bigquery
BigQuery offers the ability to load a TensorFlow SavedModel and carry out predictions. This capability is a great way to add text-based similarity and clustering on top of your data warehouse.
BigQuery可以加載TensorFlow SavedModel并執行預測。 此功能是在數據倉庫之上添加基于文本的相似性和群集的一種好方法。
Follow along by copy-pasting queries from my notebook in GitHub. You can try out the queries in the BigQuery console or in an AI Platform Jupyter notebook.
然后在GitHub中從我的筆記本復制粘貼查詢。 您可以在BigQuery控制臺或AI Platform Jupyter筆記本中嘗試查詢。
風暴報告數據 (Storm reports data)
As an example, I’ll use a dataset consisting of wind reports phoned into National Weather Service offices by “storm spotters”. This is a public dataset in BigQuery and it can be queried as follows:
舉例來說,我將使用由“風暴發現者”致電國家氣象局辦公室的風報告組成的數據集。 這是BigQuery中的公共數據集,可以按以下方式查詢:
SELECT
EXTRACT(DAYOFYEAR from timestamp) AS julian_day,
ST_GeogPoint(longitude, latitude) AS location,
comments
FROM `bigquery-public-data.noaa_preliminary_severe_storms.wind_reports`
WHERE EXTRACT(YEAR from timestamp) = 2019
LIMIT 10The result looks like this:
結果看起來像這樣:

Let’s say that we want to build a SQL query to search for comments that look like “power line down on a home”.
假設我們要構建一個SQL查詢來搜索看起來像“家中的電源線”的注釋。
Steps:
腳步:
- Load a machine learning model that creates an embedding (essentially a compact numerical representation) of some text. 加載一個機器學習模型,該模型創建一些文本的嵌入(本質上是緊湊的數字表示形式)。
- Use the model to generate the embedding of our search term. 使用該模型生成搜索詞的嵌入。
- Use the model to generate the embedding of every comment in the wind reports table. 使用該模型可將每個評論嵌入風報告表中。
- Look for rows where the two embeddings are close to each other. 查找兩個嵌入彼此靠近的行。
將文本嵌入模型加載到BigQuery中 (Loading a text embedding model into BigQuery)
TensorFlow Hub has a number of text embedding models. For best results, you should use a model that has been trained on data that is similar to your dataset and which has a sufficient number of dimensions so as to capture the nuances of your text.
TensorFlow Hub具有許多文本嵌入模型。 為了獲得最佳結果,您應該使用經過訓練的模型,該數據類似于您的數據集,并且具有足夠的維數,以捕獲文本的細微差別。
For this demonstration, I’ll use the Swivel embedding which was trained on Google News and has 20 dimensions (i.e., it is pretty coarse). This is sufficient for what we need to do.
在此演示中,我將使用在Google新聞上接受訓練的Swivel嵌入,它具有20個維度(即,非常粗略)。 這足以滿足我們的需求。
The Swivel embedding layer is already available in TensorFlow SavedModel format, so we simply need to download it, extract it from the tarred, gzipped file, and upload it to Google Cloud Storage:
Swivel嵌入層已經可以使用TensorFlow SavedModel格式,因此我們只需要下載它,從壓縮后的壓縮文件中提取出來,然后將其上傳到Google Cloud Storage:
FILE=swivel.tar.gz
wget --quiet -O tmp/swivel.tar.gz https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1?tf-hub-format=compressed
cd tmp
tar xvfz swivel.tar.gz
cd ..
mv tmp swivel
gsutil -m cp -R swivel gs://${BUCKET}/swivelOnce the model files on GCS, we can load it into BigQuery as an ML model:
將模型文件保存到GCS后,我們可以將其作為ML模型加載到BigQuery中:
CREATE OR REPLACE MODEL advdata.swivel_text_embed
OPTIONS(model_type='tensorflow', model_path='gs://BUCKET/swivel/*')嘗試在BigQuery中嵌入模型 (Try out embedding model in BigQuery)
To try out the model in BigQuery, we need to know its input and output schema. These would be the names of the Keras layers when it was exported. We can get them by going to the BigQuery console and viewing the “Schema” tab of the model:
要在BigQuery中試用模型,我們需要了解其輸入和輸出架構。 這些將是導出時Keras圖層的名稱。 我們可以通過轉到BigQuery控制臺并查看模型的“架構”標簽來獲得它們:
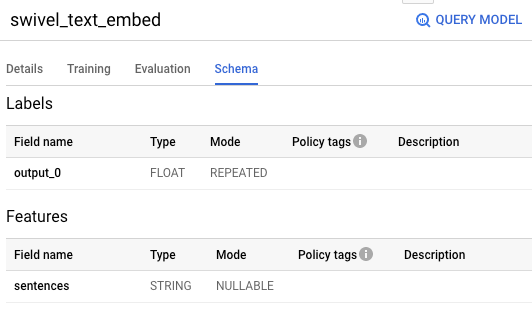
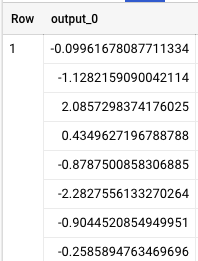
Let’s try this model out by getting the embedding for a famous August speech, calling the input text as sentences and knowing that we will get an output column named output_0:
讓我們通過獲得著名的August演講的嵌入,將輸入文本稱為句子并知道我們將得到一個名為output_0的輸出列來試用該模型:
SELECT output_0 FROM
ML.PREDICT(MODEL advdata.swivel_text_embed,(
SELECT "Long years ago, we made a tryst with destiny; and now the time comes when we shall redeem our pledge, not wholly or in full measure, but very substantially." AS sentences))The result has 20 numbers as expected, the first few of which are shown below:
結果有20個預期的數字,其中前幾個顯示如下:
文件相似度搜尋 (Document similarity search)
Define a function to compute the Euclidean squared distance between a pair of embeddings:
定義一個函數來計算一對嵌入之間的歐幾里德平方距離:
CREATE TEMPORARY FUNCTION td(a ARRAY<FLOAT64>, b ARRAY<FLOAT64>, idx INT64) AS (
(a[OFFSET(idx)] - b[OFFSET(idx)]) * (a[OFFSET(idx)] - b[OFFSET(idx)])
);CREATE TEMPORARY FUNCTION term_distance(a ARRAY<FLOAT64>, b ARRAY<FLOAT64>) AS ((
SELECT SQRT(SUM( td(a, b, idx))) FROM UNNEST(GENERATE_ARRAY(0, 19)) idx
));Then, compute the embedding for our search term:
然后,為我們的搜索詞計算嵌入:
WITH search_term AS (
SELECT output_0 AS term_embedding FROM ML.PREDICT(MODEL advdata.swivel_text_embed,(SELECT "power line down on a home" AS sentences))
)and compute the distance between each comment’s embedding and the term_embedding of the search term (above):
并計算每個評論的嵌入與搜索詞的term_embedding之間的距離(如上):
SELECT
term_distance(term_embedding, output_0) AS termdist,
comments
FROM ML.PREDICT(MODEL advdata.swivel_text_embed,(
SELECT comments, LOWER(comments) AS sentences
FROM `bigquery-public-data.noaa_preliminary_severe_storms.wind_reports`
WHERE EXTRACT(YEAR from timestamp) = 2019
)), search_term
ORDER By termdist ASC
LIMIT 10The result is:
結果是:
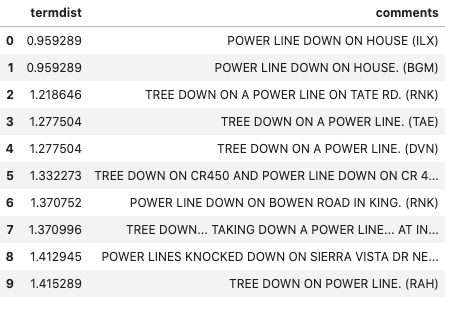
Remember that we searched for “power line down on home”. Note that the top two results are “power line down on house” — the text embedding has been helpful in recognizing that home and house are similar in this context. The next set of top matches are all about power lines, the most unique pair of words in our search term.
請記住,我們搜索的是“家中的電源線”。 請注意,最上面的兩個結果是“房屋上的電源線斷開”-文本嵌入有助于識別房屋和房屋在這種情況下是相似的。 下一組熱門匹配項都是關于電源線的,這是我們搜索詞中最獨特的詞對。
文件叢集 (Document Clustering)
Document clustering involves using the embeddings as an input to a clustering algorithm such as K-Means. We can do this in BigQuery itself, and to make things a bit more interesting, we’ll use the location and day-of-year as additional inputs to the clustering algorithm.
文檔聚類涉及將嵌入用作聚類算法(例如K-Means)的輸入。 我們可以在BigQuery本身中做到這一點,并使事情變得更加有趣,我們將位置和年份作為聚類算法的其他輸入。
CREATE OR REPLACE MODEL advdata.storm_reports_clustering
OPTIONS(model_type='kmeans', NUM_CLUSTERS=10) ASSELECT
arr_to_input_20(output_0) AS comments_embed,
EXTRACT(DAYOFYEAR from timestamp) AS julian_day,
longitude, latitude
FROM ML.PREDICT(MODEL advdata.swivel_text_embed,(
SELECT timestamp, longitude, latitude, LOWER(comments) AS sentences
FROM `bigquery-public-data.noaa_preliminary_severe_storms.wind_reports`
WHERE EXTRACT(YEAR from timestamp) = 2019
))The embedding (output_0) is an array, but BigQuery ML currently wants named inputs. The work around is to convert the array to a struct:
嵌入(output_0)是一個數組,但是BigQuery ML當前需要命名輸入。 解決方法是將數組轉換為結構:
CREATE TEMPORARY FUNCTION arr_to_input_20(arr ARRAY<FLOAT64>)
RETURNS
STRUCT<p1 FLOAT64, p2 FLOAT64, p3 FLOAT64, p4 FLOAT64,
p5 FLOAT64, p6 FLOAT64, p7 FLOAT64, p8 FLOAT64,
p9 FLOAT64, p10 FLOAT64, p11 FLOAT64, p12 FLOAT64,
p13 FLOAT64, p14 FLOAT64, p15 FLOAT64, p16 FLOAT64,
p17 FLOAT64, p18 FLOAT64, p19 FLOAT64, p20 FLOAT64>AS (
STRUCT(
arr[OFFSET(0)]
, arr[OFFSET(1)]
, arr[OFFSET(2)]
, arr[OFFSET(3)]
, arr[OFFSET(4)]
, arr[OFFSET(5)]
, arr[OFFSET(6)]
, arr[OFFSET(7)]
, arr[OFFSET(8)]
, arr[OFFSET(9)]
, arr[OFFSET(10)]
, arr[OFFSET(11)]
, arr[OFFSET(12)]
, arr[OFFSET(13)]
, arr[OFFSET(14)]
, arr[OFFSET(15)]
, arr[OFFSET(16)]
, arr[OFFSET(17)]
, arr[OFFSET(18)]
, arr[OFFSET(19)]
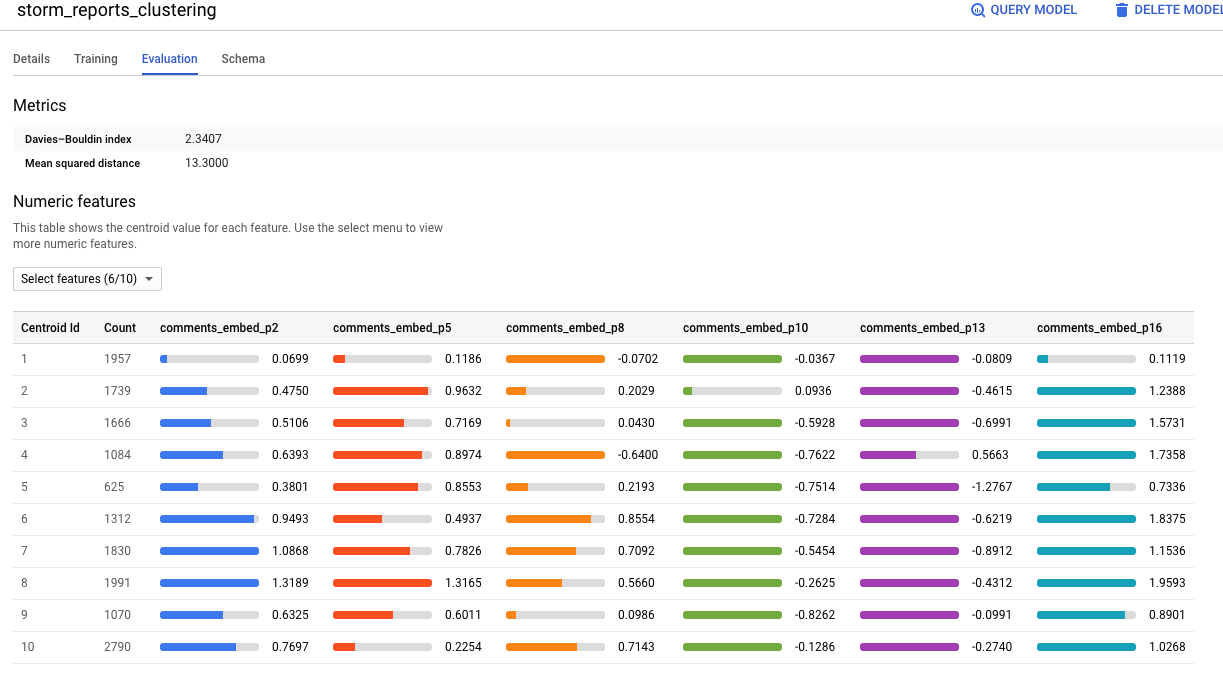
));The resulting ten clusters can visualized in the BigQuery console:
可以在BigQuery控制臺中看到生成的十個集群:
What do the comments in cluster #1 look like? The query is:
第1組中的注釋是什么樣的? 查詢是:
SELECT sentences
FROM ML.PREDICT(MODEL `ai-analytics-solutions.advdata.storm_reports_clustering`,
(
SELECT
sentences,
arr_to_input_20(output_0) AS comments_embed,
EXTRACT(DAYOFYEAR from timestamp) AS julian_day,
longitude, latitude
FROM ML.PREDICT(MODEL advdata.swivel_text_embed,(
SELECT timestamp, longitude, latitude, LOWER(comments) AS sentences
FROM `bigquery-public-data.noaa_preliminary_severe_storms.wind_reports`
WHERE EXTRACT(YEAR from timestamp) = 2019
))))
WHERE centroid_id = 1The result shows that these are mostly short, uninformative comments:
結果表明,這些大多是簡短的,無用的評論:

How about cluster #3? Most of these reports seem to have something to do with verification by radar!!!
第3組如何? 這些報告大多數似乎與雷達驗證有關!!!
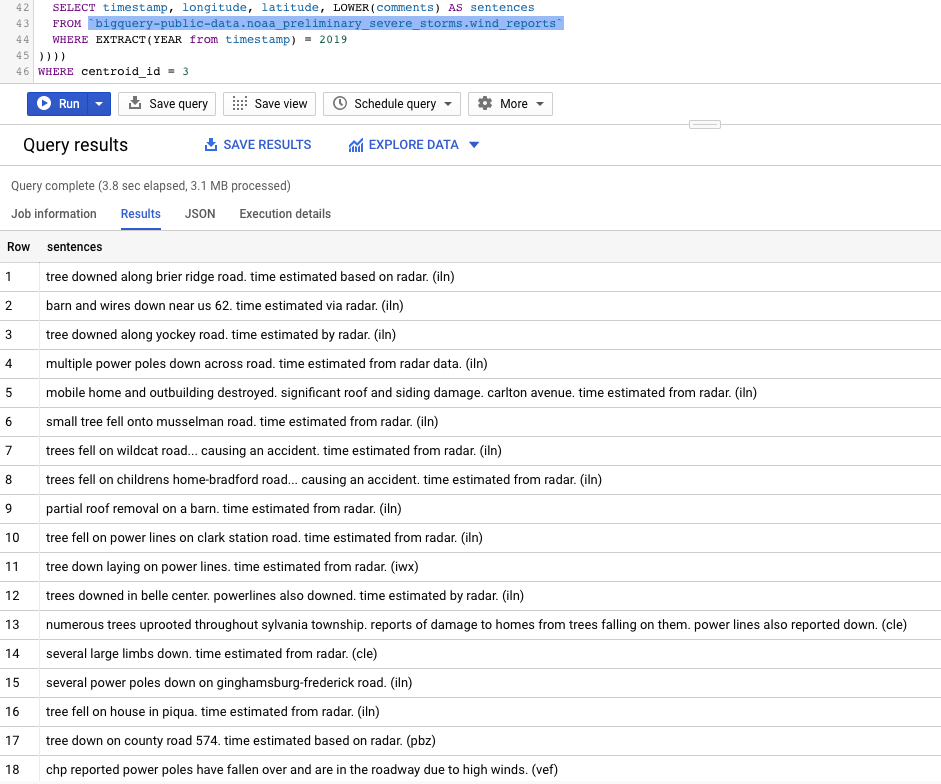
Enjoy!
請享用!
鏈接 (Links)
TensorFlow Hub has several text embedding models. You don’t have to use Swivel, although Swivel is a good general-purpose choice.
TensorFlow Hub具有多個文本嵌入模型。 盡管Swivel是一個不錯的通用選擇,但您不必使用Swivel 。
Full queries are in my notebook on GitHub. You can try out the queries in the BigQuery console or in an AI Platform Jupyter notebook.
完整查詢在我的GitHub筆記本上 。 您可以在BigQuery控制臺或AI Platform Jupyter筆記本中嘗試查詢。
翻譯自: https://towardsdatascience.com/how-to-do-text-similarity-search-and-document-clustering-in-bigquery-75eb8f45ab65
bigquery
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390616.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390616.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390616.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
![bzoj 1996: [Hnoi2010]chorus 合唱隊](http://pic.xiahunao.cn/bzoj 1996: [Hnoi2010]chorus 合唱隊)
bzoj 1996: [Hnoi2010]chorus 合唱隊

移動應用程序開發_什么是移動應用程序開發?
)
leetcode 1600. 皇位繼承順序(dfs)

vlookup match_INDEX-MATCH — VLOOKUP功能的升級

java基礎-BigDecimal類常用方法介紹

節點對象轉節點_節點流程對象說明

PAT——1018. 錘子剪刀布

leetcode 1239. 串聯字符串的最大長度

flask redis_在Flask應用程序中將Redis隊列用于異步任務
)
CentOS7下分布式文件系統FastDFS的安裝 配置 (單節點)

如何修復會話固定漏洞_PHP安全漏洞:會話劫持,跨站點腳本,SQL注入以及如何修復它們...

劍指 Offer 38. 字符串的排列
)
前饋神經網絡中的前饋_前饋神經網絡在基于趨勢的交易中的有效性(1)

解釋什么是快速排序算法?_解釋排序算法

SpringBoot自動化配置的注解開關原理

hadoop將消亡_數據科學家:適應還是消亡!

劍指 Offer 15. 二進制中1的個數 and leetcode 1905. 統計子島嶼
![[轉]kafka介紹](http://pic.xiahunao.cn/[轉]kafka介紹)
[轉]kafka介紹

如何開始android開發_如何開始進行Android開發
