SIFT概念:
Sift(尺度不變特征變換),全稱是Scale Invariant Feature Transform Sift提取圖像的局部特征,在尺度空間尋找極值點,并提取出其位置、尺度、方向信息。
Sfit的應用范圍包括 物體辨別、機器人地圖感知與導航、影像拼接、3D模型建立、手勢識別、影像追蹤等。
Sift特征的特點:
1.對旋轉、尺度縮放、亮度變化保持不變性,對視角變化、噪聲等也存在一定程度的穩定性;
2.獨特性,信息量豐富,適用于在海量特征數據中進行快速,準確的匹配;
3.多量性,即使少數幾個物體也可以產生大量的Sfit特征向量;
4.可擴展性,可以很方便的與其他形式的特征向量進行聯合;
Sfit算法的實質:
Sfit算法的實質是在不同的尺度空間上查找關鍵點(特征點),計算關鍵點的大小、方向、尺度信息,利 用這些信息組成關鍵點對特征點進行描述的問題。Sift所查找的關鍵點都是一些十分突出,不會因光照, 仿射變換和噪聲等因素而變換的“穩定”特征點,如角點、邊緣點、暗區的亮點以及亮區的暗點等。 匹配的過程就是對比這些特征點的過程:
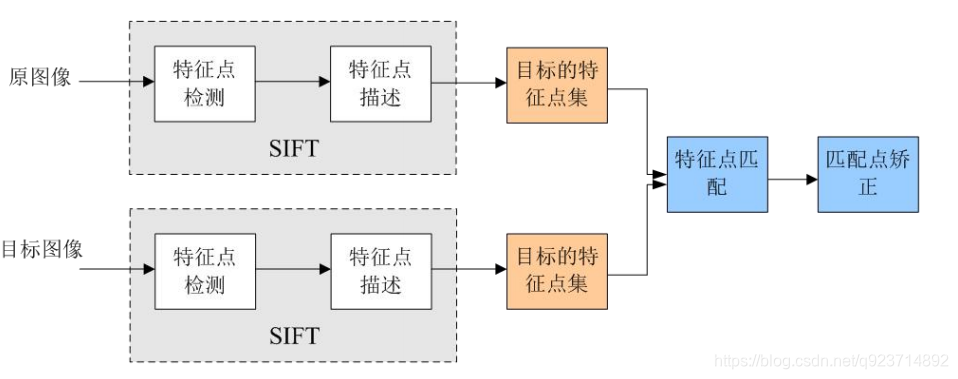
SIFT特征提取和匹配具體步驟:
1.生成高斯差分金字塔(DOG金字塔),尺度空間構建
2.空間極值點檢測(關鍵點的初步查探)
3. 穩定關鍵點的精確定位
4. 穩定關鍵點方向信息分配
5. 關鍵點描述
6. 特征點匹配
1. 生成高斯差分金字塔(DOG金字塔),尺度空間構建:
尺度空間:
尺度空間,在攝像頭中,計算機無法分辨一個景物的尺度信息。而人眼不同,除了人大腦里已經對物體 有了基本的概念(例如正常人在十幾米外看到蘋果,和在近距離看到蘋果,都能認出是蘋果)以外,人 眼在距離物體近時,能夠獲得物體足夠多的特性,在距離物體遠時,能夠忽略細節,例如,近距離看一 個人臉能看到毛孔,距離遠了看不到毛孔等等。 在圖片信息當中,分辨率都是固定的,要想得到類似人眼的效果,就要把圖片弄成不同的分辨率,制作 成圖像金字塔來模擬人眼的功能,從而在其他圖片中進行特征識別時,能夠像人眼睛一樣,即使要識別 的物體尺寸變大或者變小,也能夠識別出來。
尺度空間即試圖在圖像領域中模擬人眼觀察物體的概念與方法。例如:觀察一顆樹,關鍵在于我們想要 觀察是樹葉子還是整棵樹:如果是一整棵樹(相當于大尺度情況下觀察),那么就應該去除圖像的細節部分。 如果是樹葉(小尺度情況下觀察),那么就該觀察局部細節特征。
圖像金字塔
通俗地說,尺度空間,就相當于一個圖片需要獲得多少分辨率的量級。如果把一個圖片從原始分辨率 不停的對其分辨率進行減少,然后將這些圖片摞在一起,可以看成一個四棱錐的樣式,這個東西就叫 做圖像金字塔。
圖像金字塔是一種以多分辨率來解釋圖像的結構,通過對原始圖像進行多尺度像素采樣的方式,生成N 個不同分辨率的圖像。把具有最高級別分辨率的圖像放在底部,以金字塔形狀排列,往上是一系列像 素(尺寸)逐漸降低的圖像,一直到金字塔的頂部只包含一個像素點的圖像,這就構成了傳統意義上 的圖像金字塔。

獲得圖像金字塔一般包括二個步驟:
1.利用低通濾波器平滑圖像 (高斯濾波)
2.對平滑圖像進行抽樣(采樣) 有兩種采樣方式——上采樣(分辨率逐級升高)和下采樣(分辨率逐級降低)
高斯金字塔
主要思想是通過對原始圖像進行尺度變換,獲得圖像多尺度下的尺度空間表示序列,對這些序列進 行尺度空間主輪廓的提取,并以該主輪廓作為一種特征向量,實現邊緣、角點檢測不同分辨率上的 關鍵點提取等。 各尺度下圖像的模糊度逐漸變大,能夠模擬人在距離目標由近到遠時目標物體在視網膜上的形成過 程。尺度空間構建的基礎是DOG金字塔,DOG金字塔構建的基礎是高斯金字塔。
高斯金字塔式在Sift算子中提出來的概念,首先高斯金字塔并不是一個金字塔,而是有很多組(Octave) 金字塔構成,并且每組金字塔都包含若干層(Interval)。
高斯金字塔構建過程:
1.先將原圖像擴大一倍之后作為高斯金字塔的第1組第1層,將第1組第1層圖像經高斯卷積(其實就 是高斯平滑或稱高斯濾波)之后作為第1組金字塔的第2層。
2. 將σ乘以一個比例系數k,得到一個新的平滑因子σ=kσ,用它來平滑第1組第2層圖像,結果圖像作為 第3層。
3. 如此這般重復,最后得到L層圖像,在同一組中,每一層圖像的尺寸都是一樣的,只是平滑系數不 一樣。它們對應的平滑系數分別為:0,σ,kσ,k2σ,k3σ……k^(L-2)σ。
4. 將第1組倒數第三層圖像作比例因子為2的降采樣,得到的圖像作為第2組的第1層,然后對第2組的 第1層圖像做平滑因子為σ的高斯平滑,得到第2組的第2層,就像步驟2中一樣,如此得到第2組的L 層圖像,同組內它們的尺寸是一樣的,對應的平滑系數分別為:0,σ,kσ,k2σ,k3σ……k^(L-2)σ。 但是在尺寸方面第2組是第1組圖像的一半。
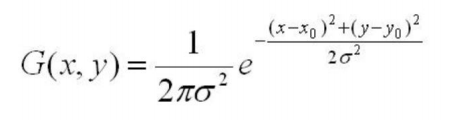 (高斯公式)
(高斯公式)
反復執行,就可以得到一共O組,每組L層,共計OL個圖像,這些圖像一起就構成了高斯金字塔:
注意:
? 在同一組內,不同層圖像的尺寸是一樣的,后一層圖像的 高斯平滑因子σ是前一層圖像平滑因子的k倍;
? 在不同組內,后一組第一個圖像是前一組倒數第三個圖像 的二分之一采樣,圖像大小是前一組的一半;
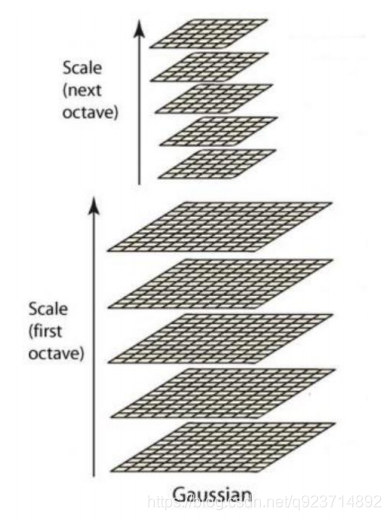

從上圖的實現結果可以發現:圖像越往金字塔上層,越模糊
構建尺度空間
在高斯金字塔中一共生成O組L層不同尺度的圖像,這兩個量合起來(O,L)就構成了高斯金字塔的尺 度空間,也就是說以高斯金字塔的組O作為二維坐標系的一個坐標,不同層L作為另一個坐標,則給定 的一組坐標(O,L)就可以唯一確定高斯金字塔中的一幅圖像。 尺度空間的形象表述:
? 圖中尺度空間中k前的系數n表示的是第一組 圖像尺寸是當前組圖像尺寸的n倍。

SIFT算法在構建尺度空間時候采取高斯核函數進行濾波,使原始圖像保存最多的細節特征,經過高斯濾波 后細節特征逐漸減少來模擬大尺度情況下的特征表示。 利用高斯核函數進行濾波的主要原因有兩個:
(1)高斯核函數是唯一的尺度不變核函數。
(2)DoG核函數可以近似為LoG函數,這樣可以使特征提取更加簡單。 其實尺度空間圖像生成就是當前圖像與不同尺度核參數σ進行卷積運算后產生的圖像。 L(x, y, σ) ,定義為原始圖像I(x, y)與一個可變尺度的2維高斯函數G(x, y, σ) 卷積運算。
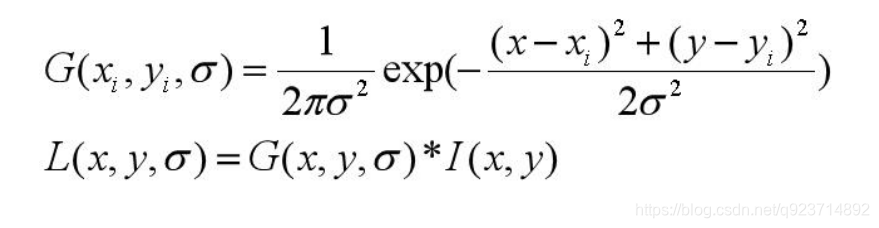
尺度空間構建的基礎是DOG金字塔,DOG金字塔構建的基礎是高斯金字塔。
差分金字塔,DOG(Difference of Gaussian)金字塔是在高斯金字塔的基礎上構建起來的, 其實生成高斯金字塔的目的就是為了構建DOG金字塔。 DOG金字塔的第1組第1層是由高斯金字塔的第1組第2層減第1組第1層得到的。
以此類推, 逐組逐層生成每一個差分圖像,所有差分圖像構成差分金字塔。概括為DOG金字塔的第o組 第l層圖像是由高斯金字塔的第o組第l+1層減第o組第l層得到的。
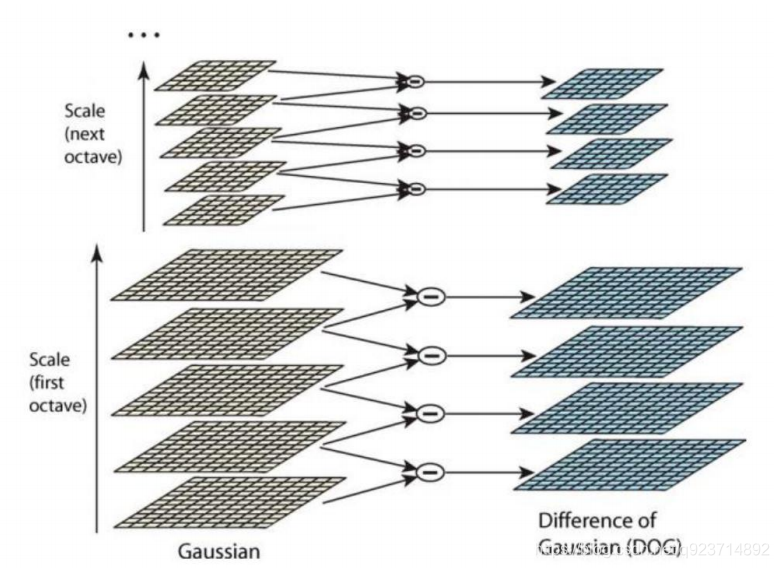
但是實際結果:
原因就是差值很小,肉眼很難看見。
歸一化之后:

2.空間極值點檢測(關鍵點的初步查探)
特征點是由DOG空間的局部極值點組成的。為了尋找DoG函數的極值點,每一個像素點要和它所有的 相鄰點比較,看其是否比它的圖像域和尺度域的相鄰點大或者小。、 如下圖,中間的檢測點和它同尺度的8個相鄰點和上下相鄰尺度對應的9×2個點共26個點比較,以確保 在尺度空間和二維圖像空間都檢測到極值點。

注意,局部極值點都是在同一個組當中進行的,所以肯定有這樣的問題,某一組當中的第一個圖和 最后一個圖層沒有前一張圖和下一張圖,那該怎么計算? 解決辦法是,在用高斯模糊,在高斯金字塔多“模糊”出三張來湊數,所以在DOG中多出兩張。
高斯金字塔的k值計算:
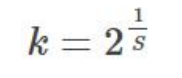
s:每組圖像中檢測s個尺度的極值點。
(實際計算時,s通常在3到5之間) Sift算法中生成高斯金字塔的規則(M,N為原始圖像的行數和列數):

+3就是因為在高斯金字塔要多“模糊”出三張來湊數
3. 穩定關鍵點的精確定位
DOG值對噪聲和邊緣比較敏感,所以在第2步的尺度空間中檢測到的局部極值點還要經過進一步的篩選,去除不穩定和錯誤檢測出的極值點。
利用閾值的方法來限制,在opencv中為contrastThreshold。
4. 穩定關鍵點方向信息分配
穩定的極值點是在不同尺度空間下提取的,這保證了關鍵點的尺度不變性。 為關鍵點分配方向信息所要解決的問題是使得關鍵點對圖像角度和旋轉具有不變性。
方法:
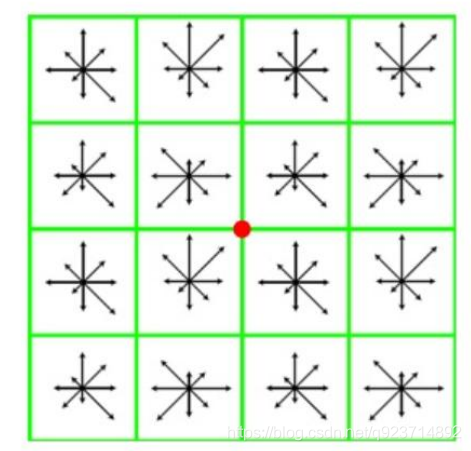
獲取關鍵點所在尺度空間的鄰域,然后計算該區域的梯度和方向,根據計算得到的結果創建 方向直方圖,直方圖的峰值為主方向的參數,其他高于主方向百分之80的方向被判定為輔助方向, 這樣設定對穩定性有很大幫助。
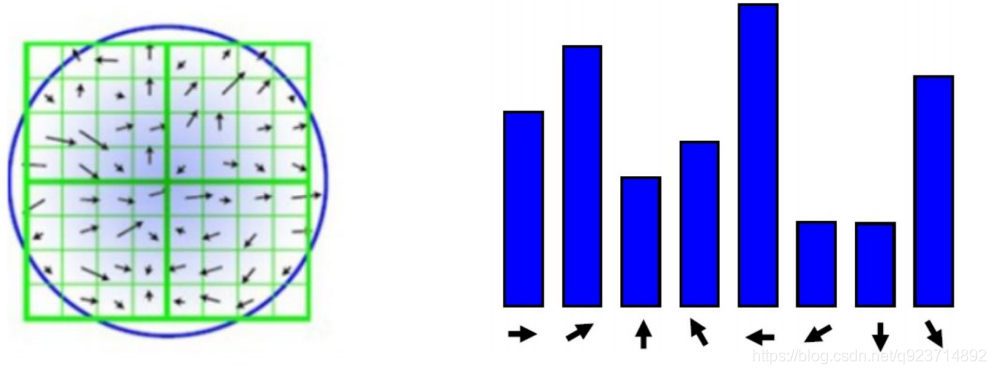
這里講解一下:每個小方格為一個像素點,通過求其周圍一圈8個像素所得的梯度找其最大的梯度,為主方向,達到主方向百分之80的及以上的方向被判定為輔助方向,例如藍色圖片中,←為最大峰值,↗和↘為輔助方向。
對于任一關鍵點,其梯度幅值表述為:
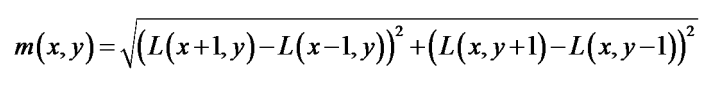
梯度方向為:
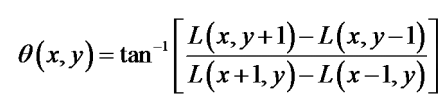
5. 關鍵點描述
對于每一個關鍵點,都擁有位置、尺度以及方向三個信息。所以具備平移、縮放、和旋轉不變性。 為每個關鍵點建立一個描述符,用一組向量將這個關鍵點描述出來,使其不隨各種變化而改變,比 如光照變化、視角變化等等描述子不但包含關鍵點,也包括關鍵點周圍對其有貢獻的鄰域點。
**描述的思路是:**對關鍵點周圍像素區域分塊,計算塊內梯度直方圖,生成具有獨特性的向量,這個 向量是該區域圖像信息的一種抽象表述。
如下圖,對于22塊,每塊的所有像素點的灰度做高斯加權,每塊最終取8個方向,即可以生成 228維度的向量,以這22*8維向量作為中心關鍵點的數學描述。

注意:Lowe實驗結果表明:對于每個關鍵點采用4×4×8=128維向量表征,綜合效果最優(不變性與獨特性)。
6. 特征點匹配
特征點的匹配是通過計算兩組特征點的128維的關鍵點的歐式距離實現的。 歐式距離越小,則相似度越高,當歐式距離小于設定的閾值時,可以判定為匹配成功。
具體步驟:
1、分別對模板圖(參考圖,reference image)和實時圖(觀測圖,observation image)建立關鍵點描述 子集合。目標的識別是通過兩點集內關鍵點描述子的比對來完成。具有128維的關鍵點描述子的相似性度 量采用歐式距離。
2、匹配可采取窮舉法完成。
代碼實現:
注意:(所以我也沒有運行出來=。=)

完成SIFT1-5步的實現代碼
import cv2
import numpy as npimg = cv2.imread("lenna.png")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)sift = cv2.xfeatures2d.SIFT_create()
keypoints, descriptor = sift.detectAndCompute(gray, None)# cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS對圖像的每個關鍵點都繪制了圓圈和方向。
img = cv2.drawKeypoints(image=img, outImage=img, keypoints=keypoints,flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS,color=(51, 163, 236))#img=cv2.drawKeypoints(gray,keypoints,img)cv2.imshow('sift_keypoints', img)
cv2.waitKey(0)
cv2.destroyAllWindows()因為我也運行不了,所以就不給結果展示了,理解代碼就好。
完成SIFT全部的實現代碼
import cv2
import numpy as np#畫圖函數部分
def drawMatchesKnn_cv2(img1_gray,kp1,img2_gray,kp2,goodMatch):h1, w1 = img1_gray.shape[:2]h2, w2 = img2_gray.shape[:2]vis = np.zeros((max(h1, h2), w1 + w2, 3), np.uint8)vis[:h1, :w1] = img1_grayvis[:h2, w1:w1 + w2] = img2_grayp1 = [kpp.queryIdx for kpp in goodMatch]p2 = [kpp.trainIdx for kpp in goodMatch]post1 = np.int32([kp1[pp].pt for pp in p1])post2 = np.int32([kp2[pp].pt for pp in p2]) + (w1, 0)for (x1, y1), (x2, y2) in zip(post1, post2):cv2.line(vis, (x1, y1), (x2, y2), (0,0,255))cv2.namedWindow("match",cv2.WINDOW_NORMAL)cv2.imshow("match", vis)#圖像輸入
img1_gray = cv2.imread("iphone1.png")
img2_gray = cv2.imread("iphone2.png")#SIFT特征計算
sift = cv2.SIFT()
#sift = cv2.xfeatures2d.SIFT_create()
#sift = cv2.SURF()kp1, des1 = sift.detectAndCompute(img1_gray, None)
kp2, des2 = sift.detectAndCompute(img2_gray, None)#BFMatcher解決匹配
bf = cv2.BFMatcher(cv2.NORM_L2)
matches = bf.knnMatch(des1, des2, k = 2)#閾值對比,小于閾值時才被認為是匹配
goodMatch = []
for m,n in matches:if m.distance < 0.50*n.distance:goodMatch.append(m)drawMatchesKnn_cv2(img1_gray,kp1,img2_gray,kp2,goodMatch[:20])cv2.waitKey(0)
cv2.destroyAllWindows()因為我也運行不了,所以就不給結果展示了,理解代碼就好。
_主成分分析技巧)




![bzoj1095 [ZJOI2007]Hide 捉迷藏](http://pic.xiahunao.cn/bzoj1095 [ZJOI2007]Hide 捉迷藏)




思想及實現)




)

和歸一化實現)

