ai前沿公司
In 1950, Alan Turing developed the Turing Test as a test of a machine’s ability to display human-like intelligent behavior. In his prolific paper, he posed the following questions:
1950年,阿蘭圖靈開發的圖靈測試作為一臺機器的顯示類似人類的智能行為能力的考驗。 在他的論文中 ,他提出了以下問題:
“Can machines think?”
“機器可以思考嗎?”
“Are there imaginable digital computers which would do well in the imitation game?”
“有沒有可以想象的數字計算機在模仿游戲中表現出色?”
In most applications of AI, a model is created to imitate the judgment of humans and implement it at scale, be it autonomous vehicles, text summarization, image recognition, or product recommendation.
在大多數AI應用中,都會創建一個模型來模仿人類的判斷并大規模實施,例如自動駕駛汽車,文本摘要,圖像識別或產品推薦。
By the nature of imitation, a computer is only able to replicate what humans have done, based on previous data. This doesn’t leave room for genuine creativity, which relies on innovation, not imitation.
根據模仿的性質,計算機只能根據以前的數據來復制人類所做的事情。 這就沒有真正的創造力的余地,真正的創造力是依靠創新而不是模仿。
But more recently, computer-generated creations have started to push the boundaries between imitation and innovation across various mediums.
但是最近,計算機生成的作品已經開始跨各種媒介推動模仿與創新之間的界限。
The question arises: can a computer be creative? Can it be taught to innovate on its own and generate original outputs? And can it do this in a way that makes it indistinguishable from human creativity?
隨之而來的問題是:計算機能否具有創造力? 可以教它自己進行創新并產生原始輸出嗎? 并能以使其與人類創造力沒有區別的方式做到這一點嗎?
Here, a few developments at the intersection of art and AI that can help us to answer those questions.
在這里,藝術和人工智能的交匯處可以幫助我們回答這些問題。
1.埃德蒙·德·貝拉米 (1. Edmond de Belamy)
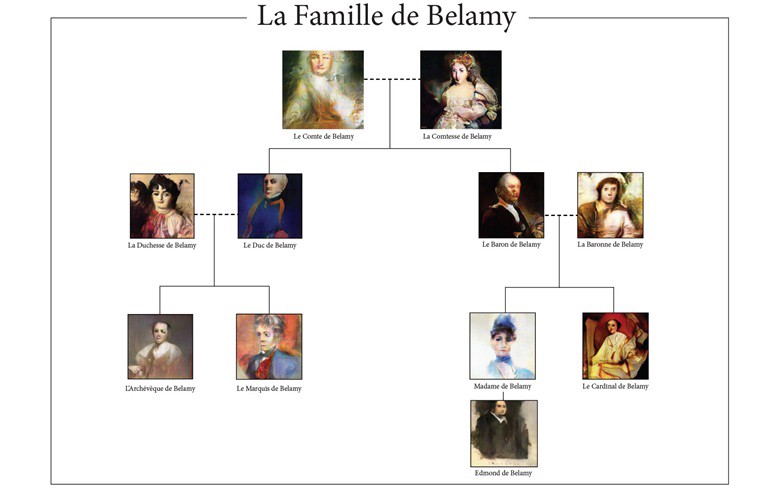
In October 2018, Christie’s Auction House in New York sold a computer-generated portrait of Edmond de Belamy, created in the style of 19th-century European portraiture.
2018年10月,紐約佳士得拍賣行出售了計算機生成的埃德蒙·德·貝拉米的肖像,該肖像以19世紀歐洲肖像畫的風格創作。
The piece sold for $432,500, more than 40 times its original estimate.
這件作品以432,500美元的價格售出,是其原始估價的40倍以上。

The painting (or, as art aficionados may prefer, print) is part of a collection of portraits of the fictional Belamy family, created by the French collective Obvious, which aims to explore the interface of AI with art.
這幅畫(或者像藝術愛好者可能喜歡的那樣,是印刷品)是虛構的Belamy家族肖像集的一部分,該肖像集是由法國集體組織Obvious創建的,旨在探索AI與藝術的界面。
As well as the seemingly unfinished, blurry and featureless portrait of Edmond Belamy himself, almost as eye-catching is the mathematical formula, in place of a signature, in the bottom right corner.
就像埃德蒙·貝拉米(Edmond Belamy)本人的看似未完成的,模糊的和毫無特色的肖像一樣,右下角的數學公式幾乎代替了簽名,引人注目。
This formula is the loss function used by the Generative Adversarial Network (GAN) to create the portrait. This raises interesting questions about the authorship of such pieces of art. Are they truly the result of the mathematical formula, or the human who originally developed it?
此公式是Genversative Adversarial Network (GAN)用于創建肖像的損失函數 。 這就提出了有關這些藝術品的作者的有趣問題。 它們是真正的數學公式的結果,還是真正開發數學公式的人?
GANs are a deep learning framework containing two competing (hence the name “adversarial”) neural networks, with the aim of creating new datasets that statistically mimic the original training data.
GAN是一個深度學習框架,其中包含兩個相互競爭的(因此稱為“對抗性”)神經網絡,目的是創建新的數據集,以統計學方式模擬原始訓練數據。
The first, known as the discriminator, is fed a training set of data (in this case images) and aims to learn to discriminate this data from synthetically generated data. To create the Belamy family, Obvious trained the discriminator on 15,000 portraits produced between the 14th and 20th centuries.
第一個被稱為鑒別器,被提供訓練數據集(在這種情況下為圖像),目的是學習從合成生成的數據中區分該數據。 為了創建Belamy家族,Obvious在14至20世紀間制作的15,000張肖像上對鑒別器進行了培訓。
The second, the generator, creates an output, trying to fool the discriminator into incorrectly identifying it as part of the original data. As such, the final output is newly created data, similar enough to the original that the discriminator cannot tell it has been synthetically created.
第二個函數是生成器,它創建一個輸出,試圖欺騙鑒別器,將其錯誤地標識為原始數據的一部分。 這樣,最終的輸出是新創建的數據,與原始數據足夠相似,因此鑒別器無法告知它是綜合創建的。
Edmond de Belamy may be proof of at least one thing: that people are willing to pay for fine art developed by AI.
埃德蒙·德·貝拉米(Edmond de Belamy)至少可以證明一件事:人們愿意為AI開發的美術付出代價。
But the question remains whether Obvious successfully imitated human creativity. Considering the purpose of a GAN is to replicate its training data, it might be a stretch to argue that their outputs are truly innovative.
但是問題仍然存在,就是“顯而易見”是否成功地模仿了人類的創造力。 考慮到GAN的目的是復制其訓練數據,因此可能會爭辯說其輸出是真正的創新。
2.艾坎 (2. AICAN)
On 13th February 2019 a four-week exhibit, Faceless Portraits Transcending Time, at the HG Contemporary art gallery in Chelsea, New York, contained prints of artwork produced entirely by AICAN, an algorithm designed and written by Ahmed Elgammal, Director of the Art & AI Lab at Rutgers University. According to Elgammal,
2019年2月13日,在紐約切爾西HG當代美術館的為期四周的展覽《 無臉肖像超越時間》 ( Farless Portraits Transcending Time)包含了由AICAN (藝術和藝術總監艾哈邁德· 埃爾加馬爾 ( Ahmed Elgammal)設計和編寫的算法)完全由AICAN制作的藝術品印刷品羅格斯大學AI實驗室。 根據Elgammal ,
AICAN [is] a program that could be thought of as a nearly autonomous artist that has learned existing styles and aesthetics and can generate innovate images of its own.
AICAN是一個程序,可以被認為是一個近乎自主的藝術家,已經學習了現有的樣式和美學,并且可以生成自己的創新圖像。

Instead of GANs, AICAN uses what Elgammal has called a “creative adversarial network” (CAN). These diverge from GANs by adding an element that penalizes the model for work that too closely matches a given established style.
AICAN代替了GAN,使用Elgammal所謂的“創意對抗網絡”(CAN)。 這些元素與GAN的區別在于,添加了對模型進行懲罰的元素,這些元素對與給定既定樣式過于接近的工作進行了懲罰。
Psychologist Colin Martindale hypothesizes that artists will try to increase the appeal of their work by diverging from existing artistic styles. CANs do just that: allowing a model to introduce novelty so that AICAN can diverge from existing styles.
心理學家科林·馬丁代爾(Colin Martindale) 假設 ,藝術家將試圖通過與現有的藝術風格有所不同來增加其作品的吸引力。 CAN就是這樣做的:允許模型引入新穎性,以便AICAN可以與現有樣式有所不同。
AICAN is trained on over 80,000 images of Western art over the last 5 centuries but does not focus on a specific artistic style. As well as the images themselves, the algorithm is also fed the names of the pieces, so that the output is an image along with a title, all created by AICAN.
在過去的5個世紀中,AICAN接受了80,000幅西方藝術圖像的培訓,但并未專注于特定的藝術風格。 除了圖像本身之外,算法還獲得了片段的名稱,因此輸出是一幅圖像以及一個標題,均由AICAN創建。
More often than not, these pieces are more abstract, which Elgammal believes is because AICAN uses the most recent trends in art history, such as abstract art, to understand how best to diverge from existing styles.
這些作品通常更多地是抽象的,Elgammal 認為這是因為AICAN利用藝術史上的最新趨勢(例如抽象藝術)來了解如何最好地與現有樣式區分開。

In the paper introducing CANs, two experiments were conducted on humans to ascertain whether or not they could distinguish between human and computer-generated images. Each experiment, which received 10 distinct responses, measured that humans incorrectly labeled the CAN images as produced by humans 53% and 75% of the time, respectively. This is compared to 35% and 65% for GANs.
在介紹CAN的論文中 ,對人體進行了兩個實驗,以確定它們是否可以區分人和計算機生成的圖像。 每個實驗收到10個不同的響應,測量出人類分別錯誤地標記了人類在53%和75%的時間內所產生的CAN圖像。 相比之下,GAN分別為35%和65%。
CANs may be more successful than GANs at imitating humans. Perhaps we can finally argue that CANs succeed where GANs failed. They don’t just try to replicate a dataset—the penalty term might actually allow them to innovate.
在模仿人類方面,CAN可能比GAN更成功。 也許我們最終可以爭辯說,CAN可以在GAN失敗的地方成功。 他們不僅嘗試復制數據集,而且懲罰性條款實際上可能允許他們進行創新。
3.音樂智力 (3. Musical intelligence)
In 1981, David Cope, a music professor at the University of California, began what he called “Experiments in Musical Intelligence” (EMI, pronounced “Emmy”).
1981年,加利福尼亞大學的音樂教授David Cope開始了他所謂的“ 音樂智能實驗 ”(EMI,發音為“ Emmy”)。
According to Cope, he began these experiments as the result of composer’s block; he wanted a program that understood his overall style of music and could provide him with the next note or measure. However, he found that he had very little information about his own style and instead,
根據庫普的說法,他是由于作曲家的阻撓而開始進行這些實驗的。 他需要一個程序來理解他的音樂整體風格,并為他提供下一個音符或小節 。 但是,他發現自己對自己風格的了解很少,相反,
I began creating computer programs which composed complete works in the styles of various classical composers, about which I felt I knew something more concrete.
我開始創建計算機程序,這些程序以各種古典作曲家的風格構成完整的作品,對此我感到我知道更具體的東西。
So, Cope began writing EMI in Lisp, a functional programming language created in the mid-1900s. He developed it on three key principles:
因此,Cope開始用Lisp(一種在1900年代中期創建的功能性編程語言)編寫EMI。 他根據三個關鍵原則進行了開發:
- Deconstruction — analyzing the music and separating it into parts 解構—分析音樂并將其分成幾部分
- Signatures — identifying commonalities for a given composer and retaining the parts that signify their style 簽名-識別給定作曲家的共性并保留表示其風格的部分
- Compatibility — recombining the pieces into a new piece 兼容性—將片段重組為新片段
After seven years of work Cope finally finished a version of EMI to imitate the style of Johann Sebastian Bach and, in a single day, it was able to compose 5,000 works in Bach’s style. Of these, Cope selected a few which were performed in Santa Cruz without informing the audience that they were not authentic works of Bach.
經過7年的工作,Cope最終完成了EMI的版本,以模仿Johann Sebastian Bach的風格,并且一天之內就可以創作出5,000幅Bach風格的作品 。 其中,科普選擇了一些在圣克魯斯(Santa Cruz)演出的作品,而沒有告知觀眾他們不是巴赫的真實作品。

After praising the wonderful performance, the audience was told that these were created by a computer, and a significant proportion of the audience, and the wider music community, reacted with anger.
在贊揚了精彩的表演之后,聽眾被告知這是由計算機制作的,很大比例的聽眾以及更廣泛的音樂界對此感到憤怒。
In particular, Professor Steve Larson from the University of Oregon proposed to Cope a challenge. In October 1997 Larson’s wife, the pianist Winifred Kerner performed three pieces of music in front of hundreds of students in the University of Oregon’s concert hall. One was composed by Bach, one by Larson and one by EMI.
俄勒岡大學的史蒂夫·拉森教授特別提出了應對挑戰的建議。 1997年10月,拉爾森的妻子,鋼琴家Winifred Kerner在俄勒岡大學音樂廳的數百名學生面前演奏了三首音樂。 其中一位由巴赫組成,一位由拉爾森(Larson)組成,另一位由EMI(EMI)組成。
At the end of the concert, the audience was asked to guess which piece was by which composer. To Larson’s dismay, the audience thought EMI’s piece was composed by Bach, Bach’s piece by Larson and Larson’s piece by EMI.
音樂會結束時,要求觀眾猜測是哪個作曲家創作的。 令拉森沮喪的是,觀眾們認為EMI的作品是巴赫的作品,巴赫的作品是拉森的作品,拉森的作品是EMI的作品。
This is possibly one of the most successful stories of a computer imitating human creativity. (Have a listen to some of the pieces and you will be hardpressed to notice any difference between EMI and a human composer.) However, what makes EMI great at imitation is also what makes it bad at innovation. Just like GANs, they are imitating to the detriment of innovation.
這可能是計算機模仿人類創造力最成功的故事之一。 ( 聽一些文章,您將很難注意到EMI和人類作曲家之間的任何區別。)但是,使EMI在模仿方面表現出色的原因也在于在創新方面不利的原因。 就像GAN一樣,它們在模仿創新。
4.偽裝肖像 (4. POEMPORTRAITS)
In 2016, artist and designer Es Devlin met with Hans-Ulrich Obrist, Artistic Director of the Serpentine Galleries in London, to discuss what original and creative ideas they could come up with for the Serpentine Gala in 2017. Devlin decided to collaborate with Google Art & Culture Lab and Ross Goodwin to create POEMPORTRAITS.
2016年 ,藝術家兼設計師Es Devlin與倫敦蛇形畫廊藝術總監Hans-Ulrich Obrist會面,討論他們在2017年的蛇形藝術晚會上可以提出哪些原創和創意。Devlin決定與Google Art合作與文化實驗室和羅斯古德溫一起創建POEMPORTRAITS 。
POEMPORTRAITS asks users to donate a word, then uses the word to write a poem. This poem is then overlaid onto a selfie taken by the user.
POEMPORTRAITS要求用戶捐贈一個單詞,然后使用該單詞寫一首詩 。 然后將這首詩覆蓋在用戶拍攝的自拍上。
According to Devlin,
據德夫林說,
“the resulting poems can be surprisingly poignant, and at other times nonsensical.”
“由此產生的詩詞可能令人驚訝地凄美,有時甚至是荒謬的。”
These poems are then added to an ever-growing collective poem, containing all POEMPORTRAITS’ generated poems.
然后將這些詩歌添加到不斷增長的集體詩歌中,其中包含所有POEMPORTRAITS生成的詩歌。

I tried it myself, donating the word ‘fluorescent’. You can see my POEMPORTRAIT above.
我自己嘗試過,捐贈了“熒光燈”一詞。 您可以在上方看到我的POEMPORTRAIT。
Before he collaborated with Google and Devlin, Goodwin had been experimenting with text generation. His code is available on GitHub and includes two pre-trained LSTM (Long Short-Term Memory) models for poem generation, which were used as a base for POEMPORTRAIT.
在與Google和Devlin合作之前, Goodwin一直在嘗試生成文本。 他的代碼可在GitHub上獲得 ,其中包括兩個用于詩生成的經過預先訓練的LSTM( 長短期記憶 )模型,這些模型被用作POEMPORTRAIT的基礎。
An LSTM is a type of recurrent neural network (RNN) that determines which word connections should be persisted further into a text to ensure the model understands the association between words.
LSTM是一種遞歸神經網絡 (RNN),它確定哪些單詞連接應進一步保留到文本中,以確保模型能夠理解單詞之間的關聯。
For example, in the sentence “The car was great, so I decided to buy it,” the model will learn that the word ‘it’ refers to the word ‘car. This is a step beyond earlier models which only considered relations between words within a given distance of each other.
例如,在句子“汽車很棒,所以我決定購買它”中 ,模型將得知單詞“ it”是指單詞“ car”。 這是較早的模型的一個步驟,該模型僅考慮彼此之間給定距離內的單詞之間的關系。

For POEMPORTRAIT, the LSTM model was trained on over 25 million words, written by 19th-century poets, to build a statistical model that essentially predicts the next word given a word or set of words. Hence, the donated word acts as a seed to which words are added, producing prose in the style of 19th-century poetry.
對于POEMPORTRAIT,LSTM模型接受了19世紀詩人撰寫的超過2500萬個單詞的訓練,從而建立了一個統計模型,該模型本質上可以預測給定一個單詞或一組單詞的下一個單詞。 因此,捐贈的單詞充當添加單詞的種子,從而產生了19世紀詩歌風格的散文。
Unfortunately, there have not been any experiments on humans to qualitatively measure the effectiveness of POEMPORTRAITS at imitating human poets.
不幸的是,還沒有關于人類的實驗來定性地評估POEMPORTRAITS在模仿人類詩人方面的有效性。
It is clear that these are not just a random string of words, but follow (at least loosely) a set of language rules learned by the LSTM models. However, one can argue that poetry (and the same argument can be made for painting and music) is the culmination of human emotion.
顯然,這些不僅僅是單詞的隨機字符串,而且(至少是寬松地)遵循LSTM模型學習的一組語言規則。 但是,人們可以辯稱,詩歌(繪畫和音樂也可以提出同樣的論點)是人類情感的高潮。
5.互動圖形 (5. Interactive graphics)
A group of researchers from NVIDIA released a paper in 2018 detailing Video-to-Video Synthesis, a process whereby a model generates a new video based on a training video or set of training videos.
NVIDIA(英偉達)的一組研究人員于2018年發表了一篇論文 ,詳細介紹了Video-to-Video Synthesis ,該過程是模型根據訓練視頻或一組訓練視頻生成新視頻的過程。
As well as making their work publicly available on their GitHub repo, an physical, interactive prototype was showcased at the NeurIPS conference in Montreal, Canada. This prototype was a simple driving simulator, in a world where the graphics had been designed entirely by a machine learning model.
除了在GitHub存儲庫上公開提供其工作外, 還在加拿大蒙特利爾的NeurIPS會議上展示了一個物理,交互式原型。 這個原型是一個簡單的駕駛模擬器,在這個世界中,圖形完全是由機器學習模型設計的。
To build this prototype they first took training data from an open-source dataset created for the training of autonomous vehicles. This dataset was then segmented into different objects (trees, cars, road, etc.) and a GAN was trained on these segments so that it could generate its own versions of these objects.
為了構建此原型,他們首先從用于訓練自動駕駛汽車的開源數據集中獲取了訓練數據。 然后將此數據集分割為不同的對象(樹木,汽車,道路等),并在這些段上對GAN進行了訓練,以便可以生成自己的這些對象版本。
Using a standard game engine, Unreal Engine 4, they created a framework for their graphical world. Then, the GAN generated objects for each category of item in real-time as needed.
他們使用標準游戲引擎Unreal Engine 4創建了用于圖形世界的框架。 然后,GAN根據需要實時為每個類別的項目生成對象。

In some sense, this may seem similar to any other computer-generated image created by a GAN (or CAN). We saw two examples of these earlier in this article.
從某種意義上講,這似乎與GAN(或CAN)創建的任何其他計算機生成的圖像相似。 在本文前面的部分中,我們看到了兩個示例。
However, the researchers realized that regenerating the entire world for each frame led to inconsistencies. Although a tree would appear in the same position in each frame, the image of the tree itself would change as it was being regenerated by the model.
但是,研究人員意識到,為每個幀重新生成整個世界會導致不一致。 盡管一棵樹將在每個幀中出現在相同的位置,但是由于模型正在重新生成,樹本身的圖像將發生變化。
To solve this, the researchers added a short term memory to the model, ensuring that the objects remained somewhat consistent between frames.
為了解決這個問題,研究人員在模型中添加了一個短期記憶,以確保對象在幀之間保持一定的一致性。
Unlike all our previous example, video games may have a slightly different goal. The models don’t have to innovate in the same way an artist innovates when they create a new piece, and, generally speaking, there doesn’t need to be any emotion behind the output.
與我們之前的所有示例不同,視頻游戲的目標可能會稍有不同。 這些模型不必像藝術家創作新作品時那樣進行創新,通常來說,輸出后不需要任何情感。
Instead, gamers will want models to depict a realistic-looking world for them to play in. However, in this case, the model was extremely computationally expensive and the demo only ran at 25 frames per second. As well as this, despite being in 2K the images display the characteristic blurriness of GAN generated images.
取而代之的是,游戲玩家希望模型能夠描繪出逼真的世界供他們玩。但是,在這種情況下,模型的計算量非常大,因此演示僅以每秒25幀的速度運行。 不僅如此,盡管圖像大小為2K,但仍顯示GAN生成圖像的特征模糊。
Unfortunately, according to Bryan Catanzaro, NVIDIA’s Vice Chairman of Applied Deep Learning, it will likely be decades before AI-produced graphics are used in consumer games.
不幸的是, 根據 NVIDIA應用深度學習副主席Bryan Catanzaro所說,在消費者游戲中使用AI生產的圖形可能要幾十年了。
AI is starting to contribute to all areas of the art world, as we can see from the examples above. However, the question remains as to whether these innovations are truly—well, innovative.
從上面的示例可以看出,人工智能開始為藝術世界的所有領域做出貢獻。 但是,問題仍然在于這些創新是否是真正的,很好的創新。
Are these models effective imitators?
這些模型是有效的模仿者嗎?
We saw in several cases, including AICAN and EMI that computers can generate outputs that fool humans. However, especially for painting, this may be limited to particular styles.
我們在包括AICAN和EMI在內的幾種情況下看到,計算機可以產生愚弄人類的輸出。 但是,尤其是對于繪畫,這可能僅限于特定樣式。
The outputs of generative models (GANs and CANs) generally do not create solid and well-defined lines, meaning images are often blurry. This can be effective for certain styles (say, abstract art) but not for others (say, portraiture).
生成模型(GAN和CAN)的輸出通常不會創建實線和輪廓分明的線,這意味著圖像通常很模糊。 這可能對某些樣式(例如抽象藝術)有效,但對其他樣式(例如肖像畫)無效。

Are these models innovating?
這些模式在創新嗎?
Innovation is a key characteristic of humans, but it is often hard to define. We clearly saw how CANs tried to add innovation by adapting GANs to penalize unoriginality, but one can still argue that the output is a culmination of whatever training data the model was fed.
創新是人類的關鍵特征,但通常很難定義。 我們清楚地看到了CAN如何通過調整GAN來懲罰原始性來嘗試增加創新,但是仍然可以說輸出是模型輸入的任何訓練數據的最終產物。
On the other hand, are humans ideas not the culmination of human past experiences, our own training data so to speak?
另一方面,人類的思想不是人類過去的經驗的結晶嗎?可以說我們自己的訓練數據嗎?
Finally, does art require human emotion?
最后,藝術需要人類的情感嗎?
One thing is for certain, none of the pieces in the examples above were generated with any emotional intelligence. In mediums such as poetry and art, the story and emotion behind a piece, instilled by the author, is often what makes it resonate with others.
可以肯定的是,以上示例中的任何部分都不是由任何情商生成的。 在詩歌和藝術等媒介中,作者所灌輸的作品背后的故事和情感常常使之與他人產生共鳴。
Without this emotional intelligence by the author, can a piece of art be truly appreciated by its audience?
如果沒有作者的這種情感智慧,藝術品能不能真正受到觀眾的欣賞?
Perhaps the real question is, does it matter?
也許真正的問題是,這有關系嗎?
In a world as subjective as the art world perhaps computers don’t have to definitively imitate or innovate but can find their own unique place alongside humans.
在像藝術世界這樣的主觀世界中,計算機不必一定要模仿或創新,而可以在人類旁邊找到自己獨特的地方。
If you enjoyed this, you might like another article I wrote, “Is AI Changing the Face of Modern Medicine?”.
如果喜歡這個,您可能會喜歡我寫的另一篇文章,“ AI是否正在改變現代醫學的面貌? ”。
翻譯自: https://medium.com/swlh/is-fine-art-the-next-frontier-of-ai-64645f95bef8
ai前沿公司
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388651.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388651.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388651.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

查看修改swap空間大小

關于WKWebView高度的問題的解決
)
測試nignx php請求并發數,nginx 優化(突破十萬并發)

多米諾骨牌v.1MEL語言

THINKPHP3.2視頻教程

mardown 標題帶數字_標題中帶有數字的故事更成功嗎?

897. 遞增順序查找樹-未解決
 并行開關機Azure ARM VM)
Azure PowerShell (16) 并行開關機Azure ARM VM

使用Pandas 1.1.0進行穩健的2個DataFrames驗證


織夢在線報名平臺php,DedeCMSv5

pom.xml文件詳解


置信區間的置信區間_什么是置信區間,為什么人們使用它們?

事實上著就是MAYA4.5完全手冊插件篇的內容

制作alipay-sdk-java包到本地倉庫

php中wlog是什么意思,d-log模式是什么意思
:如何快速地掌握PowerShell?)
PowerShell入門(三):如何快速地掌握PowerShell?
了解您的數據并發現潛在模式)
