selenium抓取
In this article we will go through a web scraping process of an E-Commerce website. I have designed this particular post to be beginner friendly. So, if you have no prior knowledge about web scraping or Selenium you can still follow along.
在本文中,我們將介紹電子商務網站的Web抓取過程。 我設計的這個特殊職位是初學者友好的。 因此,如果您不具備有關Web抓取或Selenium的先驗知識,則仍然可以繼續。
To understand web scraping, we need to understand HTML code basics. We will cover that as well.
要了解網絡抓取,我們需要了解HTML代碼基礎。 我們也會對此進行介紹。
HTML基礎 (Basics of HTML)
There are a lot of things to talk about concerning HTML basics but we will focus on the things that will be helpful (at least most of the times) in web scraping.
關于HTML基礎知識,有很多要討論的話題,但我們將專注于(至少在大多數情況下)對Web抓取有用的事情。
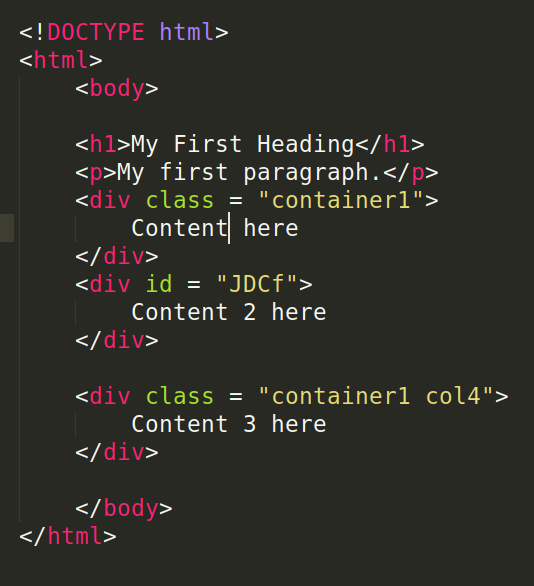

HTML element (Fig 1 RIGHT) — an HTML element is the collection of start tag, its attributes, an end tag and everything in between.
HTML元素 (圖1右)— HTML元素是開始標記,其屬性,結束標記以及介于兩者之間的所有內容的集合。
Attributes — are special words used inside a start tag to control the element’s behavior. Attribute and its value are together used in referencing a tag and its content for styling. The most important attributes we will use in web scraping includes
class,idandname.屬性 -是在開始標簽內用于控制元素行為的特殊單詞。 屬性及其值一起用于引用標簽及其內容的樣式。 我們將在網絡抓取中使用的最重要的屬性包括
class,id和name。classandidattributes — HTML elements can have one or more classes, separated by spaces (see Fig 1 LEFT above). On the other hand, HTML elements must have uniqueidattributes, that is, anidcannot be used to reference more than one HTML element.class和id屬性 -HTML元素可以具有一個或多個用空格分隔的類(請參見上面的圖1左圖)。 另一方面,HTML元素必須具有唯一的id屬性,即,一個id不能用于引用多個HTML元素。
簡單的網頁爬取 (Simple Web Scraping)
Before we go into the actual scraping of an E-Commerce site let us scrape the site shown in the Figure below (from the HTML code in Fig 1 LEFT)
在進入實際的電子商務網站抓取之前,讓我們抓取下圖所示的網站(來自圖1左圖HTML代碼)
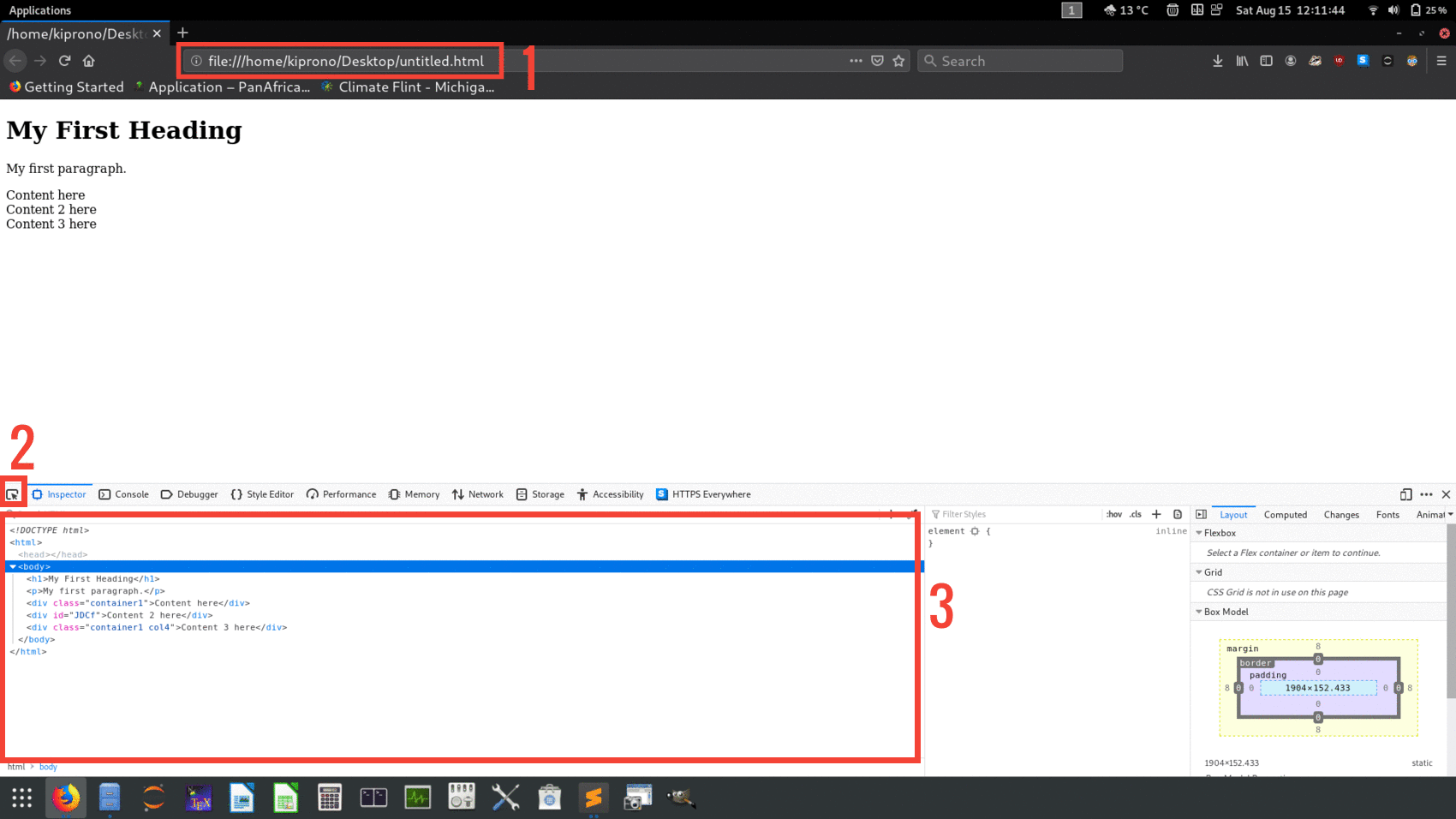
From the Figure (Fig 2) above note the following:
從上圖(圖2)中注意以下幾點:
This is the Uniform Resource Locator (URL). For this particular case, the locator leads to HTML code stored locally.
這是統一資源定位符( URL )。 對于這種特殊情況,定位器會導致本地存儲HTML代碼。
- The button labelled 2 is very important when you are hovering through the page to identify the elements of your interest. Once your object of interest is highlighted the tag element will also be highlighted. 當您將鼠標懸停在頁面上以標識感興趣的元素時,標記為2的按鈕非常重要。 感興趣的對象突出顯示后,標記元素也將突出顯示。
This is the page source code. It is just the HTML code like in Fig 1 LEFT. You can view this page source by clicking Ctrl+Shift+I to inspect the page or right click on site and choose Inspect Element or Inspect whichever is available on the options.
這是頁面源代碼。 就像圖1左圖一樣,它只是HTML代碼。 您可以通過單擊Ctrl + Shift + I來檢查頁面或在站點上單擊鼠標右鍵,然后選擇“ 檢查元素”或“ 檢查 ”選項中可用的內容,以查看此頁面源。
先決條件 (Prerequisites)
To conduct web scraping, we need selenium Python package (If you don’t have the package install it using pip) and browser webdriver. For selenium to work, it must have access to the driver. Download web drivers matching your browser from here: Chrome, Firefox, Edge and Safari. Once the web driver is downloaded, save it and note the path. By default, selenium will look for the driver on the current working directory and as such you may want to save the drive on the same directory as the Python script. You are however not obliged to do this. You can save it anyway and provide a full path to the executable on Line 5 below
要進行網絡抓取,我們需要使用selenium Python軟件包(如果您沒有使用pip安裝該軟件包)和瀏覽器webdriver 。 為了使selenium起作用,它必須有權訪問驅動程序。 從此處下載與您的瀏覽器匹配的Web驅動程序: Chrome , Firefox , Edge和Safari 。 下載網絡驅動程序后,請保存并記下路徑。 默認情況下, selenium將在當前工作目錄中查找驅動程序,因此,您可能希望將驅動器與Python腳本保存在同一目錄中。 但是,您沒有義務這樣做。 您仍然可以保存它,并在下面的第5行提供完整的可執行文件路徑
from selenium import webdriver
import timePATH = "./chromedriver"
driver = webdriver.Chrome(PATH)
driver.get(url="file:///home/kiprono/Desktop/untitled.html")
time.sleep(5)
driver.close()Line 1 and 2 import necessary libraries.
第1行和第2行導入必要的庫。
Line 4 an 5— Define the path to the web driver you downloaded and instantiate a Chrome driver. I am using Chrome web driver but you can as well use Firefox, Microsoft Edge or Safari.
第4行和第5行 -定義您下載的Web驅動程序的路徑并實例化Chrome驅動程序。 我正在使用Chrome Web驅動程序,但您也可以使用Firefox,Microsoft Edge或Safari。
Line 6 — The driver launches a Chrome session in 5 and get the url source in 6.
第6行 -驅動程序在5中啟動Chrome會話,并在6中獲得url源。
Line 7 and 8— This line pauses Python execution for 5 seconds before closing the browser in 8. Pausing is important so that you have a glance of what is happening on the browser and closing ensures that the browsing session is ended otherwise we will end up with so many windows of Chrome sessions. Sleeping time may also be very important when waiting for the page load. However, there is another proper way of initiating a wait.
第7和8行-該行將Python執行暫停5秒鐘,然后在8中關閉瀏覽器。暫停很重要,這樣您就可以瀏覽瀏覽器上發生的一切,并確保關閉瀏覽會話,否則我們將結束Chrome會話的窗口如此之多。 等待頁面加載時,Hibernate時間也可能非常重要。 但是,還有另一種適當的方式來啟動等待。
定位元素 (Locating the Elements)
This is the most important part of web scraping. In this section we need to learn how to get HTML elements by using different attributes.
這是網頁抓取的最重要部分。 在本節中,我們需要學習如何通過使用不同的屬性來獲取HTML元素。
Recall: Elements of a web page can be identified by using a class, id, tag, name or/and xpath. Ids are unique but classes are not. This means that a given class can identify more than one web element whereas one id identifies one and only one element.
回想一下 : 網頁的元素可以通過使用 class , id , tag , name 或/和 xpath 來標識 。 ID是唯一的,但類不是唯一的。 這意味著一個給定的 class 可以標識一個以上的Web元素,而一個 id 標識一個且只有一個元素。
One HTML element can be identified using any of the following methods
可以使用以下任何一種方法來標識一個HTML元素
- driver.find_element_by_id driver.find_element_by_id
- driver.find_element_by_name driver.find_element_by_name
- driver.find_element_by_xpath driver.find_element_by_xpath
- driver.find_element_by_tag_name driver.find_element_by_tag_name
- driver.find_element_by_class_name driver.find_element_by_class_name
Multiple HTML elements can be identified using any of the following (the result is a list of elements found)
可以使用以下任意一種來標識多個HTML元素(結果是找到的元素列表)
- driver.find_elements_by_name driver.find_elements_by_name
- driver.find_elements_by_xpath driver.find_elements_by_xpath
- driver.find_elements_by_tag_name driver.find_elements_by_tag_name
- driver.find_elements_by_class_name driver.find_elements_by_class_name
Note: id cannot be used to identify multiple elements because id can only identify one element.
注意: id 不能用于標識多個元素,因為 id 只能標識一個元素。
from selenium import webdriver
import timePATH = "./chromedriver"
driver = webdriver.Chrome(PATH)
driver.get(url="file:///home/kiprono/Desktop/untitled.html")
print("Element identified by id:",driver.find_element_by_id("JDCf").text)
print("Element identified by class:",driver.find_element_by_class_name("container1").text)
print("Element identified by class:",driver.find_element_by_class_name("col4").text)
print("Element identified by tag name:",driver.find_element_by_tag_name("h1").text)
print("Element identified by xpath:",driver.find_element_by_xpath("/html/body/p").text)time.sleep(5)
driver.close()Output:
輸出:
Element identified by id: Content 2 here
Element identified by class: Content here
Element identified by class: Content 3 here
Element identified by tag name: My First Heading
Element identified by xpath: My first paragraph.Line 8 — Note that
container1is a class attribute value identifying two elements anddrive.find_element_by_class_namereturns the first element found.第8行 -注意
container1是一個類屬性值,標識兩個元素,drive.find_element_by_class_name返回找到的第一個元素。To extract the text from HTML element we use
.textfunction as shown in the code snippet above.要從HTML元素中提取文本,我們使用
.text函數,如上面的代碼片段所示。Line 11 — To locate an element by
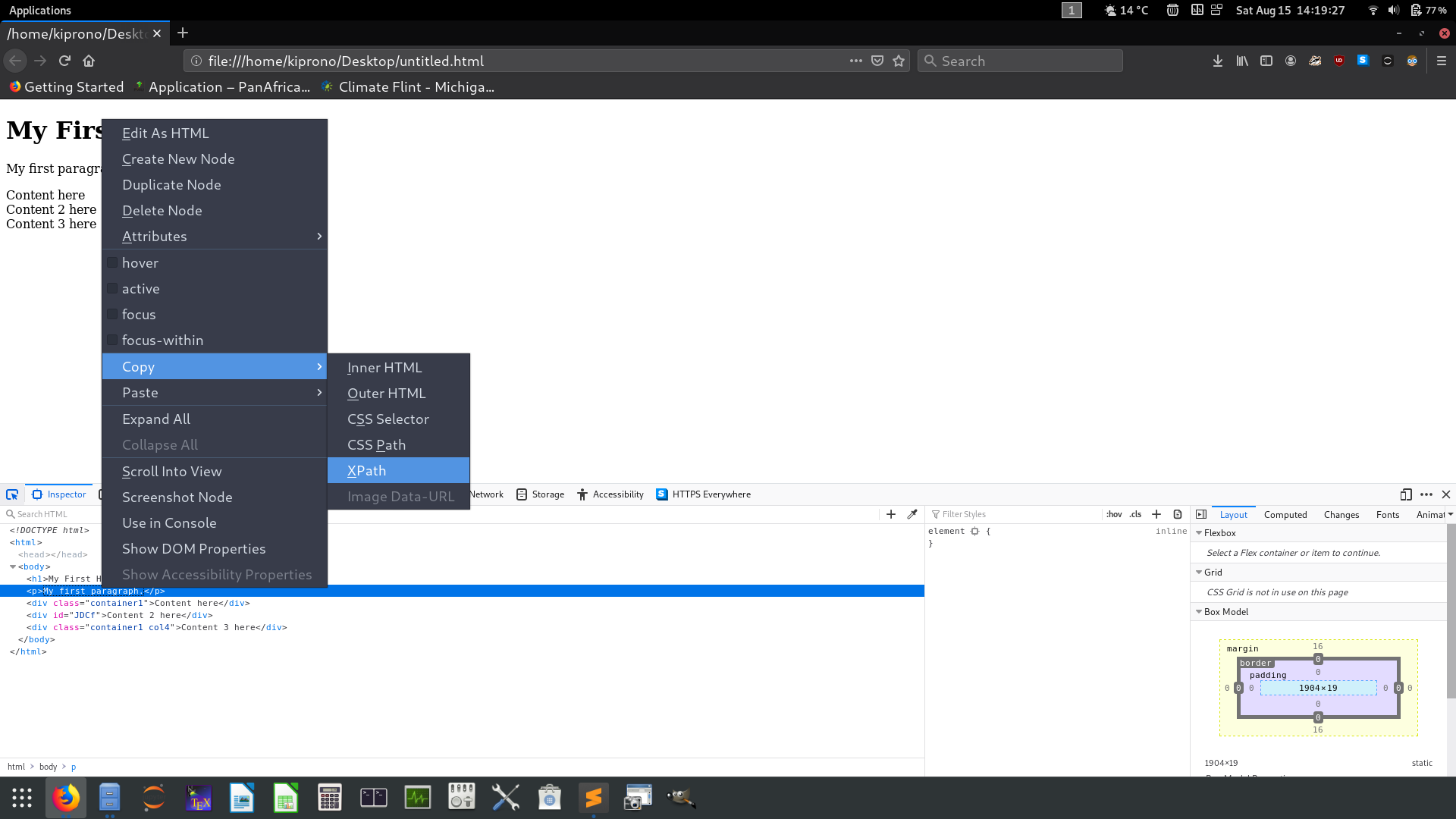
xpathinspect the site elements, right click on the source code matching the element of interest and copy the XPath as show in the Figure (Fig 3) below第11行 -要通過
xpath查找元素,請檢查站點元素,右鍵單擊與感興趣的元素匹配的源代碼,然后復制XPath,如下圖(圖3)所示
We can identify and loop through both elements identified by container1 class as shown below
我們可以識別并遍歷container1類識別的兩個元素,如下所示
multiple_elements = driver.find_elements_by_class_name("container1")
for element in multiple_elements:print(element.text)Output:
輸出:
Content here
Content 3 here刮實際站點 (Scraping Actual Site)
Now that you got the feel of how selenium work let us go ahead and scrape the actual site we are supposed to scrape. We will be scraping online book store [link].
現在您已經感覺到Selenium的工作方式,讓我們繼續進行操作,并刮除應該刮除的實際站點。 我們將抓取在線書店[ 鏈接 ]。
We will proceed as follows.
我們將進行如下操作。
- Scrape details for each book on the page. Each page as 20 books. The details of each book can be found by using the URL on each card. So, to get the book details we need this links. 在頁面上刮取每本書的詳細信息。 每頁為20本書。 可以通過使用每張卡上的URL找到每本書的詳細信息。 因此,要獲取書籍詳細信息,我們需要此鏈接。
- Scrape books in each and every page. This means that we will have a loop to scrape each book in the page and another one to iterate through pages. 在每一頁中刮擦書籍。 這意味著我們將有一個循環來抓取頁面中的每一本書,而另一循環則要遍歷頁面。
- Moving from one page to another involves a modification of the URL in a way that it is trivial to predict a link to any page. 從一頁移動到另一頁涉及對URL的修改,這很容易預測到任何頁面的鏈接。
Here are the pages:
以下是頁面:
Page 1 URL : http://books.toscrape.com/ . The following link also works for page 1 : http://books.toscrape.com/catalogue/page-1.html
第1頁網址: http : //books.toscrape.com/ 。 以下鏈接也適用于第1頁: http : //books.toscrape.com/catalogue/page-1.html
Page 2 URL : http://books.toscrape.com/catalogue/page-2.html
第2頁網址: http : //books.toscrape.com/catalogue/page-2.html
Page 3 URL : http://books.toscrape.com/catalogue/page-3.html
第3頁網址: http : //books.toscrape.com/catalogue/page-3.html
Page 4 URL : http://books.toscrape.com/catalogue/page-4.html
第4頁網址: http : //books.toscrape.com/catalogue/page-4.html
- and so on 等等
Clearly, we can notice a pattern implying that looping through the pages will be simple because we can generate these URL as we move along the loop.
顯然,我們可以注意到一種模式,這意味著在頁面之間循環很簡單,因為在循環中我們可以生成這些URL。
刮一本書 (Scraping one book)
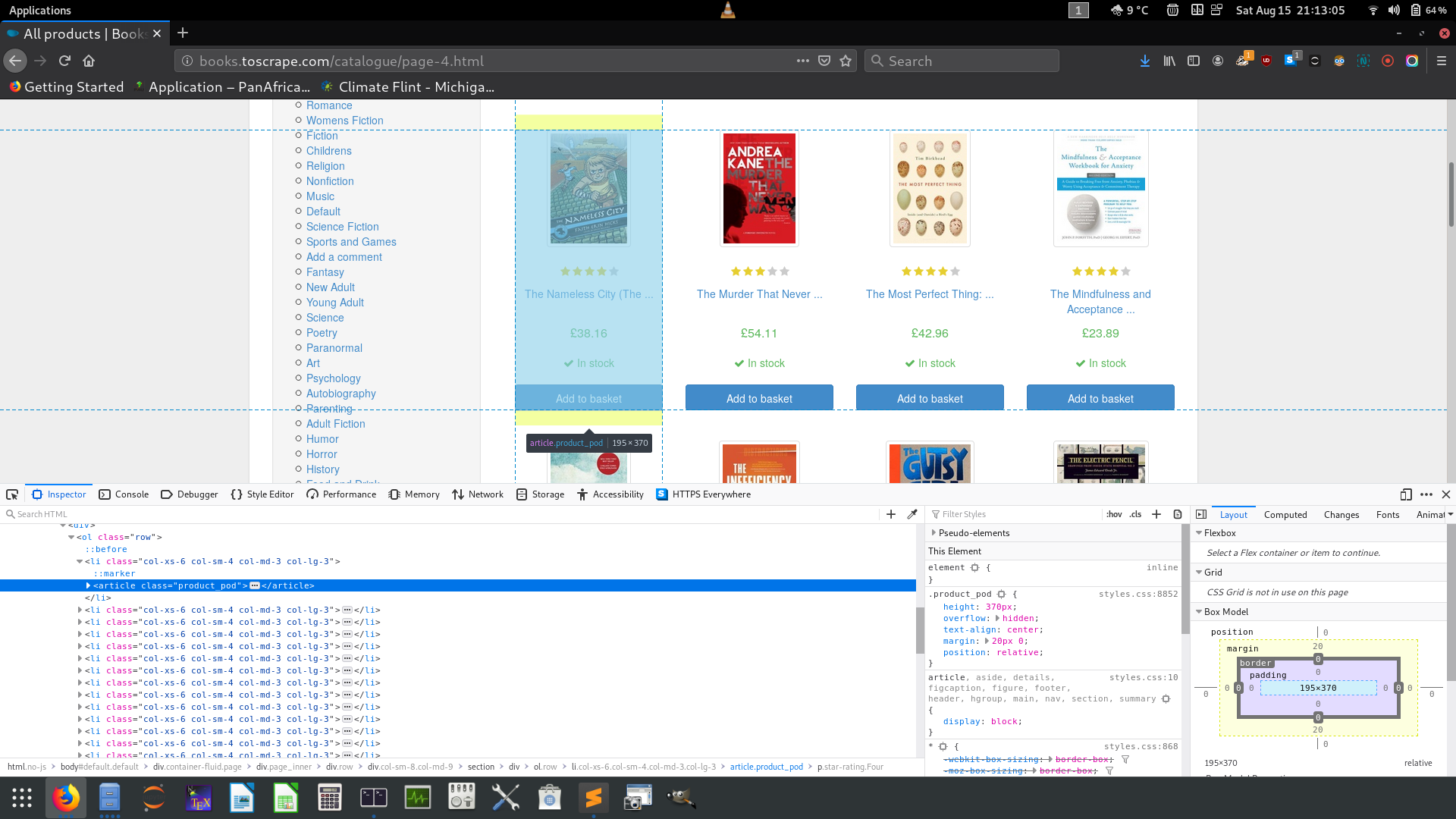
On inspecting the site here is the HTML code for the highlighted region (representing one book)
在檢查站點時,這里是突出顯示區域HTML代碼(代表一本書)
<article class="product_pod">
<div class="image_container">
<a href="the-nameless-city-the-nameless-city-1_940/index.html">
<img src="../media/cache/f4/79/f479de5f305c2ac0512702cf7155bb74.jpg" alt="The Nameless City (The Nameless City #1)" class="thumbnail">
</a>
</div>
<p class="star-rating Four">
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
</p>
<h3>
<a href="the-nameless-city-the-nameless-city-1_940/index.html" title="The Nameless City (The Nameless City #1)">The Nameless City (The ...</a>
</h3>
<div class="product_price">
<p class="price_color">£38.16</p>
<p class="instock availability">
<i class="icon-ok"></i>
In stock</p>
<form>
<button type="submit" class="btn btn-primary btn-block" data-loading-text="Adding...">Add to basket</button>
</form>
</div>
</article>Before we go into coding lets make some observations
在進行編碼之前,先觀察一下
The book in question is inside
articletag. The tag as a class attribute with the valueproduct_prod有問題的書在
article標簽里面。 標記作為類屬性,其值為product_prodWhat we need in this card is to get the URL, that is,
hrefinatag. to get intohrefwe need to move down the hierarchy as follows:class= “product_prod”>h3tag >atag and the get value ofhrefattribute.我們需要在這個卡有什么是讓URL,即,
href的a標簽。 進入href我們需要下移如下層次:class= “product_prod”>h3標簽>a標簽和的get值href屬性。In fact all books in all pages belong to the same class
product_prodand witharticletag.實際上,所有頁面中的所有書籍都屬于同一類
product_prod并帶有article標簽。
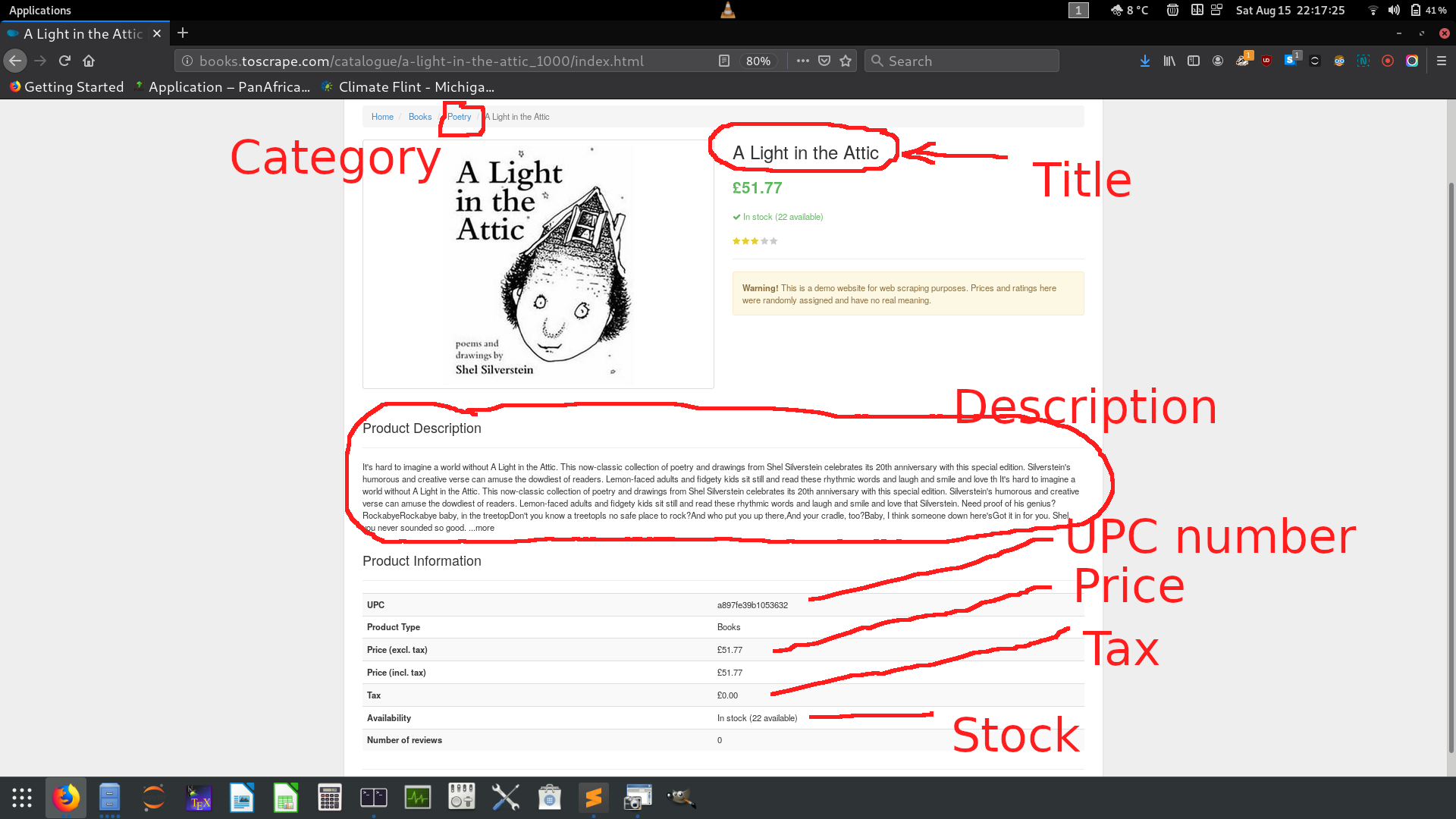
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import pandas as pd
import numpy as np
import re#Set up the path to the chrome driver
PATH = "/home/kiprono/chromedriver"
driver = webdriver.Chrome(PATH)
#parse the page source using get() function
driver.get("http://books.toscrape.com/catalogue/category/books_1/page-1.html")#We find all the books in the page and just use 1
incategory = driver.find_elements_by_class_name("product_pod")[0]
#local the URL to open the contents of the book
a = incategory.find_element_by_tag_name("h3").find_element_by_tag_name("a").get_property("href")
driver.get(a)
#locate our elements of interest on the page containing book details.
title = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/h1")
price = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/p[1]")
stock = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/p[2]")
stars = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/p[3]").get_attribute("class")
stock = int(re.findall("\d+",stock.text)[0])# This is a fuction to convert stars from string expressions to int
def StarConversion(value):if value == "One":return 1elif value == "Two":return 2elif value == "Three":return 3elif value == "Four":return 4elif value == "Five":return 5 stars = StarConversion(stars.split()[1])description = driver.find_element_by_xpath("//*[@id='content_inner']/article/p")upc = driver.find_element_by_xpath("//*[@id='content_inner']/article/table/tbody/tr[1]/td")tax = driver.find_element_by_xpath("//*[@id='content_inner']/article/table/tbody/tr[5]/td")category_a = driver.find_element_by_xpath("//*[@id='default']/div/div/ul/li[3]/a")# all of our interest into a dictionary r
r = {"Title":title.text,"Stock": stock,"Stars": stars,"Price":price.text,"Tax":tax.text,"UPC":upc.text,"Description": description.text
}# print all contents of the dictionary
print(r)time.sleep(3)
driver.quit()Lets go through some lines so that you understand what the code is actually doing
讓我們看幾行,以便您了解代碼的實際作用
Line 16 through 18 — We are moving down the the HTML code to get the URL for the book. Once we get the link we open in 19. Note that 16 locates all books in the page because all the books belongs to the same class
product_prodthat is why we index (index 0) it to get only one book.第16到18行-我們向下移動HTML代碼以獲取該書的URL。 一旦獲得鏈接,我們將在19中打開。請注意, 16會定位頁面中的所有書籍,因為所有書籍都屬于同一類
product_prod,這就是為什么我們對其進行索引(索引0)以獲得一本書的原因。It is also important to note that the numbers of stars a book has comes as a property of
ptag. Here is where the star is located:同樣重要的是要注意,一本書擁有的星星數是
p標簽的屬性。 這是星星所在的位置:
<p class="star-rating Four">
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
</p>This book is rated 4-star but this fact is hidden as a value to the class attribute. You use get_attribute(class) to access such an information. On extracting content on line 24 by using text function, you will get such a string
這本書被評為四星級,但是這個事實被隱藏為class屬性的值。 您可以使用get_attribute(class)訪問此類信息。 通過使用text函數在第24行提取內容時,您將獲得這樣的字符串
star-rating FourTherefore we had to splitting the string before using the function in line 28–38 to get the actual star as a number.
因此,在使用第28–38行中的函數之前,我們必須先對字符串進行分割,以獲取實際的星形作為數字。
If you extract the text content in 23 you will end up with such as string
如果您提取23中的文本內容,您將最終得到諸如字符串
In stock (22 available)What we need is just the number 22 to mean that we have 22 copies available. We achieve that with line 25 where we are using regular expressions to extract the number.
我們需要的只是數字22,意味著我們有22份副本。 我們在第25行使用正則表達式提取數字來實現這一點。
re.findall("\d+","In stock (22 available)")Output:
['22']In regular expression
\dmeans the values [0–9] and+means one or more occurrence of a character in that class, that is, in our case, we want to capture any number (irrespective of the number of the digits) in the string.在正則表達式中,
\d表示值[0–9],而+表示該類中一個或多個字符的出現,也就是說,在我們的例子中,我們要捕獲任何數字(與數字個數無關)字符串。
在一頁中刮所有書 (Scrape all books in one page)
Recall that line 16 above locates all the books in the page. Therefore, in order to scrape all the books in one page we need to loop through the list generated in that line as shown below
回想一下上面的第16行找到了頁面中的所有書籍。 因此,為了將所有書籍抓取到一頁中,我們需要遍歷該行中生成的列表,如下所示
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import pandas as pd
import numpy as np
import redef StarConversion(value):if value == "One":return 1elif value == "Two":return 2elif value == "Three":return 3elif value == "Four":return 4elif value == "Five":return 5 # Scrape one category # Travel#Set up the path to the chrome driver
PATH = "/home/kiprono/chromedriver"
driver = webdriver.Chrome(PATH)
driver.get("http://books.toscrape.com/catalogue/category/books_1/page-1.html")# Lets find all books in the page
incategory = driver.find_elements_by_class_name("product_pod")
#Generate a list of links for each and every book
links = []
for i in range(len(incategory)):item = incategory[i]#get the href propertya = item.find_element_by_tag_name("h3").find_element_by_tag_name("a").get_property("href")#Append the link to list linkslinks.append(a)all_details = []
# Lets loop through each link to acces the page of each book
for link in links:# get one book urldriver.get(url=link)# title of the booktitle = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/h1")# price of the bookprice = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/p[1]")# stock - number of copies available for the bookstock = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/p[2]")# Stock comes as stringstock = int(re.findall("\d+",stock.text)[0])# Stars - Actual stars are in the tag attributestars = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/p[3]").get_attribute("class")# convert string to number. Stars are like One, Two, Three ... We need 1,2,3,...stars = StarConversion(stars.split()[1])# Descriptiontry:description = driver.find_element_by_xpath("//*[@id='content_inner']/article/p")description = description.textexcept:description = None# UPC IDupc = driver.find_element_by_xpath("//*[@id='content_inner']/article/table/tbody/tr[1]/td")# Tax imposed in the booktax = driver.find_element_by_xpath("//*[@id='content_inner']/article/table/tbody/tr[5]/td")# Category of the bookcategory_a = driver.find_element_by_xpath("//*[@id='default']/div/div/ul/li[3]/a")# Define a dictionary with details we needr = {"1Title":title.text,"2Category":category_a.text,"3Stock": stock,"4Stars": stars,"5Price":price.text,"6Tax":tax.text,"7UPC":upc.text,"8Description": description}# append r to all detailsall_details.append(r)time.sleep(4)driver.close()Once you have understood the previous example of scraping one book then this one should be easy to follow because the only difference is that we want to loop through all the books extracting the links (lines 33 through 38) and then loop through those links to extract the information we needed (line 42–84).
一旦您了解了前面刮取一本書的示例,那么該書應該很容易理解,因為唯一的區別是我們要循環瀏覽所有書籍以提取鏈接( 第33至38行 ),然后循環瀏覽這些鏈接以提取鏈接我們需要的信息( 第42–84行 )。
In this snippet also we have introduced try-except blocks to catch cases where the information we want is not available. Specifically, some books misses description section.
在此代碼段中,我們還引入了try-except塊來捕獲所需信息不可用的情況。 具體來說,有些書缺少description部分。
I am sure you will also enjoy to see selenium open the pages as you watch. Enjoy!
我相信您也會喜??歡Selenium在觀看時打開頁面。 請享用!
刮取所有頁面中的所有書籍 (Scraping all books in all pages)
The key concept to understand here is that we need to loop through each book in each page, that is, two loops are involved here. As stated earlier we know that pages URL follows some pattern, for example, in our case we have
這里要理解的關鍵概念是,我們需要遍歷每一頁中的每一本書,也就是說,這里涉及兩個循環。 如前所述,我們知道頁面URL遵循某種模式,例如,在我們的情況下,
Page 1 : http://books.toscrape.com/index.html or http://books.toscrape.com/catalogue/page-1.html
第1頁: http : //books.toscrape.com/index.html或http://books.toscrape.com/catalogue/page-1.html
Page 2: http://books.toscrape.com/catalogue/page-2.html
第2頁: http : //books.toscrape.com/catalogue/page-2.html
Page 3: http://books.toscrape.com/catalogue/page-3.html
第3頁: http : //books.toscrape.com/catalogue/page-3.html
- and so on until page 50 (we have 50 pages on site). 依此類推,直到第50頁(我們的網站上有50頁)。
We can easily create a Python for-loop to generate such URLs. Lets see how we can generate the first 10
我們可以輕松地創建Python for循環來生成此類URL。 讓我們看看如何生成前10個
for c in range(1,11):print("http://books.toscrape.com/catalogue/category/books_1/page-{}.html".format(c))Output:
輸出:
http://books.toscrape.com/catalogue/category/books_1/page-1.htmlhttp://books.toscrape.com/catalogue/category/books_1/page-2.htmlhttp://books.toscrape.com/catalogue/category/books_1/page-3.htmlhttp://books.toscrape.com/catalogue/category/books_1/page-4.htmlhttp://books.toscrape.com/catalogue/category/books_1/page-5.htmlhttp://books.toscrape.com/catalogue/category/books_1/page-6.htmlhttp://books.toscrape.com/catalogue/category/books_1/page-7.htmlhttp://books.toscrape.com/catalogue/category/books_1/page-8.htmlhttp://books.toscrape.com/catalogue/category/books_1/page-9.htmlhttp://books.toscrape.com/catalogue/category/books_1/page-10.htmlTherefore, we can scrape all books in all pages simply as below
因此,我們可以如下簡單地刮取所有頁面中的所有書籍
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import pandas as pd
import numpy as np
import re# Scrape one category # Travel#Set up the path to the chrome driver
PATH = "/home/kiprono/chromedriver"
driver = webdriver.Chrome(PATH)
#parse the page source using get() function
driver.get("http://books.toscrape.com/catalogue/category/books_1/index.html")def StarConversion(value):if value == "One":return 1elif value == "Two":return 2elif value == "Three":return 3elif value == "Four":return 4elif value == "Five":return 5 #next_button = driver.find_element_by_class_name("next").find_element_by_tag_name("a").click()
all_details = []
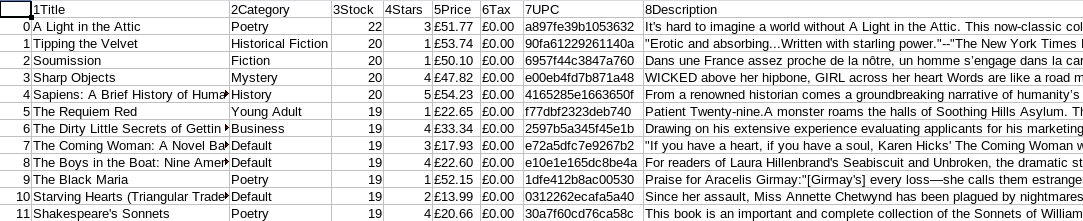
for c in range(1,51):try:#get the pagedriver.get("http://books.toscrape.com/catalogue/category/books_1/page-{}.html".format(c))print("http://books.toscrape.com/catalogue/category/books_1/page-{}.html".format(c))# Lets find all books in the pageincategory = driver.find_elements_by_class_name("product_pod")#Generate a list of links for each and every booklinks = []for i in range(len(incategory)):item = incategory[i]#get the href propertya = item.find_element_by_tag_name("h3").find_element_by_tag_name("a").get_property("href")#Append the link to list linkslinks.append(a)# Lets loop through each link to acces the page of each bookfor link in links:# get one book urldriver.get(url=link)# title of the booktitle = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/h1")# price of the bookprice = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/p[1]")# stock - number of copies available for the bookstock = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/p[2]")# Stock comes as string so we need to use this regex to exract digitsstock = int(re.findall("\d+",stock.text)[0])# Stars - Actual stars are values of class attributestars = driver.find_element_by_xpath("//*[@id='content_inner']/article/div[1]/div[2]/p[3]").get_attribute("class")# convert string to number. Stars are like One, Two, Three ... We need 1,2,3,...stars = StarConversion(stars.split()[1])# Descriptiontry:description = driver.find_element_by_xpath("//*[@id='content_inner']/article/p")description = description.textexcept:description = None# UPC IDupc = driver.find_element_by_xpath("//*[@id='content_inner']/article/table/tbody/tr[1]/td")# Tax imposed in the booktax = driver.find_element_by_xpath("//*[@id='content_inner']/article/table/tbody/tr[5]/td")# Category of the bookcategory_a = driver.find_element_by_xpath("//*[@id='default']/div/div/ul/li[3]/a")# Define a dictionary with details we needr = {"1Title":title.text,"2Category":category_a.text,"3Stock": stock,"4Stars": stars,"5Price":price.text,"6Tax":tax.text,"7UPC":upc.text,"8Description": description}# append r to all detailsall_details.append(r)except:# Lets just close the browser if we run to an errordriver.close()# save the information into a CSV file
df = pd.DataFrame(all_details)
df.to_csv("all_pages.csv")time.sleep(3)
driver.close()The only difference between this snippet and the previous one is the fact that we are looping through pages with the loop starting in line 34 and the fact we also write all the information scraped into a CSV file named all_pages.csv .
此代碼段與上一個代碼段之間的唯一區別是,我們正在循環瀏覽頁面,循環從第34行開始,并且我們還將所有抓取的信息都寫入了名為all_pages.csv的CSV文件all_pages.csv 。
We are also using try-expect to handle exceptions that may arise in the process of scraping. In case an exception is raise we just exit and close the browser (line 94)
我們還使用try-expect處理可能在抓取過程中出現的異常。 萬一引發異常,我們只需退出并關閉瀏覽器( 第94行 )
結論 (Conclusion)
Web scraping is an important process of collecting data from the internet. Different websites have different designs and therefore there’s no particular one scraper that can be used in any particular site. The most essential skill is to understand web scraping on a high level: knowing how to locate web elements and being able to identify and handle errors when they arise. This kind of understanding comes up when we practice web scraping on different sites.
Web抓取是從Internet收集數據的重要過程。 不同的網站具有不同的設計,因此,沒有一個特定的刮板可用于任何特定的站點。 最基本的技能是從較高的角度了解Web抓取:知道如何定位Web元素并能夠在出現錯誤時進行識別和處理。 當我們在不同站點上練習Web抓取時,就會出現這種理解。
Here are more web scraping examples:
以下是更多網絡抓取示例:
Lastly, some websites do not permit their data to be scraped especially scraping and publishing the result. It is, therefore, important to check the site policies before scraping.
最后,某些網站不允許刮擦其數據,尤其是刮擦并發布結果。 因此,在抓取之前檢查站點策略很重要。
As always, thank you for reading :-)
和往常一樣,謝謝您的閱讀:-)
翻譯自: https://towardsdatascience.com/web-scraping-e-commerce-website-using-selenium-1088131c8541
selenium抓取
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390572.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390572.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390572.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

劍指 Offer 37. 序列化二叉樹

ie8 ajaxSubmit 上傳文件提示下載

一個簡單的 js 時間對象創建

裁判打分_內在的裁判偏見

數據庫sql課程設計_SQL和數據庫-初學者完整課程

LCP 07. 傳遞信息

微信公眾號自動回復加超鏈接最新可用實現方案

devops開發模式流程圖_2020 Web開發人員路線圖–成為前端,后端或DevOps開發人員的視覺指南

從Jupyter Notebook切換到腳本的5個理由

leetcode 1833. 雪糕的最大數量

MVC架構 -- 初學試水選課管理系統

rest api 示例2_REST API教程– REST Client,REST Service和API調用通過代碼示例進行了解釋

win10子系統linux編譯ffmpeg

ip登錄打印機怎么打印_不要打印,登錄。

leetcode 451. 根據字符出現頻率排序

Spring-Security 自定義Filter完成驗證碼校驗

如何使用Ionic和Firebase在短短三天內創建冠狀病毒跟蹤器應用程序
_封裝思想——this關鍵字)
二、Java面向對象(7)_封裝思想——this關鍵字

機器學習模型 非線性模型_調試機器學習模型的終極指南
