介紹 (Introduction)
This blog post summarizes the results of the Capstone Project in the IBM Data Science Specialization on Coursera. Within the project, the districts of Frankfurt am Main in Germany shall be clustered according to their venue data using the K-Means clustering algorithm. The first section describes the Business problem that we will be dealing with. Then we shall take a look at the data that can be used to solve the problem and the methodology for finding a solution.
這篇博客文章總結了Coursera上IBM Data Science Specialization中Capstone項目的結果。 在項目內,應使用K-Means聚類算法根據其場地數據對德國美因河畔法蘭克福地區進行聚類。 第一部分描述了我們將要處理的業務問題。 然后,我們將研究可用于解決問題的數據和找到解決方案的方法。
業務問題 (Business Problem)
A client is interested in opening a franchise of their Asian restaurant chain in the city of Frankfurt am Main, preferably close to the city center. It will be their first restaurant in the city, and they want us to find out which would be the best neighborhood/district to open an Asian restaurant in the city. Additionally, the results of the clustering algorithm t can also be used by someone interested in moving to Frankfurt and wanting to know about the cuisines available in the various districts.
客戶有興趣在美因河畔法蘭克福市(最好是靠近市中心)開設其亞洲餐廳連鎖店的特許經營權。 這將是他們在這座城市的第一家餐廳,他們希望我們找出哪一個是在城市開設亞洲餐廳的最佳社區/地區。 另外,聚類算法t的結果也可以供有興趣移居法蘭克福并希望了解各個地區可用美食的人使用。
數據 (Data)
Following datasets have been used in this project:
在該項目中使用了以下數據集:
Street Directory of the city of Frankfurt am Main: https://offenedaten.frankfurt.de/dataset/strassenverzeichnis-der-stadt-frankfurt-am-main
美因河畔法蘭克福市街道目錄: https : //offenedaten.frankfurt.de/dataset/strassenverzeichnis-der-stadt-frankfurt-am-main
- Foursquare API to get the most common venues in Frankfurt districts. Foursquare API獲得法蘭克福地區最常見的場所。
Demographics of Frankfurt am Main Neighborhoods : https://offenedaten.frankfurt.de/dataset/stadtteilprofile-bevoelkerung
法蘭克福主要社區的人口統計學: https : //offenedaten.frankfurt.de/dataset/stadtteilprofile-bevoelkerung
Election Atlas 2015 — GeoJSON Frankfurt neighborhoods: https://offenedaten.frankfurt.de/dataset/wahlatlas-2015-geodaten/resource/84dff094-ab75-431f-8c64-39606672f1da
2015年選舉地圖集-法蘭克福GeoJSON社區: https : //offenedaten.frankfurt.de/dataset/wahlatlas-2015-geodaten/resource/84dff094-ab75-431f-8c64-39606672f1da
數據收集與清理 (Data Gathering and cleaning)
We will analyze the districts of the city of Frankfurt am Main in this project. The datasets are available as CSV files which can be converted into a pandas dataframe using the pd.read_csv function inbuilt in pandas.
我們將在此項目中分析美因河畔法蘭克福市的地區。 數據集以CSV文件形式提供,可以使用內置在pandas中的pd.read_csv函數將其轉換為pandas數據框。
Data 1: Street directory of Frankfurt am Main:
數據1:美因河畔法蘭克福的街道目錄:
This dataset will be used to extract the district names and postcodes in Frankfurt. It is available as a CSV file and can be accessed via the link given above. Frankfurt contains 46 city districts. This is a huge dataset containing 4540 rows and 15 columns. Therefore, it was necessary to shorten and clean it by keeping only the data that is required. It is a street directory, which is why the dataset is so big. It was shortened to extract only the district names and postcodes. The resultant dataset contained 46 rows (one for each district) and 3 columns.
該數據集將用于提取法蘭克福的地區名稱和郵政編碼。 它以CSV文件的形式提供,可以通過上面給出的鏈接進行訪問。 法蘭克福包含46個市區。 這是一個巨大的數據集,包含4540行和15列。 因此,有必要通過僅保留所需的數據來縮短和清理它。 這是街道目錄,因此數據集如此之大。 縮短了提取區域名稱和郵政編碼的時間。 結果數據集包含46行(每個區一個)和3列。
Data 2 :
數據2:
The geographical coordinates of the districts will be utilized as input for Foursquare API that will be leveraged to extract information for each district respectively. We will use the Foursquare API to explore the districts in Frankfurt. We use Foursquare API to get the most common venues for each district. Foursquare returns a JSON file, from which required data needs to be extracted. We only extract the venue name, category, and geographical coordinates for each venue. These are then stored in a separate dataframe, for use in clustering.
地區的地理坐標將被用作Foursquare API的輸入,Foursquare API將被用于分別提取每個地區的信息。 我們將使用Foursquare API探索法蘭克福地區。 我們使用Foursquare API獲取每個地區最常見的場所。 Foursquare返回一個JSON文件,需要從中提取所需的數據。 我們僅提取每個場地的場地名稱,類別和地理坐標。 然后將它們存儲在單獨的數據框中,以用于群集。
Data 3: Frankfurt Demographics:
資料3:法蘭克福客層:
This dataset contains the district-wise distribution of population for the city of Frankfurt. It also contains useful data about the percentage of foreigners and specifically, population of various ethnicities in the districts. It contains 46 rows (one for each district) and 164 columns. It needs to be shortened to analyze. Only the required columns were picked from this dataset, which contained information about the total population of each district, population of foreigners, and so on. Moreover, the column names are in German. These were translated into English for easy understanding.
該數據集包含法蘭克福市的區域人口分布。 它還包含有關外國人百分比,特別是各地區不同種族人口的有用數據。 它包含46行(每個區一個)和164列。 需要縮短分析時間。 從此數據集中僅選擇了必需的列,其中包含有關每個地區的總人口,外國人的人口等信息。 此外,列名是德語。 這些被翻譯成英文以便于理解。
Data 4: Frankfurt neighborhoods GeoJSON:
數據4:法蘭克福社區GeoJSON:
The geoJSON file is required for plotting the Choropleth maps to analyze the demographics of Frankfurt districts. The district names in this file must match the district names in the dataset which is intended to be plotted. After checking, it was found that the districts of Bahnhofsviertel and Gutleutviertel are combined into a single district in the geoJSON file. Thus, the 2 district rows were merged in the demographics dataset. Also, there was an issue with the German letters containing umlauts, i.e. ü, ?, ?. Hence, districts containing these letters were also renamed as per the characters found in their equivalent names in the geoJSON file.
繪制Choropleth地圖以分析法蘭克福地區的人口統計信息時,需要geoJSON文件。 該文件中的區域名稱必須與要繪制的數據集中的區域名稱匹配。 檢查之后,發現在geoJSON文件中,Bahnhofsviertel和Gutleutviertel的區域合并為一個區域。 因此,這2個地區行已合并到人口統計數據集中。 另外,包含變音符號(即ü,?,?)的德語字母也存在問題。 因此,包含這些字母的地區也根據geoJSON文件中相同名稱中的字符進行了重命名。
方法 (Methodology)
Analytical Approach
分析方法
We shall first use k-means clustering to cluster the neighborhoods in Frankfurt. Frankfurt has 46 districts. We shall use the geocoder to get the geographical coordinates for each of these districts. We will use Foursquare API to explore the districts using their coordinates and get the most common venues in each district. Based on this information, we shall cluster the districts using k-means and take a look at each cluster. We need to look at clusters with a greater number of Asian and similar cuisine restaurants, as that indicates that there is demand for Asian cuisine in that cluster.
我們將首先使用k-means聚類對法蘭克福的社區進行聚類。 法蘭克福有46個區。 我們將使用地理編碼器獲取這些地區中每個地區的地理坐標。 我們將使用Foursquare API使用坐標來探索區域,并獲取每個區域中最常見的場所。 基于此信息,我們將使用k均值對區域進行聚類,并查看每個聚類。 我們需要查看具有更多亞洲和類似美食餐廳的集群,因為這表明該集群中對亞洲美食有需求。
Then we shall use the demographics data to find the districts with a greater population and compare that with the cluster data. We shall find districts that have more Asian restaurants as well as a sizeable Asian population, as these will be ideal for opening a new Asian restaurant. Additionally, we shall also look at closeby districts with lesser Asian restaurants but a sizeable Asian population, as this is also a good prospect, due to less competition in the area.
然后,我們將使用人口統計數據查找人口較多的地區,并將其與聚類數據進行比較。 我們將找到擁有更多亞洲餐廳以及大量亞洲人口的地區,因為這些地區對于開設新的亞洲餐廳非常理想。 此外,我們還將關注亞洲餐館較少但亞洲人口眾多的附近地區,因為由于該地區競爭較少,這也是一個很好的前景。

The street directory dataset is scraped and sliced to ultimately obtain just a list of districts in Frankfurt am Main along with their postal codes.
街道目錄數據集將被剪切和切片,最終僅可獲得美因河畔法蘭克福的地區列表以及其郵政編碼。
We require the geographical coordinates of the districts to plot on a map using Folium. These are not readily available in the dataset. We obtain the latitude and longitude for each district using Geopy- geopy is a Python 2 and 3 client for several popular geocoding web services.
我們要求使用Folium在地圖上繪制區域的地理坐標。 這些在數據集中并不容易獲得。 我們使用Geopy獲得每個地區的緯度和經度。geopy是Python 2和3客戶端,用于幾種流行的地理編碼Web服務。
Geopy makes it easy for Python developers to locate the coordinates of addresses, cities, countries, and landmarks across the globe using third-party geocoders and other data sources to get the data.
Geopy使Python開發人員可以使用第三方地理編碼器和其他數據源輕松獲取全球地址,城市,國家和地標的坐標,以獲取數據。
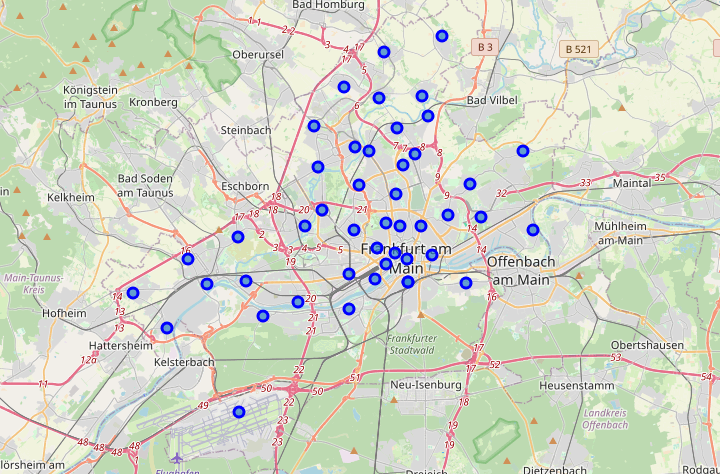
Next, the top 100 venues shall be fetched for each postal code. For this task, an API call to the Foursquare API is performed. The Foursquare API offers location data from all over the world for business purposes as well as for developers. The required format of the URL for performing an API call to the Foursquare API is displayed below. A developer only needs a free developer account.
接下來,應為每個郵政編碼獲取前100個場所。 對于此任務,執行對Foursquare API的API調用。 Foursquare API提供了來自世界各地的位置數據,用于商業目的以及開發人員。 下面顯示了執行對Foursquare API的API調用所需的URL格式。 開發人員只需要一個免費的開發人員帳戶。

The received venues are stored in a new dataframe. We check for the number of unique venue categories present in the data returned by Foursquare. It turns out there are 188 unique venue categories in Frankfurt.
接收到的場所將存儲在新的數據框中。 我們檢查Foursquare返回的數據中存在的唯一場所類別的數量。 事實證明,法蘭克福有188個獨特的場館類別。
Next up, we need to prepare the data for the K-means clustering algorithm. It cannot work with textual data or more commonly known as categorical data. Hence we need to encode the data using one-hot encoding. The encoded data is then grouped by District name in order to have 1 row for each district. When the data gets grouped, the one-hot encoded categories get summed up if a venue category appears more than once within a district. In order to have values at the same scale and smaller than one, the mean of the frequency of occurrence of each category is calculated and stored.
接下來,我們需要為K-means聚類算法準備數據。 它不能與文本數據或更常用的分類數據一起使用。 因此,我們需要使用一鍵編碼對數據進行編碼。 然后按地區名稱對編碼數據進行分組,以便每個地區有1行。 對數據進行分組后,如果場所類別在一個區域中出現多次,則將對一鍵編碼類別進行匯總。 為了使值具有相同的標度并且小于1,計算并存儲每個類別的出現頻率的平均值。
In order to get more insights into the data, the top 10 most common venues for each district are obtained and a separate dataframe is created to store these.
為了更深入地了解數據,獲取了每個地區的前10個最常見的場所,并創建了一個單獨的數據框來存儲這些場所。
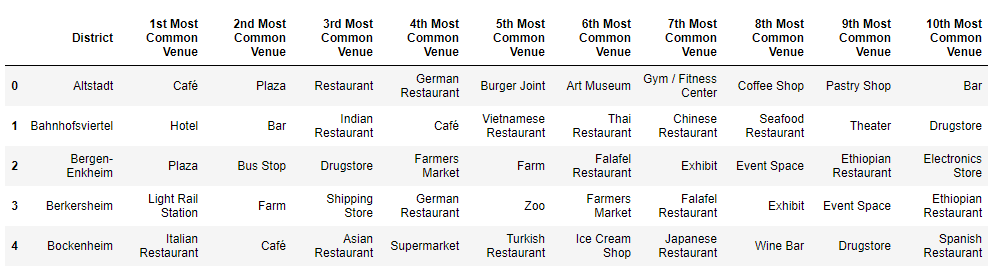
使用K均值聚類 (Clustering using K-means)
The one-hot encoded and grouped data is the input to the K-means algorithm and the number of clusters is set to five. We use the scikit-learn library for the K-means algorithm. The district column is dropped as it is textual data and we need to cluster using only the encoded values. The resulting cluster labels are then additionally stored in the data frame containing the ten most common venues for each district.
一鍵編碼和分組的數據是K-means算法的輸入,并且簇數設置為五個。 我們將scikit-learn庫用于K-means算法。 區域列被刪除,因為它是文本數據,因此我們只需要使用編碼后的值進行聚類。 然后,將生成的聚類標簽另外存儲在包含每個地區十個最常見場所的數據框中。

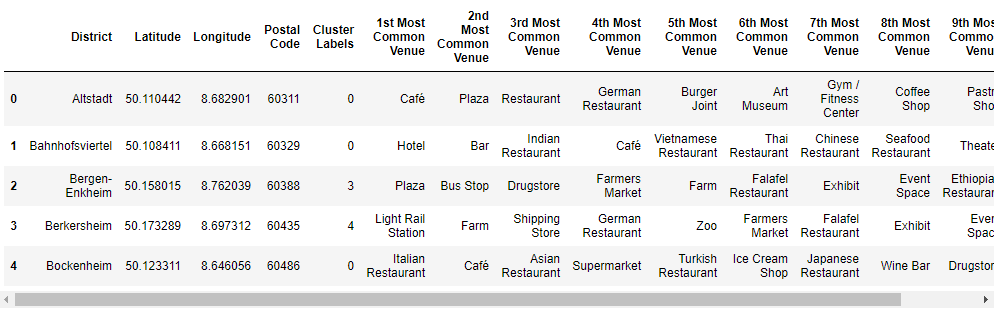
The dataframe containing the cluster labels and top venues is then merged with the dataframe containing latitude and longitude as seen in image above. This data was then used to visualize the clusters on a map using Folium.
然后,將包含聚類標簽和頂部地點的數據框與包含緯度和經度的數據框合并,如上圖所示。 然后使用Folium將這些數據用于在地圖上可視化群集。
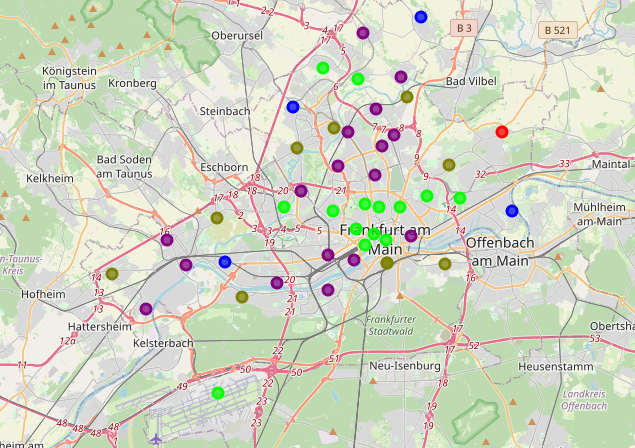
We then look at each cluster and based on the most common venues, we can name them and make decisions on which cluster is suitable for opening a new Asian restaurant.
然后,我們查看每個集群,并根據最常見的場所進行命名,并確定哪個集群適合開設新的亞洲餐廳。
觀察結果 (Observations)
We observe that the purple and light green clusters contain the most districts and the most number of venues. While the light green cluster contains more restaurants, the purple cluster contains more hotels, which indicates tourists. We can see that a variety of cuisines are offered in the light green cluster, indicating that they cater to a variety of customers. Most of the districts are located close to the city center. These factors make this cluster the most eligible for opening a new Asian restaurant.
我們觀察到紫色和淺綠色的群集包含最多的區域和最多的場所。 淺綠色的群集包含更多的餐廳,而紫色的群集包含更多的酒店,表示游客。 我們可以看到,淺綠色群集中提供了多種美食,表明它們可以滿足各種客戶的需求。 大多數地區都靠近市中心。 這些因素使該集群最有資格開設新的亞洲餐廳。
The purple cluster, on the other hand, although it does not contain many restaurants, has a lot of hotels and is pretty close to the city center. Presence of hotels indicates an influx of tourists, some of them Asian, meaning more prospective customers and if one finds a location not too far from the city center, an Asian restaurant here could flourish.
另一方面,紫色群集雖然沒有很多餐廳,但擁有許多旅館,并且非常靠近市中心。 旅館的存在表明游客的涌入,其中一些是亞洲人,這意味著潛在的顧客更多,如果發現離市中心不遠的地點,這里的亞洲餐館可能會興旺。
To know which district specifically would be perfect for opening an Asian restaurant, we look at the district-wise demographics of Frankfurt am Main, and then explore districts from both the light green and purple clusters.
要了解哪個區域最適合開設亞洲餐廳,我們先看一下美因河畔法蘭克福的區域人口統計信息,然后從淺綠色和紫色群集中探索區域。
數據探索-法蘭克福人口統計 (Data Exploration — Frankfurt demographics)
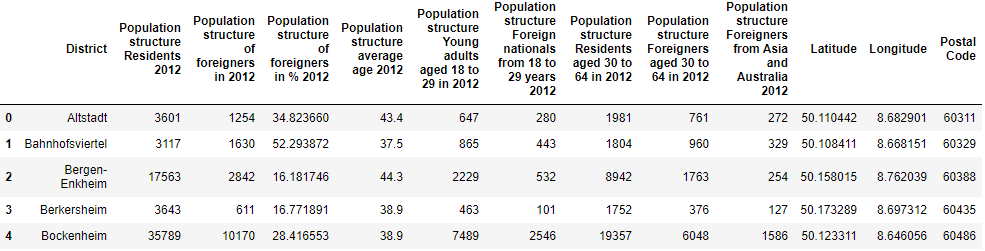
The demographics dataset contains district-wise distribution of population for the city of Frankfurt. It also contains useful data about the percentage of foreigners and specifically, population of various ethnicities in the districts. Only the required columns were picked from this dataset, which contained information about the total population of each district, population of foreigners, and so on. This dataset was then merged with the dataset containing the latitude and longitudes of the districts. The resulting dataset is as seen below.
人口統計數據集包含法蘭克福市的區域人口分布。 它還包含有關外國人百分比,特別是各地區不同種族人口的有用數據。 從該數據集中僅選擇了必需的列,其中包含有關每個地區的總人口,外國人的人口等信息。 然后將此數據集與包含地區緯度和經度的數據集合并。 結果數據集如下所示。
使用Choropleth映射進行數據可視化 (Data visualization using Choropleth maps)
The data from the demographics dataset is then plotted on a Choropleth map to visualize the population distribution across the city of Frankfurt. This data will then be used to select districts based on the earlier clustering results to explore further.
然后,將人口統計數據集中的數據繪制在Choropleth地圖上,以可視化法蘭克福市的人口分布。 然后,將根據較早的聚類結果將這些數據用于選擇地區,以進行進一步的探索。
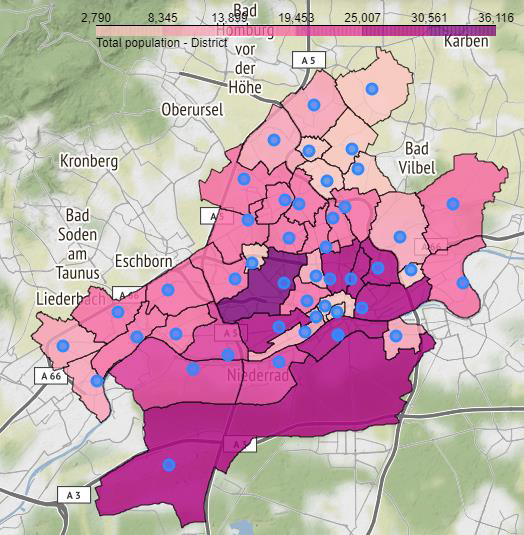
From this map, we observe that the central districts have the highest populations in Frankfurt, along with the district of Flughafen on the outskirts.
從這張地圖中,我們觀察到法蘭克福以及法蘭克福郊區的Flughafen地區人口最多。
Next, we take a look at the distribution of Asian and Australian population in Frankfurt.
接下來,我們來看看法蘭克福的亞洲和澳大利亞人口分布。
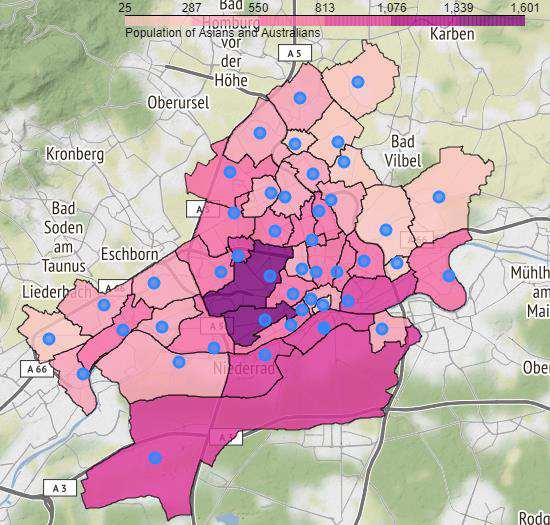
We can see from the above maps, that the districts of Bockenheim and Gallus have the highest population of Asians and Australians. Out of these, Bockenheim comes under the light green cluster, and Gallus comes under the purple cluster. These 2 neighborhoods are then explored to find out the number of Asian or similar cuisine restaurants in these districts.
從上面的地圖我們可以看到,博肯海姆和蓋洛斯地區的亞洲人和澳大利亞人數量最多。 其中,博肯海姆位于淺綠色的星團之下,而蓋洛斯位于紫色的星團之下。 然后探索這兩個街區,以找出這些地區中亞洲或類似餐廳的數量。
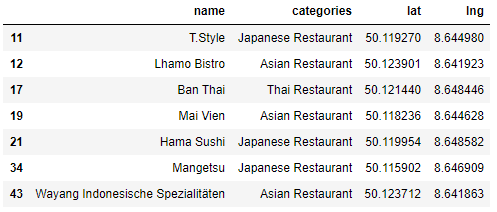
Bockenheim
博肯海姆
2. Gallus
2.捷拉斯
3. Niederrad
3.尼德拉德

結果和討論 (Results and Discussion)
By clustering the districts in Frankfurt and subsequently analyzing the district-wise demographics of the city, and then merging the two findings, we could arrive at 3 prospective neighborhoods that would be ideal for opening an Asian restaurant in the city.
通過將法蘭克福的各個區域進行聚類,然后分析該城市的區域人口統計資料,然后合并這兩個發現,我們可以得出3個潛在的社區,這對于在該城市開設亞洲餐廳非常理想。
1. Bockenheim:
1.博肯海姆:
Bockenheim falls in the light green cluster and is very close to the city center. It has 7 Asian restaurants which shows that there is a lot of demand for Asian cuisine in the area. It also has the highest population of Asians in the city at 1586.
博肯海姆(Bockenheim)落在淺綠色的集群中,非常靠近市中心。 它擁有7家亞洲餐廳,這表明該地區對亞洲美食的需求很大。 1586年,該市也是亞洲人口最多的城市。
2. Gallus:
2.捷拉斯:
Gallus is in the purple cluster containing a greater number of hotels. It is not far from the city center and has 5 Asian restaurants indicating that there is demand here as well. It has the second-highest population of Asians in the city at 1512. Hence, this seems like a better option than Bockenheim for opening an Asian restaurant owing to lesser competition, similar Asian population, and more prospective customers in the form of tourists.
捷拉斯位于包含大量酒店的紫色集群中。 它距離市中心不遠,有5家亞洲餐廳,表明這里也有需求。 在1512年,它是該市第二大亞裔人口。因此,這似乎比博肯海姆(Bockenheim)開設亞洲餐館更好的選擇,原因是競爭較少,亞洲人口相似,并且游客形式更趨于潛在客戶。
3. Niederrad:
3.尼德拉德:
Niederrad is also in the purple cluster having more hotels. It is also not far from the city center but has only 1 Asian restaurant — much less than both Bockenheim and Gallus. Niederrad also has a sizeable Asian population at 929, although a bit less than the other 2 districts in contention. Since it is in the purple cluster, we can expect more tourists in this district. We see that there are 3 hotels in the area. This translates to more prospective customers. Hence, this also seems like a good alternative to Gallus owing to much lesser competition, proximity to the city center, and more tourists.
尼德拉德(Niederrad)也在紫色集群中,擁有更多的酒店。 它也離市中心不遠,但是只有1家亞洲餐廳-比Bockenheim和Gallus都少得多。 尼德拉德(Niederrad)在929年的亞洲人口也相當可觀,盡管在爭奪中比其他兩個地區要少一些。 由于它位于紫色集群中,因此我們可以期望這個地區有更多游客。 我們發現該地區有3家酒店。 這轉化為更多潛在客戶。 因此,由于競爭少,靠近市中心且游客多,這似乎是捷拉斯的一個不錯的選擇。
結論: (Conclusion:)
The neighborhoods in Frankfurt am Main were clustered and displayed on a map containing the results. The demographics were studied and based on the findings, 3 districts were found to be ideal as a solution to the Business problem of opening an Asian restaurant. The client can choose any of the 3 neighborhoods to open an Asian restaurant, based on their preferences, confidence, and affinity to risk-taking.
美因河畔法蘭克福的社區被聚類并顯示在包含結果的地圖上。 研究了人口統計信息,并根據調查結果,發現了3個地區是解決開設亞洲餐廳的業務問題的理想選擇。 客戶可以根據自己的喜好,信心和對冒險的意愿,選擇3個街區中的任何一個開設亞洲餐廳。
翻譯自: https://medium.com/swlh/clustering-neighborhoods-in-frankfurt-am-main-using-k-means-bb805545fd00
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389349.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389349.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389349.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Pytorch損失函數losses簡介

讀取Mc1000的 唯一 ID 機器號

樣本均值的抽樣分布_抽樣分布樣本均值
)
玩轉ceph性能測試---對象存儲(一)
![[BZOJ 4300]絕世好題](http://pic.xiahunao.cn/[BZOJ 4300]絕世好題)
[BZOJ 4300]絕世好題

因果關系和相關關系 大數據_數據科學中的相關性與因果關系

Pytorch構建模型的3種方法

vue取數據第一個數據_我作為數據科學家的第一個月

Flask-SocketIO 簡單使用指南


Symbol Mc1000 聲音的設置以及播放

/bin/bash^M: 壞的解釋器: 沒有那個文件或目錄

rcp rapido_為什么氣流非常適合Rapido

pandas處理丟失數據與數據導入導出

Mysql5.7開啟遠程

分類結果可視化python_可視化分類結果的另一種方法

算法組合 優化算法_算法交易簡化了風險價值和投資組合優化

Symbol Mc1000 快捷鍵 的 設置 事件 開發

pandas合并concatmerge和plot畫圖
