意見 (Opinion)
動機 (Motivation)
Like most people, the first tool I used when started learning data science is Jupyter Notebook. Most of the online data science courses use Jupyter Notebook as a medium to teach. This makes sense because it is easier for beginners to start writing code in Jupyter Notebook’s cells than writing a script with classes and functions.
與大多數人一樣,我開始學習數據科學時使用的第一個工具是Jupyter Notebook。 大多數在線數據科學課程都使用Jupyter Notebook作為教學手段。 這是有道理的,因為對于初學者來說,在Jupyter Notebook的單元格中開始編寫代碼比編寫具有類和函數的腳本要容易得多。
Another reason why Jupyter Notebook is such a common tool in data science is that Jupyter Notebook makes it easy to explore and plot the data. When we type ‘Shift + Enter’, we will immediately see the results of the code, which makes it easy for us to identify whether our code works or not.
Jupyter Notebook之所以成為數據科學中如此普遍的工具的另一個原因是,Jupyter Notebook使其易于瀏覽和繪制數據。 當我們鍵入“ Shift + Enter”時,我們將立即看到代碼的結果,這使我們很容易確定我們的代碼是否有效。
However, I realized several fallbacks of Jupyter Notebook as I work with more data science projects:
但是,當我處理更多數據科學項目時,我意識到了Jupyter Notebook的一些后備功能:
Unorganized: As my code gets bigger, it becomes increasingly difficult for me to keep track of what I write. No matter how many markdowns I use to separate the notebook into different sections, the disconnected cells make it difficult for me to concentrate on what the code does.
雜亂無章 :隨著我的代碼變得越來越大,對我而言,跟蹤自己的編寫變得越來越困難。 無論我使用多少次降價將筆記本分成不同的部分,斷開的單元格都使我難以集中精力執行代碼。
Difficult to experiment: You may want to test with different methods of processing your data, choose different parameters for your machine learning algorithm to see if the accuracy increases. But every time you experiment with new methods, you need to rerun the entire notebook. This is time-consuming, especially when the processing procedure or the training takes a long time to run.
難以實驗:您 可能想用不同的數據處理方法進行測試,為機器學習算法選擇不同的參數以查看準確性是否提高。 但是,每次嘗試新方法時,都需要重新運行整個筆記本。 這非常耗時,尤其是在處理過程或培訓需要很長時間才能運行時。
Not ideal for reproducibility: If you want to use new data with a slightly different structure, it would be difficult to identify the source of error in your notebook.
對于重現性而言并不理想:如果要使用結構略有不同的新數據,則很難在筆記本中識別錯誤源。
Difficult to debug: When you get an error in your code, it is difficult to know whether the reason for the error is the code or the change in data. If the error is in the code, which part of the code is causing the problem?
難以調試:當您得到 代碼中的錯誤,很難知道錯誤的原因是代碼還是數據更改。 如果錯誤出在代碼中,則代碼的哪一部分導致了問題?
Not ideal for production: Jupyter Notebook does not play very well with other tools. It is not easy to run the code from Jupyter Notebook while using other tools.
對于生產而言并不理想: Jupyter Notebook在與其他工具配合使用時效果不佳。 使用其他工具時,從Jupyter Notebook運行代碼并不容易。
I knew there must be a better way to handle my code so I decided to give scripts a try. These are the benefits I found when using scripts:
我知道必須有一種更好的方式來處理我的代碼,所以我決定嘗試一下腳本。 這些是我在使用腳本時發現的好處:
有組織的 (Organized)
The cells in Jupyter Notebook make it difficult to organize the code into different parts. With a script, we could create several small functions with each function specifies what the code does like this
Jupyter Notebook中的單元格使得很難將代碼組織成不同的部分。 使用腳本,我們可以創建幾個小函數,每個函數指定代碼的功能,如下所示
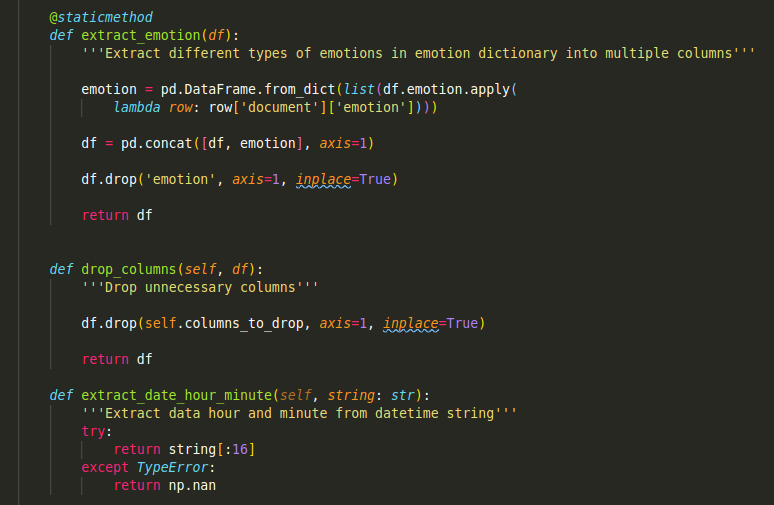
Better yet, if these functions could be categorized in the same category such as functions to process the data, we could put them in the same class!
更好的是,如果可以將這些函數歸為同一類,例如處理數據的函數,我們可以將它們歸為同一類!
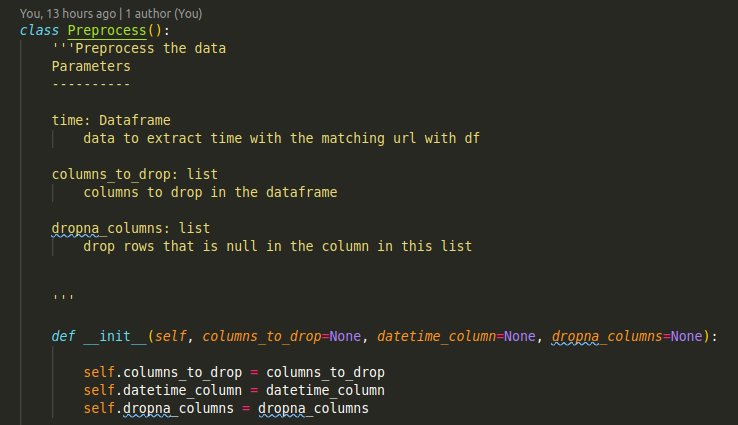
Whenever we want to process our data, we know the functions in the class Preprocess can be used for this purpose.
每當我們要處理數據時,我們都知道Preprocess類中的函數可用于此目的。
鼓勵實驗 (Encourage Experiment)
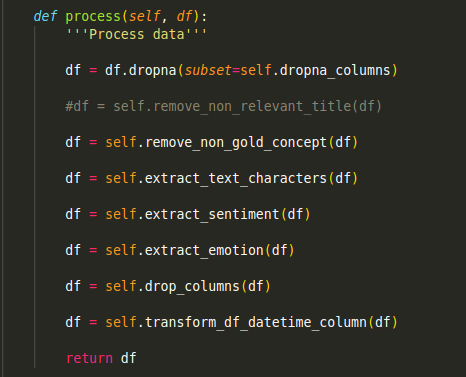
When we want to experiment with a different approach to preprocess data, we could just add or remove a function by commenting out like this without being afraid to break the code! Even if we happen to break the code, we know exactly where to fix it.
當我們想嘗試另一種預處理數據的方法時,我們可以通過注釋掉這樣的方式來添加或刪除函數,而不必擔心破壞代碼! 即使我們碰巧破壞了代碼,我們也知道在哪里修復它。
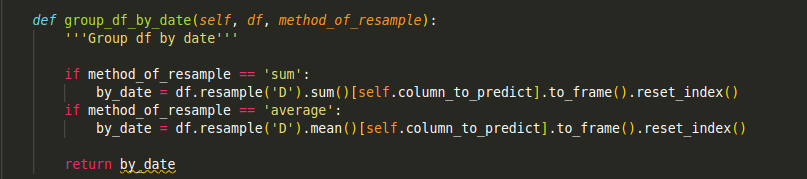
We could also experiment with different parameters by changing the input of the functions. For example, if we want to see how different methods of resampling my Pandas series affect my results, we could just switch from method_of_resample='sum’ to method_of_resample= 'average'. How neat!
我們還可以通過更改函數的輸入來試驗不同的參數。 例如,如果要查看對熊貓系列進行重采樣的不同方法如何影響我的結果,可以將其從method_of_resample='sum'切換到method_of_resample= 'average' 。 多么整潔!
You can still use functions in a notebook, but when your number of functions gets really big, you might want to split the functions in different notebooks. Importing functions across different notebook is not easy.
您仍然可以在筆記本中使用功能,但是當功能數量真的很大時,您可能希望將功能拆分到不同的筆記本中。 跨不同筆記本導入功能并不容易。
重現性的理想選擇 (Ideal for Reproducibility)
With classes and functions, we could make the code general enough so that it will be able to work with other data.
使用類和函數,我們可以使代碼足夠通用,以便能夠與其他數據一起使用。
For example, if we want to drop different columns in my new data, we just need to change columns_to_drop to a list of columns, we want to drop and the code will run smoothly!
例如,如果我們想在新數據中刪除不同的列,我們只需要將columns_to_drop更改為列的列表,我們就可以刪除并且代碼將平穩運行!
columns_to_drop = config.columns.to_dropdatetime_column = config.columns.datetime.sentimentdropna_columns = config.columns.drop_naprocessor = Preprocess(columns_to_drop, datetime_column, dropna_columns)I can also create a pipeline that specifies steps to process and train the data! Once I have a pipeline, all I need to do is to use
我還可以創建一個管道來指定處理和訓練數據的步驟! 一旦有了管道,我要做的就是使用
pipline.fit_transform(data)to apply the same processing to both the train and test data.
對火車和測試數據進行相同的處理。
易于調試 (Easy to Debug)
With functions, it is easier to test whether that function produces the output we expect. We can quickly spot out where in the code we should change to produce the output we want
使用函數,可以更輕松地測試該函數是否產生我們期望的輸出。 我們可以快速找出應該在代碼中更改的位置以產生所需的輸出
def extract_date_hour_minute(string: str):'''Extract data hour and minute from datetime string'''try:return string[:16]except TypeError:return np.nandef test_extract_date_hour_minute():'''Test whether the function extract date, hour, and minute '''string = '2020-07-30T23:25:31.036+03:00'assert extract_date_hour_minute(string) == '2020-07-30T23:25'If all of the tests pass but there is still an error in running our code, we know the data is where we should look next.
如果所有測試都通過了,但是在運行我們的代碼時仍然存在錯誤,那么我們知道數據是我們下一步應該去的地方。
For example, after passing the test above, I still have a TypeError when running the script, which gives me the idea that my data has null values. I just need to take care of that to run the code smoothly.
例如,通過上述測試后,運行腳本時我仍然遇到TypeError,這使我想到了我的數據具有空值。 我只需要注意這一點即可順利運行代碼。
生產的理想選擇 (Ideal for Production)
We can use different functions in multiple scripts on top of something else like this
我們可以在類似這樣的其他東西的多個腳本中使用不同的功能
from preprocess import preprocess
from model import run_model
from predict import predictdef main(config):df = preprocess(config)df = run_model(config)df, df_scale, min_day, max_day, accuracy = predict(df, config)or to add a config file to control the values of the variables. This prevents us from wasting time tracking down a specific variable in the code just to change its value.
或添加配置文件以控制變量的值。 這樣可以避免我們浪費時間跟蹤代碼中的特定變量以更改其值。
columns:to_drop:#- keywords#- entities- code- error- warningsbinary_columns: - sentiment - Diffdatetime:time: Date sentiment: crawleddrop_na: - sentiment- usage- crawled- emotionto_predict: sentimentWe could also easily add tools to track the experiment such as MLFlow or tools to handle configuration such as Hydra.cc!
我們還可以很容易地添加工具來跟蹤實驗,如MLFlow或工具來處理配置,如Hydra.cc !
我不喜歡使用Jupyter Notebook的想法,直到我將自己推出舒適區 (I didn’t like the Idea of Using Jupyter Notebook until I Pushed myself out of my Comfort Zone)
I used to use Jupyter Notebook all the time. When some data scientists advise me to switch from Jupyter Notebook to script to prevent some problems listed above, I didn’t understand and felt resistant to do so. I didn’t like the uncertainty of not being able to see the outcome when I run the cell.
我曾經一直使用Jupyter Notebook。 當一些數據科學家建議我從Jupyter Notebook切換到腳本以防止上面列出的某些問題時,我并不理解,并且對此感到抵觸。 我不喜歡在運行單元時無法看到結果的不確定性。
But the disadvantage of Jupyter Notebook grew as I started my first real data science project in my new company so I decided to push myself out of my comfort zone and experiment with scripts.
但是Jupyter Notebook的劣勢隨著我在新公司中開始第一個真實數據科學項目而變得越來越嚴重,因此我決定將自己從舒適的領域中脫身出來,并嘗試使用腳本。
In the beginning, I felt uncomfortable but started to notice the benefits of using scripts. I started to feel more organized when my code is organized into different functions, classes, and into multiple scripts with each script serving different purposes such as preprocessing, training, and testing.
一開始,我感到不舒服,但是開始注意到使用腳本的好處。 當我的代碼被組織成不同的函數,類和多個腳本,并且每個腳本具有不同的目的(例如預處理,培訓和測試)時,我開始變得井井有條。
所以,您是否建議我停止使用Jupyter Notebook? (So are you Suggesting me to Stop Using Jupyter Notebook?)
Don’t get me wrong. I still use Jupyter Notebook if my code is small and if I don’t plan to put my code into production. I use Jupyter Notebook when I want to explore and visualize the data. I also use it to explain how to use some python libraries. For example, I write use mostly Jupyter Notebooks in this repository as the medium to explain the code mentioned in all of my articles.
不要誤會我的意思。 如果我的代碼很小并且我不打算將代碼投入生產,我仍然會使用Jupyter Notebook。 當我想瀏覽和可視化數據時,我使用Jupyter Notebook。 我也用它來解釋如何使用一些python庫。 例如,我在這個存儲庫中主要使用Jupyter Notebooks作為媒介來解釋我所有文章中提到的代碼。
If you don’t feel comfortable with coding everything in scripts, you could use both scripts and Jupyter Notebook for different purposes. For example, you could create classes and functions in scripts then import them in the notebook so that the notebook is less messy.
如果您不滿意用腳本編寫所有代碼,則可以將腳本和Jupyter Notebook都用于不同的目的。 例如,您可以在腳本中創建類和函數,然后將其導入筆記本中,以使筆記本不那么混亂。
Another alternative is to turn the notebook into the script after writing the notebook. I personally don't prefer this approach because it often takes me longer to organize the code in my notebook such as put them into functions and classes and write test functions.
另一種選擇是在編寫筆記本后將筆記本變成腳本。 我個人不喜歡這種方法,因為通常需要我花費更長的時間在筆記本中組織代碼,例如將它們放入函數和類中以及編寫測試函數。
I find writing a small function then writing a small test function is faster and safer. If I happen to want to speeds up my code with the new Python library, I could use the test function I already wrote to make sure it still works as I expected.
我發現編寫一個小的函數然后編寫一個小的測試函數會更快,更安全。 如果我碰巧想用新的Python庫加速代碼,則可以使用已經編寫的測試函數來確保它仍然可以按預期工作。
With that being said, I believe there are more ways to solve the disadvantage of Jupyter Notebook than what I mentioned here such as how Netflix uses put the notebook into production and schedule the notebook to run at a certain time.
話雖這么說,我相信比我在這里提到的解決Jupyter Notebook的缺點還有更多的方法,例如Netflix如何使用Netflix將筆記本電腦投入生產并安排筆記本電腦在特定時間運行 。
結論 (Conclusion)
Everybody has their own way to make their workflow more efficient and to me, it is to leverage the utility of scripts. If you have just switched from Jupyter Notebook to script, it might not be intuitive to write code in scripts, but trust me, you will get used to using scripts eventually.
每個人都有自己的方法來提高工作流程的效率,對我來說,這是利用腳本的實用程序。 如果您剛剛從Jupyter Notebook切換到腳本,那么用腳本編寫代碼可能并不直觀,但是請相信我,您最終將習慣于使用腳本。
Once that happens, you will start to realize many benefits of the scripts over the messy Jupyter Notebook and want to write most of your code in scripts.
一旦發生這種情況,相對于凌亂的Jupyter Notebook,您將開始意識到腳本的許多優點,并希望將大多數代碼編寫在腳本中。
If you don’t feel comfortable with the big change, start small.
如果您對較大的變化不滿意,請從小處著手。
Big changes start with small steps
大變化始于小步
I like to write about basic data science concepts and play with different algorithms and data science tools. You could connect with me on LinkedIn and Twitter.
我喜歡寫有關基本數據科學概念的文章,并喜歡使用不同的算法和數據科學工具。 您可以在LinkedIn和Twitter上與我聯系。
Star this repo if you want to check out the codes for all of the articles I have written. Follow me on Medium to stay informed with my latest data science articles like these
如果您想查看我編寫的所有文章的代碼,請給此回購加注星號。 在Medium上關注我,以了解有關這些最新數據科學文章的最新信息
翻譯自: https://towardsdatascience.com/5-reasons-why-you-should-switch-from-jupyter-notebook-to-scripts-cb3535ba9c95
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390563.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390563.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390563.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

leetcode 1833. 雪糕的最大數量

MVC架構 -- 初學試水選課管理系統

rest api 示例2_REST API教程– REST Client,REST Service和API調用通過代碼示例進行了解釋

win10子系統linux編譯ffmpeg

ip登錄打印機怎么打印_不要打印,登錄。

leetcode 451. 根據字符出現頻率排序

Spring-Security 自定義Filter完成驗證碼校驗

如何使用Ionic和Firebase在短短三天內創建冠狀病毒跟蹤器應用程序
_封裝思想——this關鍵字)
二、Java面向對象(7)_封裝思想——this關鍵字

機器學習模型 非線性模型_調試機器學習模型的終極指南

leetcode 645. 錯誤的集合

Linux環境變量總結
通過示例進行解釋)
目錄指南中的Python列表文件-listdir VS system(“ ls”)通過示例進行解釋

Java多線程并發學習-進階大綱

大數據定律與中心極限定理_為什么中心極限定理對數據科學家很重要?

useEffect語法講解

leetcode 726. 原子的數量

web相關基礎知識1

JavaScript循環:標簽語句,繼續語句和中斷語句說明
