Following the previous article written about solving Python dependencies, we will take a look at the quality of software. This article will cover “inspections” of software stacks and will link a free dataset available on Kaggle. Even though the title says the quality of “machine learning software”, principles and ideas can be reused for inspecting any software quality.
在上一篇有關解決Python依賴關系的文章之后,我們將介紹軟件的質量。 本文將介紹軟件堆棧的“檢查”,并將鏈接Kaggle上可用的免費數據集。 即使標題說明了“機器學習軟件”的質量,也可以重用原理和思想來檢查任何軟件質量。
應用程序(軟件和硬件)堆棧 (Application (Software & Hardware) Stack)
Let’s consider a Python machine learning application. This application can use a machine learning library, such as TensorFlow. TensorFlow is in that case a direct dependency of the application and by installing it, the machine learning application is using directly TensorFlow and indirectly dependencies of TensorFlow. Examples of such indirect dependencies of our application can be NumPy or absl-py that are used by TensorFlow.
讓我們考慮一個Python機器學習應用程序。 該應用程序可以使用機器學習庫,例如TensorFlow 。 在這種情況下,TensorFlow是應用程序的直接依賴項,通過安裝它,機器學習應用程序將直接使用TensorFlow并間接使用TensorFlow依賴項。 我們應用程序的這種間接依賴關系的示例可以是TensorFlow使用的NumPy或absl-py 。
Our machine learning Python application and all the Python libraries run on top of a Python interpreter in some specific version. Moreover, they can use other additional native dependencies (provided by the operating system) such as glibc or CUDA (if running computations on GPU). To visualize this fact, let’s create a stack with all the items creating the application stack running on top of some hardware.
我們的機器學習Python應用程序和所有Python庫在某些特定版本的Python解釋器上運行。 此外,他們可以使用其他附加的本機依賴項(由操作系統提供),例如glibc或CUDA (如果在GPU上運行計算)。 為了形象化這一事實,讓我們創建一個堆棧,其中所有項都創建在某些硬件之上運行的應用程序堆棧。
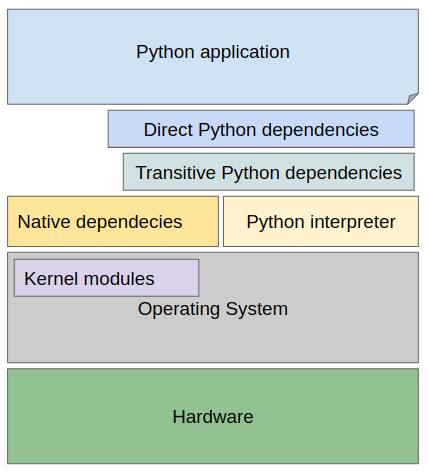
Note that an issue in any of the described layers causes that our Python application misbehaves, produces wrong output, produces runtime errors, or simply does not start at all.
請注意,任何描述的層中的問題都會導致我們的Python應用程序行為異常,產生錯誤的輸出,產生運行時錯誤,或者根本無法啟動。
Let’s try to identify any possible issues in the described stack by building the software and let’s have it running on our hardware. By doing so we can spot possible issues before pushing our application to a production environment or fine-tune the software so that we get the best possible out of our application on the hardware available.
讓我們嘗試通過構建軟件來確定所描述堆棧中的任何可能問題,并使其在我們的硬件上運行。 這樣,我們可以在將應用程序推送到生產環境之前發現可能的問題,或者對軟件進行微調,以便在可用硬件上充分利用應用程序。
按需軟件堆棧創建 (On-demand software stack creation)
If our application depends on a TensorFlow release starting version 2.0.0 (e.g. requirements on API offered by tensorflow>=2.0.0), we can test our application with different versions of TensorFlow up to the current 2.3.0 release available on PyPI to this date. The same can be applied to transitive dependencies of TensorFlow, e.g. absl-py, NumPy, or any other. A version change of any transitive dependency can be performed analogically to any other dependency in our software stack.
如果我們的應用程序依賴于2.0.0版本開始的TensorFlow版本(例如tensorflow>=2.0.0提供的API要求),我們可以使用不同版本的TensorFlow來測試我們的應用程序,直到PyPI上可用的當前2.3.0版本為止。 這個日期 。 這可以應用于TensorFlow的傳遞依賴項,例如absl-py , NumPy或任何其他。 任何傳遞依賴的版本更改都可以類似于我們軟件堆棧中的任何其他依賴進行。
依賴猴子 (Dependency Monkey)
Note one version change can completely change (or even invalidate) what dependencies in what versions will be present in the application stack considering the dependency graph and version range specifications of libraries present in the software stack. To create a pinned down list of packages in specific versions to be installed a resolver needs to be run in order to resolve packages and their version range requirements.
請注意,考慮到軟件堆棧中存在的庫的依賴關系圖和版本范圍規范,一個版本更改可以完全更改(甚至無效)應用程序堆棧中將存在哪些版本的依賴關系。 要創建要安裝的特定版本的軟件包的固定列表,需要運行解析器以解析軟件包及其版本范圍要求。
Do you remember the state space described in the first article of “How to beat Python’s pip” series? Dependency Monkey can in fact create the state space of all the possible software stacks that can be resolved respecting version range specifications. If the state space is too large to resovle in a reasonable time, it can be sampled.
您還記得“如何擊敗Python的點子”系列的第一篇文章中描述的狀態空間嗎? Dependency Monkey實際上可以創建所有可能的軟件堆棧的狀態空間,這些版本可以根據版本范圍規范進行解析。 如果狀態空間太大而無法在合理的時間內恢復狀態,則可以對其進行采樣。

A component called “Dependency Monkey” is capable of creating different software stacks considering the dependency graph and version specifications of packages in the dependency graph. This all is done offline based on pre-computed results from Thoth’s solver runs (see the previous article from “How to beat Python’s pip” series). The results of solver runs are synced into Thoth’s database so that they are available in a query-able form. Doing so enables Dependency Monkey to resolve software stacks at a fast pace (see a YouTube video on optimizing Thoth’s resolver). Moreover, the underlying algorithm can consider Python packages published on different Python indices (besides PyPI, it can also use custom TensorFlow builds from an index such as the AICoE one). We will do a more in-depth explanation of Dependency Monkey in one of the upcoming articles. If you are too eager, feel free to browse its online documentation.
考慮到依賴關系圖和依賴關系圖中軟件包的版本規格,稱為“依賴關系猴子”的組件能夠創建不同的軟件堆棧。 所有這些都是根據Thoth的求解器運行的預先計算的結果脫機完成的(請參閱“ How to beat Python's pip”系列的上一篇文章) 。 求解器運行的結果將同步到Thoth的數據庫中,以便以可查詢的形式提供它們。 這樣做使Dependency Monkey能夠快速解決軟件堆棧的問題 (請參見有關優化Thoth解析器的YouTube視頻 )。 此外,底層算法可以考慮發布在不同Python索引上的Python包( 除了PyPI之外 ,它還可以使用來自諸如AICoE的索引的自定義TensorFlow構建 )。 我們將在后續文章之一中對Dependency Monkey做更深入的解釋。 如果您太渴望了,請隨時瀏覽其在線文檔 。
Amun API (Amun API)
Now, let’s utilize a service called “Amun”. This service was designed to accept a specification of the software stack and hardware and execute an application given the specification.
現在,讓我們利用一項名為“ Amun ”的服務。 該服務旨在接受軟件堆棧和硬件的規范,并根據給定的規范執行應用程序。
Amun is an OpenShift cluster native application, that utilizes OpenShift features (such as builds, container image registry, …) and Argo Workflows to run desired software on specific hardware using a specific software environment. The specification is accepted in a JSON format that is subsequently translated into respective steps that need to be done in order to test the given stack build and run.
Amun是一個OpenShift群集本機應用程序,它利用OpenShift功能(例如構建,容器映像注冊表等)和Argo Workflow在使用特定軟件環境的特定硬件上運行所需的軟件。 該規范以JSON格式接受,隨后將其轉換為需要執行的各個步驟,以測試給定的堆棧構建和運行。
The video linked above shows how Amun inspections are run and how the knowledge created is aggregated using OpenShift, Argo workflows, and Ceph. You can see inspected different TensorFlow builds tensorflow , tensorflow-cpu , intel-tensorflow and a community builds of TensorFlow for AVX2 instruction set support available on the AICoE index.
上面鏈接的視頻顯示了如何運行Amun檢查以及如何使用OpenShift,Argo工作流程和Ceph匯總所創建的知識。 您可以在AICoE索引上看到經過檢查的不同TensorFlow構建tensorflow , tensorflow-cpu , intel-tensorflow和TensorFlow for AVX2指令集支持的社區構建 。
在Kaggle上的Thoth檢查數據集 (Thoth’s inspection dataset on Kaggle)
We (Red Hat) have produced multiple inspections as part of the project Thoth where we tested different TensorFlow releases and different TensorFlow builds.
我們(Red Hat)作為Thoth項目的一部分進行了多次檢查,在其中我們測試了不同的TensorFlow版本和不同的TensorFlow版本。
One such dataset is Thoth’s performance data set in version 1 on Kaggle. It’s consisting out of nearly 4000 files capturing information about inspection runs of TensorFlow stacks. A notebook published together with the dataset can help one exploring the dataset.
這樣的數據集就是在Kaggle的版本1中的Thoth的性能數據 。 它由近4000個文件組成,這些文件捕獲有關TensorFlow堆棧檢查運行的信息。 與數據集一起發布的筆記本可以幫助人們探索數據集。
托特計劃 (Project Thoth)
Project Thoth is an application that aims to help Python developers. If you wish to be updated on any improvements and any progress we make in project Thoth, feel free to subscribe to our YouTube channel where we post updates as well as recordings from scrum demos.
Project Thoth是旨在幫助Python開發人員的應用程序。 如果您希望了解我們在Thoth項目中所做的任何改進和進展的最新信息,請隨時訂閱我們的YouTube頻道 ,我們在其中發布更新以及Scrum演示的錄音。
Stay tuned for any updates!
請隨時關注任何更新!
翻譯自: https://towardsdatascience.com/how-to-beat-pythons-pip-inspecting-the-quality-of-machine-learning-software-f1a028f0c42a
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388418.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388418.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388418.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

KindEditor解決上傳視頻不能在手機端顯示的問題

湖北經濟學院的計算機是否強,graphics-ch11-真實感圖形繪制_湖北經濟學院:計算機圖形學_ppt_大學課件預覽_高等教育資訊網...

ARP攻擊網絡上不去,可以進行mac地址綁定

《獨家記憶》見面會高甜寵粉 張超現場解鎖隱藏技能

計算機軟件技術基礎fifo算法,軟件技術基礎真題
)
NOI 2016 優秀的拆分 (后綴數組+差分)

多元線性回歸 python_Python中的多元線性回歸

關于apache和tomcat集群,線程是否占用實驗

爬蟲之數據解析的三種方式

相對于硬件計算機軟件就是,計算機的軟件是將解決問題的方法,軟件是相對于硬件來說的...

數據冒險控制冒險_勞動生產率和其他冒險

如何把一個java程序打包成exe文件,運行在沒有java虛

Java后端WebSocket的Tomcat實現

加速業務交付,從 GKE 上使用 Kubernetes 和 Istio 開始

knn 鄰居數量k的選取_選擇K個最近的鄰居
![計算機網絡中 子網掩碼的算法,[網絡天地]子網掩碼快速算法(轉載)](http://pic.xiahunao.cn/計算機網絡中 子網掩碼的算法,[網絡天地]子網掩碼快速算法(轉載))
計算機網絡中 子網掩碼的算法,[網絡天地]子網掩碼快速算法(轉載)

EXTJS+JSP上傳文件帶進度條

android Json詳解

