python中api
工作技能世界 (The World of Job Skills)
So you want to figure out where your skills fit into today’s job market. Maybe you’re just curious to see a comprehensive constellation of job skills, clean and standardized. Or you need a taxonomy of skills for a Resume parsing project. Well, the EMSI skills API is one possible tool for the job!
因此,您想弄清楚自己的技能適合當今的就業市場。 也許您只是好奇地看到一個完整,標準化的工作技能組合。 或者,您需要針對簡歷解析項目的技能分類。 嗯, EMSI技能API是一項可行的工具!
In this tutorial, I’ll walk you through some boilerplate code you can use to access a few key endpoints from the API: a global list of skills, skill extraction from a document, skill lookup by name, and lastly finding related skills by skill ID. Let’s get started.
在本教程中,我將指導您完成一些樣板代碼,您可以使用這些樣板代碼從API訪問一些關鍵端點: 技能的全局列表,從文檔中提取技能,按名稱查找技能以及最后按技能查找相關技能ID 。 讓我們開始吧。
建立 (Setup)
Getting started is as easy as signing up for the API’s free access. You’ll get authentication credentials emailed to you once you complete that process.
入門就像注冊 API的免費訪問一樣容易。 完成該過程后,您將通過電子郵件將身份驗證憑據發送給您。
進口聲明 (Import Statements)
We’ll use a few packages here, so let’s import those first:
我們將在此處使用一些軟件包,因此讓我們首先導入它們:
All of these are pretty standard. I’m using the json_normalize package which is an easy means of converting JSON to Pandas DataFrames, which will be nicer for readability.
所有這些都是相當標準的。 我正在使用json_normalize包,這是將JSON轉換為Pandas DataFrames的一種簡便方法,這對于可讀性會更好。
驗證您的連接 (Authenticating Your Connection)
The first part of accessing the API is simply using the credentials in that signup email to establish a connection and get an access token. I ran the following in a cell in a Jupyter Notebook with Python.
訪問API的第一部分只是使用注冊電子郵件中的憑據來建立連接并獲取訪問令牌。 我在使用Python的Jupyter Notebook的單元格中運行了以下內容。
Sidenote: if my code blocks (like the one above) are cut off, please follow the source link in their caption to read the full code!
旁注:如果我的代碼塊(如上面的代碼塊)被切除,請按照其標題中的源鏈接閱讀完整的代碼!
This code results in an authentication JSON object, where one of the keys is the access_token. Here I’ve explicitly accessed the value of that key and assigned it to a variable of the same name for later use.
這段代碼生成一個身份驗證JSON對象,其中的鍵之一是access_token 。 在這里,我已顯式訪問該鍵的值,并將其分配給同名變量,以供以后使用。
“你好,世界!” EMSI的技能API (The “Hello, World!” of EMSI’s Skills API)
EMSI has multiple APIs, but we’ll be focused on the Skills API in this tutorial. To get started, we’re just going to use that access token to pull the full list of skills available to us.
EMSI有多個API,但是在本教程中我們將重點介紹Skills API。 首先,我們將使用該訪問令牌提取可供我們使用的完整技能列表。
拉全球職業技能清單 (Pull the Global List of Job Skills)
I wrote a simple function to pull the skills list and write it to a Pandas DataFrame for nicer formatting and readability.
我編寫了一個簡單的函數來提取技能列表,并將其寫入Pandas DataFrame,以獲得更好的格式和可讀性。
I set the url to the skills list endpoint, concatenated the access token in with the necessary syntactical specifications for the API, and used the requests library to get the data. This results in the following global list of skills:
我將URL設置為技能列表端點,將訪問令牌與API的必要語法規范連接在一起,并使用請求庫獲取數據。 這將產生以下全局技能列表:
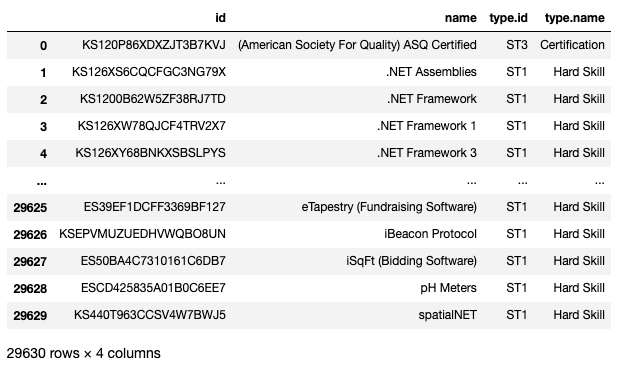
You can see here there are both hard and soft skills, each skill has a unique ID, and each skill is standardized and proper cased. Each skill type has a type ID as well. There are nearly 30,000 skills listed here!
您可以在此處看到硬技能和軟技能,每種技能都有唯一的ID,并且每種技能都經過標準化和適當的區分。 每個技能類型也都有一個類型ID。 這里列出了將近30,000種技能!
提取給定文檔中出現的技能 (Extract the Skills That Appear in a Given Document)
Say instead you have a document (a resume or job description for example), and you want to find relevant skills that the resume holder has or the job poster wants. The following function will prompt you for a text input. Paste the text in there and set a confidence interval between 0 and 1 (I usually do 0.4 to see a longer list of skills), and voilà — skills extracted!
假設您有一個文檔(例如,一份簡歷或職位描述),并且想找到簡歷持有人或職位發布者想要的相關技能。 以下功能將提示您輸入文本。 在其中粘貼文本,并在0到1之間設置一個置信區間(通常我會做0.4來查看更多的技能列表),然后瞧瞧-提取出來的技能!
I had typed “python and such” as a simple example, which returned this skill extraction with a 100% (1.0) confidence level to no surprise:
我以簡單的示例輸入了“ python之類”,它以100%(1.0)的置信度返回了此技能提取,這并不奇怪:

This is all well and good. But what if you want to find how a skill is referred to in this taxonomy? Well, there’s an API that finds related skills by ID, but we need to know the ID first! Let’s find that now.
這一切都很好。 但是,如果您想查找此分類法中如何提及一項技能,該怎么辦? 嗯,有一個API可通過ID查找相關技能,但我們需要首先了解ID! 讓我們現在找到它。
通過名稱查找技能以找到其ID (Look Up a Skill by Name to find its ID)
The following code uses Python’s str.contains method to find skills that contain the substring entered as an argument to the function.
以下代碼使用Python的str.contains方法查找包含包含作為函數參數輸入的子字符串的技能。
As you can see, using the str.contains(name_substring) method results in finding all skills that have the word Python in it. This allows us to see the full range of possibilities and select the IDs of the ones we want to find related skills for. The DataFrame returned by the above function is shown below:
如您所見,使用str.contains(name_substring)方法會發現其中包含單詞Python所有技能。 這使我們能夠看到所有可能性,并選擇我們想要查找相關技能的ID。 上面的函數返回的DataFrame如下所示:
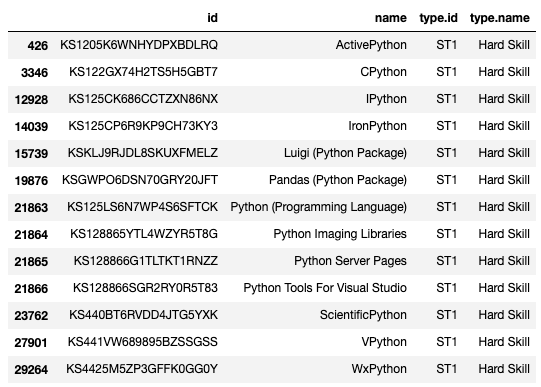
There is a lot of granularity here! Let’s next find related skills to Pandas and Python as an example by grabbing their IDs and inputting them into the next block of code.
這里有很多粒度! 接下來,讓我們通過獲取它們的ID并將其輸入到下一個代碼塊中,來找到與Pandas和Python相關的技能作為示例。
查找與技能相關的技能 (Find Related Skills to a Skill)
We have our IDs for the skills of interest. Now we want to find related skills to them. I’ve added the IDs of the skills in question to the code in the payload and as comments at the top of the following code block. If you want to add more, pay close attention to the formatting of payload. It escapes the “ and other nuances like needing the spacing before the closing }.
我們擁有感興趣技能的ID。 現在,我們想找到與他們相關的技能。 我已經將有關技能的ID添加到有效負載中的代碼中,并在以下代碼塊的頂部作為注釋。 如果要添加更多內容,請密切注意payload的格式。 它避免了“”和其他細微差別,例如在結束}前需要間隔。
We saw in the previous output of skills involving the word Python that there were many options. I chose to find skills related to Python and Pandas. The resultant DataFrame is shown below:
在前面涉及Python的技能輸出中,我們看到了很多選擇。 我選擇查找與Python和Pandas相關的技能。 結果數據框如下所示:
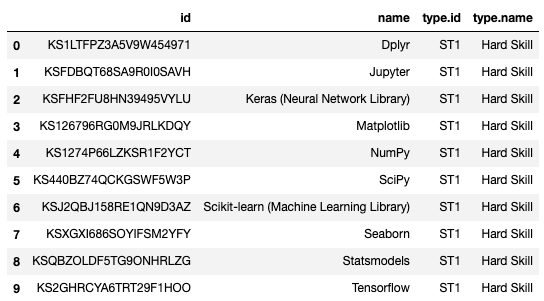
This is great performance! It shows us other Python packages essentially, including NumPy which almost always accompanies Pandas in our import statements in Data Science!
這是很棒的表現! 它從本質上向我們展示了其他Python軟件包,包括NumPy,它幾乎總是在數據科學中的import語句中伴隨Pandas!
結論和未來的工作 (Conclusion and Future Work to be Done)
Thanks for reading this quick tutorial on the EMSI Skills API. I hope you found it useful for whatever your use case may be. If you want to see this developed in a specific further direction, please leave me a comment below! There are many more interesting datasets from EMSI as well that are worth checking out, including those with information on the labor markets, job postings, and much more.
感謝您閱讀有關EMSI Skills API的快速教程。 我希望您發現它對您的用例可能有用。 如果您想看到這個方向的進一步發展,請在下面給我留言! 有來自許多EMSI更有趣的數據集,以及那些值得檢查,包括那些在勞動力市場信息,招聘信息,以及更多 。
For the next steps, I can re-engineer the related skills code block so that it’s a function, taking in a list of skill IDs as keyword arguments and adding them into the payload. Right now it’s a little finicky and not standardized. I’d like to engineer this into a module, where a connection is a class, and utilization of each endpoint is a method with more robust attributes and arguments. That would certainly save many lines of code.
對于下一步,我可以重新設計相關的技能代碼塊,使其成為一個功能,將技能ID的列表作為關鍵字參數,并將其添加到有效負載中。 現在,它有點挑剔且不規范。 我想將其設計到一個模塊中,其中連接是一個類,每個端點的利用是一種具有更可靠的屬性和參數的方法。 那肯定會節省很多行代碼。
But till next time — happy coding!
但是直到下一次-編碼愉快!
Riley
賴利
翻譯自: https://towardsdatascience.com/finding-relevant-job-skills-via-api-in-python-ced56cbb3493
python中api
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388538.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388538.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388538.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
識別欺詐性的招聘廣告)
欺詐行為識別_使用R(編程)識別欺詐性的招聘廣告

PE文件的感染C++源代碼

c語言實驗四報告,湖北理工學院14本科C語言實驗報告實驗四數組


rabbitmq channel參數詳解【轉】
)
感染EXE文件代碼(C++)

nlp gpt論文_GPT-3:NLP鎮的最新動態

真實不裝| 阿里巴巴新人上路指北


tomcat java環境配置

uber 數據可視化_使用R探索您在Uber上的活動:如何分析和可視化您的個人數據歷史記錄
Ribbon)
java B2B2C springmvc mybatis電子商城系統(四)Ribbon

c語言函數的形參有幾個,C中子函數最多有幾個形參

Linux上Libevent的安裝

Win7安裝oracle 10 g
![基于plotly數據可視化_[Plotly + Datashader]可視化大型地理空間數據集](http://pic.xiahunao.cn/基于plotly數據可視化_[Plotly + Datashader]可視化大型地理空間數據集)
基于plotly數據可視化_[Plotly + Datashader]可視化大型地理空間數據集

Centos用戶和用戶組管理

吹氣球問題的C語言編程,C語言怎樣給一個數組中的數從大到小排序

