(這個我也沒有怎么懂,為了防止以后能用上,還是記錄下來)
譜聚類
注意:譜聚類核心聚類算法還是K-means 算法進行聚類~
譜聚類的實現過程:
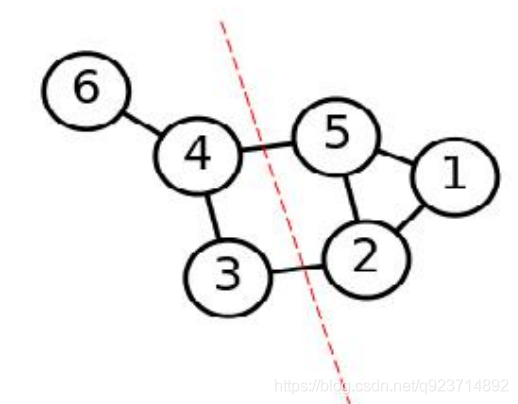
1.根據數據構造一個 圖結構(Graph) ,Graph 的每一個節點對應一個數據點,將相 似的點連接起來,并且邊的權重用于表示數據之間的相似度。把這個 Graph 用鄰接矩陣的形式表示出來,記為 W 。
2. 把 W 的每一列元素加起來得到 N 個數,把它們放在對角線上(其他地方都是零), 組成一個 N * N的矩陣,記為 D 。并令 L = D-W 。
3. 求出 L 的前 k 個特征值,以及對應的特征向量。
4. 把這 k 個特征(列)向量排列在一起組成一個 N * k 的矩陣,將其中每一行看作 k 維空間中的一個向量,并使用 K-means 算法進行聚類。聚類的結果中每一行所屬的類 別就是原來 Graph 中的節點亦即最初的N 個數據點分別所屬的類別。
簡單抽象譜聚類過程實現步驟:
簡單抽象譜聚類過程,主要有兩步:
1.構圖,將采樣點數據構造成一張網圖。
2.切圖,即將第一步構造出來的按照一定的切邊準則,切分成不同的圖,而不同的子圖,即我們對 應的聚類結果。
代碼實習:
總體感覺上是:先降維,然后再用K-means 算法聚類
import matplotlib.pyplot as plt
import numpy as np
from numpy import linalg as LA
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics.pairwise import rbf_kernel
from sklearn.preprocessing import normalizedef similarity_function(points):"""相似性函數,利用徑向基核函數計算相似性矩陣,對角線元素置為0對角線元素為什么要置為0我也不清楚,但是論文里是這么說的:param points::return:"""res = rbf_kernel(points)for i in range(len(res)):res[i, i] = 0return resdef spectral_clustering(points, k):"""譜聚類:param points: 樣本點:param k: 聚類個數:return: 聚類結果"""W = similarity_function(points)# 度矩陣D可以從相似度矩陣W得到,這里計算的是D^(-1/2)# D = np.diag(np.sum(W, axis=1))# Dn = np.sqrt(LA.inv(D))# 本來應該像上面那樣寫,我做了點數學變換,寫成了下面一行Dn = np.diag(np.power(np.sum(W, axis=1), -0.5))# 拉普拉斯矩陣:L=Dn*(D-W)*Dn=I-Dn*W*Dn(降維)# 也是做了數學變換的,簡寫為下面一行L = np.eye(len(points)) - np.dot(np.dot(Dn, W), Dn)eigvals, eigvecs = LA.eig(L)# 前k小的特征值對應的索引,argsort函數indices = np.argsort(eigvals)[:k]# 取出前k小的特征值對應的特征向量,并進行正則化k_smallest_eigenvectors = normalize(eigvecs[:, indices])# 利用KMeans進行聚類return KMeans(n_clusters=k).fit_predict(k_smallest_eigenvectors)'''
sklearn中的make_blobs()函數---為聚類產生數據集n_samples是待生成的樣本的總數。n_features是每個樣本的特征數。centers表示類別數。cluster_std表示每個類別的方差,例如我們希望生成2類數據,其中一類比另一類具有更大的方差,可以將cluster_std設置為[1.0,3.0]。
'''X, y = make_blobs(n_samples=100, n_features=2, centers=2)
labels = spectral_clustering(X, 3)# 畫圖
plt.style.use('ggplot')
# 原數據
fig, (ax0, ax1) = plt.subplots(ncols=2)
ax0.scatter(X[:, 0], X[:, 1], c=y)
ax0.set_title('raw data')
# 譜聚類結果
ax1.scatter(X[:, 0], X[:, 1], c=labels)
ax1.set_title('Spectral Clustering')
plt.show()
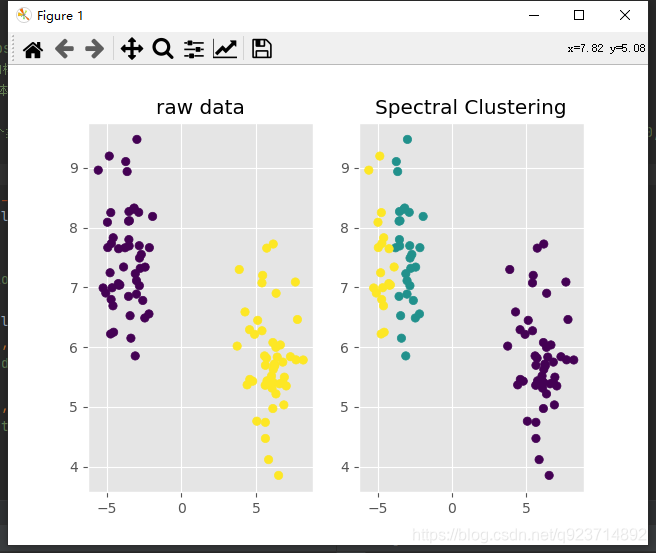
實現結果:



_主成分分析技巧)




![bzoj1095 [ZJOI2007]Hide 捉迷藏](http://pic.xiahunao.cn/bzoj1095 [ZJOI2007]Hide 捉迷藏)




思想及實現)




)
