卡爾曼濾波濾波方程
Before getting into what a Kalman filter is or what it does, let’s first do an exercise. Open the google maps application on your phone and check your device’s current location.
在了解什么是卡爾曼濾波器或其功能之前,我們先做一個練習。 在手機上打開Goog??le Maps應用程序,然后檢查設備的當前位置。
Did you check it? How accurately is it able to pinpoint your location? Quite accurately isn’t it. The errors from your actual location might range from 2m to 20m depending on the quality of the GPS or whether you are indoors or outdoors but still, it did a pretty good job. In fact, it did a great job considering the fact that earth is so huge and it’s able to pinpoint your location, with a small error radius which is represented by a circle around the point.
你檢查了嗎? 能夠精確定位您的位置嗎? 完全是不是。 根據GPS的質量,或者您是在室內還是室外,實際位置的誤差范圍可能在2m至20m之間,但這仍然做得很好。 實際上,考慮到地球是如此之大,它能夠以較小的誤差半徑(通過圍繞該點的圓圈表示)來精確定位您的位置,因此,它做得很好。
But now let’s say you install a GPS on your car and you are told to remote control it from your house, given the feed from the GPS. Would you be able to navigate your car through the streets? Your answer would be definitely no. Even though the GPS is able to pinpoint the location of your car with decent accuracy, the error in measurements can range from 2 to 3 meters which makes it impossible to drive with no other feed. This is where the field of localization comes in. Localization is the task of reducing the error in the position of our vehicle to cm level accuracy.
但是,現在讓我們假設您在汽車上安裝了GPS,然后根據GPS的提示,您被告知要在家中對其進行遙控。 您能在街上開車嗎? 您的答案肯定不會。 即使GPS能夠精確定位您的汽車位置,但測量誤差可能會在2至3米的范圍內,這使得沒有其他飼料就無法駕駛。 這就是本地化的領域。本地化是將我們的車輛位置誤差降低到厘米級精度的任務。

Now to do this, instead of just relying on our GPS, we install other instruments such as IMU, camera, lidar, and radar to our vehicle and use the additional information to get a better understanding of the environment.
現在,不僅要依靠我們的GPS,還需要在車輛上安裝其他儀器,例如IMU,攝像頭,激光雷達和雷達,并使用其他信息來更好地了解環境。
Ok, so now we have a much detailed sense of the environment and, if now the task is given to you, you’ll probably feel more confident in being able to navigate the car through the streets with just the device feeds. At Least the less crowded ones. But what if this task is given to a computer? Humans are quite good at recognizing patterns without much effort but, for a computer, it still needs to process the information, and factors like measurement error, measurement noise, process error, and delays add further complexity. Here’s where Kalman filter comes in.
好的,現在我們對環境有了更詳盡的了解,如果現在將任務交給您,您可能會感到更加自信,能夠僅使用設備提要在街上駕駛汽車。 至少不那么擁擠。 但是,如果將此任務交給計算機怎么辦? 人類非常擅長于識別模式,而無需花費太多精力,但對于計算機而言,它仍然需要處理信息,并且諸如測量誤差,測量噪聲,過程誤差和延遲之類的因素會進一步增加復雜性。 這就是卡爾曼濾波器的作用。
Kalman filter is an algorithm, named after Rudolf E. Kálmán, one of the primary developers of this theory, which is extensively used for many applications. A common application is for Guidance, Navigation, and Control of Vehicles.
卡爾曼濾波器是一種算法,以該理論的主要開發者之一Rudolf E.Kálmán命名,已廣泛用于許多應用程序。 常見的應用是車輛的制導,導航和控制。
Kalman filters are based on the theory of Bayesian probabilities. There are typically two steps in the Kalman filter: Predict and Update.
卡爾曼濾波器基于貝葉斯概率理論。 卡爾曼濾波器通常有兩個步驟: Predict和Update 。
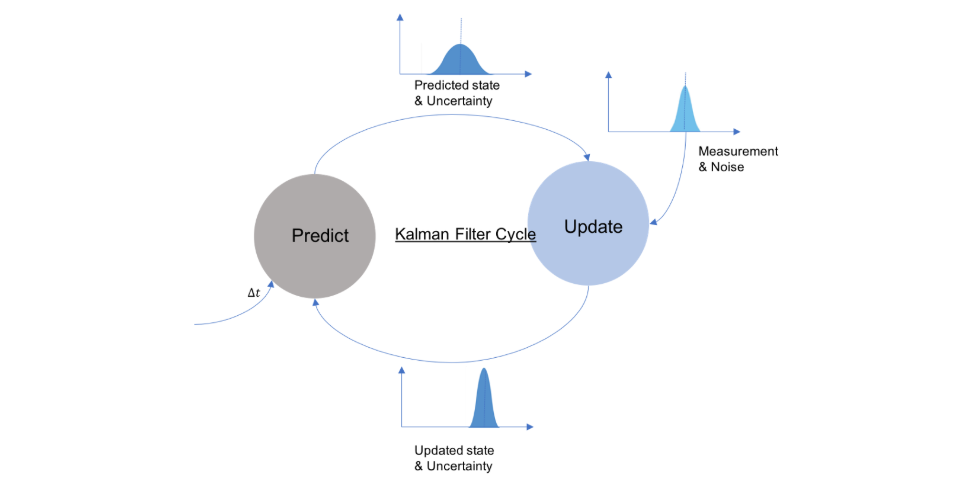
To understand what each of the steps does, we first define something called the State of the vehicle. The state represents a collection of measurements that we would like to describe our vehicle with. It can be a combination of anything from, position, velocity, lateral acceleration, yaw, yaw rate, and many more. Let’s take a simple example of a car that can only move along the x-axis with only the position as part of the state. We start with a good guess for the state of the vehicle.
為了了解每個步驟的作用,我們首先定義一個稱為“車輛狀態 ”的內容。 狀態代表我們要用來描述車輛的測量值的集合。 它可以是位置,速度,橫向加速度,偏航,偏航率等等中任何一項的組合。 讓我們舉一個簡單的汽車示例,該汽車只能沿x軸移動,而位置僅是狀態的一部分。 我們首先對車輛的狀態進行猜測。
Let’s start with position 0 m. We assume a constant velocity model i.e., we will not consider the effect of acceleration to our vehicle’s position estimate.
讓我們從位置0 m開始。 我們假設一個恒定速度模型,即,我們將不考慮加速度對我們的車輛位置估計的影響。
Now we bump up the velocity of our vehicle to 1 m/s. Remember that we have assumed a constant velocity model, so we will not consider the acceleration in between. Where do you expect the vehicle to be after 1second has elapsed? You probably answered it correctly. The answer is at 1m. The velocity of the vehicle is 1 m/s and according to distance = velocity * time, we get distance as 1m.
現在,我們將車輛的速度提高到1 m / s。 請記住,我們假設了一個恒定速度模型,因此我們將不考慮兩者之間的加速度。 您希望車輛經過1秒后會在哪里? 您可能回答正確。 答案是1m。 車輛的速度為1 m / s,根據距離=速度*時間,我們得出距離為1m。
Now, can you predict the position after 2 more seconds have elapsed with the same velocity? The answer is 3m. Easy, right? Given the velocity of the vehicle at all times, you were able to predict the position of the vehicle. If we were able to predict the position of the vehicle without any hustle, why do we need Kalman filter?
現在,您能以相同的速度經過2秒后預測位置嗎? 答案是3m。 容易吧? 給定車輛始終的速度,您就可以預測車輛的位置。 如果我們能夠毫無障礙地預測車輛的位置,為什么我們需要卡爾曼濾波器?
The truth is, we wouldn’t have needed Kalman filters if we could have been 100% sure of all our measurements. But in reality, no measurement is perfect. So the place where we assume our velocity to be 1 m/s may not be 100% accurate. It may be 0.9 m/s or 1.1 m/s or something else, we aren’t sure. There is always some margin for error. Now, what will happen to our position estimate? Because there is an error term in velocity, there will also be an associated error term for the position estimate as well. As the vehicle moves with time, we can propagate the state of the vehicle along with it’s associated error term. This is the prediction step of the Kalman filter.
事實是,如果我們可以100%確信所有測量結果,就不需要卡爾曼濾波器。 但實際上,沒有任何測量是完美的。 因此,我們假設速度為1 m / s的地方可能不是100%準確的。 我們不確定這可能是0.9 m / s或1.1 m / s或其他。 總會有一些誤差。 現在,我們的職位估計會怎樣? 由于速度中存在誤差項,因此位置估計也將具有關聯的誤差項。 隨著車輛隨時間移動,我們可以傳播車輛狀態及其相關的誤差項。 這是卡爾曼濾波器的預測步驟。
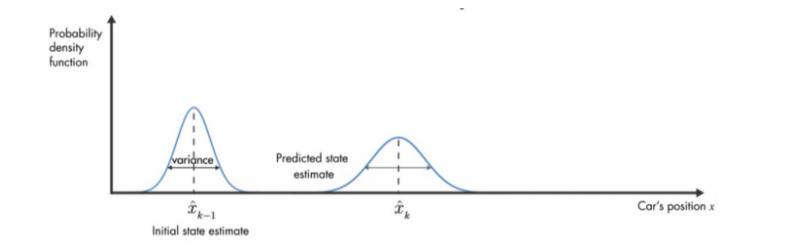
Now the prediction step alone cannot solve the problem of localization as the errors will keep accumulating with time, degrading our position estimate. Our estimates degrade with time because no new information is collected while the car is moving and hence some information is lost during each propagation step. This is evident from the image above where the probability distribution of position estimate gets wider as it moves ahead. And, if this is continued, the probability distribution of the vehicle position will tend to uniform distribution.
現在,僅憑預測步驟就無法解決定位問題,因為誤差會隨著時間的推移而不斷累積,從而降低了我們的位置估算值。 我們的估計會隨著時間的推移而降低,因為在汽車行駛時沒有收集到任何新信息,因此在每個傳播步驟中都會丟失一些信息。 從上圖可以清楚地看出,位置估計的概率分布隨著向前移動而變寬。 并且,如果繼續這樣,則車輛位置的概率分布將趨于均勻分布。
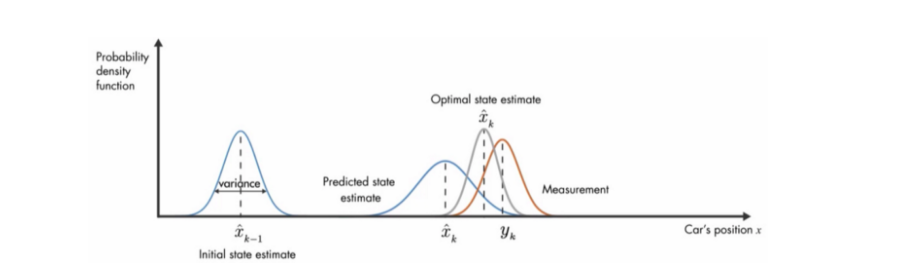
The Update step solves this problem. Let’s say we have a GPS installed on our vehicle which tells us our position every 2 seconds. So after every 2 seconds, using this new information, we can update the state of the vehicle based on the measurements and previous belief of the state. The update step makes sure that the errors don’t keep accumulating with time.
更新步驟解決了此問題。 假設我們在車輛上安裝了GPS,每2秒就會告訴我們我們的位置。 因此,每隔2秒鐘,使用此新信息,我們就可以基于測量結果和狀態的先前信念來更新車輛的狀態。 更新步驟可確保錯誤不會隨著時間累積。
卡爾曼濾波方程 (Kalman Filter equations)
Cool, if you have understood everything, you have got a good grasp of what Kalman filters are, and how they work. So, let’s see how all this is implemented in mathematical equations.
太好了,如果您了解了所有內容,那么您將對Kalman過濾器及其工作原理有很好的了解。 因此,讓我們看看如何在數學方程式中實現所有這些功能。
Predict:
預測:

Update:
更新:

Did I suddenly confuse you with all the equations? Don’t worry, even I felt the same way when I had faced these equations for the first time. Instead of getting too deep into the linear algebra that is making this possible, we will try to understand the essence of each equation. You can still follow the equations without getting into the derivation of the advanced linear algebra concepts.
我突然把所有方程式弄糊涂了嗎? 不用擔心,即使是我第一次面對這些方程式時,也有同樣的感覺。 我們將不會試圖深入了解每個方程式的實質,而不必太過深入地研究線性代數使之成為可能。 您仍然可以遵循這些方程式,而無需進行高級線性代數概念的推導。
Consider an example of a car initially at position 0. We measure its position every Δt seconds and we keep track of the car’s position and velocity along the x- dimension.
考慮一個最初在位置0處的汽車的示例。我們每隔Δt秒測量一次它的位置,并沿x維度跟蹤汽車的位置和速度。
步驟1 :(預測) (Step 1: (Predict))
1.1 Propagation of State:
1.1國家的傳播:


As we are describing our car using position and velocity, these quantities will be part of the car’s state. x is the position and ? is the derivative of position wrt to time which is velocity.
當我們使用位置和速度描述汽車時,這些量將成為汽車狀態的一部分。 x是位置, ?是位置wrt對時間的導數,即速度。

Control inputs represent the collection of external parameters that are used to control the car. In our case, we consider lateral acceleration ‘a’ as an input.
控制輸入??代表用于控制汽車的外部參數的集合。 在我們的案例中,我們將橫向加速度“ a”視為輸入。

The state-transition model describes how the car’s state propagates in the time, given the state of the previous time step. The propagation of state is governed by the two equations below:
狀態轉換模型描述了給定上一個時間步長的狀態下汽車狀態在時間中的傳播方式。 狀態的傳播受以下兩個方程式控制:

The multiplication F(k) X(k-1) is translated by the above equations. Here the subscript k of F has no significance because F does not vary with time.
乘積F(k)X(k-1)由上述方程式轉換。 在此, F的下標k不重要,因為F不會隨時間變化。

The control-input model is a matrix that defines the effect of control-inputs on the car’s state. For only lateral acceleration as the input, its effect on the state parameters are as follows:
控制輸入??模型是一個矩陣,用于定義控制輸入對汽車狀態的影響。 僅將橫向加速度作為輸入,它對狀態參數的影響如下:

The equations above are what you will get on the multiplication B(k) u(k). Similar to F, the subscript k of B also does not have any significance as B is also constant throughout.
上面的等式是乘法B(k)u(k)的結果 。 與F相似, B的下標k也沒有任何意義,因為B始終是恒定的。
You might wonder what the hat in X? (k|k-1) means? In linear algebra to represent an estimate of a variable, we put a hat over the variable. As we can only estimate the state of the car is, the hat represents that it is an estimate of the state.
您可能想知道X?(k | k-1)中的帽子是什么意思? 在線性代數中,代表變量的估計,我們在變量上加了一個帽子。 因為我們只能估計汽車的狀態,所以帽子代表它是狀態的估計。
1.2 Propagation of Estimate Covariance Matrix:
1.2估計協方差矩陣的傳播:

P(k) represents the estimate covariance matrix of the uncertainty in the state parameters i.e. position and velocity. It keeps track of the errors associated with our state. The subscript k|k-1 represents the estimate covariance at time step k given the estimate covariance at time step k-1. It is initialized with some prior variance.
P(k)表示狀態參數(即位置和速度)中不確定性的估計協方差矩陣。 它跟蹤與我們的狀態相關的錯誤。 下標k | k-1表示給定時間步長k-1的估計協方差時,時間步長k的估計協方差。 初始化時有一些先驗差異。

Because we have two parameters in our state, the estimate covariance matrix is 2 x 2 matrix. We initialize the matrix based on our initial beliefs of the uncertainty in position and velocity. These values occupy the major diagonal of the matrix in the same order as that of the order in the state. When there is no measurement available, the estimate covariance matrix is propagated based on the state-transition model F with Q as the process noise. Q is calculated as follows:
因為我們在狀態中有兩個參數,所以估計協方差矩陣為2 x 2矩陣。 我們基于對位置和速度不確定性的最初信念初始化矩陣。 這些值以與狀態中順序相同的順序占據矩陣的主要對角線。 當沒有可用的度量時,基于狀態轉換模型F傳播估計協方差矩陣,其中Q為過程噪聲。 Q計算如下:
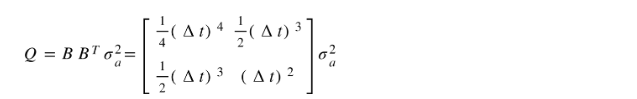
Keep in mind the uncertainty of the state parameters will increase in this step because of the propagation step.
請記住,由于傳播步驟,狀態參數的不確定性將在此步驟中增加。
步驟2 :(更新) (Step 2: (Update))
2.1 Measurement:
2.1測量

Measurement step also known as the Innovation step is the step where we gain information from the instruments installed on the car. This is a crucial step as, without any external information, the car is as good as blind.
測量步驟也稱為創新步驟,是我們從汽車上安裝的儀器中獲取信息的步驟。 這是至關重要的一步,因為在沒有任何外部信息的情況下,汽車就像盲人一樣好。
In our case, we will assume a GPS-like system on our car, that can tell the position of the car periodically.
在我們的案例中,我們將在汽車上假設一個類似GPS的系統,該系統可以定期告訴汽車位置。
You can call the observation model a matrix, that transforms our state to the format of that of the measurement matrix z(k). In our case, we only use GPS to measure the position so,
您可以將觀測模型稱為矩陣,該矩陣將我們的狀態轉換為測量矩陣z(k)的格式。 在我們的案例中,我們僅使用GPS來測量位置,

Hence, the observation model in our case will be:
因此,在我們的案例中,觀察模型將是:

Again, we can drop the subscript k as it is time-invariant. On multiplying observation model with the state, we get:
同樣,我們可以刪除下標k,因為它是時不變的。 通過將觀察模型與狀態相乘,我們得到:

We now have our state transformed into the format of measurement. So for this step, we calculate the residual ?(k) which is observed measurement minus calculated measurement.
現在,我們將狀態轉換為度量格式。 因此,對于這一步,我們計算觀察到的測量值減去計算出的測量值后的殘差?(k) 。
2.2 Kalman gain:
2.2卡爾曼增益:
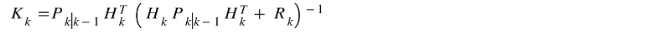
We have now arrived at the most cryptic equation of the Kalman filter algorithm, the computation of Kalman gain ( K(k) ). This is the real game player in the algorithm for which we went through all of this trouble. Kalman gain holds the information of uncertainties in state parameters fused with the uncertainties in observations of the instrument readings. P(k) holds uncertainty in state parameters while R(k) represents the observation noise matrix. These are fused into Kalman gain using the above equation. In the next steps, we will see the role of Kalman gain in enhancing our prior estimates.
現在,我們得出了卡爾曼濾波算法中最隱秘的方程式,即卡爾曼增益( K(k))的計算 。 這是我們遇到了所有麻煩的真正算法中的游戲者。 卡爾曼增益保持狀態參數的不確定性信息與儀器讀數觀測值的不確定性相融合。 P(k)保持狀態參數的不確定性,而R(k)代表觀察噪聲矩陣。 使用以上公式將它們融合到卡爾曼增益中。 在接下來的步驟中,我們將看到卡爾曼增益在增強我們先前的估計中的作用。
2.3 Update state:
2.3更新狀態:

We now have X? (k|k-1), which is the estimate of the state which we calculated in the propagation step. We have ?(k), which is the residual we calculated in the innovation step, and we have K(k), Kalman gain which we calculated in the previous step. Based on these three we update the estimate of the state. The significance of k | k (read as k given k) in X? (k|k) is that we are enhancing our estimates which we calculated in the propagation step using the observed measurements.
現在我們有X?(k | k-1),它是在傳播步驟中計算出的狀態的估計值。 我們有?(k),這是我們在創新步驟中計算出的殘差,而我們有K(k) ,即在上一步中計算出的卡爾曼增益。 基于這三個,我們更新狀態的估計。 k的意義 X?(k | k)中的 k (在給定k的情況下,讀作k )是我們正在增強我們的估計值,該估計值是使用觀察到的測量值在傳播步驟中計算得出的。
To get an intuition of how this is happening, consider the state measured in the propagation step and the residual calculated in the measurement step. Both of the things kind of represent the same thing but in different formats. Where X? (k|k-1) represents the prior belief of state, the residual ?(k), represents the difference in measured state and prior belief. The Kalman gain acts as a bridge between them. It contains the information regarding the proportions in which the prior belief of state and the observations will be weighted to calculate the updated state. The cool thing about this is, you don’t need to worry about knowing which measurement contributes how much towards the estimate. All of that has been computed as part of the Kalman gain which contains all this information.
為了直觀了解這種情況的發生,請考慮在傳播步驟中測量的狀態和在測量步驟中計算的殘差。 兩種事物都代表同一事物,但格式不同。 X?(k | k-1)表示狀態的先驗信念,而殘差?(k)表示測量狀態和先驗信念的差。 卡爾曼增益充當它們之間的橋梁。 它包含有關比例的信息,狀態的先驗信念和觀察將按權重進行加權以計算更新的狀態。 與此有關的很酷的事情是,您不必擔心知道哪種度量對估計有多大貢獻。 所有這些都作為包含所有這些信息的卡爾曼增益的一部分進行了計算。
2.4 Update Estimate Covariance Matrix:
2.4更新估算協方差矩陣:

In this is the final step of the Kalman filter, we use the Kalman gain computed, the observation model, and the prior belief of estimate covariance to update the estimate covariance matrix. As Kalman gain holds the gain in information gathered from instruments, the uncertainties in state parameters decrease as we have gained information. With a continuous feed of the measurements, the Kalman filter is able to reduce the uncertainty in the car’s state and is able to localize the car.
在這是卡爾曼濾波器的最后一步,我們使用計算的卡爾曼增益,觀測模型和估計協方差的先驗信念來更新估計協方差矩陣。 由于卡爾曼增益保持了從儀器收集的信息的增益,因此,隨著我們獲得信息,狀態參數的不確定性會降低。 通過連續提供測量值,卡爾曼濾波器能夠減少汽車狀態的不確定性,并能夠對汽車進行定位。
摘要 (Summary)
We can summarize the algorithm as follows:
我們可以將算法總結如下:

UFF! That was a lot, wasn’t it! But by decoding the equations, line by line along with me, we have finally understood how Kalman filters work, and how it is implemented mathematically. Understanding the equations isn’t hard. Don’t let the notations and the linear algebra intrigue you. It’s more important to understand the meaning that they are trying to convey.
FF! 太多了,不是嗎! 但是通過與我一起逐行解碼方程,我們終于了解了卡爾曼濾波器的工作原理以及如何在數學上實現它。 了解方程式并不難。 不要讓符號和線性代數引起您的興趣。 理解他們試圖傳達的含義更為重要。
結論 (Conclusion)

Kudos! If you got everything, you now understand one of the most widely used algorithms for localization in the autonomous industry. There are variants to the original Kalman filter algorithms like Extended Kalman Filter (EKF) or Unscented Kalman Filter (UKF) to name a few but they all rely on the same concepts that we learned today. I would also suggest you go through Wikipedia, and read about Kalman filters there. If you found this very interesting, you can also checkout EKF and UKF online and try to see what limitations the original Kalman filter faces, and how they are tried to resolve in these variants.
榮譽! 如果您掌握了一切,現在您將了解自治行業中最廣泛使用的本地化算法之一。 原始卡爾曼濾波器算法有多種變體,例如擴展卡爾曼濾波器(EKF)或無味卡爾曼濾波器(UKF)等,但它們都依賴于我們今天學習的相同概念。 我還建議您瀏覽Wikipedia,并在那里閱讀有關Kalman過濾器的信息 。 如果您發現這很有趣,還可以在線簽出EKF和UKF,并嘗試查看原始Kalman濾波器面的局限性,以及如何解決這些變體。
翻譯自: https://medium.com/team-rover/understanding-kalman-filter-and-its-equations-5fcc5d5fe61e
卡爾曼濾波濾波方程
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388999.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388999.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388999.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
到底做了些什么??)
js中的new()到底做了些什么??

Candidate sampling:NCE loss和negative sample

golang key map 所有_Map的底層實現 為什么遍歷Map總是亂序的

樸素貝葉斯分類器 文本分類_構建災難響應的文本分類器

第二輪沖次會議第六次

markdown 鏈接跳轉到標題_我是如何使用 Vim 高效率寫 Markdown 的



Seaborn:Python


Springboot集成BeanValidation擴展一:錯誤提示信息加公共模板
)
福大軟工 · 第十次作業 - 項目測評(團隊)

銷貨清單數據_2020年8月數據科學閱讀清單

c++運行不出結果_fastjson 不出網利用總結
)
FocusBI:租房分析可視化(PowerBI網址體驗)

米其林餐廳 鹽之花_在世界范圍內探索《米其林指南》

require_once的用法

差值平方和匹配_純前端實現圖片的模板匹配

藍牙耳機音量大解決辦法_長時間使用藍牙耳機的危害這么大?我們到底該選什么藍牙耳機呢?...
