深度學習數據更換背景
數據科學教育 (DATA SCIENCE EDUCATION)
目錄 (Table of Contents)
The Importance of Context Knowledge
情境知識的重要性
(Optional) Research Supporting Context-Based Learning
(可選)研究支持基于上下文的學習
The Context of Data Science
數據科學的背景
Understand the Concept, not the Calculation
了解概念,而不是計算
The Context of the Sub-Disciplines
子學科的背景
Next Steps
下一步
情境知識的重要性 (The Importance of Context Knowledge)
I made the decision to orient my career path towards data science during my senior year of university. It only took one or two research-binges before I realized the vast depth of the field in front of me. I knew eventually I’d have to understand things like the architecture of a convolutional neural network, the process of numericalization for NLP, or the underpinnings of principal component analysis. However, rather than jumping into the minutiae of these concepts in a void, I’ve always needed to develop a rock-solid contextual foundation of knowledge first. I’ll call this approach context-based learning.
我決定在大學四年級時將自己的職業道路轉向數據科學。 在我意識到眼前的廣闊領域之前,只花了一兩個研究便步。 我知道最終我將必須了解卷積神經網絡的體系結構,NLP的數字化過程或主成分分析的基礎。 但是,我始終沒有首先跳入這些概念的細微之處,而是始終首先開發了堅實的知識上下文基礎。 我將這種方法稱為基于上下文的學習 。
什么是基于上下文的學習? (What is context-based learning?)
I will loosely define context-based learning as learning a concept by first focusing on its contextual elements. In other words, understanding the big picture before delving into the deep theory. It’s important to emphasize “first” in that definition, as learning the context is analogous to building the chassis of a vehicle. Although the chassis is an essential element, it is not a car, and is non-functional on its own. Rather, it is the bedrock from which the car is built. In the same way, a contextual framework is the bedrock from which technical content is laid on top of.
我將寬松地將基于上下文的學習定義為通過首先關注其上下文元素來學習概念 。 換句話說,在深入研究深度理論之前先了解全局。 重要的是要在該定義中強調“第一”,因為學習上下文類似于構建車輛底盤。 盡管底盤是必不可少的元素,但它不是汽車,并且無法單獨發揮作用。 相反,它是制造汽車的基石。 同樣,上下文框架是基礎,技術內容是基礎。
(可選)研究支持基于上下文的學習 ((Optional) Research Supporting Context-Based Learning)
This style of learning leverages a fact well supported by research in the psychology of learning — humans retain knowledge most effectively by associating them to something they have a firm grasp on rather than memorizing new concepts in a void. In short, we learn by association.
這種學習方式充分利用了學習心理學方面的研究支持的事實-人類通過將知識與他們牢牢掌握的東西聯系起來而不是在空虛中記住新概念,從而最有效地保留了知識。 簡而言之, 我們通過聯想學習。
The late educational psychology professor Dr. Barak Rosenshine at the University of Illinois emphasized the importance of these contextual frameworks in education in Principles of Instruction:
伊利諾伊大學的已故教育心理學教授Barak Rosenshine博士在《教學原理》中強調了這些情境框架在教育中的重要性:
“When one’s knowledge on a particular topic is large and well-connected, it is easier to learn new information and prior knowledge is more readily available for use.”
“當一個人對某個特定主題的知識廣博且聯系緊密時,它就更容易學習新信息,并且現有知識也更易于使用。”
The amount of background knowledge you have is also correlated to how well you comprehend new material. Therefore, to learn most efficiently, one must develop a strong foundation of background knowledge prior to delving into the details.
您所擁有的背景知識的數量也與您對新材料的理解程度有關 。 因此,為了最有效地學習,在深入研究細節之前,必須先建立扎實的背景知識基礎。
數據科學的背景 (The Context of Data Science)
So what is the background knowledge, or context, of data science? Well, I always begin context-based learning by asking a lot of questions. Specifically, I try to ask broad, conceptual questions, as opposed to detail-oriented ones.
那么,數據科學的背景知識或背景是什么? 好吧,我總是通過問很多問題來開始基于上下文的學習。 具體來說,我嘗試提出廣泛的概念性問題 ,而不是注重細節的問題。
The following is a handful of questions I first asked myself at the beginning of my data science journey, as well as the answers I provided. I want to emphasize that my answers fulfilled my context gaps of knowledge at the time. In the same way, you should answer these and other questions in a manner that relates to your educational and personal background directly.
以下是我在數據科學之旅開始時首先問自己的幾個問題,以及我提供的答案。 我想強調的是,我的答案彌補了我當時在知識方面的空白。 同樣,您應該以與您的教育和個人背景直接相關的方式回答這些問題和其他問題。
數據科學如何適應我對其他領域的理解? (How does data science fit into my understanding of other fields?)
Data science is an interdisciplinary field that leverages math, programming, business, and domain knowledge to tackle difficult data problems. The overlap between data science and my major (cognitive science with machine learning & neural computation) rests on math (which is necessary for machine learning), programming (which provides computational functionality for the field as a whole), as well as data analysis techniques, such as those used in computational neuroscience. The “science” in data science comes from its use of various scientific methodologies, such as statistical significance.
數據科學是一個跨學科領域,它利用數學,編程,業務和領域知識來解決棘手的數據問題。 數據科學與我的專業(具有機器學習和神經計算的認知科學)之間的重疊在于數學(機器學習必需的),編程(為整個領域提供計算功能)以及數據分析技術,例如計算神經科學中使用的那些。 數據科學中的“科學”來自對各種科學方法的使用,例如統計意義。
數據科學中最重要的元素是什么,它們如何相互聯系? (What are the most important elements of data science, and how do they relate to one another?)
All data scientists go through a process known as the “data science pipeline”, essentially a step-by-step, end-to-end process outlining the workflow of a data scientist. Acronyms like OSEMN make the basic pipeline easy to remember, but generally, pipelines vary in their subtleties. The basic structure is as follows:
所有數據科學家都要經歷一個稱為“數據科學管道”的過程,該過程本質上是一個循序漸進的,端到端的過程,概述了數據科學家的工作流程。 OSEMN等首字母縮寫詞使基本管道易于記憶,但是通常,管道的細微之處有所不同。 基本結構如下:
- Data Collection 數據采集
- Data Cleaning 數據清理
- Exploratory Data Analysis 探索性數據分析
- Model Building 建筑模型
- Visualization/ Model Deployment 可視化/模型部署
什么是機器學習? 為何機器學習與數據科學如此緊密地聯系在一起? (What is machine learning? And why is machine learning so tied to data science specifically?)
Machine learning (ML) is a field that studies computer science algorithms that are not traditional “closed” algorithms. Instead, ML algorithms “learn” from data. This reliance on data is what makes ML so integral to data science. ML is in the “model building” and “model deployment” category of the data science pipeline.
機器學習(ML)是研究不是傳統的“封閉式”算法的計算機科學算法的領域。 相反,機器學習算法從數據中“學習”。 這種對數據的依賴使ML成為數據科學不可或缺的一部分。 ML屬于數據科學管道的“模型構建”和“模型部署”類別。
數據科學的子學科是什么? (What are the sub-disciplines of data science?)
There are many fields that contribute to data science, but the most fundamental disciplines that make up data science are computer science, statistics, machine learning, and linear algebra. Although business and domain knowledge are also critical, the academic scope of data science relies on the original sub-disciplines mentioned. Furthermore, the sub-disciplines themselves often have their own sub-disciplines, such as calculus being necessary to understand how machine learning algorithms work.
數據科學有很多領域,但構成數據科學的最基本學科是計算機科學,統計學,機器學習和線性代數。 盡管業務和領域知識也很關鍵,但是數據科學的學術范圍取決于所提到的原始子學科。 此外,子學科本身通常也具有自己的子學科,例如微積分對于理解機器學習算法的工作方式是必不可少的。
了解概念,而不是計算 (Understand the Concept, not the Calculation)
One important dichotomy I discovered early on during my undergrad math studies was the distinction between calculations and conceptual understanding. For example, in the case of statistics, memorizing how to calculate this
我在本科數學學習初期發現的一個重要二分法是計算與概念理解之間的區別。 例如,對于統計數據,請記住如何計算
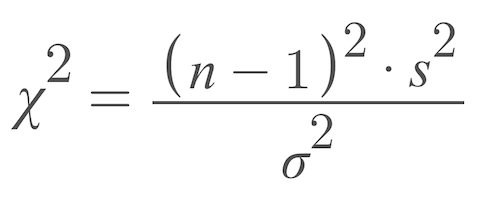
is far less important than understanding the use case of a chi-square test statistic in testing hypotheses between categorical variables. Or, for calculus, understanding that this
在理解分類變量之間的假設時,遠不如了解卡方檢驗統計量的用例重要。 或者,對于微積分,請理解
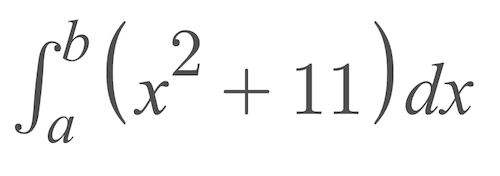
describes an area underneath a quadratic curve is far more important than memorizing fancy methods to solve it by hand. (*ahem*)
描述二次曲線下方的區域遠比記憶花哨的方法來手工解決它重要得多。 (*啊*)
I actually find building programs to be an incredibly accurate analogy of this. When learning to program, it is evidently clear early on that trying to learn every implementation of every function is impossible. A much more efficient strategy is to understand the inputs and outputs so that you may piece together snippets of code to make things work.
我實際上發現構建程序可以非常精確地類比。 在學習編程時,很顯然很早就開始嘗試學習每個功能的每個實現都是不可能的。 一種更有效的策略是理解輸入和輸出,以便您可以拼湊代碼片段以使事情正常進行。
Even in the cases you don’t google or use StackOverflow, courses like fastai abstract the vast majority of implementation away so that you may build an end-to-end framework of understanding first (in fastai’s case, build an end-to-end model), and only after do you go back to try to understand the fundamental details that underlie the abstractions.
即使在您不使用Google或不使用StackOverflow的情況下,諸如fastai之類的課程也將絕大多數實現抽象化了,以便您可以構建首先了解的端到端框架(在fastai的情況下,構建端到端模型),并做之后,才回去試著去了解背后的抽象的基本細節。
In this way, learning the concepts as opposed to the calculations is an application of context-based learning, as the contextual framework is built up so that when you do need to learn the calculations, they are compartmentalized properly.
通過這種方式,學習與計算相反的概念是基于上下文的學習的一種應用,因為構建了上下文框架,因此當您確實需要學習計算時,可以將它們適當地分隔開。
子學科的背景 (The Context of the Sub-Disciplines)
Following the context-based learning approach, once we have figured out the sub-disciplines of data science, we should dig into their context to understand how they fit in with the overall scope of the field.
遵循基于上下文的學習方法,一旦我們弄清了數據科學的子學科,就應該深入研究它們的上下文,以了解它們如何適合該領域的整體范圍。
計算機科學 (Computer Science)
Why are all data science projects so coding-heavy?
為什么所有數據科學項目都如此繁重的編碼?
Modern statistics dates back to the 19th century, yet the application of statistics was confined to small samples as there was no efficient means of organizing large amounts of data and calculating parameters. The computer was that means.
現代統計可以追溯到19世紀,但由于沒有有效的方法來組織大量數據和計算參數,因此統計的應用僅限于小樣本。 電腦就是那個意思。
Furthermore, the advent of GPU parallel processing enabled machine learning models to train hundreds of times faster. In essence, incredibly powerful tools for statistics became accessible via the computer, thus the heavy emphasis on coding.
此外,GPU并行處理的出現使機器學習模型的訓練速度提高了數百倍。 從本質上講,非常強大的統計工具可以通過計算機訪問,因此非常重視編碼。
FURTHER Qs: What programming languages are the most important for data science? How much programming do I need for data science?
問:哪些編程語言對數據科學最重要? 數據科學需要多少編程?
統計 (Statistics)
Why is statistics important for data science?
為什么統計對于數據科學很重要?
Given that most of data science is simply computational statistics, this field lays out the groundwork and toolset for rigorous mathematical analysis of data.
鑒于大多數數據科學僅僅是計算統計,因此該領域為嚴格的數據數學分析奠定了基礎和工具集。
FURTHER Qs: Just what the hell is all this talk about Bayes? What specific statistics libraries do data scientists use?
問:問題 到底是關于貝葉斯的? 數據科學家使用哪些特定的統計庫?
線性代數 (Linear algebra)
What is linear algebra and how does it relate to data science?
什么是線性代數,它與數據科學有什么關系?
Linear algebra is simply the study of linear equations. Multiple linear equations stacked together can be expressed as a matrix. Matrices, collections of numbers in rows and columns, are essentially equivalent to tabular data (data in a table). Moreover, image data is nothing but an n-dimensional vector of tuples (i.e. a list of a list of numbers). This is why a good understanding of linear algebra provides an understanding of the structure of data itself.
線性代數只是線性方程的研究。 堆疊在一起的多個線性方程式可以表示為矩陣。 矩陣,即行和列中的數字的集合,基本上等效于表格數據(表格中的數據)。 此外,圖像數據不過是元組的n維向量(即,數字列表的列表)。 這就是為什么很好地理解線性代數可以理解數據本身的結構的原因。
FURTHER Qs: What is a tensor? How is linear algebra used in deep learning?
問:什么是張量? 線性代數如何在深度學習中使用?
機器學習與微積分 (Machine Learning & Calculus)
What is the link between calculus and machine learning?
微積分與機器學習之間的聯系是什么?
A critical component of calculus is the study of optimization. Since the objective of all machine learning algorithms is to minimize an error function, calculus provides the tools to understand how that minimization occurs.
微積分的重要組成部分是優化研究。 由于所有機器學習算法的目標都是最小化誤差函數,因此演算提供了了解最小化如何發生的工具。
FURTHER Qs: What is gradient descent? What is back-propagation? Why is calculus involved in it?
問 : 什么是梯度下降? 什么是反向傳播? 為什么微積分參與其中?
下一步 (Next Steps)
Ask yourself conceptual questions. Lots of conceptual questions. These questions will vary for everyone as their aim should be to patch the gaps of knowledge for how data science fits into your overall understanding of the field.
問自己概念上的問題。 很多概念性問題。 這些問題對于每個人都會有所不同,因為他們的目標應該是彌補知識差距,以了解數據科學如何適合您對該領域的整體理解。
Get creative. A colleague of mine mentioned that visualization maps really helped her understand the context of AI, machine learning, and deep learning and how they all fit together. Similarly, use maps and flowcharts to understand any topics in data science you’re currently struggling to piece together.
發揮創意。 我的一位同事提到,可視化地圖確實幫助她了解了AI,機器學習和深度學習的上下文以及它們如何融合在一起。 同樣,使用地圖和流程圖了解您目前正在拼湊的數據科學中的任何主題。
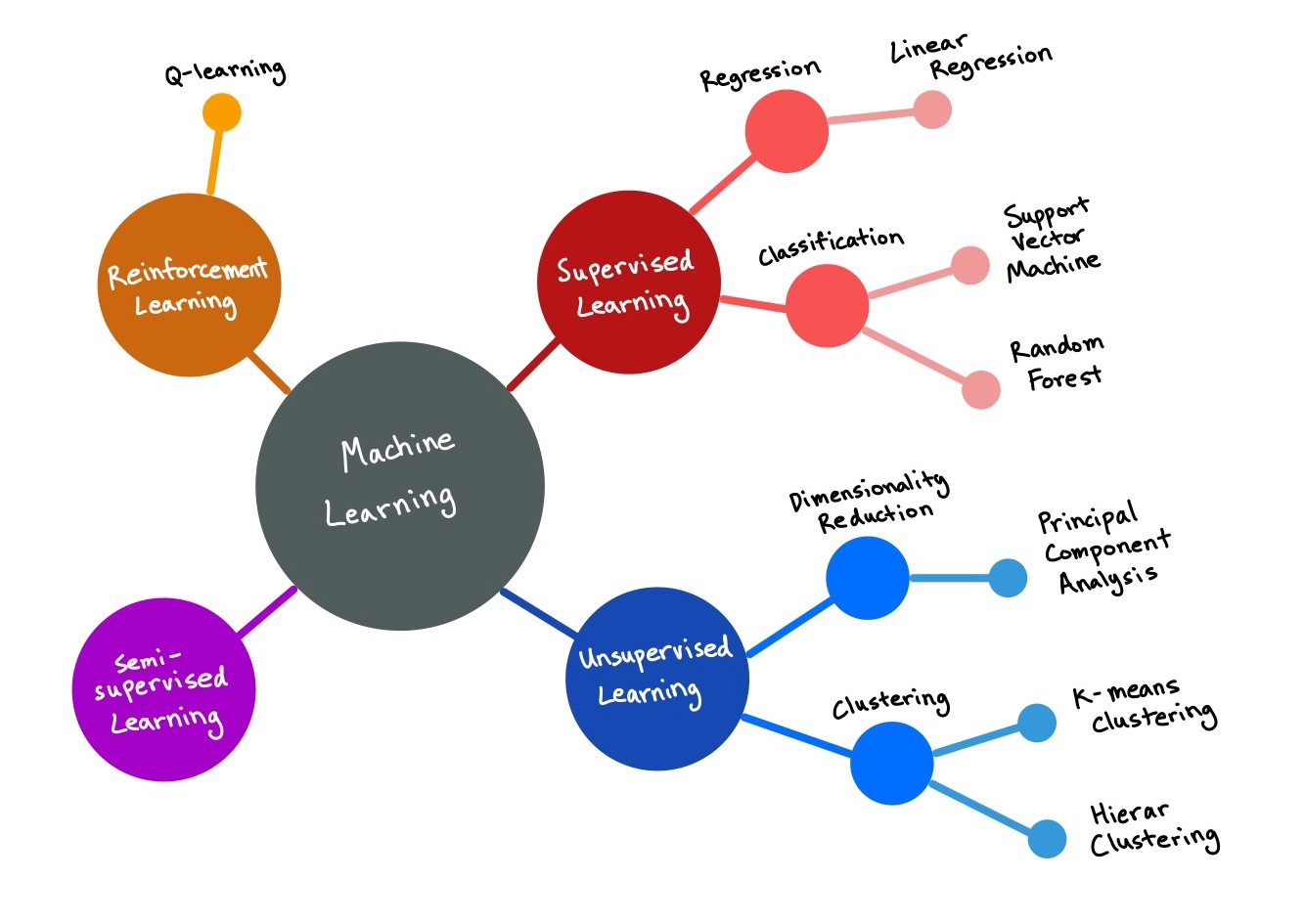
After you’re armed with a strong contextual understanding of data science, go ahead and dig deep into the nuances of various supervised algorithms, the best practices for data preprocessing, or the creation of beautiful dashboard visualizations with Tableau.
在對數據科學有很強的上下文理解能力之后,繼續深入研究各種監督算法的細微差別,數據預處理的最佳實踐或使用Tableau創建漂亮的儀表板可視化效果。
Just try to make sure every new concept is put into context along the way.
只是嘗試確保在此過程中將每個新概念都放在上下文中。
翻譯自: https://towardsdatascience.com/the-best-way-to-start-learning-data-science-is-to-understand-its-context-751e917e655e
深度學習數據更換背景
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389304.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389304.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389304.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

熊貓數據集_用熊貓掌握數據聚合

IOS CALayer的屬性和使用

GridView詳解

訪問模型參數,初始化模型參數,共享模型參數方法

QZEZ第一屆“飯吉圓”杯程序設計競賽

談談數據分析 caoz_讓我們談談開放數據…

數據創造價值_展示數據并創造價值

Java入門系列-22-IO流


卷積神經網絡——各種網絡的簡潔介紹和實現

數據中臺是下一代大數據_全棧數據科學:下一代數據科學家群體

net如何判斷瀏覽器的類別




北方工業大學gpa計算_北方大學聯盟倉庫的探索性分析
)
泰坦尼克數據集預測分析_探索性數據分析-泰坦尼克號數據集案例研究(第二部分)


