圖像相似度比較哈希算法:
什么是哈希(Hash)?
? 散列函數(或散列算法,又稱哈希函數,英語:Hash Function)是一種從任何一種數據中創建小 的數字“指紋”的方法。散列函數把消息或數據壓縮成摘要,使得數據量變小,將數據的格式固定 下來。該函數將數據打亂混合,重新創建一個叫做散列值(hash values,hash codes,hash sums, 或hashes)的指紋。散列值通常用一個短的隨機字母和數字組成的字符串來代表。
? 通過哈希算法得到的任意長度的二進制值映射為較短的固定長度的二進制值,即哈希值。此外, 哈希值是一段數據唯一且極其緊湊的數值表示形式,如果通過哈希一段明文得到哈希值,哪怕只 更改該段明文中的任意一個字母,隨后得到的哈希值都將不同。
? 哈希算法是一個函數,能夠把幾乎所有的數字文件都轉換成一串由數字和字母構成的看似亂碼的 字符串。
哈希函數的特點
哈希函數作為一種加密函數,其擁有兩個最重要特點:
- 不可逆性。輸入信息得出輸出的那個看似亂碼的字符串(哈希值)非常容易,但是從輸出的字符 串反推出輸入的結果卻是卻非常非常難。
- 輸出值唯一性和不可預測性。只要輸入的信息有一點點區別,那么根據哈希算法得出來的輸出值 也相差甚遠。
哈希算法的種類
哈希算法是一類算法的總稱,共有三種:
- 均值哈希算法aHash
- 差值哈希算法dHash
- 感知哈希算法pHash
漢明距離
兩個整數之間的漢明距離指的是這兩個數字對應二進制位不同的位置的數目。

均值哈希算法
步驟:
- 縮放:圖片縮放為8*8,保留結構,除去細節。
- 灰度化:轉換為灰度圖。
- 求平均值:計算灰度圖所有像素的平均值。
- 比較:像素值大于平均值記作1,相反記作0,總共64位。
- 生成hash:將上述步驟生成的1和0按順序組合起來既是圖片的指紋(hash)。
- 對比指紋:將兩幅圖的指紋對比,計算漢明距離,即兩個64位的hash值有多少位是不一樣的,不 相同位數越少,圖片越相似。
差值哈希算法
差值哈希算法相較于均值哈希算法,前期和后期基本相同,只有中間比較hash有變化。
步驟:
- 縮放:圖片縮放為8*9,保留結構,除去細節。
- 灰度化:轉換為灰度圖。
- 求平均值:計算灰度圖所有像素的平均值。
- 比較:像素值大于后一個像素值記作1,相反記作0。本行不與下一行對比,每行9個像素, 八個差值,有8行,總共64位
- 生成hash:將上述步驟生成的1和0按順序組合起來既是圖片的指紋(hash)。
- 對比指紋:將兩幅圖的指紋對比,計算漢明距離,即兩個64位的hash值有多少位是不一樣 的,不相同位數越少,圖片越相似。
感知哈希算法
均值哈希算法過于嚴格,不夠精確,更適合搜索縮略圖,為了獲得更精確的結果可以選擇感知哈希 算法,它采用的是DCT(離散余弦變換)來降低頻率的方法。
步驟:
- 縮小圖片:32 * 32是一個較好的大小,這樣方便DCT計算
- 轉化為灰度圖:把縮放后的圖片轉化為灰度圖。
- 計算DCT:DCT把圖片分離成分率的集合
- 縮小DCT:DCT計算后的矩陣是32 * 32,保留左上角的8 * 8,這些代表圖片的最低頻率。
- 計算平均值:計算縮小DCT后的所有像素點的平均值。
- 進一步減小DCT:大于平均值記錄為1,反之記錄為0.
- 得到信息指紋:組合64個信息位,順序隨意保持一致性。
- 最后比對兩張圖片的指紋,獲得漢明距離即可。
代碼實現:均值哈希算法和差值哈希算法
import cv2
import numpy as np#均值哈希算法
def aHash(img):#縮放為8*8img=cv2.resize(img,(8,8),interpolation=cv2.INTER_CUBIC)#轉換為灰度圖gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#s為像素和初值為0,hash_str為hash值初值為''s=0hash_str=''#遍歷累加求像素和for i in range(8):for j in range(8):s=s+gray[i,j]#求平均灰度avg=s/64#灰度大于平均值為1相反為0生成圖片的hash值for i in range(8):for j in range(8):if gray[i,j]>avg:hash_str=hash_str+'1'else:hash_str=hash_str+'0' return hash_str#差值感知算法
def dHash(img):#縮放8*9img=cv2.resize(img,(9,8),interpolation=cv2.INTER_CUBIC)#轉換灰度圖gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)hash_str=''#每行前一個像素大于后一個像素為1,相反為0,生成哈希for i in range(8):for j in range(8):if gray[i,j]>gray[i,j+1]:hash_str=hash_str+'1'else:hash_str=hash_str+'0'return hash_str#Hash值對比
def cmpHash(hash1,hash2):n=0#hash長度不同則返回-1代表傳參出錯if len(hash1)!=len(hash2):return -1#遍歷判斷for i in range(len(hash1)):#不相等則n計數+1,n最終為相似度if hash1[i]!=hash2[i]:n=n+1return nimg1=cv2.imread('lenna.png')
img2=cv2.imread('lenna_noise.png')
hash1= aHash(img1)
hash2= aHash(img2)
print(hash1)
print(hash2)
n=cmpHash(hash1,hash2)
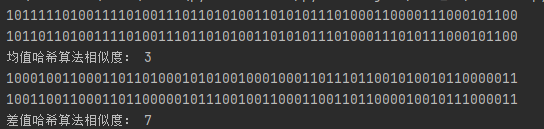
print('均值哈希算法相似度:',n)hash1= dHash(img1)
hash2= dHash(img2)
print(hash1)
print(hash2)
n=cmpHash(hash1,hash2)
print('差值哈希算法相似度:',n)運行結果:
輸入:

輸出:
圖像相似度比較哈希算法
三種算法的比較:
? aHash:均值哈希。速度比較快,但是常常不太精確。
? pHash:感知哈希。精確度較高,但是速度方面較差一些。
? dHash:差值哈希。精確度較高,且速度也非常快。
? 均值哈希本質上是對顏色的比較;
? 感知哈希由于做了 DCT 操作,本質上是對頻率的比較;
? 差值哈希本質上是基于漸變的感知哈希算法。

和歸一化實現)


 or ‘1type‘ as a synonym of type is deprecated解決辦法)
轉移方式及參數傳遞)













