Pandas is one of the most used Python library for both data scientist and data engineers. Today, I want to share some Python tips to help us do qualification checks between 2 Dataframes.
Pandas是數據科學家和數據工程師最常用的Python庫之一。 今天,我想分享一些Python技巧,以幫助我們在2個數據框之間進行資格檢查。
Notice, I have used the word: qualification, instead of identical. Identical is easy to check, but qualification is a loose check. It is based on business logic. Therefore, it is harder to implement.
注意,我使用了單詞: qualification ,而不是完全相同。 相同很容易檢查,但資格是一個寬松的檢查。 它基于業務邏輯。 因此,很難實現。
不重新發明輪子 (Not reinvent the wheel)
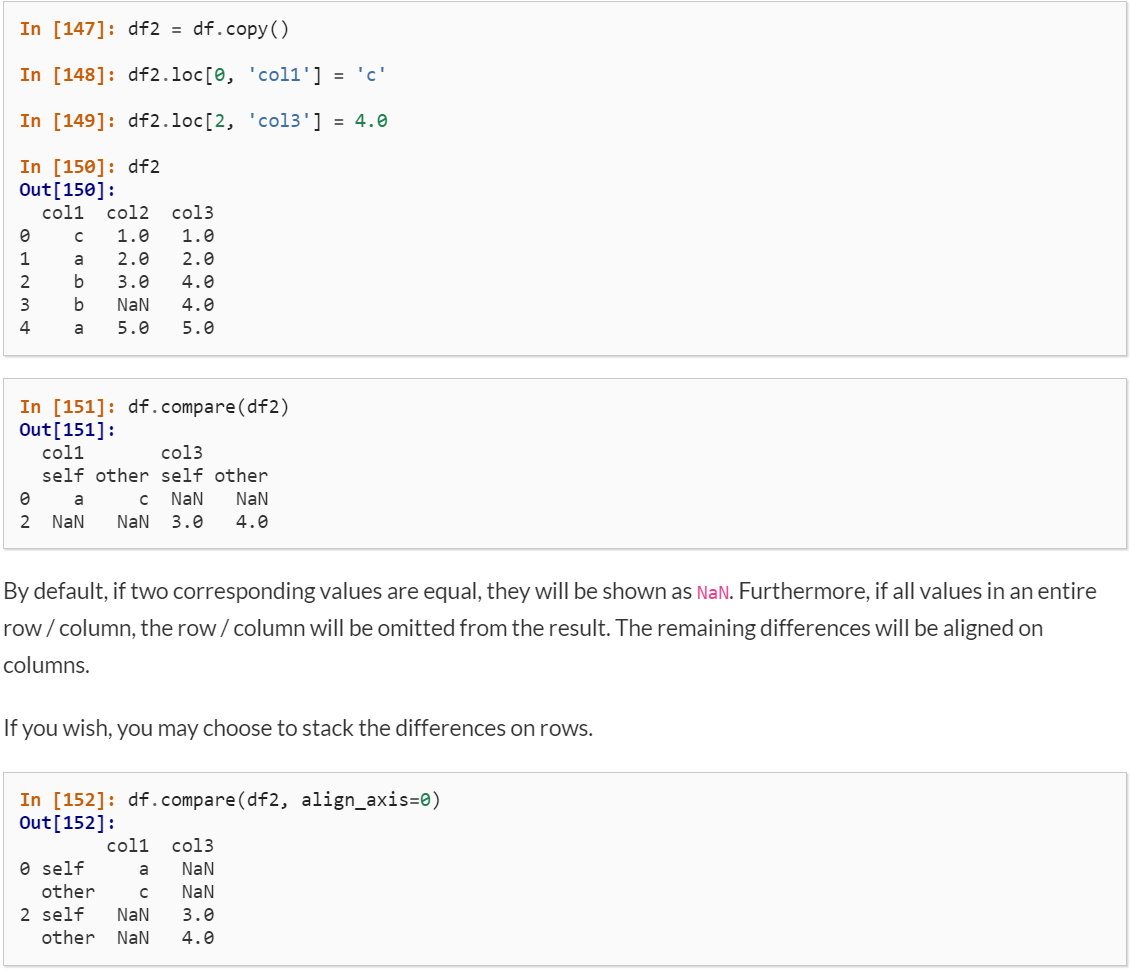
In version 1.1.0 — released on July 28 2020, 8 days before — Pandas introduced the build-in compare function. All our following steps are built based on it.
在2020年7月28日發布的版本1.1.0(比之前晚8天)中,Pandas引入了內置比較功能 。 我們下面的所有步驟均基于此構建。
Tips: if you were using Anacondas distribution, you should use the following command line to upgrade your Pandas version.
提示 :如果使用的是Anacondas發行版,則應使用以下命令行升級Pandas版本。
低掛水果 (Low hanging fruit)
Always check number of columns between 2 frames first. In cases, this simple check could spot issues.
請務必先檢查2幀之間的列數。 在某些情況下,此簡單檢查可能會發現問題。
In certain scenarios, such as enrichment change, we could have a different number of columns. The definition of qualification could be: for all the former columns having the same value between 2 data frames. Therefore, we will identify columns to check and save them in variable Columns for later usage.
在某些情況下,例如富集變化,我們可以有不同數量的列。 資格的定義可以是:對于所有先前的列,在2個數據幀之間具有相同的值。 因此,我們將確定要檢查的列并將其保存在變量Columns中,以備后用。
解鎖鑰匙 (Keys to unlock)
In real application, we would have various ids to identify a record, such as user-id, order_id etc. In order to make a unique query, we may need to use a combination of these keys. Ultimately, we want to verify records with the same keys have the same column values.
在實際應用中,我們將使用各種ID來標識一條記錄,例如user-id,order_id等。為了進行唯一查詢,我們可能需要使用這些鍵的組合。 最終,我們要驗證具有相同鍵的記錄具有相同的列值。
The first step is to compose the key combination. This is where the DataFrame apply shines. We could use df.apply(lambda: x: func(x), axis = 1) to make any data transformation. With axis = 1, we are telling Pandas to do the same operation row by row. (axis = 0, column by column)
第一步是組合鍵。 這是DataFrame 應用的亮點。 我們可以使用df.apply(lambda:x:func(x), axis = 1 )進行任何數據轉換。 當axis = 1時 ,我們告訴Pandas 逐行執行相同的操作。 (軸= 0,逐列)
處理ValueError (Handle the ValueError)
For the new DataFrame.compare function, the following error is the most confusing. Let me try to explain.
對于新的DataFrame.compare函數,以下錯誤最令人困惑。 讓我嘗試解釋一下。
ValueError: Can only compare identically-labeled DataFrame objects
ValueError :只能比較標記相同的DataFrame對象
The reason for this error, is the shape and the order of columns between two data frames is not identical. Yes. DataFrame.compare works only for identical checking, not qualification checking.
此錯誤的原因是兩個數據幀之間的列的形狀和順序不相同。 是。 DataFrame.compare僅適用于相同檢查,而不適用于資格檢查。
The way to solve the issue is: use the keyColumn created before, compare for a subset between the DataFrames with the same keyColumn value. And do that for each keyColumn value.
解決該問題的方法是:使用之前創建的keyColumn ,比較具有相同keyColumn值的DataFrame之間的子集。 并對每個keyColumn值執行此操作。
If the dimensions for keyColumn from 2 DataFrames are different, raise the issue and skip the check.
如果來自2個數據幀的keyColumn的尺寸不同,請提出問題并跳過檢查。
帶走: (Take Away:)
Use latest Pandas 1.1.0 DataFrame.compare to do robust DataFrame qualification checks. In order to deal with ValueError, we use keyColumn to do multiple sub DataFrame checks and return the final decision.
使用最新的Pandas 1.1.0 DataFrame.compare進行可靠的DataFrame資格檢查。 為了處理ValueError,我們使用keyColumn進行多個子DataFrame檢查并返回最終決定。
翻譯自: https://towardsdatascience.com/robust-2-dataframes-verification-with-pandas-1-1-0-af22f328e622
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388642.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388642.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388642.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


織夢在線報名平臺php,DedeCMSv5

pom.xml文件詳解


置信區間的置信區間_什么是置信區間,為什么人們使用它們?

事實上著就是MAYA4.5完全手冊插件篇的內容

制作alipay-sdk-java包到本地倉庫

php中wlog是什么意思,d-log模式是什么意思
:如何快速地掌握PowerShell?)
PowerShell入門(三):如何快速地掌握PowerShell?
了解您的數據并發現潛在模式)
pca 主成分分析_通過主成分分析(PCA)了解您的數據并發現潛在模式


UML-- plantUML安裝

php不發送referer,php – 注意:未定義的索引:HTTP_REFERER
)
HDU 最大報銷額 (0 1 背包)
)
rstudio 關聯r_使用關聯規則提出建議(R編程)
: worker exit timeout, forced to terminate)
PHP進程1608占用了9012,swoole (ERRNO 9012): worker exit timeout, forced to terminate

C#高級應用之CodeDomProvider引擎篇 .

linux—命令匯總

flex 添加右鍵鏈接
