歸一化 均值歸一化
Do you remember the awkward moment when someone you had a good conversation with forgets your name? In this day and age we have a new standard, an expectation. And when the expectation is not met the feeling is not far off being asked “where do I know you from again?” by some the lady/guy you spent the whole evening with at the pub last week, awkward! — well I don’t actually go to the pub but you get my gist. We are in the era of personalization and personalized content is popping up everywhere — Netflix, Youtube, Amazon, etc. The user demands personalized content, and businesses seek to meet the demands of the users.
你還記得尷尬的時刻,當有人你與你忘記一個名字很好的交談? 在這個時代,我們有了新的標準,一種期望。 當沒有達到期望時,很快就會被問到“我又從哪里認識你?” 上周您在酒吧里和整個晚上在一起的女士/男士中,有些尷尬! -嗯,我實際上并不去酒吧,但您明白了我的要旨。 我們正處于個性化時代,個性化內容隨處可見-Netflix,Youtube,Amazon等。用戶需要個性化內容,而企業則在努力滿足用戶的需求。
In the recent years, many businesses have been employing Machine Learning to develop effective recommender systems to assist in personalizing the users experience. As with all things in life, this feat comes with its challenges. Evaluating the impact of a recommender engine is a major challenge in the development stages, or enhancement stages of a recommender engine. Although we may be sure of the positive impact caused by a recommender system, there’s a much required need to quantify this impact in order to effectively communicate to stakeholders or for when we want to enhance our system in the future.
近年來,許多企業一直在使用機器學習來開發有效的推薦系統,以幫助個性化用戶體驗。 與生活中的所有事物一樣,這一壯舉也伴隨著挑戰。 在推薦引擎的開發階段或增強階段,評估推薦引擎的影響是一項重大挑戰。 盡管我們可以肯定推薦系統會帶來的積極影響,但是仍然需要量化這種影響,以便有效地與利益相關者進行交流,或者在將來我們希望增強我們的系統時。
After a long-winded introduction, I hereby present to you… Normalized Discounted Cumulative Gain (NDCG).
在經過漫長的介紹之后,我在此向您介紹…… 歸一化累積折扣收益 (NDCG)。
A measure of ranking quality that is often used to measure effectiveness of web search engine algorithms or related applications.
排名質量的度量標準,通常用于度量Web搜索引擎算法或相關應用程序的有效性。
If we are to understand the NDCG metric accordingly we must first understand CG (Cumulative Gain) and DCG (Discounted Cumulative Gain), as well as understanding the two assumptions that we make when we use DCG and its related measures:
如果要相應地理解NDCG度量標準,則必須首先了解CG(累積增益)和DCG(折讓累積增益),以及理解我們在使用DCG及其相關度量時做出的兩個假設:
- Highly relevant documents are more useful when appearing earlier in the search engine results list. 如果相關性較高的文檔出現在搜索引擎結果列表的前面,則將更為有用。
- Highly relevant documents are more useful than marginally relevant documents, which are more useful than non-relevant documents 高度相關的文檔比邊緣相關的文檔更有用,后者比不相關的文檔更有用
(Source: Wikipedia)
(來源:維基百科)
累積增益(CG) (Cumulative Gain (CG))
If every recommendation has a graded relevance score associated with it, CG is the sum of graded relevance values of all results in a search result list — see Figure 1 for how we can express this mathematically.
如果每個建議都具有與之相關的分級的相關性得分,則CG是搜索結果列表中所有結果的分級的相關性值的總和-有關如何數學表達的信息,請參見圖1。
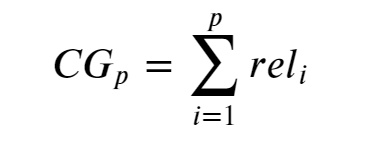
The Cumulative Gain at a particular rank position p, where the rel_i is the graded relevance of the result at position i. To demonstrate this in Python we must first let the variable setA be the graded relevance scores of a response to a search query, thereby each graded relevance score is associated with a document.
在特定等級位置p處的累積增益,其中rel_i是位置i處結果的分級相關性。 為了在Python中證明這一點,我們必須首先讓變量setA為搜索查詢響應的分級相關性得分,從而使每個分級相關性得分與文檔相關聯。
setA = [3, 1, 2, 3, 2, 0]
print(sum(setA))11The problem with CG is that it does not take into consideration the rank of the result set when determining the usefulness of a result set. In other words, if we was to reorder the graded relevance scores returned in setA we will not get a better insight into the usefulness of the result set since the CG will be unchanged. See the code cell below for an example.
CG的問題在于,在確定結果集的有用性時,它沒有考慮結果集的等級。 換句話說,如果我們要對在setA返回的分級相關性分數進行重新排序,則由于CG不變,因此我們將無法更好地了解結果集的用途。 有關示例,請參見下面的代碼單元。
setB = sorted(setA, reverse=True)
print(f"setA: {setA}\tCG setA: {cg_a}\nsetB: {setB}\tCG setB: {sum(setB)}")setA: [3, 1, 2, 3, 2, 0] CG setA: 11
setB: [3, 3, 2, 2, 1, 0] CG setB: 11setB is clearly returning a much more useful set than setA, but the CG measure says that they are returning equally as good results.
顯然setB返回的集合比setA有用得多,但是CG度量表明它們返回的結果相同。
折讓累計收益 (Discounted Cumulative Gain)
To overcome this we introduce DCG. DCG penalizes highly relevant documents that appear lower in the search by reducing the graded relevance value logarithimically proportional to the position of the result — see Figure 2.
為了克服這個問題,我們引入了DCG。 DCG通過降低與結果位置成對數比例的相關度等級值,對在搜索中顯示較低的高度相關的文檔進行懲罰-見圖2。
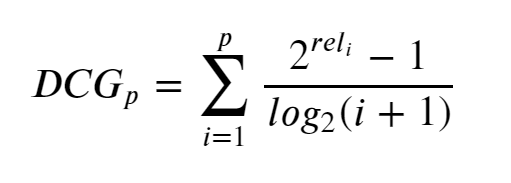
Below we have created a function called discountedCumulativeGain to calculate DCG for setA and setB. If this is an effective measurement, setB should have a higher DCG than setA since its results are more useful.
下面我們創建了一個名為函數discountedCumulativeGain計算DCG為setA和setB 。 如果這是一種有效的測量方法,則setB DCG應當比setA因為其結果更有用。
import numpy as np
def discountedCumulativeGain(result):
dcg = []
for idx, val in enumerate(result):
numerator = 2**val - 1
# add 2 because python 0-index
denominator = np.log2(idx + 2)
score = numerator/denominator
dcg.append(score)
return sum(dcg)print(f"DCG setA: {discountedCumulativeGain(setA)}\nDCG setB: {discountedCumulativeGain(setB)}")DCG setA: 13.306224081788834
DCG setB: 14.595390756454924The DCG of setB is higher than setA which aligns with our intuition that setB returned more useful results than setA.
setB的DCG高于setA ,這符合我們的直覺,即setB返回的結果比setA更有用。
歸一化折現累積收益 (Normalized Discounted Cumulative Gain)
An issue arises with DCG when we want to compare the search engines performance from one query to the next because search results list can vary in length depending on the query that has been provided. Hence, by normalizing the cumulative gain at each position for a chosen value of p across queries we arrive at NDCG. We perform this by sorting all the relevant documents in the corpus by their relative relevance producing the max possible DCG through position p (a.k.a Ideal Discounted Cumulative Gain) - see Figure 3.
當我們要比較一個查詢與下一個查詢的搜索引擎性能時,DCG會出現問題,因為搜索結果列表的長度可能會有所不同,具體取決于所提供的查詢。 因此,通過將查詢中p的選定值的每個位置處的累積增益標準化,我們得出NDCG。 我們通過將語料庫中的所有相關文檔按照它們的相對相關性進行排序來執行此操作,從而通過位置p (又稱理想折現累積增益)產生最大可能的DCG-見圖3。
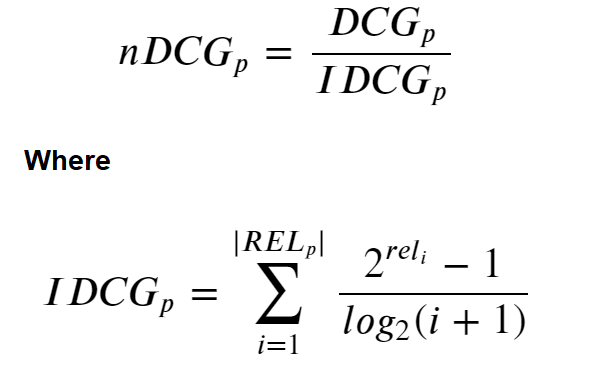
To perform this metric in python we created the function normalizedDiscountedCumulativeGain to assist with this functionality.
為了在python中執行此指標,我們創建了功能normalizedDiscountedCumulativeGain來輔助此功能。
def normalizedDiscountedCumulativeGain(result, sorted_result):
dcg = discountedCumulativeGain(result)
idcg = discountedCumulativeGain(sorted_result)
ndcg = dcg / idcg
return ndcgprint(f"DCG setA: {normalizedDiscountedCumulativeGain(setA, setB)}\nDCG setB: {normalizedDiscountedCumulativeGain(setB, setB)}")DCG setA: 0.9116730277265138
DCG setB: 1.0The ratios will always be in the range of [0, 1] with 1 being a perfect score — meaning that the DCG is the same as the IDCG. Therefore, the NDCG values can be averaged for all queries to obtain a measure of the average performance of a recommender systems ranking algorithm.
比率將始終在[0,1]范圍內,其中1為完美分數-意味著DCG與IDCG相同。 因此,可以對所有查詢的NDCG值取平均值,以獲得對推薦系統排名算法的平均性能的度量。
NDCG的局限性 (Limitations of NDCG)
(source: Wikipedia)
(來源:維基百科)
- The NDCG does not penalize for bad documents in the results NDCG不會對結果中的不良文件進行處罰
- Does not penalize missing documents in the results 不懲罰結果中缺少的文件
- May not be suitable to measure performance of queiries that may often have several equally good results 可能不適合測量可能經常具有幾個同樣好的結果的查詢的性能
結語 (Wrap Up)
The main difficulty that we face when using NDCG is that often times we don’t know the ideal ordering of results when only partial relevance feedback is available. However, the NDCG has proven to be an effect metric to evaluate ranking quality for various problems, for example the Personalized Web Search Challenge, AirBnB New User Booking Challenge, and Personalize Expedia Hotel Searches — ICDM 2013 to name a few.
使用NDCG時,我們面臨的主要困難是,當只有部分相關性反饋可用時,我們常常不知道結果的理想排序。 但是,事實證明,NDCG是評估各種問題排名質量的一種效果指標,例如個性化Web搜索挑戰賽 , AirBnB新用戶預訂挑戰賽和個性化Expedia酒店搜索-ICDM 2013等 。
Thank you for reading to the end of this post. If you’d like to get in contact with me, I am most accessible on LinkedIn.
感謝您閱讀這篇文章的結尾。 如果您想與我聯系,可以在LinkedIn上訪問我。
翻譯自: https://towardsdatascience.com/normalized-discounted-cumulative-gain-37e6f75090e9
歸一化 均值歸一化
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388948.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388948.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388948.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

sqlserver垮庫查詢_Oracle和SQLServer中實現跨庫查詢

Angular2+ typescript 項目里面用require

機器學習實踐三---神經網絡學習

Microsoft Expression Blend 2 密鑰,key

ethereumjs/ethereumjs-common-3-test

mysql修改_mysql修改表操作

機器學習實踐四--正則化線性回歸 和 偏差vs方差

深度學習 推理 訓練_使用關系推理的自我監督學習進行訓練而無需標記數據

Android strings.xml中定義字符串顯示空格

WCF開發入門的六個步驟
)
LOJ116 有源匯有上下界最大流(上下界網絡流)

CentOS 7 使用 ACL 設置文件權限
)
機器學習實踐五---支持向量機(SVM)

作為微軟技術.net 3.5的三大核心技術之一的WCF雖然沒有WPF美麗的外觀

服務器安裝mysql_阿里云服務器上安裝MySQL

在PyTorch中轉換數據

「網絡流24題」試題庫問題
)
機器學習實踐六---K-means聚類算法 和 主成分分析(PCA)

航海家軟件公式全破解
