ai驅動數據安全治理
Data gathering consists of many time-consuming and complex activities. These include proxy management, data parsing, infrastructure management, overcoming fingerprinting anti-measures, rendering JavaScript-heavy websites at scale, and much more. Is there a way to automate these processes? Absolutely.
數據收集包括許多耗時且復雜的活動。 這些措施包括代理管理,數據解析,基礎結構管理,克服指紋防措施,大規模渲染JavaScript繁重的網站等。 有沒有辦法使這些過程自動化? 絕對。
Finding a more manageable solution for a large-scale data gathering has been on the minds of many in the web scraping community. Specialists saw a lot of potential in applying AI (Artificial Intelligence) and ML (Machine Learning) to web scraping. However, only recently, actions toward data gathering automation using AI applications have been taken. This is no wonder, as AI and ML algorithms became more robust at large-scale only in recent years together with advancement in computing solutions.
網絡抓取社區中的許多人一直在尋找為大規模數據收集提供更易管理的解決方案。 專家們看到了將AI(人工智能)和ML(機器學習)應用于網頁抓取的巨大潛力。 但是,直到最近,才采取行動使用AI應用程序進行數據收集自動化。 這也就不足為奇了,因為AI和ML算法直到最近幾年才隨著計算解決方案的進步而變得更加強大。
By applying AI-powered solutions in data gathering, we can help automate tedious manual work and ensure a much better quality of the collected data. To better grasp the struggles of web scraping, let’s look into the process of data gathering, its biggest challenges, and possible future solutions that might ease and potentially solve mentioned challenges.
通過在數據收集中應用基于AI的解決方案,我們可以幫助完成繁瑣的手工工作,并確保所收集數據的質量更高。 為了更好地掌握Web抓取的工作,讓我們研究數據收集的過程,最大的挑戰以及將來可能緩解和潛在解決上述挑戰的解決方案。
數據收集:逐步 (Data collection: step by step)
To better understand the web scraping process, it’s best to visualize it in a value chain:
為了更好地了解網絡抓取過程,最好在價值鏈中對其進行可視化處理:
As you can see, web scraping takes up four distinct actions:
如您所見,Web抓取采取了四個不同的操作:
- Crawling path building and URL collection. 搜尋路徑建立和URL收集。
- Scraper development and its support. 刮板的開發及其支持。
- Proxy acquisition and management. 代理獲取和管理。
- Data fetching and parsing. 數據獲取和解析。
Anything that goes beyond those terms is considered to be data engineering or part of data analysis.
超出這些術語的任何內容都被視為數據工程或數據分析的一部分。
By pinpointing which actions belong to the web scraping category, it becomes easier to find the most common data gathering challenges. It also allows us to see which parts can be automated and improved with the help of AI and ML powered solutions.
通過查明哪些動作屬于Web抓取類別,可以更輕松地找到最常見的數據收集難題。 它還使我們能夠看到哪些零件可以借助AI和ML支持的解決方案進行自動化和改進。
大規模刮刮挑戰 (Large-scale scraping challenges)
Traditional data gathering from the web requires a lot of governance and quality assurance. Of course, the difficulties that come with data gathering increase together with the scale of the scraping project. Let’s dig a little deeper into the said challenges by going through our value chain’s actions and analyzing potential issues.
從網絡收集傳統數據需要大量的管理和質量保證。 當然,數據收集帶來的困難隨著抓取項目的規模而增加。 讓我們通過價值鏈的行動并分析潛在問題,對上述挑戰進行更深入的研究。
建立搜尋路徑并收集URL (Building a crawling path and collecting URLs)
Building a crawling path is the first and essential part of data gathering. To put it simply, a crawling path is a library of URLs from which data will be extracted. The biggest challenge here is not the collection of the website URLs that you want to scrape, but obtaining all the necessary URLs of the initial targets. That could mean dozens, if not hundreds of URLs that will need to be scraped, parsed, and identified as important URLs for your case.
建立爬網路徑是數據收集的首要且必不可少的部分。 簡單來說,爬網路徑是一個URL庫,將從中提取數據。 這里最大的挑戰不是您要抓取的網站URL的集合,而是獲得初始目標的所有必需URL。 這可能意味著需要抓取,解析和標識數十個(如果不是數百個)URL,這對于您的案例而言是重要的URL。
刮板的開發及其維護 (Scraper development and its maintenance)
Building a scraper comes with a whole new set of issues. There are a lot of factors to look out for when doing so:
構建刮板會帶來一系列全新問題。 這樣做時要注意很多因素:
- Choosing the language, APIs, frameworks, etc. 選擇語言,API,框架等。
- Testing out what you’ve built. 測試您的構建。
- Infrastructure management and maintenance. 基礎架構管理和維護。
- Overcoming fingerprinting anti-measures. 克服指紋防措施。
- Rendering JavaScript-heavy websites at scale. 大規模渲染JavaScript繁重的網站。
These are just the tip of the iceberg that you will encounter when building a web scraper. There are plenty more smaller and time consuming things that will accumulate into larger issues.
這些只是構建網絡刮板時遇到的冰山一角。 還有很多小而費時的事情會累積成更大的問題。
代理收購與管理 (Proxy acquisition and management)
Proxy management will be a challenge, especially to those new to scraping. There are so many little mistakes one can make to block batches of proxies until successfully scraping a site. Proxy rotation is a good practice, but it doesn’t illuminate all the issues and requires constant management and upkeep of the infrastructure. So if you are relying on a proxy vendor, a good and frequent communication will be necessary.
代理管理將是一個挑戰,特別是對于那些剛開始使用的人。 在成功刮取站點之前,阻止批次代理存在很多小錯誤。 代理輪換是一種很好的做法,但是它不能說明所有問題,并且需要對基礎架構進行持續的管理和維護。 因此,如果您依賴代理供應商,則需要進行良好且頻繁的溝通。
數據獲取和解析 (Data fetching and parsing)
Data parsing is the process of making the acquired data understandable and usable. While creating a parser might sound easy, its further maintenance will cause big problems. Adapting to different page formats and website changes will be a constant struggle and will require your developers teams’ attention more often than you can expect.
數據解析是使獲取的數據易于理解和使用的過程。 盡管創建解析器聽起來很容易,但對其進行進一步的維護將導致大問題。 適應不同的頁面格式和網站更改將一直是一個難題,并且將需要您的開發團隊更多的注意力。
As you can see, traditional web scraping comes with many challenges, requires a lot of manual labour, time, and resources. However, the brightside with computing is that almost all things can be automated. And as the development of AI and ML powered web scraping is emerging, creating a future-proof large-scale data gathering becomes a more realistic solution.
如您所見,傳統的Web抓取面臨許多挑戰,需要大量的人工,時間和資源。 但是,計算的亮點是幾乎所有事物都可以自動化。 隨著AI和ML支持的Web抓取技術的發展不斷涌現,創建面向未來的大規模數據收集已成為一種更為現實的解決方案。
使網頁抓取永不過時 (Making web scraping future-proof)
In what way AI and ML can innovate and improve web scraping? According to Oxylabs Next-Gen Residential Proxy AI & ML advisory board member Jonas Kubilius, an AI researcher, Marie Sklodowska-Curie Alumnus, and Co-Founder of Three Thirds:
AI和ML以什么方式可以創新和改善網頁抓取? 根據Oxylabs下一代住宅代理AI和ML顧問委員會成員Jonas Kubilius的說法,他是AI研究人員Marie Sklodowska-Curie Alumnus和“三分之三”的聯合創始人:
“There are recurring patterns in web content that are typically scraped, such as how prices are encoded and displayed, so in principle, ML should be able to learn to spot these patterns and extract the relevant information. The research challenge here is to learn models that generalize well across various websites or that can learn from a few human-provided examples. The engineering challenge is to scale up these solutions to realistic web scraping loads and pipelines.”
“網絡內容中經常會出現重復出現的模式,例如價格的編碼和顯示方式,因此,原則上,機器學習應該能夠發現這些模式并提取相關信息。 這里的研究挑戰是學習在各種網站上都能很好地概括的模型,或者可以從一些人類提供的示例中學習模型。 工程上的挑戰是將這些解決方案擴展到實際的Web抓取負載和管道。 ”
Instead of manually developing and managing the scrapers code for each new website and URL, creating an AI and ML-powered solution will simplify the data gathering pipeline. This will take care of proxy pool management, data parsing maintenance, and other tedious work.
創建一個由AI和ML支持的解決方案將簡化數據收集流程,而不是為每個新網站和URL手動開發和管理刮板代碼。 這將負責代理池管理,數據解析維護以及其他繁瑣的工作。
Not only does AI and ML-powered solutions enable developers to build highly scalable data extraction tools, but it also enables data science teams to prototype rapidly. It also stands as a backup to your existing custom-built code if it was ever to break.
由AI和ML支持的解決方案不僅使開發人員能夠構建高度可擴展的數據提取工具,而且還使數據科學團隊能夠快速進行原型制作。 如果曾經破解過,它也可以作為現有定制代碼的備份。
網頁抓取的未來前景如何 (What the future holds for web scraping)
As we already established, creating fast data processing pipelines along with cutting edge ML techniques can offer an unparalleled competitive advantage in the web scraping community. And looking at today’s market, the implementation of AI and ML in data gathering has already started.
正如我們已經確定的那樣,創建快速的數據處理管道以及最先進的ML技術可以在Web抓取社區中提供無與倫比的競爭優勢。 縱觀當今市場,已經開始在數據收集中實施AI和ML。
For this reason, Oxylabs is introducing Next-Gen Residential Proxies which are powered by the latest AI applications.
因此,Oxylabs推出了由最新的AI應用程序提供支持的下一代住宅代理 。
Next-Gen Residential Proxies were built with heavy-duty data retrieval operations in mind. They enable web data extraction without delays or errors. The product is as customizable as a regular proxy, but at the same time, it guarantees a much higher success rate and requires less maintenance. Custom headers and IP stickiness are both supported, alongside reusable cookies and POST requests. Its main benefits are:
下一代住宅代理的構建考慮了重型數據檢索操作。 它們使Web數據提取沒有延遲或錯誤。 該產品可以像常規代理一樣進行自定義,但是同時,它可以確保更高的成功率并需要更少的維護。 支持自定義標頭和IP粘性,以及可重用的cookie和POST請求。 它的主要優點是:
- 100% success rate 成功率100%
- AI-Powered Dynamic Fingerprinting (CAPTCHA, block, and website change handling) AI驅動的動態指紋識別(CAPTCHA,阻止和網站更改處理)
- Machine Learning based HTML parsing 基于機器學習HTML解析
- Easy integration (like any other proxy) 易于集成(像其他代理一樣)
- Auto-Retry system 自動重試系統
- JavaScript rendering JavaScript渲染
- Patented proxy rotation system 專利代理旋轉系統
Going back to our previous web scraping value chain, you can see which parts of web scraping can be automated and improved with AI and ML-powered Next-Gen Residential Proxies.
回到我們以前的網絡抓取價值鏈,您可以看到可以使用AI和ML支持的下一代住宅代理來自動化和改進網絡抓取的哪些部分。
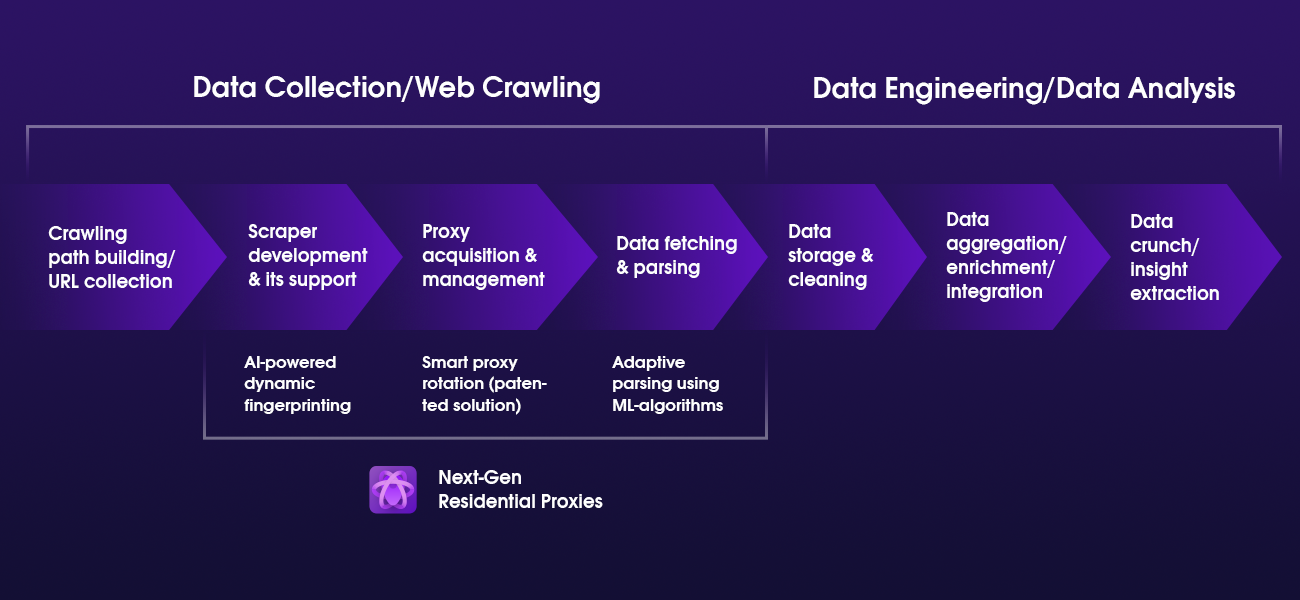
The Next-Gen Residential Proxy solution automates almost the whole scraping process, making it a truly strong competitor for future-proof web scraping.
下一代住宅代理解決方案幾乎可以自動化整個刮削過程,使其成為永不過時的網絡刮削的真正強大競爭對手。
This project will be continuously developed and improved by Oxylabs in-house ML engineering team and a board of advisors, Jonas Kubilius, Adi Andrei, Pujaa Rajan, and Ali Chaudhry, specializing in the fields of Artificial Intelligence and ML engineering.
Oxylabs內部的ML工程團隊和顧問委員會Jonas Kubilius , Adi Andrei , Pujaa Rajan和Ali Chaudhry將繼續開發和改進此項目,該委員會專門研究人工智能和ML工程領域。
結語 (Wrapping up)
As the scale of web scraping projects increase, automating data gathering becomes a high priority for businesses that want to stay ahead of the competition. With the improvement of AI algorithms in recent years, along with the increase in compute power and the growth of the talent pool has made AI implementations possible in a number of industries, web scraping included.
隨著網絡抓取項目規模的擴大,對于希望保持競爭優勢的企業而言,自動化數據收集已成為當務之急。 近年來,隨著AI算法的改進,以及計算能力的提高和人才庫的增長,使得許多行業都可以實施AI,其中包括Web抓取。
Establishing AI and ML-powered data gathering techniques offers a great competitive advantage in the industry, as well as save copious amounts of time and resources. It is the new future of large-scale web scraping, and a good head start of the development of future-proof solutions.
建立由AI和ML支持的數據收集技術在行業中提供了巨大的競爭優勢,并且節省了大量的時間和資源。 這是大規模刮網的新未來,也是開發面向未來的解決方案的良好開端。
翻譯自: https://towardsdatascience.com/the-new-beginnings-of-ai-powered-web-data-gathering-solutions-a8e95f5e1d3f
ai驅動數據安全治理
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389361.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389361.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389361.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

從Text文本中讀值插入到數據庫中

Dataset和DataLoader構建數據通道

鐵拳nat映射_鐵拳如何重塑我的數據可視化設計流程

Django2 Web 實戰03-文件上傳
)
BZOJ.2738.矩陣乘法(整體二分 二維樹狀數組)

從數據庫里讀值往TEXT文本里寫
)
DengAI —如何應對數據科學競賽? (EDA)

Pytorch模型層簡單介紹

有效溝通的技能有哪些_如何有效地展示您的數據科學或軟件工程技能

java.net.SocketException: Software caused connection abort: socket write erro
![[博客..配置?]博客園美化](http://pic.xiahunao.cn/[博客..配置?]博客園美化)
[博客..配置?]博客園美化

使用K-Means對美因河畔法蘭克福的社區進行聚類

Pytorch損失函數losses簡介

讀取Mc1000的 唯一 ID 機器號

樣本均值的抽樣分布_抽樣分布樣本均值
)
玩轉ceph性能測試---對象存儲(一)
![[BZOJ 4300]絕世好題](http://pic.xiahunao.cn/[BZOJ 4300]絕世好題)
[BZOJ 4300]絕世好題

因果關系和相關關系 大數據_數據科學中的相關性與因果關系

Pytorch構建模型的3種方法
