python 儀表盤
Dashboard scraping is a useful skill to have when the only way to interact with the data you need is through a dashboard. We’re going to learn how to scrape data from a dashboard using the Selenium and Beautiful Soup packages in Python. The Selenium package allows you to write Python code to automate web browser interaction, and the Beautiful Soup package allows you to easily pull data from the HTML code that produces the webpage you want to scrape.
當與所需數據進行交互的唯一方法是通過儀表板時,儀表板抓取是一項有用的技能。 我們將學習如何使用Python中的Selenium和Beautiful Soup軟件包從儀表板上抓取數據。 Selenium程序包允許您編寫Python代碼來自動執行Web瀏覽器交互,而Beautiful Soup程序包則使您可以輕松地從生成您要抓取的網頁HTML代碼中提取數據。
Our goal is to scrape the Fort Bend County Community Impact Dashboard that visualizes the COVID-19 situation in Fort Bend County in Texas. We will extract the history of total tests performed and the daily case counts reported so that we can estimate the percent of positive cases in Fort Bend County.
我們的目標是刮擦本德堡縣社區影響儀表板 ,以可視化方式顯示德克薩斯州本德堡縣的COVID-19情況。 我們將提取進行的總檢測的歷史記錄和每日報告的病例計數,以便我們可以估算本德堡縣陽性病例的百分比。
Note that all of the code in this tutorial is written in Python version 3.6.2.
請注意,本教程中的所有代碼都是使用Python 3.6.2版編寫的。
步驟1:導入Python軟件包,模塊和方法 (Step 1: Import Python Packages, Modules, and Methods)
The first step is to import the Python packages, modules, and methods needed for dashboard scraping. The versions of the packages used in this tutorial are listed below.
第一步是導入儀表板抓取所需的Python包,模塊和方法。 下面列出了本教程中使用的軟件包的版本。
步驟2:抓取HTML源代碼 (Step 2: Scrape HTML Source Code)
The next step is to write Python code to automate our interaction with the dashboard. Before writing any code, we must look at the dashboard and inspect its source code to identify the HTML elements that contain the data we need. The dashboard source code refers to the HTML code that tells your browser how to render the dashboard web page. To view the dashboard source code, navigate to the dashboard and use the keyboard shortcut Ctrl+Shift+I. An interactive panel containing the dashboard source code will appear.
下一步是編寫Python代碼來自動化我們與儀表板的交互。 在編寫任何代碼之前,我們必須查看儀表板并檢查其源代碼以識別包含我們所需數據HTML元素。 儀表板源代碼是指HTML代碼,它告訴您的瀏覽器如何呈現儀表板網頁。 要查看儀表板源代碼,請導航至儀表板并使用鍵盤快捷鍵Ctrl+Shift+I 將出現一個包含儀表板源代碼的交互式面板。
Notice that the history of total tests performed and the daily case counts reported are only visible after clicking the “History” tab in the “Total Numbers of Tests Performed at County Sites” panel and the “Daily Case Count” tab in the “Confirmed Cases” panel, respectively. This means that we need to write Python code that automatically clicks on the “History” and “Daily Case Count” tabs so that the history of total tests performed and the daily case counts reported will be visible to Beautiful Soup.
請注意,僅在單擊“縣站點執行的測試總數”面板中的“歷史記錄”選項卡和“已確認案例”中的“每日案例計數”選項卡之后,才可以執行總測試的歷史記錄和報告的每日案例計數”面板。 這意味著我們需要編寫Python代碼,該代碼自動單擊“歷史記錄”和“每日案例計數”選項卡,以便Beautiful Soup可以看到執行的總測試的歷史記錄和每日報告的案例計數。
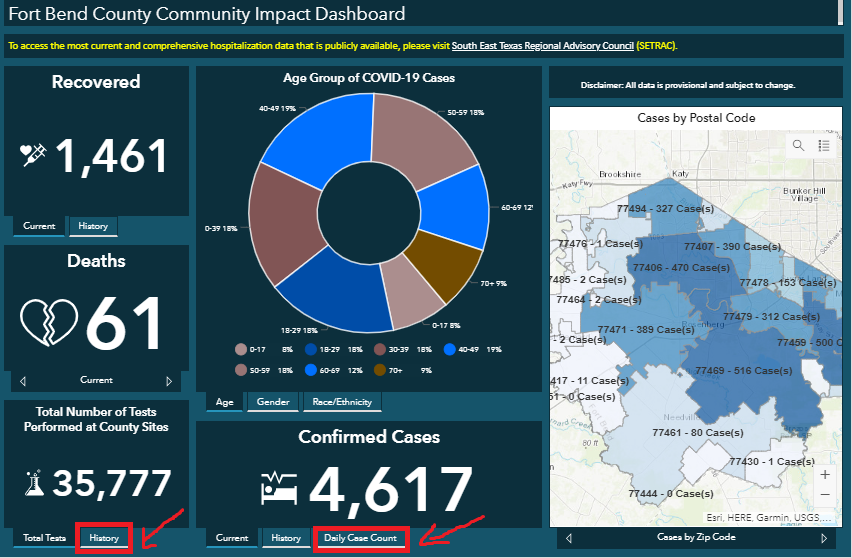
To find the HTML element that contains the “History” tab, use the shortcut Ctrl+Shift+C and then click on the "History" tab. You will see in the source code panel that the "History" tab is in a div element with ID "ember208".
要查找包含“歷史記錄”選項卡HTML元素,請使用快捷鍵Ctrl+Shift+C ,然后單擊“歷史記錄”選項卡。 您將在源代碼面板中看到“歷史記錄”選項卡位于ID為“ ember208”的div元素中。
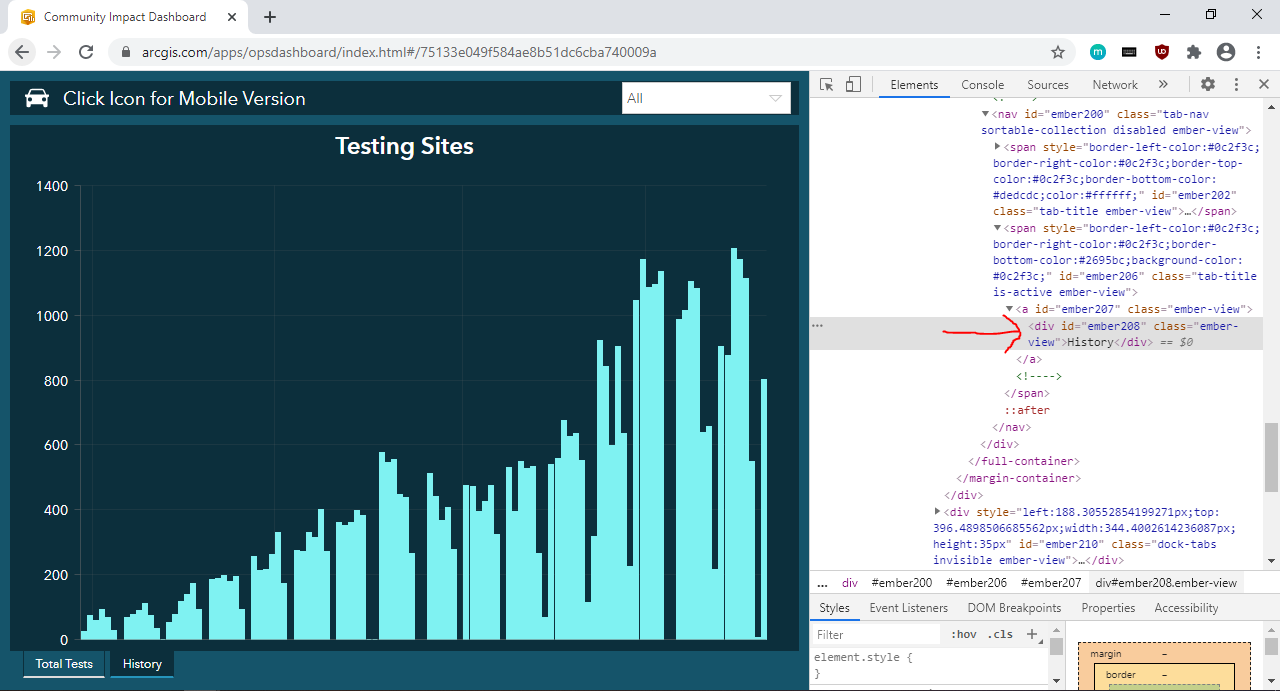
Following the same steps for the “Daily Case Count” tab, you will see that the “Daily Case Count” tab is in a div element with ID “ember238”.
按照“每日案件計數”標簽的相同步驟,您將看到“每日案件計數”標簽位于ID為“ ember238”的div元素中。
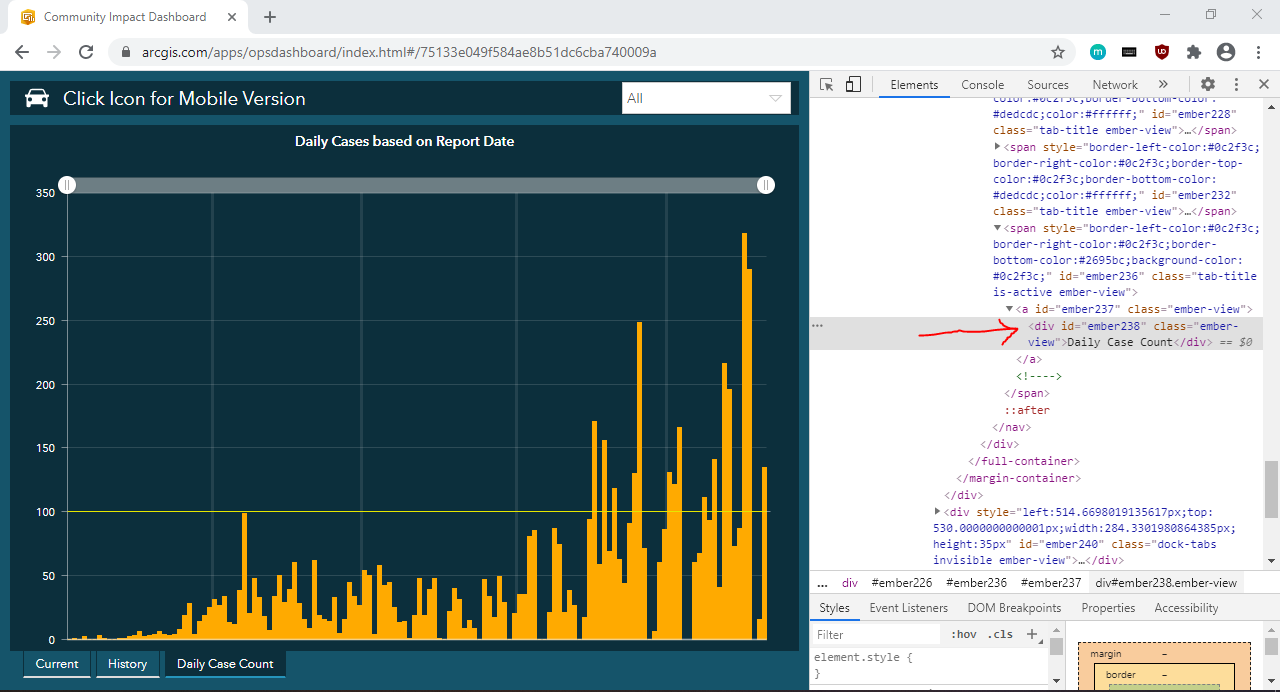
Now that we have identified the elements we need, we can write code that:
現在我們已經確定了所需的元素,我們可以編寫代碼:
- Launches the dashboard in Chrome 在Chrome中啟動儀表板
- Clicks on the “History” tab once the “History” tab finishes loading 一旦“歷史記錄”選項卡完成加載,請單擊“歷史記錄”選項卡
- Clicks on the “Daily Case Count” tab once the “Daily Case Count” tab finishes loading 一旦“每日病例數”選項卡完成加載,請單擊“每日病例數”選項卡
- Extracts the dashboard HTML source code 提取儀表板HTML源代碼
- Exits Chrome 退出Chrome
步驟3:從HTML解析數據 (Step 3: Parse Data from HTML)
Now, we need to parse the HTML source code to extract the history of total tests performed and the daily case counts reported. We will begin by looking at the dashboard source code to identify the HTML elements that contain the data.
現在,我們需要解析HTML源代碼,以提取執行的總測試的歷史記錄和每日報告的病例數。 我們將從查看儀表板源代碼開始,以識別包含數據HTML元素。
To find the div element that contains the history of total tests performed, use the Ctrl+Shift+C shortcut and then click in the general area of the "Testing Sites" plot. You will see in the source code that the entire plot is in the div element with ID "ember96".
要查找包含已執行的全部測試的歷史記錄的div元素,請使用Ctrl+Shift+C快捷鍵,然后單擊“測試站點”圖的常規區域。 您會在源代碼中看到整個圖位于ID為“ ember96”的div元素中。
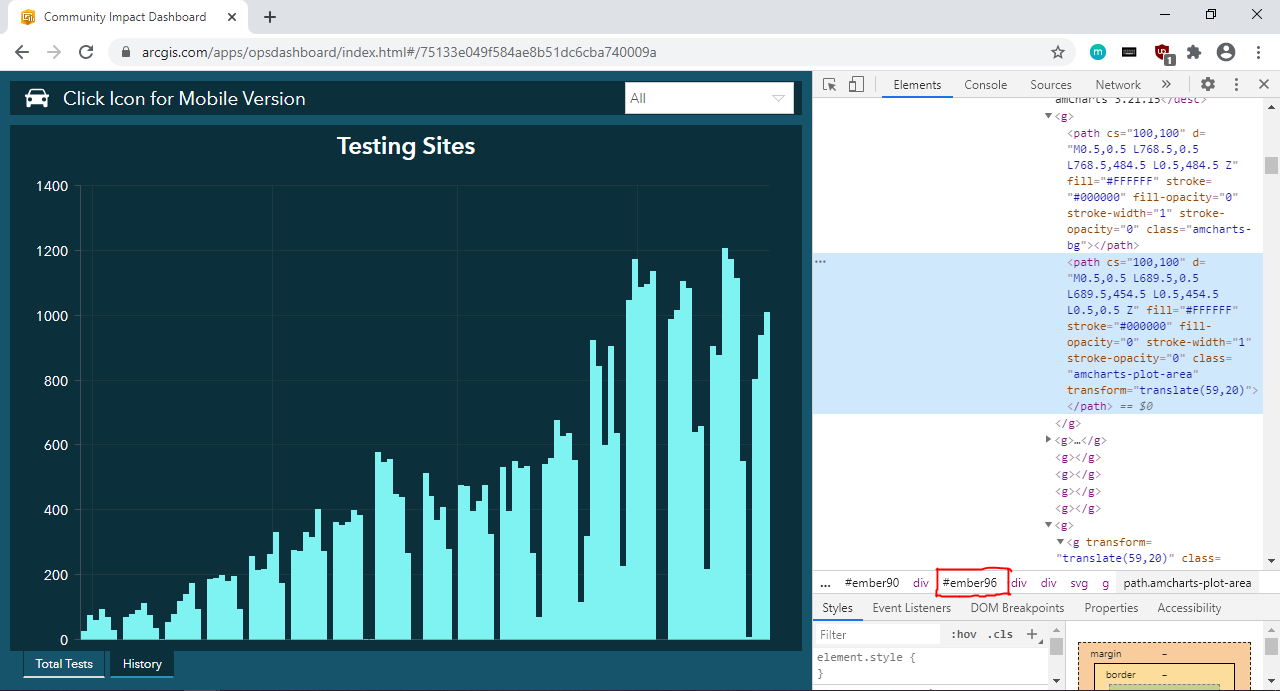
If you hover over a specific data point, a label containing the date and number of tests performed will appear. Use the Ctrl+Shift+C shortcut and click on a specific data point. You will see that the label text is stored as the aria-label attribute of a g element.
如果將鼠標懸停在特定數據點上,則會顯示一個標簽,其中包含執行的測試的日期和數量。 使用Ctrl+Shift+C快捷鍵,然后單擊特定的數據點。 您將看到標簽文本存儲為g元素的aria-label屬性。

Following the same steps for the daily case counts reported, you will see that the plot of daily case counts is in the div element with ID “ember143”.
按照報告的每日案件計數的相同步驟,您將看到每日案件計數的圖位于ID為“ ember143”的div元素中。
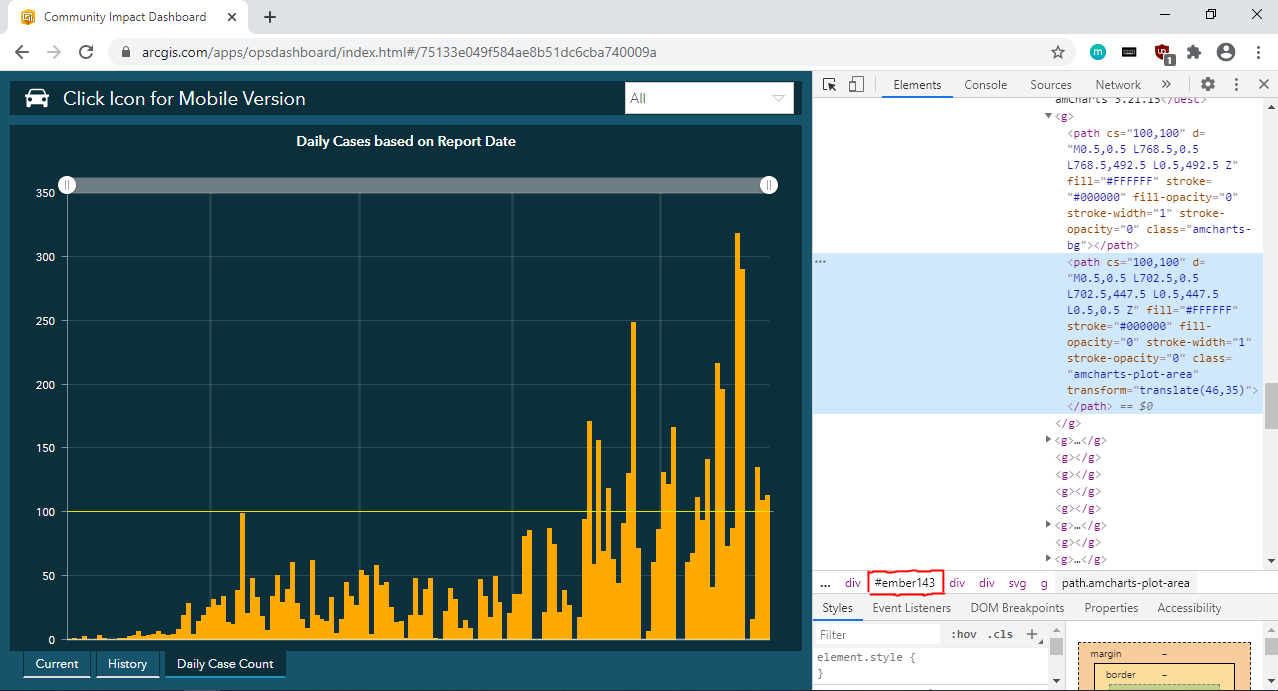
If you hover over a specific data point, a label containing the date and the number of positive cases reported will appear. Using the Ctrl+Shift+C shortcut, you will notice that the data are also stored in the aria-label attribute of g elements.
如果將鼠標懸停在特定數據點上,將顯示一個標簽,其中包含日期和報告的陽性病例數。 使用Ctrl+Shift+C快捷鍵,您會注意到數據也存儲在g元素的aria-label屬性中。

Once we have the elements that contain the data, we can write code that:
一旦有了包含數據的元素,就可以編寫代碼:
- Finds the div element that contains the plot of the total tests performed and pulls the total tests performed data 查找包含執行的總測試次數的圖的div元素,并提取執行的總測試數據
- Finds the div element that contains the plot of the daily case counts and pulls the daily case count data 查找包含每日案件計數圖的div元素,并提取每日案件計數數據
- Combines the data in a pandas dataframe and exports it to a CSV 將數據合并到pandas數據框中,并將其導出到CSV
步驟4:計算正率 (Step 4: Calculate Positivity Rate)
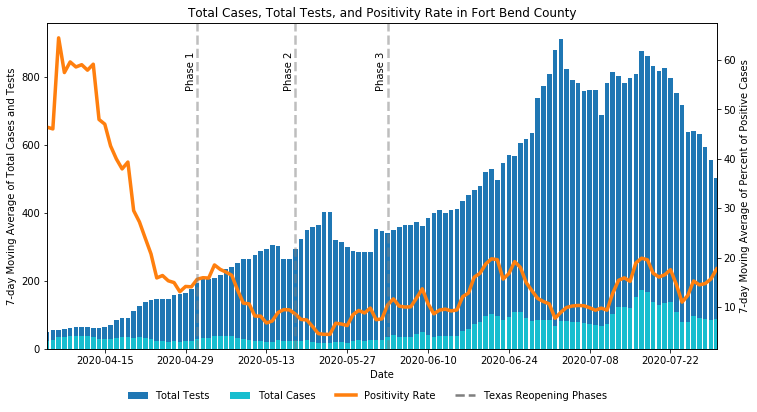
Now, we can finally estimate the COVID-19 positivity rate in Fort Bend County. We will divide the cases reported by the tests performed and calculate the 7-day moving averages. It is unclear from the dashboard whether the reported positive cases include cases that were determined through tests not conducted by the county (e.g. tests conducted at a hospital or clinic). It is also unclear when the tests for the positive cases were conducted since the dashboard only displays the reported case date. That is why the positivity rates derived from these data are only considered a rough estimate for the true positivity rate.
現在,我們終于可以估算出本德堡縣的COVID-19陽性率。 我們將通過執行的測試報告的案例相除,并計算7天移動平均值。 從儀表板尚不清楚,報告的陽性病例是否包括那些不是由縣進行的檢測(例如,在醫院或診所進行的檢測)確定的病例。 還不清楚何時進行陽性病例的測試,因為儀表板僅顯示報告的病例日期。 這就是為什么僅將這些數據得出的陽性率視為真實陽性率的粗略估計。
翻譯自: https://towardsdatascience.com/how-to-scrape-a-dashboard-with-python-8b088f6cecf3
python 儀表盤
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388348.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388348.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388348.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

VS2015 定時服務及控制端

css文件如何設置scss,Webpack - 如何將scss編譯成單獨的css文件?

Iphone表視圖的簡單操作

PhantomJS的使用

aws emr 大數據分析_DataOps —使用AWS Lambda和Amazon EMR的全自動,低成本數據管道


聯想r630服務器開啟虛擬化,整合虛擬化 聯想萬全R630服務器上市

Iphone屏幕旋轉

先進的NumPy數據科學


Xcode中捕獲iphone/ipad/ipod手機攝像頭的實時視頻數據


信息流服務器哪種好,選購存儲服務器需要注意六大關鍵因素,你知道幾個?

t3 深入Tornado


對數據倉庫進行數據建模_確定是否可以對您的數據進行建模
)
15 并發編程-(IO模型)
中將API鏈接消息解析為服務器(示例代碼))
arduino消息服務器,在C(Arduino IDE)中將API鏈接消息解析為服務器(示例代碼)

不提拔你,就是因為你只想把工作做好
