vue取數據第一個數據
A lot.
很多。
I landed my first job as a Data Scientist at the beginning of August, and like any new job, there’s a lot of information to take in at once.
我于8月初找到了數據科學家的第一份工作,并且像任何新工作一樣,一次有很多信息需要接受。
By documenting and sharing my own thoughts, hopefully those that are aspiring to work as a Data Scientist (or in anything data-related) can find this helpful in the future. Of course, each company and workplace is different, but I’d like to think that these tips can be useful to many people in general.
通過記錄和分享我自己的想法,希望那些希望成為數據科學家(或從事與數據相關的工作)的人將來能對您有所幫助。 當然,每個公司和工作場所都是不同的,但是我想這些技巧通常對許多人有用。
遇見盡可能多的人 (Meet as many people as possible)
This applies to a lot of other roles, but I feel like this is particularly important when working with data.
這也適用于許多其他角色,但是我覺得這在處理數據時特別重要。
The more people you know, the easier it is for you to do your job.
您認識的人越多,就越容易完成工作。
There’s no better time to meet people than at the start where you have the excuse of introducing yourself. By expanding your reach within the company, there’s more potential for you to find the data that you might need for analysis in the future.
沒有比在開始時介紹自己的借口更好的時間與人見面了。 通過擴大公司的業務范圍,您就有更多的潛力來查找將來可能需要進行分析的數據。
This is especially true if the data is not well-managed. Even if your team has a clean and dedicated data warehouse, there’s bound to be a moment where you’ll need something but not be able to find it without the help of someone more familiar with the data than you are.
如果數據管理不當,尤其如此。 即使您的團隊有干凈整潔的數據倉庫,也一定會有一會兒您需要一些東西,但是如果沒有比您更熟悉數據的人的幫助,便無法找到它們。
定期記筆記 (Take notes regularly)

Personally, I think this is a habit that’s worth having throughout your career.
就個人而言,我認為這是一個在整個職業生涯中都值得擁有的習慣。
By regularly taking notes, you’ll have something to refer back to in the future if you forget something — and at the beginning, you will end up forgetting things.
通過定期記筆記,如果您忘記了某些內容,將來您將有一些需要參考的地方–開始時,您最終會忘記一些東西。
Developing this habit early means that you won’t have to awkwardly ask for something in the future when you know you should have remembered it by then.
早日養成這種習慣,意味著當您知道屆時應該已經記住它時,您將來就不必笨拙地要求一些東西。
It’s also a good way to keep track of what people are currently doing or using (e.g. what data do they use etc.) and lets you document the location of things that might potentially be useful to you in the future.
這也是跟蹤人們當前在做什么或正在使用的好方法(例如,他們使用什么數據等),并讓您記錄將來可能對您有用的事物的位置。
Speaking of note-taking, I’d recommend using Notion. It’s served me well during my student days for documenting my own projects and ideas, and has transitioned easily over to my working career.
說到筆記,我建議使用Notion 。 在學生時期記錄自己的項目和想法對我很有幫助,并且可以輕松地過渡到我的工作生涯。
提前集思廣益 (Brainstorm ideas ahead of time)

This follows on from the previous section: start jotting down ideas as you’re getting more familiar with the data — even if they might seem unreasonable for now.
這是從上一節開始的:隨著對數據的熟悉程度的增加,開始記下想法,即使目前看來這些想法并不合理。
There have been times where I’ve had an idea about solving a particular problem but then forget about it later because I didn’t write it down. If you’re finally tasked to solve that same problem, you’d have to spend time coming up with the same idea again!
有時候我對解決一個特定的問題有個主意,但是后來我忘了,因為我沒有寫下來。 如果您最終被要求解決相同的問題,那么您將不得不花費時間再次提出相同的想法!
Documenting your ideas also lets you improve on them over time as you become more familiar with everything. When someone presents to you a new problem to solve, you might already have a good idea on how to solve it, thus making your job easier in the long run.
記錄您的想法還可以使您隨著時間的流逝對它們的熟悉程度不斷提高。 當有人向您提出要解決的新問題時,您可能已經對如何解決有個好主意,從長遠來看,這使您的工作變得更輕松。
不要過于復雜 (Don’t overcomplicate things)
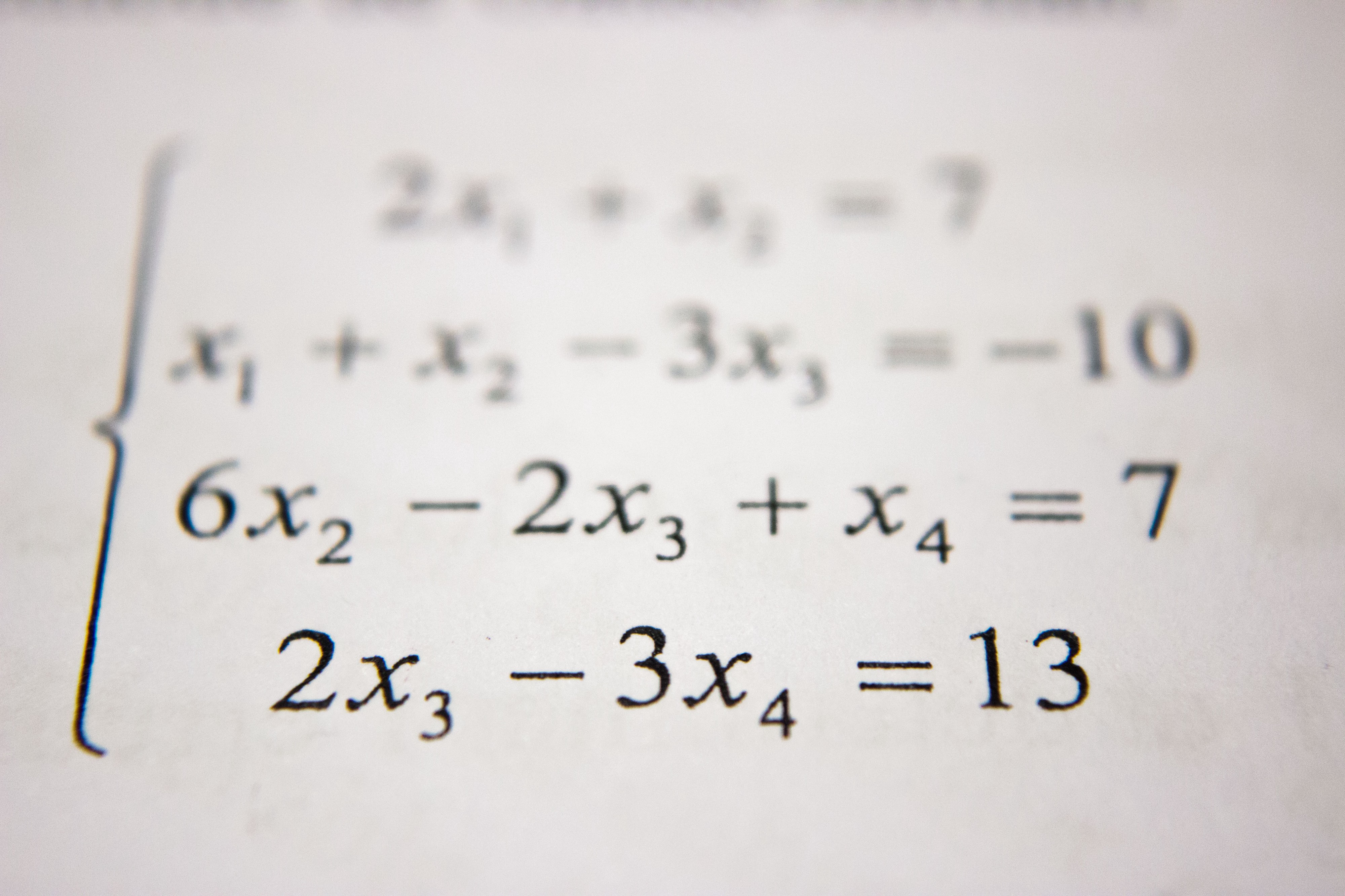
With the hype surrounding machine learning these days, it’s quite easy to fall into the trap of overcomplicating a problem that could be solved with a simple linear or logistic regression.
如今隨著圍繞機器學習的炒作,很容易陷入使問題復雜化的陷阱,而該問題可以通過簡單的線性或邏輯回歸來解決。
In some cases, the required infrastructure for a complex machine learning pipeline might not even be available.
在某些情況下,復雜的機器學習管道所需的基礎架構甚至可能不可用。
Most data science problems are statistical ones that require you to think more like a statistician than a machine learning engineer.
大多數數據科學問題都是統計問題,需要您像統計學家一樣思考而不是機器學習工程師。
That means starting with the usual: What does the distribution of the data look like? What sort of model would best fit this kind of distribution? And if so, does the data satisfy the statistical assumptions of the model? Do I need to remove any data if it doesn’t satisfy my assumptions? (e.g. multicollinearity).
這意味著從通常的情況開始:數據的分布是什么樣的? 哪種模型最適合這種分布? 如果是這樣,數據是否滿足模型的統計假設? 如果數據不符合我的假設,是否需要刪除? (例如多重共線性)。
From here, if it seems reasonable, a machine learning algorithm and/or pipeline could be considered. However, the more complicated the solution becomes, the harder it is to explain and justify your results to the decision makers. Try explaining how neural networks work to a non-mathematical audience, and you’ll find that it’s a very difficult thing to do.
從這里開始,如果看起來合理,則可以考慮使用機器學習算法和/或管道。 但是,解決方案越復雜,就很難向決策者解釋和證明您的結果。 嘗試向非數學對象解釋神經網絡的工作原理,您會發現這是一件非常困難的事情。
If it provides actionable insight and the evidence can be communicated clearly to the audience, then I think that’s a job well done.
如果它提供了可行的見解并且可以將證據清楚地傳達給聽眾,那么我認為這是一項出色的工作。
不要為解決一切感到壓力 (Don’t feel pressured to solve everything)

Although we’re hired to solve problems, there will always be times where it simply isn’t possible to go any further. It could be due to a lack of (usable) data, or that the solution takes too long to implement.
盡管我們被雇用來解決問題,但總有一些時候根本無法進一步解決問題。 可能是由于缺少(可用)數據,或者解決方案實施時間過長。
Whatever the reason is, it’s sometimes better to put it in the backburner and move on to something that can be solved. Most of the time, completing a single task is better than not completing any tasks at all.
不管是什么原因,有時最好將其放回爐中,然后繼續進行可以解決的問題。 在大多數情況下,完成一項任務比根本不完成任何任務要好。
最后-犯錯誤并從中學到快樂! (And lastly — make mistakes and have fun learning!)

Imposter syndrome is real, and it can sometimes feel a bit overwhelming when expectations are high.
冒名頂替綜合癥是真實的,當期望值很高時,有時會感到有些不知所措。
Don’t be afraid to make mistakes, especially at the beginning of your career. Instead, focus on making fewer mistakes over time. It’s only natural that as you progress, fewer and fewer mistakes will be tolerated, so make the most of it at the beginning where you have an excuse to.
不要害怕犯錯誤,尤其是在您的職業生涯初期。 相反,應著重于隨著時間的流逝減少錯誤。 很自然,隨著您的進步,越來越少的錯誤會被容忍,因此在您有借口的一開始就充分利用它。
And finally —you might feel like you should know how to solve every problem and provide amazing insights at the beginning; however, now’s the perfect opportunity to learn more about the industry instead.
最后,您可能會覺得自己應該知道如何解決每個問題并在一開始就提供驚人的見解; 但是,現在是了解該行業的絕佳機會。
Take the time to explore how certain data science techniques could be applied to solving your own business problems. I’ve noticed that I’m more motivated to read and explore other potential solutions since I now have a good reason to. The biggest motivator for me though, is realising that after all these years of hard studying, I’m finally getting paid for it!
花時間探索如何將某些數據科學技術應用于解決您自己的業務問題。 我注意到,由于我現在有充分的理由,因此我更加有動力去閱讀和探索其他潛在的解決方案。 但是,對我而言,最大的動力是意識到經過多年的努力學習,我終于為此獲得了報酬!
翻譯自: https://towardsdatascience.com/my-first-month-as-a-data-scientist-454b44aaef91
vue取數據第一個數據
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389341.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389341.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389341.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Flask-SocketIO 簡單使用指南


Symbol Mc1000 聲音的設置以及播放

/bin/bash^M: 壞的解釋器: 沒有那個文件或目錄

rcp rapido_為什么氣流非常適合Rapido

pandas處理丟失數據與數據導入導出

Mysql5.7開啟遠程

分類結果可視化python_可視化分類結果的另一種方法

算法組合 優化算法_算法交易簡化了風險價值和投資組合優化

Symbol Mc1000 快捷鍵 的 設置 事件 開發

pandas合并concatmerge和plot畫圖

Android跳轉WIFI界面的四種方式

PS摳發絲技巧 「選擇并遮住…」

covid 19如何重塑美國科技公司的工作文化

Symbol Mc1000 Text文本閱讀器整體代碼

python生日悖論分析_生日悖論

統計0-n數字中出現k的次數

房價預測 search Search 中對數據預處理的學習

3.6.1.非阻塞IO
