熊貓數據集
Tips and Tricks for Data Science
數據科學技巧與竅門
Pandas is a powerful and easy-to-use software library written in the Python programming language, and is used for data manipulation and analysis.
Pandas是使用Python編程語言編寫的功能強大且易于使用的軟件庫,可用于數據處理和分析。
Installing pandas: https://pypi.org/project/pandas/
安裝熊貓: https : //pypi.org/project/pandas/
pip install pandas
pip install pandas
什么是Pandas DataFrame? (What is a Pandas DataFrame?)
A pandas DataFrame is a two dimensional data structure which stores data in a tabular form. Every row and column are labeled and can hold data of any type.
pandas DataFrame是二維數據結構,以表格形式存儲數據。 每行和每列都有標簽,可以保存任何類型的數據。
Here is an example:
這是一個例子:
1.創建一個熊貓DataFrame (1. Creating a pandas DataFrame)
The pandas.DataFrame constructor:
pandas.DataFrame構造函數:
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False
data This parameter serves as the input to make a DataFrame, which could be a NumPy ndarray, iterable, dict or another DataFrame. An ndarray is a multidimensional container of items of the same type and size. An iterable is any Python object capable of returning its members one at a time, permitting to be iterated over in a for-loop. Some examples for iterables are lists, tuples and sets. Dict here can refer to pandas Series, arrays, constants or list-like objects.
data此參數用作制作DataFrame的輸入,該DataFrame可以是NumPy ndarray,可迭代,dict或另一個DataFrame 。 ndarray是具有相同類型和大小的項目的多維容器。 可迭代對象是能夠一次返回其成員并允許在for循環中對其進行迭代的任何Python對象。 可迭代的一些示例是列表,元組和集合。 這里的Dict可以引用pandas系列,數組,常量或類似列表的對象。
indexThis parameter could have an Index or an array-like data type and serves as the index for the row labels in the resulting DataFrame. If no indexing information is provided, this parameter will default to RangeIndex.
index此參數可以具有Index或類似數組的數據類型,并用作結果DataFrame中行標簽的索引。 如果沒有提供索引信息,則此參數將默認為RangeIndex 。
columnsThis parameter could have an Index or an array-like data type and serves as the index for the column labels in the resulting DataFrame. If no indexing information is provided, this parameter will default to RangeIndex.
columns此參數可以具有Index或類似數組的數據類型,并用作結果DataFrame中列標簽的索引。 如果沒有提供索引信息,則此參數將默認為RangeIndex 。
dtypeEach column in the DataFrame can only have a single data type. This parameter is used to force a certain data type. By default, datatype is inferred from data.
DTYPE在數據幀的每一列只能有一種數據類型。 此參數用于強制某種數據類型。 默認情況下,從數據推斷出數據類型。
copyWhen this parameter is set to True, and the input data is a DataFrame or a 2D ndarray, data is copied into the resulting DataFrame. By default, copy is set to False.
復制如果將此參數設置為True,并且輸入數據是DataFrame或2D ndarray,則將數據復制到結果DataFrame中。 默認情況下,復制設置為False。
從Python字典創建Pandas DataFrame (Creating a Pandas DataFrame from a Python Dictionary)
import pandas as pd
import pandas as pd
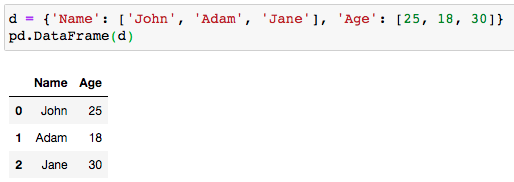
d = {'Name' : ['John', 'Adam', 'Jane'], 'Age' : [25, 18, 30]}pd.DataFrame(d)
d = {'Name' : ['John', 'Adam', 'Jane'], 'Age' : [25, 18, 30]}pd.DataFrame(d)
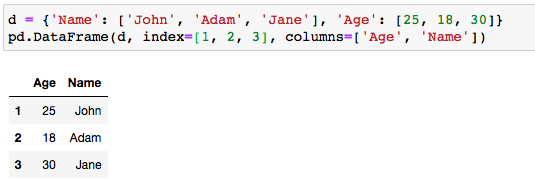
The index parameter can be used to change the default row index and the columns parameter can be used to change the order of the keys:
index參數可用于更改默認行索引, columns參數可用于更改鍵的順序:
d = {'Name' : ['John', 'Adam', 'Jane'], 'Age' : [25, 18, 30]}pd.DataFrame(d, index=[10, 20, 30], columns=['First Name', 'Current Age'])
d = {'Name' : ['John', 'Adam', 'Jane'], 'Age' : [25, 18, 30]}pd.DataFrame(d, index=[10, 20, 30], columns=['First Name', 'Current Age'])
從列表創建Pandas DataFrame: (Creating a Pandas DataFrame from a list:)
l = [['John', 25], ['Adam', 18], ['Jane', 30]]pd.DataFrame(l, columns=['Name', 'Age'])
l = [['John', 25], ['Adam', 18], ['Jane', 30]]pd.DataFrame(l, columns=['Name', 'Age'])

從文件創建Pandas DataFrame (Creating a Pandas DataFrame from a File)
For any Data Science process, the dataset is commonly stored in files having formats like CSV (Comma Separated Values). Pandas allows storing data along with their labels from a CSV file using the method pandas.read_csv().
對于任何數據科學過程,數據集通常存儲在具有CSV(逗號分隔值)之類的格式的文件中。 Pandas允許使用pandas.read_csv()方法將數據及其標簽中的數據與CSV文件一起存儲。


2.從Pandas DataFrame中選擇行和列 (2. Selecting Rows and Columns from a Pandas DataFrame)
從Pandas DataFrame中選擇列 (Selecting Columns from a Pandas DataFrame)
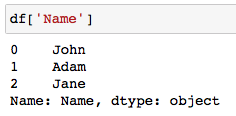
Columns can be selected using their column names.
可以使用列名稱選擇列。
df[column_1, column_2])
df[ column_1 , column_2 ])
從Pandas DataFrame中選擇行 (Selecting Rows from a Pandas DataFrame)
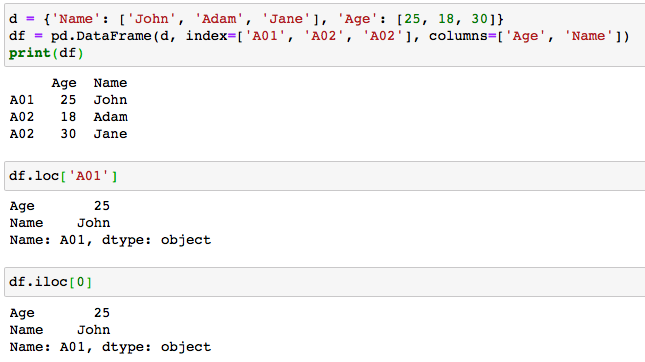
Pandas provides 2 attributes for selecting rows from a DataFrame: loc and iloc
Pandas提供了2個用于從DataFrame中選擇行的屬性: loc和iloc
loc is label-based, which means that the row label has to be specified and iloc is integer-based which means that the integer index has to be specified.
loc是基于標簽的,這意味著必須指定行標簽,而iloc是基于整數的,這意味著必須指定整數索引。
3.在Pandas DataFrame中插入行和列 (3. Inserting Rows and Columns to a Pandas DataFrame)
在Pandas DataFrame中插入行 (Inserting Rows to a Pandas DataFrame)
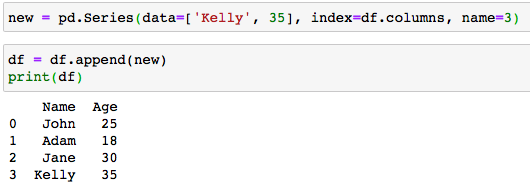
One method of inserting a row into a DataFrame is to create a pandas.Series() object and insert it at the end of the DataFrame using the pandas.DataFrame.append()method. The column indices of the DataFrame serve as the index attribute for the Series object.
將行插入DataFrame的一種方法是創建pandas.Series() 對象,然后使用pandas.DataFrame.append()方法將其插入DataFrame的pandas.DataFrame.append() 。 DataFrame的列索引用作Series對象的索引屬性。
將列插入Pandas DataFrame (Inserting Columns to a Pandas DataFrame)
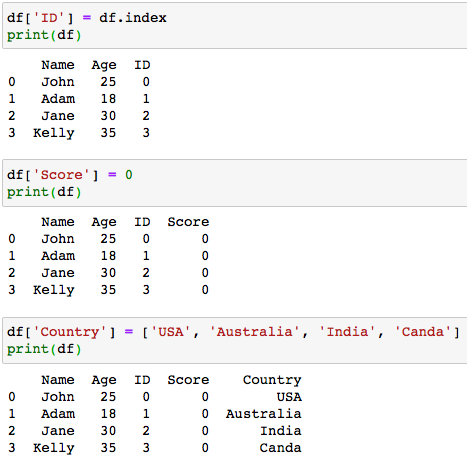
One easy method of adding a column to a DataFrame is by just referring to the new column and assigning values.
將列添加到DataFrame的一種簡單方法是僅引用新列并分配值。
4.從Pandas DataFrame刪除行和列 (4. Deleting Rows and Columns from a Pandas DataFrame)
從Pandas DataFrame刪除行 (Deleting Rows from a Pandas DataFrame)
A row can be deleted using the method pandas.DataFrame.drop() with it’s row label.
可以使用帶有行標簽的pandas.DataFrame.drop()方法刪除一行。
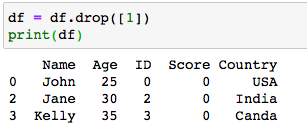
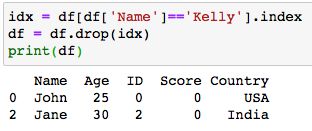
To delete a row based on a column, the index of the row is obtained using the DataFrame.index attribute and then the row with the index is deleted using the pandas.DataFrame.drop() method.
要刪除基于列的行,請使用DataFrame.index屬性獲取該行的索引,然后使用pandas.DataFrame.drop()方法刪除具有索引的行。
從Pandas DataFrame刪除列 (Deleting Columns from a Pandas DataFrame)
A column can be deleted from a DataFrame based on its label as well as its position in the DataFrame using the method pandas.DataFrame.drop().
可以使用pandas.DataFrame.drop()方法根據列的標簽及其在DataFrame中的位置從DataFrame中刪除列。
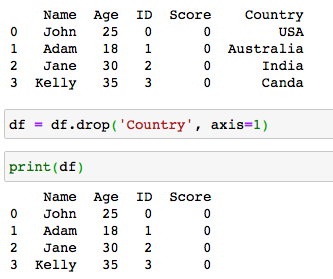
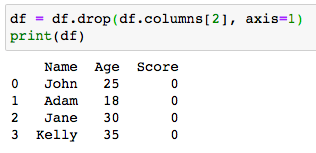
The axis argument is set to 1 when dropping columns, and 0 when dropping rows.
刪除列時, axis參數設置為1;刪除行時, axis參數設置為0。
5.對Pandas DataFrame排序 (5. Sorting a Pandas DataFrame)
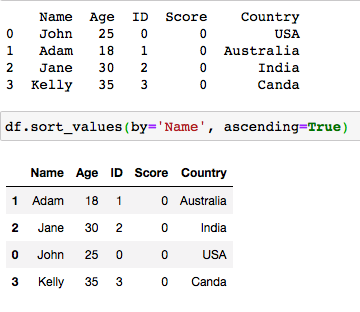
A Pandas DataFrame can be sorted using the pandas.DataFrame.sort_values() method. The by parameter for the method serves as the label of the column to sort by and ascending is set to True for sorting in ascending order and to False for sorting in descending order.
可以使用pandas.DataFrame.sort_values()方法對Pandas DataFrame進行排序。 該方法的by參數用作要按其進行排序的列的標簽,并且升序設置為True(以升序排序),設置為False(以降序排序)。

https://www.datacamp.com/community/tutorials/pandas-tutorial-dataframe-pythonhttps://realpython.com/pandas-dataframe/#creating-a-pandas-dataframehttps://www.tutorialspoint.com/python_pandas/python_pandas_dataframe.htmhttps://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
https://www.datacamp.com/community/tutorials/pandas-tutorial-dataframe-python https://realpython.com/pandas-dataframe/#creating-a-pandas-dataframe https://www.tutorialspoint.com/python_pandas/python_pandas_dataframe.htm https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
翻譯自: https://medium.com/ml-course-microsoft-udacity/5-fundamental-operations-on-a-pandas-dataframe-93b4384dff9d
熊貓數據集
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389646.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389646.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389646.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
 譯文五、六、七)
圖嵌入綜述 (arxiv 1709.07604) 譯文五、六、七


1971. Find if Path Exists in Graph

移動磁盤文件或目錄損壞且無法讀取資料如何找回

python 平滑時間序列_時間序列平滑以實現更好的聚類

基于SmartQQ協議的QQ自動回復機器人-1

1725. 可以形成最大正方形的矩形數目

幫助學生改善學習方法_學生應該如何花費時間改善自己的幸福

Spring Boot 靜態資源訪問原理解析

深挖“窄帶高清”的實現原理

學習總結5 - bootstrap學習記錄1__安裝

519. 隨機翻轉矩陣

模型的搜索和優化方法綜述:

Redis 服務安裝

熊貓數據集_對熊貓數據框使用邏輯比較


ansbile--playbook劇本案例

5938. 找出數組排序后的目標下標

決策樹之前要不要處理缺失值_不要使用這樣的決策樹
