columns.
根據數據源以及數據結構的設計方式,原始數據集中可能會缺少一些數據。 有時丟失這些數據并不意味著我們會丟失一些數據條目,但是對于某些列,我們可能會丟失一些值。
When this happened, it is important to identify whether the “null” or “NaN” values make sense in the dataset. If it doesn’t, we may need to get rid of the row.
發生這種情況時,重要的是要確定數據集中“ null”或“ NaN”值是否有意義。 如果沒有,我們可能需要擺脫該行。
However, eliminating the rows having missing values is not always the best idea. Sometimes we may use average values or other technique to fill the gaps. This is depending on the actual case.
但是,消除具有缺失值的行并不總是最好的主意。 有時我們可能會使用平均值或其他技術來填補空白。 這取決于實際情況。
CRAI方法論的使用 (Usage of CRAI Methodology)

Well, I hope the above examples explained what is “CRAI” respectively. Now, let’s take a real example to practice!
好吧,我希望以上示例分別解釋什么是“ CRAI”。 現在,讓我們以一個真實的例子進行練習!
Suppose we have an address column in our dataset, what should we do to make sure it is cleaned?
假設我們的數據集中有一個address列,應該怎么做才能確保它被清除?
C —一致性 (C — Consistency)
- The address might contain street suffixes, such as “Street” and “St”, “Avenue” and “Ave”, “Crescent” and “Cres”. Check whether we have both terms in those pairs. 該地址可能包含街道后綴,例如“街道”和“ St”,“大道”和“ Ave”,“新月”和“克雷斯”。 檢查在這些對中是否同時存在這兩個術語。
- Similarly, if we have state names in the address, we may need to make sure they are consistent, such as “VIC” and “Victoria”. 同樣,如果地址中有州名,則可能需要確保它們是一致的,例如“ VIC”和“ Victoria”。
- Check the unit number presentation of the address. “Unit 9, 24 Abc St” should be the same as “9/24 Abc St”. 檢查地址的單位編號顯示。 “ 9號街24號Abc St”應與“ 9/24 Abc St”相同。
R-理性 (R — Rationality)
- One example would be that the postcode must follow a certain format in a country. For example, it must be 4 digits in Australia. 一個示例是郵政編碼必須在某個國家/地區遵循某種格式。 例如,在澳大利亞必須為4位數字。
- If there is a country in the address string, we may need to pay attention to that. For example, the dataset is about all customers in an international company that runs its business in several countries. If an irrelevant country appears, we might need to further investigate. 如果地址字符串中有一個國家,我們可能需要注意。 例如,數據集涉及在多個國家/地區經營業務的一家國際公司中的所有客戶。 如果出現無關的國家,我們可能需要進一步調查。
A —原子性 (A — Atomicity)
- The most obvious atomicity issue is that we should split the address into several fields such as the street address, suburb, state and postcode. 最明顯的原子性問題是我們應該將地址分成幾個字段,例如街道地址,郊區,州和郵政編碼。
- If our dataset is about households, such as a health insurance policy. It might be worth to pay more attention to those duplicated addresses of different data entries. 如果我們的數據集是關于家庭的,例如健康保險單。 可能需要更多注意不同數據條目的那些重復地址。
我-誠信 (I — Integrity)
- This is about the entire data entry (row-wise) in the dataset. Of course, we need to drop the duplicated rows. 這是關于數據集中的整個數據條目(按行)。 當然,我們需要刪除重復的行。
- Check whether there are any data entries that have their address missing. Depending on the business rules and data analysis objectives, we may need to eliminate the rows that miss addresses. Also, addresses should not be able to be derived usually, so we should not need to fill gaps because we cannot. 檢查是否有任何數據條目的地址丟失。 根據業務規則和數據分析目標,我們可能需要消除丟失地址的行。 同樣,地址通常不能被導出,因此我們不需要填補空白,因為我們不能。
- If in the Atomicity checking, we found that some rows having exactly the same addresses and based on the business rules this can be determined as duplicated, we may need to combine or eliminate them. 如果在原子性檢查中發現某些地址具有完全相同的行,并且根據業務規則可以將其確定為重復行,則可能需要合并或消除它們。
摘要 (Summary)

Here is the “CRAI” methodology I usually follow myself when I first time gets along with a new dataset.
這是我初次接觸新數據集時通常會遵循的“ CRAI”方法。
It turns out that this method is kind of generic, which means that it should be applicable in almost all the scenarios. However, it is also because of its universal, we should pay more attention to the domain knowledge that will influence how you apply CRAI to clean your datasets.
事實證明,這種方法是通用的,這意味著它應該適用于幾乎所有場景。 但是,也是由于它的通用性,我們應該更加注意將影響您如何應用CRAI清理數據集的領域知識。
That’s all I want to share in this article. Hope it helps :)
這就是我要在本文中分享的全部內容。 希望能幫助到你 :)
翻譯自: https://towardsdatascience.com/data-cleansing-where-to-start-90802e95cc5d
uni-app清理緩存數據
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390623.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390623.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390623.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

高級人工智能之群體智能:蟻群算法

JavaScript標準對象:地圖

leetcode 483. 最小好進制

圖像灰度變換及圖像數組操作

npx npm區別_npm vs npx —有什么區別?

找出性能消耗是第一步,如何解決問題才是關鍵

bigquery_如何在BigQuery中進行文本相似性搜索和文檔聚類
![bzoj 1996: [Hnoi2010]chorus 合唱隊](http://pic.xiahunao.cn/bzoj 1996: [Hnoi2010]chorus 合唱隊)
bzoj 1996: [Hnoi2010]chorus 合唱隊

移動應用程序開發_什么是移動應用程序開發?
)
leetcode 1600. 皇位繼承順序(dfs)

vlookup match_INDEX-MATCH — VLOOKUP功能的升級

java基礎-BigDecimal類常用方法介紹

節點對象轉節點_節點流程對象說明

PAT——1018. 錘子剪刀布

leetcode 1239. 串聯字符串的最大長度

flask redis_在Flask應用程序中將Redis隊列用于異步任務
)
CentOS7下分布式文件系統FastDFS的安裝 配置 (單節點)

如何修復會話固定漏洞_PHP安全漏洞:會話劫持,跨站點腳本,SQL注入以及如何修復它們...

劍指 Offer 38. 字符串的排列
)