線性回歸–最小二乘法(Least Square Method)
線性回歸:
什么是線性回歸?
舉個例子,某商品的利潤在售價為2元、5元、10元時分別為4元、10元、20元, 我們很容易得出商品的利潤與售價的關系符合直線:y=2x. 在上面這個簡單的一元線性回歸方程中,我們稱“2”為回歸系數,即斜率為其回歸系數。 回歸系數表示商品的售價(x)每變動一個單位,其利潤(y)與之對應的變動關系。
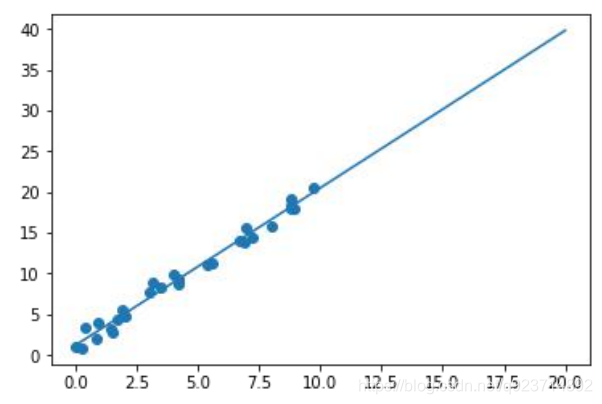
線性回歸表示這些離散的點總體上“最逼近”哪條直線。
實現方法:
? 它通過最小化誤差的平方和,尋找數據的最佳函數匹配。
? 利用最小二乘法可以簡便地求得未知的數據,并使得這些求得的數據與實際數據之間誤差的平方 和為最小。
? 假設我們現在有一系列的數據點(xi,yi) (i=1,…,m),那么由我們給出的擬合函數h(x)得到的估計量就 是h(xi)
? 殘差:ri = h(xi) – yi
最小二乘法(Least Square Method)的概念
? 殘差:ri = h(xi) – yi
? 三種范數:
1.∞-范數:殘差絕對值的最大值,即所有數據點中殘差距離的最大值:

2. 1-范數:絕對殘差和,即所有數據點殘差距離之和:
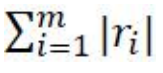
3. 2-范數:殘差平方和:
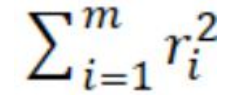
? 擬合程度,用通俗的話來講,就是我們的擬合函數h(x)與待求解的函數y之間的相似性。那么 2-范數越小,自然相似性就比較高了。
最小二乘法的定義:
由此,我們可以寫出最小二乘法的定義了:
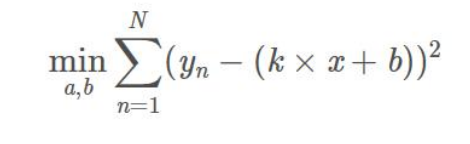
這是一個無約束的最優化問題,分別對k和b求偏導,然后令偏導數為0,即可獲得極值點。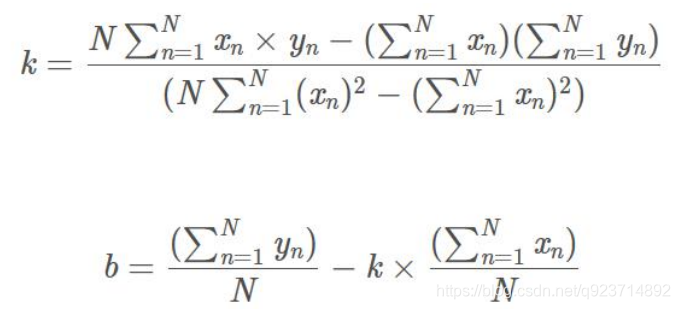
最小二乘法的代碼實現:
import pandas as pdsales=pd.read_csv('train_data.csv',sep='\s*,\s*',engine='python') #讀取CSV
X=sales['X'].values #存csv的第一列
Y=sales['Y'].values #存csv的第二列#初始化賦值
s1 = 0
s2 = 0
s3 = 0
s4 = 0
n = 4 ####你需要根據的數據量進行修改#循環累加
for i in range(n):s1 = s1 + X[i]*Y[i] #X*Y,求和s2 = s2 + X[i] #X的和s3 = s3 + Y[i] #Y的和s4 = s4 + X[i]*X[i] #X**2,求和#計算斜率和截距
k = (s2*s3-n*s1)/(s2*s2-s4*n)
b = (s3 - k*s2)/n
print("Coeff: {} Intercept: {}".format(k, b))
實驗結果:
輸入:
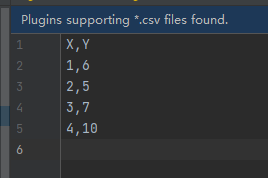
輸出:

RANSAC(隨機采樣一致性)
RANSAC與最小二乘法
? 生產實踐中的數據往往會有一定的偏差。
? 例如我們知道兩個變量X與Y之間呈線性關系,Y=aX+b,我們想確定參數a與b的具體值。通過實驗, 可以得到一組X與Y的測試值。雖然理論上兩個未知數的方程只需要兩組值即可確認,但由于系統誤 差的原因,任意取兩點算出的a與b的值都不盡相同。我們希望的是,最后計算得出的理論模型與測 試值的誤差最小。
? 最小二乘法:通過計算最小均方差關于參數a、b的偏導數為零時的值。事實上,很多情況下,最小 二乘法都是線性回歸的代名詞。
? 遺憾的是,最小二乘法只適合于誤差較小的情況。
? 在模型確定以及最大迭代次數允許的情況下,RANSAC總是能找到最優解。(對于包含80%誤差的數 據集,RANSAC的效果遠優于直接的最小二乘法。)
? 由于一張圖片中像素點數量大,采用最小二乘法運算量大,計算速度慢。
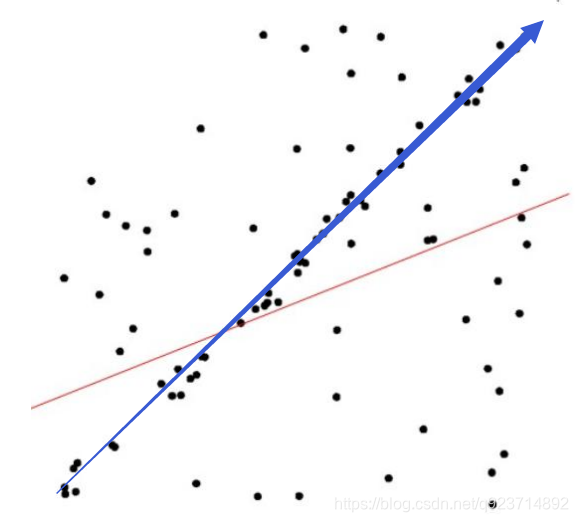
比如說:上圖,通過肉眼很明顯可以看出來擬合的線應該是藍色的,然而經過最小二乘法后得到的是紅色的線。
RANSAC的步驟:
RANSAC算法的輸入:
- 一組觀測數據(往往含有較大的噪聲或無效點),
- 一個用于解釋觀測數據的參數化模型
- 一些可信的參數。
RANSAC算法的實現: - 在數據中隨機選擇幾個點設定為內群
- 計算適合內群的模型
- 把其它剛才沒選到的點帶入剛才建立的模型中,計算是否為內群
- 記下內群數量
- 重復以上步驟
- 比較哪次計算中內群數量最多,內群最多的那次所建的模型就是我們所要求的解
注意:不同問題對應的數學模型不同,因此在計算模型參數時方法必定不同,RANSAC的作用不在于計 算模型參數,而是提供更好的輸入數據(樣本)。(這導致ransac的缺點在于要求數學模型已知)
RANSAC的參數確定:
這里有幾個問題:
- 一開始的時候我們要隨機選擇多少點(n)
- 以及要重復做多少次(k)
? 假設每個點是真正內群的概率為 w: w = 內群的數目/(內群數目+外群數目)
? 通常我們不知道 w 是多少, w^n是所選擇的n個點都是內群的機率, 1-w^n 是所選擇的n個點至少有一個 不是內群的機率, (1 ? wn)k 是表示重復 k 次都沒有全部的n個點都是內群的機率, 假設算法跑 k 次以后 成功的機率是p,那么, 1 ? p = (1 ? wn)k p = 1 ? (1 ? wn)k
? 我們可以通過P反算得到抽取次數K,K=log(1-P)/log(1-w^n)。
? 所以如果希望成功機率高:
? 當n不變時,k越大,則p越大; 當w不變時,n越大,所需的k就越大。
? 通常w未知,所以n 選小一點比較好。
RANSAC的代碼實現:
import numpy as np
import scipy as sp
import scipy.linalg as sldef ransac(data, model, n, k, t, d, debug = False, return_all = False):"""輸入:data - 樣本點model - 假設模型:事先自己確定n - 生成模型所需的最少樣本點k - 最大迭代次數t - 閾值:作為判斷點滿足模型的條件d - 擬合較好時,需要的樣本點最少的個數,當做閾值看待輸出:bestfit - 最優擬合解(返回nil,如果未找到)iterations = 0bestfit = nil #后面更新besterr = something really large #后期更新besterr = thiserrwhile iterations < k {maybeinliers = 從樣本中隨機選取n個,不一定全是局內點,甚至全部為局外點maybemodel = n個maybeinliers 擬合出來的可能符合要求的模型alsoinliers = emptyset #滿足誤差要求的樣本點,開始置空for (每一個不是maybeinliers的樣本點){if 滿足maybemodel即error < t將點加入alsoinliers }if (alsoinliers樣本點數目 > d) {%有了較好的模型,測試模型符合度bettermodel = 利用所有的maybeinliers 和 alsoinliers 重新生成更好的模型thiserr = 所有的maybeinliers 和 alsoinliers 樣本點的誤差度量if thiserr < besterr{bestfit = bettermodelbesterr = thiserr}}iterations++}return bestfit"""iterations = 0bestfit = Nonebesterr = np.inf #設置默認值best_inlier_idxs = Nonewhile iterations < k:maybe_idxs, test_idxs = random_partition(n, data.shape[0])print ('test_idxs = ', test_idxs)maybe_inliers = data[maybe_idxs, :] #獲取size(maybe_idxs)行數據(Xi,Yi)test_points = data[test_idxs] #若干行(Xi,Yi)數據點maybemodel = model.fit(maybe_inliers) #擬合模型test_err = model.get_error(test_points, maybemodel) #計算誤差:平方和最小print('test_err = ', test_err <t)also_idxs = test_idxs[test_err < t]print ('also_idxs = ', also_idxs)also_inliers = data[also_idxs,:]if debug:print ('test_err.min()',test_err.min())print ('test_err.max()',test_err.max())print ('numpy.mean(test_err)',numpy.mean(test_err))print ('iteration %d:len(alsoinliers) = %d' %(iterations, len(also_inliers)) )# if len(also_inliers > d):print('d = ', d)if (len(also_inliers) > d):betterdata = np.concatenate( (maybe_inliers, also_inliers) ) #樣本連接bettermodel = model.fit(betterdata)better_errs = model.get_error(betterdata, bettermodel)thiserr = np.mean(better_errs) #平均誤差作為新的誤差if thiserr < besterr:bestfit = bettermodelbesterr = thiserrbest_inlier_idxs = np.concatenate( (maybe_idxs, also_idxs) ) #更新局內點,將新點加入iterations += 1if bestfit is None:raise ValueError("did't meet fit acceptance criteria")if return_all:return bestfit,{'inliers':best_inlier_idxs}else:return bestfitdef random_partition(n, n_data):"""return n random rows of data and the other len(data) - n rows"""all_idxs = np.arange(n_data) #獲取n_data下標索引np.random.shuffle(all_idxs) #打亂下標索引idxs1 = all_idxs[:n]idxs2 = all_idxs[n:]return idxs1, idxs2class LinearLeastSquareModel:#最小二乘求線性解,用于RANSAC的輸入模型 def __init__(self, input_columns, output_columns, debug = False):self.input_columns = input_columnsself.output_columns = output_columnsself.debug = debugdef fit(self, data):#np.vstack按垂直方向(行順序)堆疊數組構成一個新的數組A = np.vstack( [data[:,i] for i in self.input_columns] ).T #第一列Xi-->行XiB = np.vstack( [data[:,i] for i in self.output_columns] ).T #第二列Yi-->行Yix, resids, rank, s = sl.lstsq(A, B) #residues:殘差和return x #返回最小平方和向量 def get_error(self, data, model):A = np.vstack( [data[:,i] for i in self.input_columns] ).T #第一列Xi-->行XiB = np.vstack( [data[:,i] for i in self.output_columns] ).T #第二列Yi-->行YiB_fit = sp.dot(A, model) #計算的y值,B_fit = model.k*A + model.berr_per_point = np.sum( (B - B_fit) ** 2, axis = 1 ) #sum squared error per rowreturn err_per_pointdef test():#生成理想數據n_samples = 500 #樣本個數n_inputs = 1 #輸入變量個數n_outputs = 1 #輸出變量個數A_exact = 20 * np.random.random((n_samples, n_inputs))#隨機生成0-20之間的500個數據:行向量perfect_fit = 60 * np.random.normal( size = (n_inputs, n_outputs) ) #隨機線性度,即隨機生成一個斜率B_exact = sp.dot(A_exact, perfect_fit) # y = x * k#加入高斯噪聲,最小二乘能很好的處理A_noisy = A_exact + np.random.normal( size = A_exact.shape ) #500 * 1行向量,代表XiB_noisy = B_exact + np.random.normal( size = B_exact.shape ) #500 * 1行向量,代表Yiif 1:#添加"局外點"n_outliers = 100all_idxs = np.arange( A_noisy.shape[0] ) #獲取索引0-499np.random.shuffle(all_idxs) #將all_idxs打亂outlier_idxs = all_idxs[:n_outliers] #100個0-500的隨機局外點A_noisy[outlier_idxs] = 20 * np.random.random( (n_outliers, n_inputs) ) #加入噪聲和局外點的XiB_noisy[outlier_idxs] = 50 * np.random.normal( size = (n_outliers, n_outputs)) #加入噪聲和局外點的Yi#setup model all_data = np.hstack( (A_noisy, B_noisy) ) #形式([Xi,Yi]....) shape:(500,2)500行2列input_columns = range(n_inputs) #數組的第一列x:0output_columns = [n_inputs + i for i in range(n_outputs)] #數組最后一列y:1debug = Falsemodel = LinearLeastSquareModel(input_columns, output_columns, debug = debug) #類的實例化:用最小二乘生成已知模型linear_fit,resids,rank,s = sp.linalg.lstsq(all_data[:,input_columns], all_data[:,output_columns])#run RANSAC 算法ransac_fit, ransac_data = ransac(all_data, model, 50, 1000, 7e3, 300, debug = debug, return_all = True)if 1:import pylabsort_idxs = np.argsort(A_exact[:,0])A_col0_sorted = A_exact[sort_idxs] #秩為2的數組if 1:pylab.plot( A_noisy[:,0], B_noisy[:,0], 'k.', label = 'data' ) #散點圖pylab.plot( A_noisy[ransac_data['inliers'], 0], B_noisy[ransac_data['inliers'], 0], 'bx', label = "RANSAC data" )else:pylab.plot( A_noisy[non_outlier_idxs,0], B_noisy[non_outlier_idxs,0], 'k.', label='noisy data' )pylab.plot( A_noisy[outlier_idxs,0], B_noisy[outlier_idxs,0], 'r.', label='outlier data' )pylab.plot( A_col0_sorted[:,0],np.dot(A_col0_sorted,ransac_fit)[:,0],label='RANSAC fit' )pylab.plot( A_col0_sorted[:,0],np.dot(A_col0_sorted,perfect_fit)[:,0],label='exact system' )pylab.plot( A_col0_sorted[:,0],np.dot(A_col0_sorted,linear_fit)[:,0],label='linear fit' )pylab.legend()pylab.show()if __name__ == "__main__":test()實現結果:
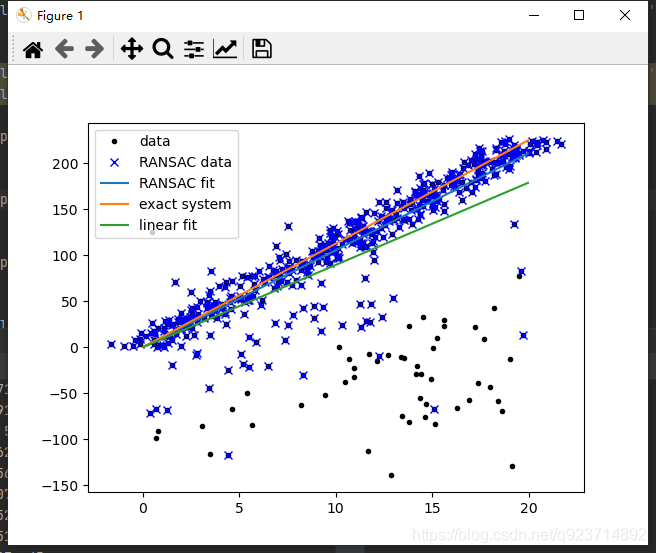
注意:特別注意:這個算法應該數據是隨機初始的,可能出現did't meet fit acceptance criteria的錯誤,多運行幾次有幾率解決。
結果很明顯可以看出:ransac模型比linear模型更加接近exact system。
RANSAC的應用:
全景拼接:
流程:
- 針對某個場景拍攝多張/序列圖像
- 通過匹配特征(sift匹配)計算下一張圖像與上一張圖像之間的變換結構。
- 圖像映射,將下一張圖像疊加到上一張圖像的坐標系中
- 變換后的融合/合成



RANSAC的優缺點:
優點:
- 它能魯棒的估計模型參數。例如,它能從包含大量局外點的數據集中估計出高精度的參數。
缺點:
- 它計算參數的迭代次數沒有上限;如果設置迭代次數的上限,得到的結果可能不是最優的結果,甚至可能得到錯誤的結果。
- RANSAC只有一定的概率得到可信的模型,概率與迭代次數成正比。
- 它要求設置跟問題相關的閥值。
- RANSAC只能從特定的數據集中估計出一個模型,如果存在兩個(或多個)模型,RANSAC不能找到 別的模型。
- 要求數學模型已知(這個缺點最致命)




)

和歸一化實現)


 or ‘1type‘ as a synonym of type is deprecated解決辦法)
轉移方式及參數傳遞)








