Golang中Map的底層結構
其實提到Map,一般想到的底層實現就是哈希表,哈希表的結構主要是Hashcode + 數組。
- 存儲kv時,首先將k通過hashcode后對數組長度取余,決定需要放入的數組的index
- 當數組對應的index已有元素時,此時產生一個【哈希沖突】。一般來說哈希沖突的解決方式為鏈表法,即在沖突的位置生成一個鏈表來存儲元素
轉自:https://www.jianshu.com/p/7aafee109f28
參考:go語言中文文檔:www.topgoer.com
對于哈希表的具體實現和哈希沖突的解決方案這里就不贅述了,大家可以去看大神程序員小灰的漫畫:什么是HashMap?。
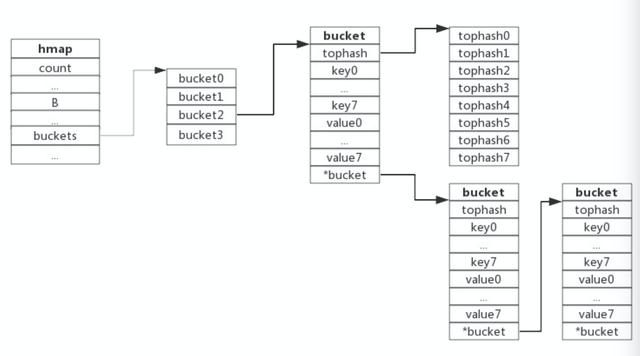
Redis中的Dict結構(用于實現RedisDB、Hashmap,Set等)其實就是非常典型的哈希表。Golang中的Map結構與傳統的哈希表稍有不同,它數組的基本單元并不是kv對,而是bucket。
每個bucket中可以放置8個kv對,這樣可以減少對象的數量,有利于提升GC的性能;當bucket中放置不下時,會繼續在溢出桶(overflow)中繼續存儲,串成一個鏈表的結構,如圖所示:
鏈表法解決哈希沖突
Bucket中結構詳解
// map 哈希表type Hmap struct{ count int // 元素數量 .... B uint8 // 哈希表數組的容量大小=2^B ... buckets unsafe.Pointer oldBuckets unsafe.Pointer // 用于擴容 ...}// Bucket 桶type bmap struct{ tophash [8]uint8 // 哈希值的高8位 keys values overflow *bmap}- key的哈希值的低B位(比如數組大小為32,2^5=32,則B=5)決定了它放入buckets中的index位置
- key的哈希值的高8位放入bucket中的tophash字段中,因為每個bucket中最多可以放8個KV對,所以tophash為大小為8的數組:tophash字段可以用于加速key的比較,當在一個bucket中查詢某key時,可以先比較哈希值的高8位是否符合,如果符合才會比較對應的key,這樣加速了key比較的過程;
- keys和values為分開存儲的,因為key和value可能是不同類型,比如map[int64]int8,分開存儲不需要進行字節補齊,可以節省空間;
- overflow即溢出桶,用于存儲哈希沖突后超過8對的kv對
擴容操作
負載因子=元素數量/數組大小
redis是1時擴容;golang因為數組中元素為bucket,每個bucket可以放8個kv,所以是在load factor = 6.5時才會觸發擴容邏輯:
- 擴容時容量翻倍,申請一個新的數組,采用漸進式哈希的方式進行遷移(和redis類似,可以避免影響性能)
- 遷移過程中支持讀寫:
- 新增kv只寫新表
- 修改和刪除雙寫,保證新老表中的數據一致
- 讀取時優先讀老表,再讀新表
- 遷移過程為每次update/remove操作時觸發部分搬遷,每次搬遷2部分bucket中的數據:
- 修改的key所在的當前Bucket
- 按照順序搬遷的一個Bucket(避免某些bucket一直未被訪問導致無法搬遷成功)
- 直到所有數據搬遷完成后,刪除oldBuckets,使得老哈希表中的Bucket對象被GC回收
遍歷Map亂序之謎
在寫代碼時,當我們使用for k,v := range map {} 時會發現,每次輸出的kv都是亂序的,既然map的底層是數組為什么不能按照固定順序地輸出呢?
結合上文我們說到擴容流程,由于擴容過程會新申請一個數組,并且將keys重新rehash后放入新的數組中。那么新的數組中的key的順序就改變了,因此哈希表的底層實現使得map無法保證穩定地按照同一順序輸出keys。
Golang的作者為了”提醒“新手程序員不要依賴map遍歷時返回的key順序,采用隨機選擇遍歷起始位置的方式使得遍歷時返回是亂序的。








)


)







