knn 鄰居數量k的選取
Classification is more-or-less just a matter of figuring out to what available group something belongs.
分類或多或少只是弄清楚某個事物所屬的可用組的問題。
Is Old Town Road a rap song or a country song?
Old Town Road是說唱歌曲還是鄉村歌曲?
Is the tomato a fruit or a vegetable?
番茄是水果還是蔬菜?
Machine learning (ML) can help us efficiently classify such data, even when we do not know (or have names for) the classes to which they belong. In cases where we do have labels for our groups, an easy-to-implement algorithm that may be used to classify new data is K Nearest Neighbors (KNN). This article will consider the following, with regards to KNN:
機器學習(ML)可以幫助我們有效地對此類數據進行分類,即使我們不知道(或為其命名)它們所屬的類。 如果我們確實有組的標簽,則可以用來對新數據進行分類的一種易于實現的算法是K最近鄰居(KNN)。 本文將考慮以下有關KNN的問題:
- What is KNN 什么是KNN
- The KNN Algorithm KNN算法
- How to implement a simple KNN in Python, step by step 如何逐步在Python中實現簡單的KNN
監督學習 (Supervised Learning)
In the image above, we have a collection of dyed squares, in variegated shades from light pink to dark blue. If we decide to separate the cards into two groups, where should we place the cards that are purple or violet?
在上圖中,我們收集了一組染色的正方形,從淺粉紅色到深藍色的雜色陰影。 如果我們決定將卡片分成兩組,那么應該將紫色或紫色的卡片放在哪里?
In supervised learning we are given labeled data, e.g., knowing that, “these 5 cards are red-tinted, and these five cards are blue-tinted.” A supervised learning algorithm analyzes the training data — in this case, the 10 identified cards — and produces an inferred function. This function may then be used for mapping new examples or determining to which or the two classes each of the other cards belongs.
在監督學習中,我們獲得了帶有標簽的數據,例如,知道“這5張卡是紅色的,而這5張卡是藍色的”。 監督學習算法分析訓練數據(在這種情況下為10張識別出的卡片),并產生推斷功能。 然后,該功能可用于映射新示例或確定每個其他卡屬于哪個類別或兩個類別。
什么是分類? (What is Classification?)
Classification is an example of supervised learning. In ML, this involves identifying to which of a set of categories a new observation belongs, on the basis of a training dataset containing observations whose category membership is known (is labeled). Practical examples of classification include assigning an email as spam or not spam or predicting whether or not a client will default on a bank loan.
分類是監督學習的一個例子。 在ML中,這涉及基于訓練數據集來識別新觀測值屬于一組類別中的哪一個,該訓練數據集包含其類別成員身份已知(帶有標簽)的觀測值。 分類的實際示例包括將電子郵件指定為垃圾郵件或不指定為垃圾郵件,或預測客戶是否會拖欠銀行貸款。
K最近的鄰居 (K Nearest Neighbors)
The KNN algorithm is commonly used in many simpler ML tasks. KNN is a non-parametric algorithm which means that it doesn’t make any assumptions about the data. KNN makes its decision based on similarity measures, which may be thought of as the distance of one example from others. This distance can simply be Euclidean distance. Also, KNN is a lazy algorithm, which means that there is little to no training phase. Therefore, new data can be immediately classified.
KNN算法通常用于許多更簡單的ML任務中。 KNN是一種非參數算法,這意味著它不會對數據做任何假設。 KNN基于相似性度量進行決策,可以將其視為一個示例與其他示例之間的距離。 該距離可以簡單地是歐幾里得距離。 同樣,KNN是一種惰性算法,這意味著幾乎沒有訓練階段。 因此,可以立即對新數據進行分類。
KNN的優缺點 (Advantages and Disadvantages of KNN)
Advantages
優點
- Makes no assumptions about the data 不對數據做任何假設
- Simple algorithm 簡單算法
- Easily applied to classification problems 輕松應用于分類問題
Disadvantages
缺點
- High sensitivity to irrelevant features 對無關功能具有很高的敏感性
- Sensitive to the scale of data used to compute distance 對用于計算距離的數據規模敏感
- Can use a lot of memory 可以使用很多內存

While KNN is considered a ‘lazy learner’, it can also be a bit of an over-achiever — searching the entire dataset to compute the distance between each new observation and each known observation.
雖然KNN被認為是“懶惰的學習者”,但它也可能有點過時-搜索整個數據集以計算每個新觀測值與每個已知觀測值之間的距離。
So, how do we use KNN?
那么,我們如何使用KNN?
KNN算法 (Algorithm of KNN)
We start by selecting some value of k, such as 3, 5 or 7.
我們首先選擇k的某個值,例如3、5或7。
The value of k can be any number below the number of observations in the dataset. When the choice is between an even number of classes, setting this parameter to an odd number avoids the possibility of a tie between the two.
k的值可以是數據集中觀測值以下的任何數字。 如果在偶數類之間進行選擇,則將此參數設置為奇數可以避免兩者之間產生聯系。
One approach for selecting k is to use the integer nearest to the square root of the number of samples in the labeled classes (+/- 1 if the square root is an even number). Given 10 labeled points from our two classes, we would set k equal to 3, the integer nearest to √10.
選擇k的一種方法是使用最接近標記類別中樣本數量平方根的整數(如果平方根是偶數,則為+/- 1)。 給定兩個類中的10個標記點,我們將k設置為3,即最接近√10的整數。
Next:
下一個:
- Choose k samples closest to the new data point according to their Euclidean distance from that point. 根據距該數據點的歐式距離選擇k個最接近新數據點的樣本。
- For each data point in test: Calculate the distance between test data and each row of training data with the help of Euclidean distance. 對于測試中的每個數據點:借助歐幾里得距離來計算測試數據與訓練數據的每一行之間的距離。
- Now, sort point distances in ascending order according to the distance computed. 現在,根據計算出的距離以升序對點距離進行排序。
- Choose top k from the distance array. 從距離數組中選擇前k個。
- Now, assign a class to the test sample based on most frequent class of these rows. 現在,根據這些行中最常見的類別為測試樣本分配一個類別。
If you comfortably read through those bullet points, you may already know enough about ML algorithms that you did not need to read this article (but please, continue).
如果您舒適地通讀了這些要點,則可能已經對ML算法有足夠的了解,而無需閱讀本文(但請繼續)。
Essentially, each of the k nearest neighbors is a vote for its own class. The new data point will be classified based on which class has the greater number of votes out of the test points k nearest neighbors.
本質上,k個最近的鄰居中的每一個都是其所屬階級的投票。 新數據點將基于哪個類在k個最鄰近鄰居的測試點中具有更大的票數進行分類。
例 (Example)
Let’s see an example to understand better.
讓我們看一個例子,以更好地理解。
Suppose we have some data which is plotted as follows:
假設我們有一些數據繪制如下:
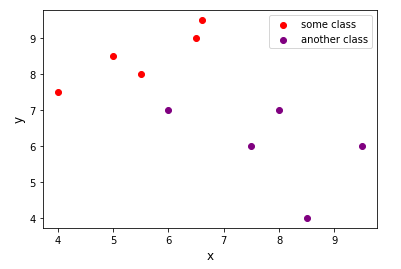
You can see that there are two classes of data, one red and the other purple.
您會看到有兩類數據,一類是紅色,另一類是紫色。
Now, consider that we have a test data point (indicated in black ) and we have to predict whether it belongs to the red class or the purple class. We will compute the Euclidean distance of the test point with k nearest neighbors. Here k = 3.
現在,考慮我們有一個測試數據點(用黑色表示),并且我們必須預測它是屬于紅色類別還是紫色類別。 我們將計算k個最近鄰居的測試點的歐幾里得距離。 這里k = 3。
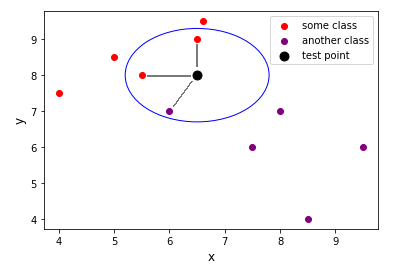
Now, we have computed the distance between the test point and its three nearest neighbors. Two of the neighboring points are from the red class, and one is from the purple class. Hence this data point will be classified as belonging to the red class.
現在,我們已經計算出測試點與其三個最近的鄰居之間的距離。 相鄰點中的兩個來自紅色類別,一個來自紫色類別。 因此,該數據點將被歸類為屬于紅色類別。
使用Python實施 (Implementation using Python)
We will use the Numpy and Sklearn libraries to implement KNN. In addition, we will use Sklearn’s GridSearchCV function.
我們將使用Numpy和Sklearn庫來實現KNN。 另外,我們將使用Sklearn的GridSearchCV函數。
網格搜索簡歷 (Grid Search CV)
Grid search is the process of performing hyperparameter tuning in order to determine the optimal values of the hyperparameters for a given model. This is significant as the performance of the entire model is based on the values specified.
網格搜索是執行超參數調整以確定給定模型的超參數的最佳值的過程。 這很重要,因為整個模型的性能基于指定的值。
為什么要使用它? (Why use it?)
Models can involve more than a dozen parameters. Each of these parameters can take on specific characteristics, based on their hyperparameter settings; and hyperparameters can present as ranges or conditions, some of which may be programmatically changed during modeling.
模型可以包含十幾個參數。 這些參數中的每一個都可以基于其超參數設置而具有特定的特性; 超參數可以表示為范圍或條件,其中某些可以在建模過程中以編程方式更改。
Manually selecting best hyperparameters in the ML process can feel like a nightmare for practitioners. Sklearn’s GridSearchCV instance helps to automate this process, programatically determining the best settings for specified parameters.
在ML流程中手動選擇最佳超參數對于從業者來說就像一場噩夢。 Sklearn的GridSearchCV實例有助于自動執行此過程,以編程方式確定指定參數的最佳設置。
So, what does this look like in (pseudocode) practice? We start be importing required libraries.
那么,這在(偽代碼)實踐中是什么樣的呢? 我們開始導入所需的庫。
import pandas as pd
import numpy as npfrom sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_scoreKNN功能 (KNN function)
We will create a custom KNN method with 5 parameters: training examples, training labels, test examples, test label and a list of possible values of k to train on.
我們將創建一個具有5個參數的自定義KNN方法:訓練示例,訓練標簽,測試示例,測試標簽和要訓練的k可能值列表。
First, we create a KNeighborsClassifier() object, imported from Sklearn. Then we create a dictionary named “parameters” and store the list k in it. Our third step is to pass the classifier, i.e. KNN, and the parameters to GridSearchCV and fit this model on the training data. GridSearchCV will optimize hyperparameters for training and we will make predictions on test data using the tuned hyperparameters. To predict the labels on test data, we call model.predict(). We can check the accuracy of our model and its predictions with the accuracy_score() function we import from Sklearn.
首先,我們創建一個從Sklearn導入的KNeighborsClassifier()對象。 然后,我們創建一個名為“ parameters”的字典,并將列表k存儲在其中。 我們的第三步是將分類器(即KNN)和參數傳遞給GridSearchCV,并將此模型擬合到訓練數據上。 GridSearchCV將優化用于訓練的超參數,我們將使用調整后的超參數對測試數據進行預測。 為了預測測試數據上的標簽,我們調用model.predict()。 我們可以使用從Sklearn導入的precision_score()函數檢查模型的準確性及其預測。
def KNN(x_tr, y_tr, x_te, y_te, k):
print('\nTraining Started for values of k', [each for each in k],'.......')
# Create an knn object using imported KNeighborsClassifier() from sklearn
knn = KNeighborsClassifier()# parameters i.e. k neighbors list
parameters = {'n_neighbors':k}
# Training the model
model = GridSearchCV(knn, param_grid = parameters, cv=3)
model.fit(x_tr, y_tr)
print('Best value of k is ',model.best_params_)
# Making Predictions on test data
print('\nPredicting on Test data.......')
pred = model.predict(x_te)
print('\nAccuracy of model on test is', accuracy_score(y_te, pred)*100,'%')
return accuracy_score(y_te, pred)This custom method is just some pre-processing done on the Google Playstore dataset. Note: a version of the dataset may be obtained from Kaggle. Data filenames and required pre-processing steps may vary.
此自定義方法只是對Google Playstore數據集進行的一些預處理。 注意:數據集的版本可以從Kaggle獲得。 數據文件名和所需的預處理步驟可能會有所不同。
def data_preprocess():
# processing Apps.csv
data = pd.read_csv('apps.csv')
columns = ['App', 'Category', 'Rating', 'Size', 'Type', 'Price', 'Genres']
data[columns]
new_data = data[columns].copy()
new_data = new_data.fillna(0)
for each in range(0, len(new_data['Rating'])):
if new_data['Rating'][each] == 0:
new_data.at[each, 'Rating'] = new_data['Rating'].mean()
price_list = [float(each.replace("$","")) for each in new_data.Price]
new_data.Price = price_list
# processing User_reviews.csv
data2 = pd.read_csv('user_reviews.csv')
column = ['App', 'Sentiment_Polarity', 'Sentiment_Subjectivity', 'Sentiment']
data2[column]
new_data2 = data2[column].copy()
# merging the two datasets into one final dataset
df = new_data.merge(new_data2, on='App')
df.Sentiment = df['Sentiment'].replace(to_replace='Positive', value=1).replace(to_replace='Negative', value=-1).replace(to_replace='Neutral', value=0)
df.Sentiment_Polarity = df.Sentiment_Polarity.fillna(df.Sentiment_Polarity.mean())
df.Sentiment_Subjectivity = df.Sentiment_Subjectivity.fillna(df.Sentiment_Subjectivity.mean())
df = df[df['Sentiment'].notna()]
df.Type = df['Type'].replace(to_replace='Free', value=1).replace(to_replace='Paid', value=0)
df = df.drop(['Size'], axis=1)
# separating dataset into samples and labels
X = df.iloc[:, 0:7]
y = df.iloc[:, 8:9]
# encoding the dataset
X = pd.get_dummies(X)
print('\nFinished pre-processing data....')
return X, yWe create a main function and all the processing is done in this function. We will call the above created methods in this main function. Also, we are applying some data normalization techniques in this function and calling the custom function on our data.
我們創建一個主要功能,所有處理都在該功能中完成。 我們將在此主函數中調用上面創建的方法。 另外,我們在此函數中應用了一些數據標準化技術,并在數據上調用了自定義函數。
Normalization may not be required, depending on the data you use.
根據您使用的數據,可能不需要規范化。
Finished pre-processing data....Training Started for values of k [3, 5, 7] .......
Best value of k is {'n_neighbors': 7}Predicting on Test data.......Accuracy of model on test is 86.07469428225184 %Running our function results in a respectable accuracy score of 86 %.
運行我們的功能可獲得可觀的86%準確度。
In this article, we took a look at the K Nearest Neighbors machine learning algorithm. We discussed how KNN uses Euclidean distance to compare the similarity of test data features to those of labeled training data. We also explored a simple solution for determining a value for k. In our custom code example, we demonstrated the use of Sklearn’s GridSearchCV for optimizing our model’s hyperperameters (and for sparing ourselves the intense manual effort that might be otherwise required to exhaustively tune those hyperparameters).
在本文中,我們研究了K最近鄰居機器學習算法。 我們討論了KNN如何使用歐氏距離將測試數據特征與標記訓練數據的相似性進行比較。 我們還探索了確定k值的簡單解決方案。 在我們的自定義代碼示例中,我們演示了使用Sklearn的GridSearchCV來優化模型的超級參數(并為自己節省了可能需要詳盡調整這些超級參數的大量手工工作)。
We can dive much deeper into KNN theory and leverage it over a broad range of applications. KNN has many uses, from data mining to recommender systems and competitor analysis. For those seeking to further explore KNN in Python, a good course of action is to try it for yourself.
我們可以更深入地研究KNN理論,并在廣泛的應用中利用它。 從數據挖掘到推薦系統和競爭對手分析,KNN有許多用途。 對于那些尋求用Python進一步探索KNN的人來說,一個好的做法是自己嘗試一下。
If you would like some suggestions, let me know in the comments or feel free to connect with me on Linkedin.
如果您想提出建議,請在評論中讓我知道,或隨時通過Linkedin與我聯系。
翻譯自: https://medium.com/swlh/choosing-k-nearest-neighbors-6f711449170d
knn 鄰居數量k的選取
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388403.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388403.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388403.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
![計算機網絡中 子網掩碼的算法,[網絡天地]子網掩碼快速算法(轉載)](http://pic.xiahunao.cn/計算機網絡中 子網掩碼的算法,[網絡天地]子網掩碼快速算法(轉載))
計算機網絡中 子網掩碼的算法,[網絡天地]子網掩碼快速算法(轉載)

EXTJS+JSP上傳文件帶進度條

android Json詳解


什么樣的代碼是好代碼_什么是好代碼?

nginx比較apache

計算機主板各模塊復位,電腦主板復位電路工作原理分析

Docker制作dotnet core控制臺程序鏡像

【362】python 正則表達式

在Python中使用Twitter Rest API批量搜索和下載推文

第一套數字電子計算機,計算機試題第一套

Windows7 + Nginx + Memcached + Tomcat 集群 session 共享
)
git 版本控制(一)

rollup學習小記

大數據 vr csdn_VR中的數據可視化如何革命化科學

object-c 日志

計算機真正管理的文件名是什么,計算機題,請大家多多幫忙,謝謝


Xcode做簡易計算器
