nlp gpt論文
什么是GPT-3? (What is GPT-3?)
The launch of Open AI’s 3rd generation of the pre-trained language model, GPT-3 (Generative Pre-training Transformer) has got the data science fraternity buzzing with excitement!
Open AI的第三代預訓練語言模型GPT-3(生成式預訓練變壓器)的發布使數據科學界的關注度高漲!
The world of Language Models (LM) is quite fascinating. To give a brief introduction, these models learn the probabilities of a sequence of words that occur in a commonly spoken language (say, English) and predict the next possible word in that sequence. They are essential for numerous NLP tasks like:
語言模型(LM)的世界非常迷人。 為了簡要介紹,這些模型學習了以常用口語(例如英語)出現的單詞序列的概率,并預測了該序列中的下一個可能單詞。 它們對于許多NLP任務至關重要,例如:
- Language Translation 語言翻譯
- Text Classification 文字分類
- Sentiment Extraction 情感提取
- Reading Comprehension 閱讀理解
- Named Entity Recognition 命名實體識別
- Question Answer Systems 問答系統
- News Article Generation, etc 新聞文章生成等
They’ve become immensely popular since the release of BERT by Google, with a host of companies competing to build the next big thing in the NLP domain!
自Google發行BERT以來,它們已經變得非常受歡迎,許多公司競相在NLP領域打造下一個重要產品!
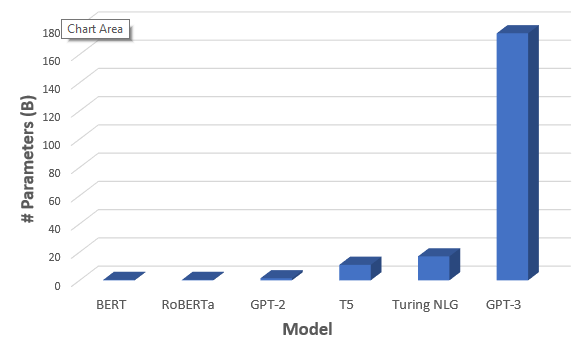
Open AI’s GPT-3 is the largest Language Model having 175 BN parameters, 10x more than that of Microsoft’s Turing NLG
Open AI的GPT-3是最大的語言模型,具有175個BN參數,是Microsoft Turing NLG的10倍以上
Open AI has been in the race for a long time now. The capabilities, features and limitations of their latest edition, GPT-3, has been described in a detailed research paper. Its predecessor GPT-2 (released in Feb 2019) was trained on 40GB of text data and had 1.5 BN parameters. In comparison, GPT-3 has a whopping 175 BN parameters, 10 times more than the next largest LM, the Turing NLG, developed by Microsoft with 17 BN parameters!
開放式AI競賽已經有很長時間了。 最新研究版本GPT-3的功能,特性和局限性已在一份詳細的研究論文中進行了描述。 它的前身GPT-2 (于2019年2月發布)接受了40GB文本數據的訓練,參數為1.5BN。 相比之下,GPT-3的參數高達175個BN,是第二大LM圖靈NLG的十倍,圖靈NLG是由微軟開發的具有17個BN參數的!
GPT-3 is based on the concepts of transformer and attention similar to GPT-2. It has been trained on a large and variety of data like Common Crawl, web texts, books and Wikipedia, based on the tokens from each data. Prior to training the model, the average quality of the datasets has been improved in 3 steps.
GPT-3基于變壓器和注意力的概念 類似于GPT-2。 根據每個數據的標記,已經針對大量數據(例如Common Crawl ,Web文本,書籍和Wikipedia)進行了培訓。 在訓練模型之前,數據集的平均質量已通過3個步驟得到了改善。
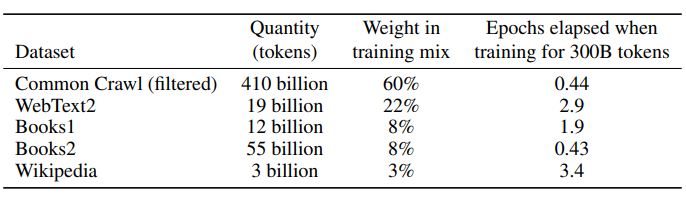
The following table shows the training corpus of GPT-3:
下表顯示了GPT-3的訓練語料庫:
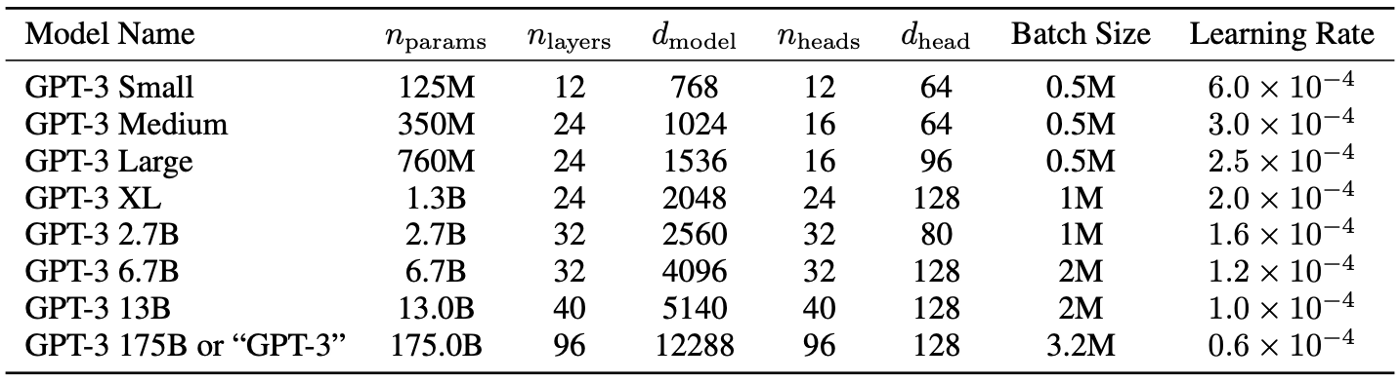
GPT-3 has variants in terms of
GPT-3在以下方面具有變體
- Sizes (Parameters and Layers) 大小(參數和層)
- Architectures 建筑學
- Learning hyper-parameters (batch size in tokens and learning rate) ranging from 125 MN to 175 BN parameters 學習超參數(令牌的批量大小和學習率)范圍從125 MN到175 BN參數
“The largest version of GPT-3 has 175 BN Parameters, 96 Attention Layers and 3.2 MN Batch Size”
“ GPT-3的最大版本具有175 BN參數,96個注意層和3.2 MN批處理大小”
Here are the details of the different variants of GPT-3 model:
以下是GPT-3模型的不同變體的詳細信息:
它能做什么? (What can it do?)
Many of the NLP tasks discussed in this blog can be performed by GPT-3 without any gradient, parameter updates or fine-tuning. This makes it a Task-Agnostic Model as it can perform tasks without any or very few prompts or examples or demonstrations called shots.
GPT-3可以執行此博客中討論的許多NLP任務,而無需進行任何漸變,參數更新或微調。 這使其成為與任務無關的模型,因為它可以執行任務而無需任何或很少的提示,示例或稱為鏡頭的演示。
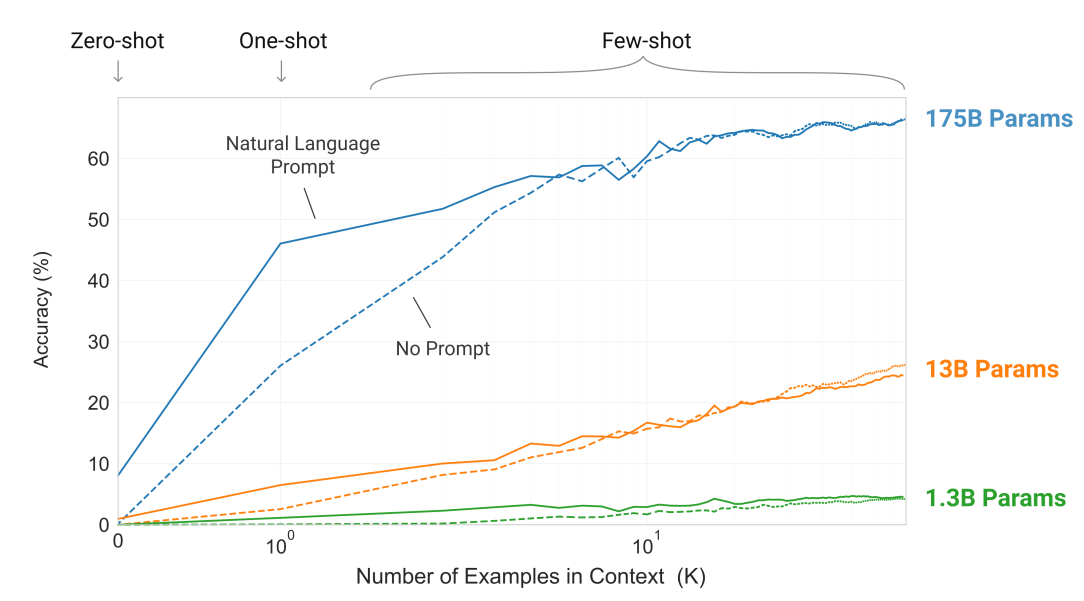
The following image displays a Zero / One / Few-Shot based task accuracy comparison for various sizes of the model (in terms of parameters) for a simple task to remove random symbols from a word with the number of in-context examples ranging between 10 to 100.
下圖顯示了針對零模型,零模型,零模型的任務準確性比較,該模型針對各種大小的模型(就參數而言),以完成一項簡單任務,以從單詞中刪除隨機符號,上下文中示例的數量在10個之間到100。
“假新聞”難題 (The “Fake News” Conundrum)
Earlier, the release of the largest model of GPT-2 was briefly stalled due to a controversial debate of it being capable of generating fake news. It was later published on Colab notebooks. In recent times, however, this has been quite common and the real news themselves have been hard to believe!
早些時候,由于有爭議的關于GPT-2能夠產生假新聞的爭議,GPT-2的最大型號的發布暫時停止了。 后來發表在Colab筆記本上 。 但是,最近這種情況已經很普遍了,真正的新聞本身很難讓人相信!
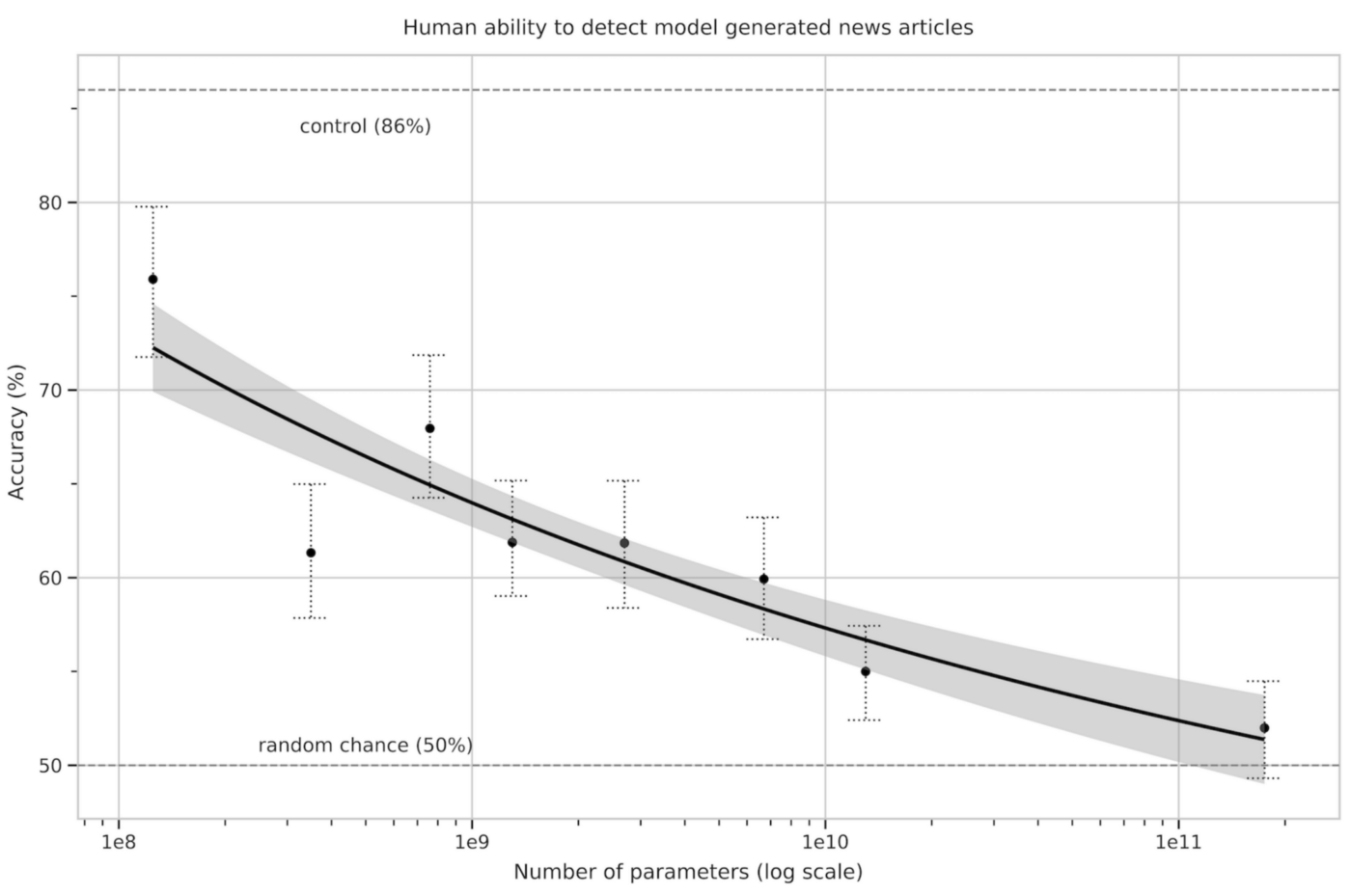
The fake news generated by GPT-3 has been so difficult to distinguish from the real ones, and in one of the experiments, the results show that only 50% of the fake news could actually be detected!
由GPT-3生成的虛假新聞很難與真實新聞區分開,在其中一項實驗中,結果表明實際上只能檢測到50%的虛假新聞!
In a task to predict the last word of a sentence, GPT-3 outperformed the current SOTA (state of the art) algorithm by 8% with an accuracy score of 76% in a zero-shot setting. In the few-shots setting, it has achieved an accuracy score of 86.4%!
在預測句子的最后一個單詞的任務中,GPT-3在零擊設置中的性能得分為76%,優于當前的SOTA(最新技術)算法。 在幾次拍攝設置中,它的準確率達到86.4%!
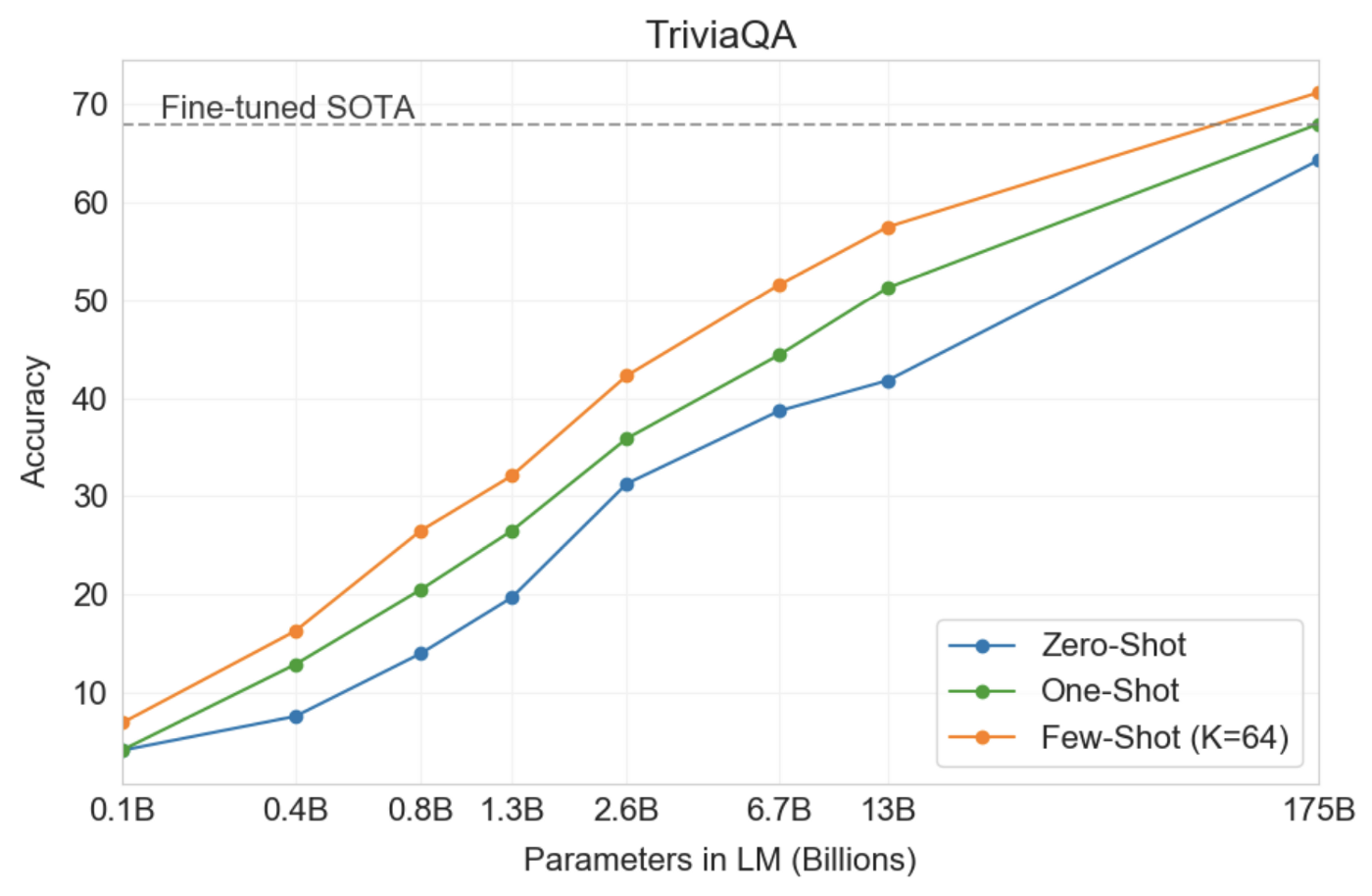
In a closed book question answering tasks, GPT-3 outperformed a fine-tuned SOTA that uses an Information Retrieval component in both one and few-shot settings.
在一本閉卷的問答任務中,GPT-3的性能優于經過精心調整的SOTA,該SOTA在一次和多次拍攝設置中都使用了信息檢索組件。
The GPT-3 API has been on the waiting list, but all the folks who could get a chance to try it shared their interesting findings and amazing results of this powerful model. Here are a few things that were observed while experimenting on the API’s interface called the Playground.
GPT-3 API一直在等待中,但是所有有機會嘗試使用它的人都分享了他們有趣的發現以及該強大模型的驚人結果。 這是在API的稱為Playground的接口上進行實驗時觀察到的一些事情。
Open AI GPT-3 API游樂場摘要: (Summary of the Open AI GPT-3 API Playground:)
Settings and Presets:Upon clicking on the settings icon, one can configure various parameters like the text length, temperature (from low/boring to standard to chaotic/creative), start and stop generated text etc. And there are multiple presets to choose and play around with like Chat, Q&A, Parsing Unstructured Data, Summarize for a 2nd grader
設置和預設:單擊設置圖標后,可以配置各種參數,例如文本長度,溫度(從低/無聊到標準到混亂/創意),開始和停止生成的文本等。并且有多個預設可供選擇和玩耍,例如聊天,問答,解析非結構化數據,為二年級學生匯總
Chat:
聊天:
The chat preset looks more like a chatbot where you can set the character of the AI as friendly, creative, clever and helpful which provides informative answers in a very polite manner whereas if you set the character of the AI to brutal it responds exactly as the character suggests!
聊天預設看起來更像是一個聊天機器人,您可以在其中將AI的角色設置為友好,富有創造力,聰明和樂于助人,以非常有禮貌的方式提供信息豐富的答案,而如果將AI的角色設置為殘酷,則其響應方式與性格暗示!
Q&A:
問答:
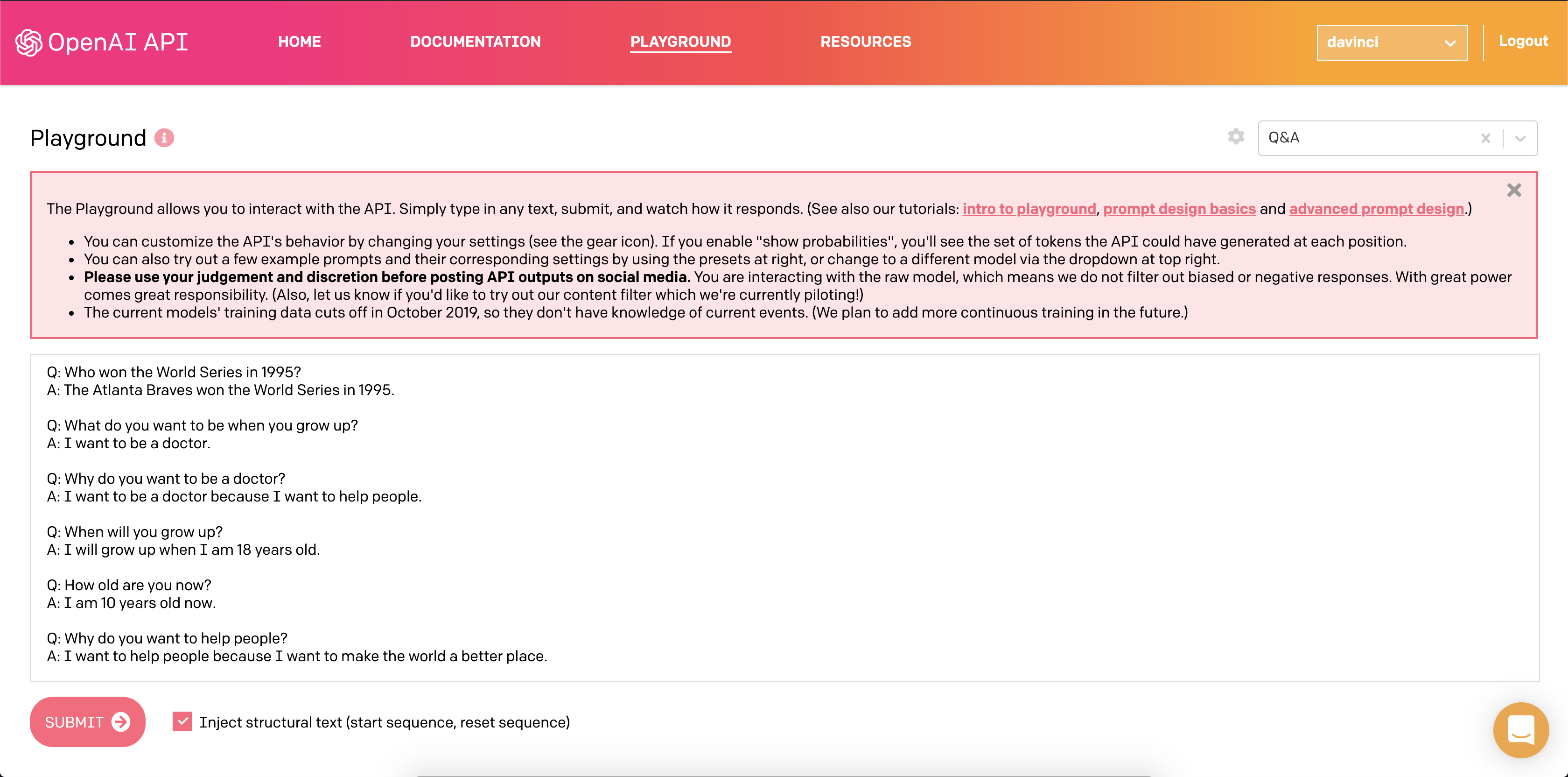
Question answering needs some training before it starts answering our questions and people did not have any complaints with the kind of answers received.
問題解答在開始回答我們的問題之前需要接受一些培訓,并且人們對所收到的答案沒有任何抱怨。
Parsing Unstructured Data:
解析非結構化數據:
This is an interesting preset of the model which can comprehend and extract structured information from the unstructured text
這是模型的一個有趣的預設,它可以理解和從非結構化文本中提取結構化信息
Summarize for 2nd Grader:
總結二年級學生:
This preset shows another level of text compression by rephrasing the difficult sentences and concepts into simpler words and sentences that can be easily understood by a kid
該預設通過將難于理解的句子和概念改寫為較容易理解的簡單單詞和句子,從而顯示了另一級文本壓縮
Multilingual text processing:GPT-3 can handle languages other than English better than GPT-2. People have tried tasks in various languages German, Russian and Japanese it did perform well and were very much ready for multilingual text processing.
多語言文本處理: GPT-3可以比GPT-2更好地處理英語以外的語言。 人們嘗試了多種語言的德語,俄語和日語任務,性能很好,并且已經為多語言文本處理做好了充分的準備。
Text Generation:It can generate poems on demand that too in a particular style if required, can write stories and essays with some fine-tuning even in other languages
文本生成:它可以按需生成詩歌,如果需要,也可以使用特定樣式的詩,甚至可以用其他語言對故事和論文進行微調。
Code Generation:People have claimed that this API can generate code with a minimum prompts
代碼生成:人們聲稱此API可以在最少提示的情況下生成代碼
Here is an article which showcases all its capabilities and excerpts from social media.
這 是一篇文章,展示了其所有功能和來自社交媒體的摘錄。
And this is how the AI interface looks like (Below image shows the Q&A preset):
這就是AI界面的樣子(下圖顯示了Q&A預設):
我們如何使用它? (How can we use it?)
Unlike a lot of language models, GPT-3 does not need Transfer Learning, where the model is fine-tuned on task-specific data sets for specific tasks. The author of a research paper on GPT-3 mentions the following advantages of having a task-agnostic model:
與許多語言模型不同,GPT-3不需要轉移學習,在該模型中,可以根據特定任務的特定于任務的數據集對模型進行微調。 有關GPT-3的研究論文的作者提到了具有任務不可知模型的以下優點:
- Collecting task-specific data is difficult 收集特定于任務的數據很困難
- Fine-tuning might yield out-of-distribution performance 微調可能會導致分布外性能
- Need for an adaptable NLP system similar to humans, which can understand the natural language (English) and perform tasks with few or no prompts 需要類似于人類的適應性NLP系統,該系統可以理解自然語言(英語),并且很少或沒有提示地執行任務
The applications of GPT-3 are in-context learning, where a model is fed with a task/prompt/shot or an example and it responds to it on the basis of the skills and pattern recognition abilities that were learnt during the training to adapt the current specific task.
GPT-3的應用是在上下文中學習,在模型中提供任務/提示/鏡頭或示例,并根據訓練過程中學習的技能和模式識別能力對模型做出響應當前的特定任務。
Despite its tremendous useability, the huge model size is the biggest factor hindering the usage for most people, except those with available resources. However, there are discussions in the fraternity that distillation might come to the rescue!
盡管具有巨大的可用性,但是巨大的模型大小是阻礙大多數人(除了擁有可用資源的人)使用的最大因素。 但是,在兄弟會中有討論可能會解救蒸餾 !
有什么限制? (What are the limitations?)
The Open AI founder himself said that “GPT-3 has weaknesses and it makes silly mistakes”. It is weak in the segment of sentence comparison where it has to see the usage of a word in 2 different sentences.
Open AI創始人本人說:“ GPT-3有弱點,并且會犯愚蠢的錯誤”。 它在句子比較部分中很弱,在該部分中必須查看兩個不同句子中一個單詞的用法。
As per the researchers, it still faces some problems in the following tasks:
根據研究人員的說法,它在以下任務中仍然面臨一些問題:
- Repetitions 重復次數
- Coherence loss 相干損失
- Contradictions 矛盾之處
- Drawing real conclusions 得出真實結論
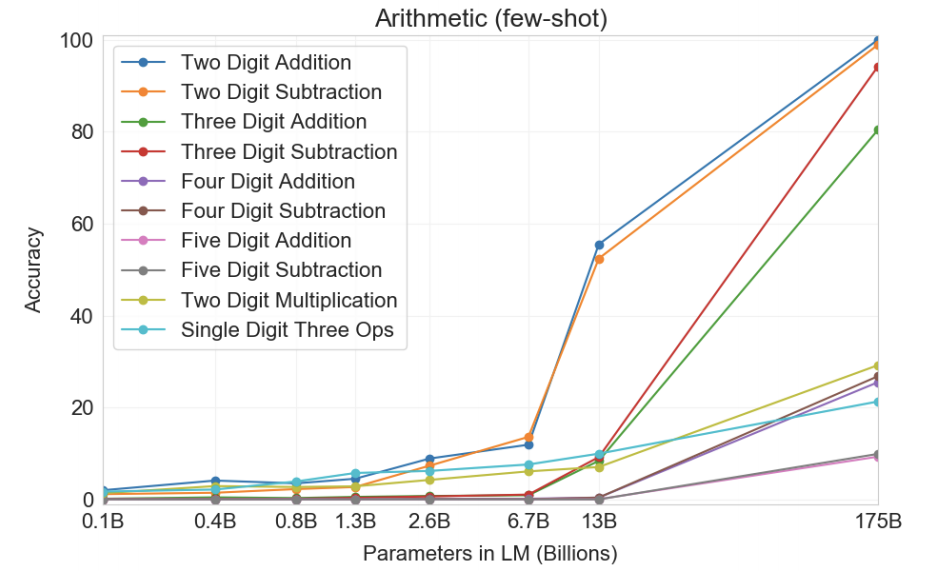
- Multiple digit additions and subtractions 多位數加減
結論 (Conclusion)
It is great to have an NLP system that doesn’t require large amounts of custom-task specific datasets and custom-model architecture to solve specific NLP tasks. The experiments conducted show its power, potential and impact on the future of NLP advancement.
擁有不需要大量特定于定制任務的數據集和定制模型體系結構來解決特定NLP任務的NLP系統,真是太好了。 進行的實驗表明了它的力量,潛力以及對NLP未來發展的影響。
Though GPT-3 doesn’t do well on everything and the size of it makes it difficult to use by everyone, this is just the threshold of a lot of new improvements to come in the field of NLP!
盡管GPT-3不能在所有方面都做得很好,并且它的大小使每個人都難以使用,但這只是NLP領域中許多新改進的門檻!
翻譯自: https://medium.com/quick-bites/gpt-3-the-latest-in-the-nlp-town-961259a0930f
nlp gpt論文
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388531.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388531.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388531.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

真實不裝| 阿里巴巴新人上路指北


tomcat java環境配置

uber 數據可視化_使用R探索您在Uber上的活動:如何分析和可視化您的個人數據歷史記錄
Ribbon)
java B2B2C springmvc mybatis電子商城系統(四)Ribbon

c語言函數的形參有幾個,C中子函數最多有幾個形參

Linux上Libevent的安裝

Win7安裝oracle 10 g
![基于plotly數據可視化_[Plotly + Datashader]可視化大型地理空間數據集](http://pic.xiahunao.cn/基于plotly數據可視化_[Plotly + Datashader]可視化大型地理空間數據集)
基于plotly數據可視化_[Plotly + Datashader]可視化大型地理空間數據集

Centos用戶和用戶組管理

吹氣球問題的C語言編程,C語言怎樣給一個數組中的數從大到小排序


劃痕實驗 遷移面積自動統計_從Jupyter遷移到合作實驗室
)
英法德三門語言同時達到c1,【分享】插翅而飛的孩子(轉載)

數據庫建表賦予權限語句

day03 基本數據類型

美國移民局的I797表原件和I129表是什么呢

數據開放 數據集_除開放式清洗之外:敘述是開放數據門戶的未來嗎?

