數據不平衡處理
重點 (Top highlight)
One of the common problems in Machine Learning is handling the imbalanced data, in which there is a highly disproportionate in the target classes.
機器學習中的常見問題之一是處理不平衡的數據,其中目標類別的比例非常不均衡。
Hello world, this is my second blog for the Data Science community. In this blog, we are going to see how to deal with the multiclass imbalanced data problem.
大家好,這是我的第二本面向數據科學社區的博客 。 在此博客中,我們將看到如何處理多類不平衡數據問題。
什么是多類不平衡數據? (What is Multiclass Imbalanced Data?)
When the target classes (two or more) of classification problems are not equally distributed, then we call it Imbalanced data. If we failed to handle this problem then the model will become a disaster because modeling using class-imbalanced data is biased in favor of the majority class.
當分類問題的目標類別(兩個或多個)沒有平均分布時,我們稱其為不平衡數據。 如果我們不能解決這個問題,那么該模型將成為災難,因為使用類不平衡數據進行建模會偏向多數類。
There are different methods of handling imbalanced data, the most common methods are Oversampling and creating synthetic samples.
處理不平衡數據的方法多種多樣,最常見的方法是過采樣和創建合成樣本。
什么是SMOTE? (What is SMOTE?)
SMOTE is an oversampling technique that generates synthetic samples from the dataset which increases the predictive power for minority classes. Even though there is no loss of information but it has a few limitations.
SMOTE是一種過采樣技術,可從數據集中生成合成樣本,從而提高了少數群體的預測能力。 即使沒有信息丟失,它也有一些局限性。
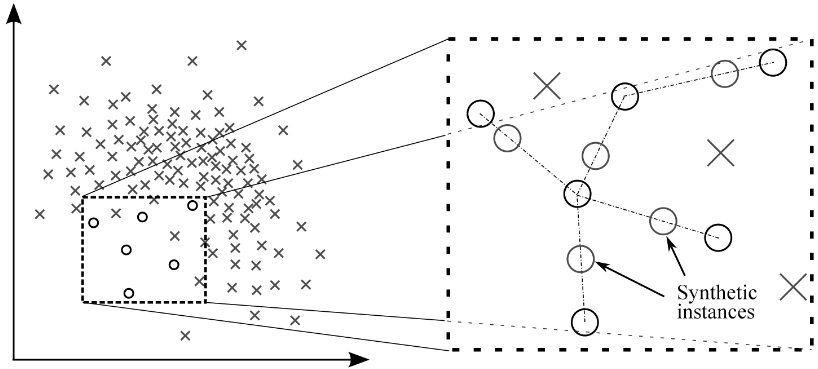
Limitations:
局限性:
- SMOTE is not very good for high dimensionality data SMOTE對于高維數據不是很好
- Overlapping of classes may happen and can introduce more noise to the data. 類的重疊可能會發生,并可能給數據帶來更多的噪音。
So, to skip this problem, we can assign weights for the class manually with the ‘class_weight’ parameter.
因此,要跳過此問題,我們可以使用' class_weight '參數為該類手動分配權重。
為什么要使用班級重量? (Why use Class weight?)
Class weights modify the loss function directly by giving a penalty to the classes with different weights. It means purposely increasing the power of the minority class and reducing the power of the majority class. Therefore, it gives better results than SMOTE.
類權重通過對具有不同權重的類進行懲罰來直接修改損失函數。 這意味著有目的地增加少數群體的權力,并減少多數階級的權力。 因此,它比SMOTE提供更好的結果。
概述: (Overview:)
I aim to keep this blog very simple. We have a few most preferred techniques for getting the weights for the data which worked for my Imbalanced learning problems.
我的目的是使這個博客非常簡單。 我們有一些最優選的技術來獲取對我的失衡學習問題有用的數據權重。
- Sklearn utils. Sklearn實用程序。
- Counts to Length. 數到長度。
- Smoothen Weights. 平滑權重。
- Sample Weight Strategy. 樣品重量策略。
1. Sklearn實用程序: (1. Sklearn utils:)
We can get class weights using sklearn to compute the class weight. By adding those weight to the minority classes while training the model, can help the performance while classifying the classes.
我們可以使用sklearn計算班級權重。 通過在訓練模型時將這些權重添加到少數類中,可以在對類進行分類的同時幫助提高性能。
from sklearn.utils import class_weightclass_weight = class_weight.compute_class_weight('balanced,
np.unique(target_Y),
target_Y)model = LogisticRegression(class_weight = class_weight)
model.fit(X,target_Y)# ['balanced', 'calculated balanced', 'normalized'] are hyperpaameters whic we can play with.We have a class_weight parameter for almost all the classification algorithms from Logistic regression to Catboost. But XGboost has scale_pos_weight for binary classification and sample_weights (refer 4) for both binary and multiclass problems.
對于從Logistic回歸到Catboost的幾乎所有分類算法,我們都有一個class_weight參數。 但是XGboost具有用于二進制分類的scale_pos_weight和用于二進制和多類問題的sample_weights(請參閱4)。
2.數長比: (2. Counts to Length Ratio:)
Very simple and straightforward! Dividing the no. of counts of each class with the no. of rows. Then
非常簡單明了! 除數 每個班級的人數 行。 然后
weights = df[target_Y].value_counts()/len(df)
model = LGBMClassifier(class_weight = weights)
model.fit(X,target_Y)3.平滑權重技術: (3. Smoothen Weights Technique:)
This is one of the preferable methods of choosing weights.
這是選擇權重的首選方法之一。
labels_dict is the dictionary object contains counts of each class.
labels_dict是字典對象,包含每個類的計數。
The log function smooths the weights for the imbalanced class.
對數函數可平滑不平衡類的權重。
def class_weight(labels_dict,mu=0.15):
total = np.sum(labels_dict.values())
keys = labels_dict.keys()
weight = dict()for i in keys:
score = np.log(mu*total/float(labels_dict[i]))
weight[i] = score if score > 1 else 1return weight# random labels_dict
labels_dict = weights = class_weight(labels_dict)model = RandomForestClassifier(class_weight = weights)
model.fit(X,target_Y)4.樣本權重策略: (4. Sample Weight Strategy:)
This below function is different from the class_weight parameter which is used to get sample weights for the XGboost algorithm. It returns different weights for each training sample.
下面的函數不同于用于獲取XGboost算法的樣本權重的class_weight參數。 對于每個訓練樣本,它返回不同的權重。
Sample_weight is an array of the same length as data, containing weights to apply to the model’s loss for each sample.
Sample_weight是與數據長度相同的數組,其中包含權重以應用于每個樣本的模型損失。
def BalancedSampleWeights(y_train,class_weight_coef):
classes = np.unique(y_train, axis = 0)
classes.sort()
class_samples = np.bincount(y_train)
total_samples = class_samples.sum()
n_classes = len(class_samples)
weights = total_samples / (n_classes * class_samples * 1.0)
class_weight_dict = {key : value for (key, value) in zip(classes, weights)}
class_weight_dict[classes[1]] = class_weight_dict[classes[1]] *
class_weight_coef
sample_weights = [class_weight_dict[i] for i in y_train]
return sample_weights#Usage
weight=BalancedSampleWeights(
model = XGBClassifier(sample_weight = weight)
model.fit(X, class_weights vs sample_weight:
class_weights與sample_weight:
sample_weights is used to give weights for each training sample. That means that you should pass a one-dimensional array with the exact same number of elements as your training samples.
sample_weights用于給出每個訓練樣本的權重。 這意味著您應該傳遞一維數組,該數組具有與訓練樣本完全相同數量的元素。
class_weights is used to give weights for each target class. This means you should pass a weight for each class that you are trying to classify.
class_weights用于為每個目標類賦予權重。 這意味著您應該為要分類的每個類傳遞權重。
結論: (Conclusion:)
The above are few methods of finding class weights and sample weights for your classifier. I mention almost all the techniques which worked well for my project.
上面是為分類器找到分類權重和樣本權重的幾種方法。 我提到幾乎所有對我的項目都有效的技術。
I’m requesting the readers to give a try on these techniques that could help you, if not take it as learning 😄 it may help you another time 😜
我要求讀者嘗試這些可以幫助您的技術,如果不以學習為learning,那可能會再次幫助您😜
Reach me at LinkedIn 😍
在LinkedIn上到達我
翻譯自: https://towardsdatascience.com/how-to-handle-multiclass-imbalanced-data-say-no-to-smote-e9a7f393c310
數據不平衡處理
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389513.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389513.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389513.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
思想及實現)
最小二乘法以及RANSAC(隨機采樣一致性)思想及實現

軟鍵盤彈起,導致底部被頂上去

關于LaaS,PaaS,SaaS一些個人的理解

糖藥病數據集分類_使用optuna和mlflow進行心臟病分類器調整

Android MVP 框架
)
相似圖像搜索的哈希算法思想及實現(差值哈希算法和均值哈希算法)

騰訊云AI應用產品總監王磊:AI 在傳統產業的最佳實踐
和歸一化實現)
標準化(Normalization)和歸一化實現

Toast源碼深度分析

序列化框架MJExtension詳解 + iOS ORM框架
 or ‘1type‘ as a synonym of type is deprecated解決辦法)
運行keras出現 FutureWarning: Passing (type, 1) or ‘1type‘ as a synonym of type is deprecated解決辦法
轉移方式及參數傳遞)
RedirectToAction()轉移方式及參數傳遞


mongdb 群集_群集文檔的文本摘要

keras框架實現手寫數字識別

gdal進行遙感影像讀寫_如何使用遙感影像進行礦物勘探

從零開始神經網絡:keras框架實現數字圖像識別詳解!


推薦算法的先驗算法的連接_數據挖掘專注于先驗算法
