一、簡單實例
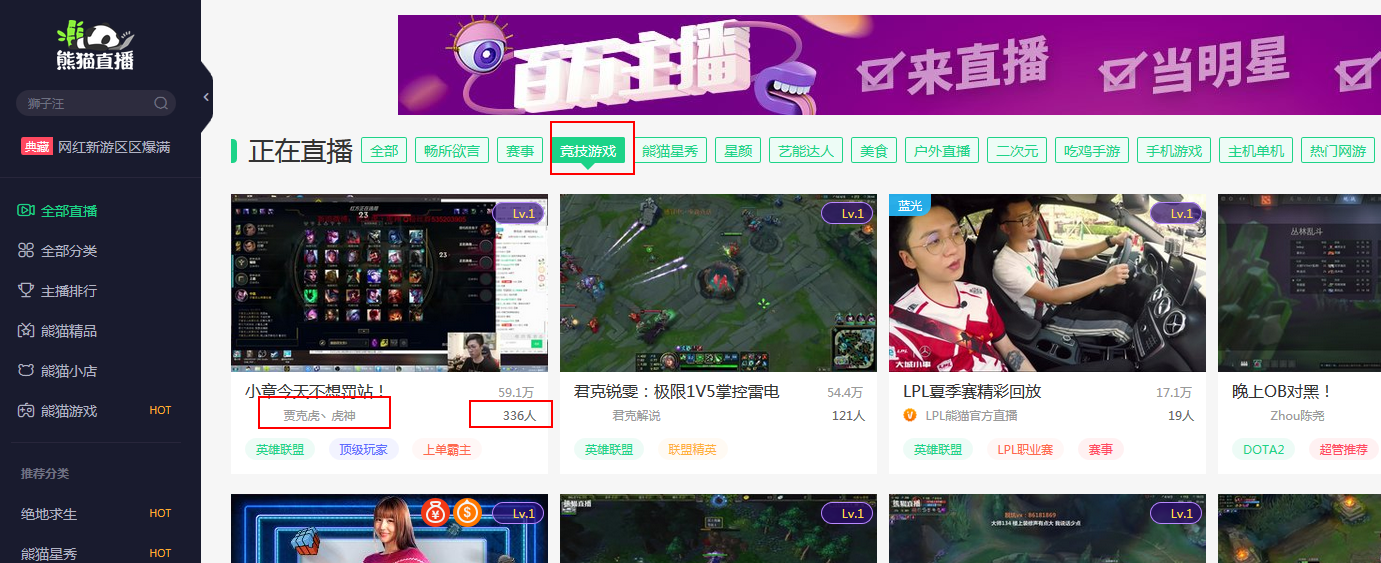
1、需求:爬取熊貓直播某類主播人氣排行
2、了解網站結構
分類——英雄聯盟——"觀看人數"
3、找到有用的信息
二、整理爬蟲常規思路
1、使用工具chrome——F12——element——箭頭——定位目標元素
目標元素:主播名字,人氣(觀看人數)
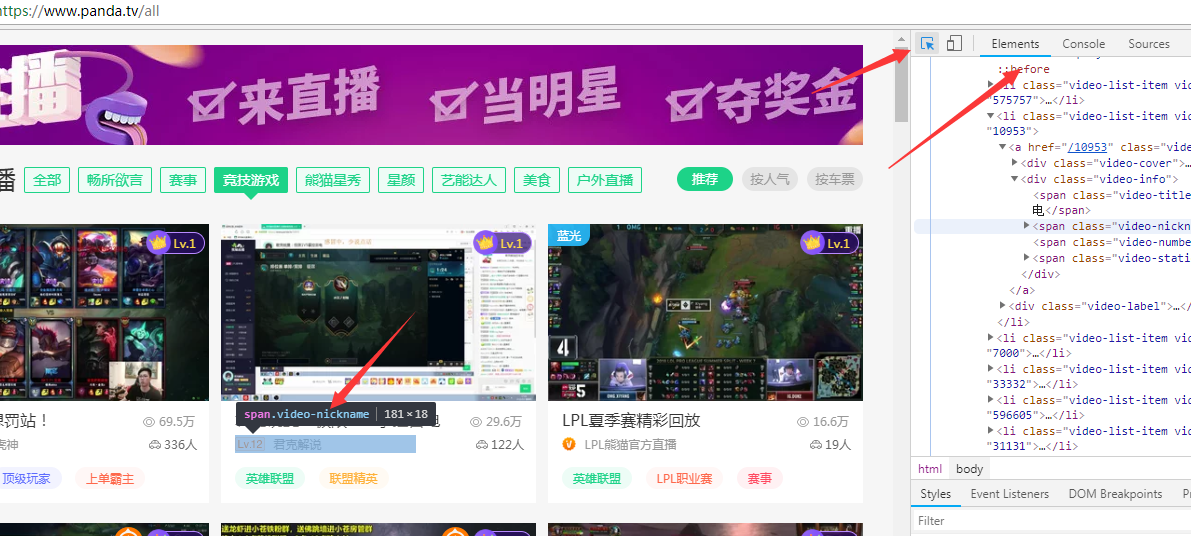
?
2、方法:使用正則表達式提取有用的信息
主播名字,人氣(觀看人數)
總結
- 爬蟲前奏
1)明確目的
2)找到數據對應的網頁
3)分析網頁的結構找到數據所在的標簽位置
- 步驟
1)模擬HTTP請求,向服務器發送這個請求,獲取到服務器返回給我們的HTML
2)用正則表達式提取我們要的數據(名字,人氣)
二、斷點調試
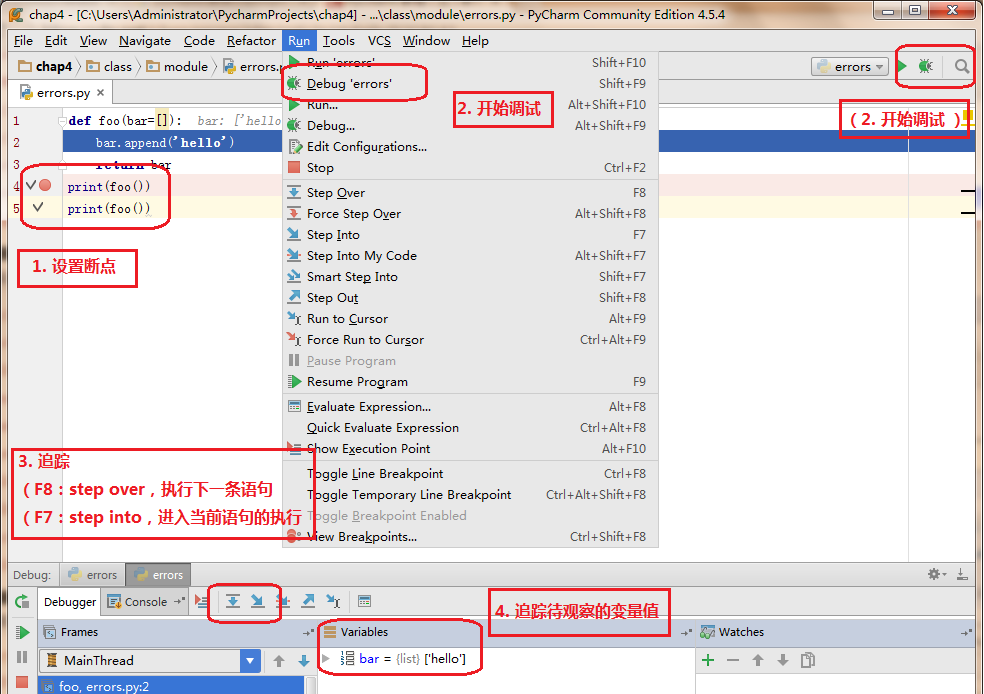
我們以如下的一種常見錯誤,來演示如何通過PyCharm斷點追蹤的方式發現程序中的錯誤:
def foo(bar=[]):bar.append('bar') return bar >>>foo() ['bar'] >>>foo() ['bar', 'bar'] >>>foo() ['bar', 'bar', 'bar']這里存在一個常見的錯誤就是誤以為:函數在每次不提供可選形參時將參數設置為默認值,也就是本例中的[],一個空的list。
這里我們便可以通斷點調試的方式進行追蹤,在每次函數調用(不顯示傳遞形參)時,觀察形參值的變化。
如圖所示為:
下圖是以這段為例,來演示如何發現程序中的bug:
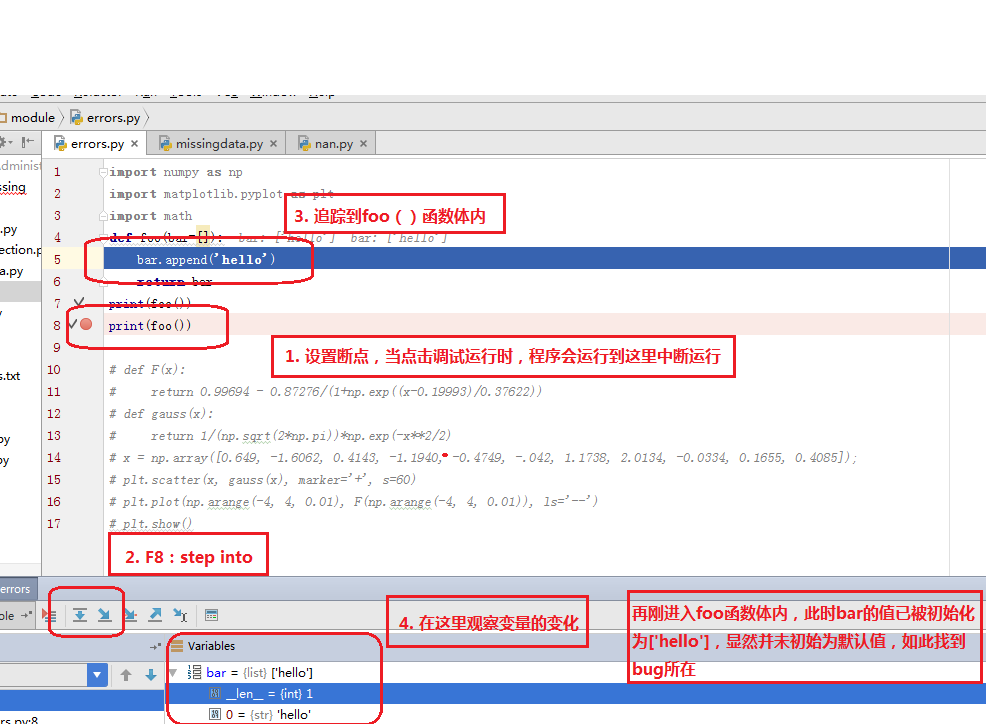
解決方案:
def foo(bar=None):if not bar: bar = [] bar.append('baz') return bar >>>foo() ['baz'] >>>foo() ['baz']三、HTML結構分析基本原則
1、爬蟲分析,最重要的一步,找到標簽(即左右邊界)
原則:
1)盡量選擇有唯一標識性的標簽
2)盡量選擇離目標信息最近的標簽
不同人選擇的標簽可能不同。
?
四、數據提取層級及原則
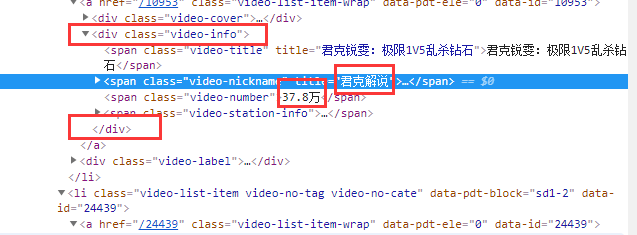
1、找到最近的定位標簽(肉眼可見)
有關聯的信息作為一組,找離這一組最近的定位標簽
如:示例中的“主播姓名”和“人數”是有關聯的,作為一組
2、判斷選擇的標簽是否是唯一的(需代碼驗證)
3、盡量選擇可閉合的定位標簽
?
可閉合,是指可將目標信息包裹起來的定位標簽。如:<... />
?
?

4、代碼實戰
1 # coding=utf-8
2 import re 3 from urllib import request 4 5 url = 'https://www.panda.tv/all' 6 r = request.urlopen(url) 7 htmls = r.read() 8 9 print(type(htmls)) # 打印type,結果是bytes類型 10 htmls = str(htmls, encoding='utf-8') # 將bytes轉成utf-8 11 print(htmls) 運行結果
Traceback (most recent call last):File "E:/pyClass/thirtheen/spider.py", line 12, in <module>print(htmls) UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 62321: illegal multibyte sequence 原因是使用的print()是win7系統的編碼,但是win7系統的默認編碼是GBK,解決方式,增加如下代碼
1 import io
2 import sys 3 sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') 優化后代碼
# coding=utf-8 import re from urllib import request import io import sys sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')class Spider():url = 'https://www.panda.tv/all'def __fetch_content(self):r = request.urlopen(Spider.url)htmls = r.read()htmls = str(htmls, encoding='utf-8') # 將bytes轉成utf-8print(htmls)return htmlsdef go(self):self.__fetch_content()spider=Spider() spider.go()
?
五、正則分析HTML
1、獲取root_html
正則表達式匹配<div class="video-info">和</div>之間的所有字符,有哪些方式?

匹配所有字符的方式
1)[\s\S]*?
2)[\w\W]*?
* 表示任意次
?表示貪婪
2、代碼實戰
?
1 # coding=utf-8 2 from urllib import request 3 import re 4 import io 5 import sys 6 sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') 7 8 #以下代碼解決SSL報錯 9 import ssl 10 ssl._create_default_https_context = ssl._create_unverified_context 11 12 13 class Spider(): 14 15 #定義類變量 16 url = 'https://www.panda.tv/all' 17 root_html='<div class="video-info">([\s\S]*?)</div>' #([\s\S]*?)匹配任意字符 18 19 #獲取服務器響應內容 20 def __fetch_content(self): 21 22 r=request.urlopen(url=Spider.url) 23 htmls = r.read() 24 htmls = str(htmls, encoding='utf-8') # 將bytes轉成utf-8 25 return htmls 26 27 #分析并獲取元素 28 def __analysis(self,htmls): 29 root_html=re.findall(Spider.root_html,htmls) 30 return root_html 31 32 33 def go(self): 34 htmls=self.__fetch_content() 35 self.__analysis(htmls) 36 37 38 spider=Spider() 39 spider.go()
遇到的問題:
1)亂碼
參考python的編碼問題整理
2)SSL錯誤
加入如下代碼
import ssl ssl._create_default_https_context = ssl._create_unverified_context
?
3)類變量的引用
Spider.root_html
六、數據精煉
正則分析獲取名字和人數
1、找到名字的左右邊界、找到人數的左右邊界
2、使用正則匹配,從root_html中獲取名字和人數,并拼接成字典格式,列表接收
3、數據精煉——去掉多余的換行和空格(如果有),將value列表轉化為str
代碼示例:
1 # coding=utf-8 2 from urllib import request 3 import re 4 import io 5 import sys 6 7 sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') 8 9 # 以下代碼解決SSL報錯 10 import ssl 11 12 ssl._create_default_https_context = ssl._create_unverified_context 13 14 15 class Spider(): 16 # 定義類變量 17 url = 'https://www.panda.tv/all' 18 root_html = '<div class="video-info">([\s\S]*?)</div>' # ([\s\S]*?)匹配任意字符 19 name_pattern = '<span class="video-title" title="([\s\S]*?)">' 20 number_pattern = '<span class="video-number">([\s\S]*?)</span>' 21 22 # 獲取服務器響應內容 23 def __fetch_content(self): 24 r = request.urlopen(url=Spider.url) 25 htmls = r.read() 26 htmls = str(htmls, encoding='utf-8') # 將bytes轉成utf-8 27 return htmls 28 29 # 分析并獲取元素 30 def __analysis(self, htmls): 31 anchors = [] # 使用list接收 32 root_html = re.findall(Spider.root_html, htmls) 33 for html in root_html: 34 name = re.findall(Spider.name_pattern, html) 35 number = re.findall(Spider.number_pattern, html) 36 anchor = {'name': name, 'number': number} # 組合成需要的字典格式 37 anchors.append(anchor) 38 39 return anchors 40 41 # 數據精煉——去掉多余的內容,轉成需要的格式 42 def __refine(self, anchors): 43 l = lambda anchor: {'name': anchor['name'][0], 'number': anchor['number'][0]} # 上一步得到的name和number是列表類型,需要轉成str 44 return map(l, anchors) 45 46 47 def go(self): 48 htmls = self.__fetch_content() 49 anchors = self.__analysis(htmls) 50 anchors=list(self.__refine(anchors)) 51 print(anchors) 52 53 54 spider = Spider() 55 spider.go()
九、業務處理——排序
?











)

)




)
