We will be covering some of the advanced concepts of NumPy specifically functions and methods required to work on a realtime dataset. Concepts covered here are more than enough to start your journey with data.
我們將介紹NumPy的一些高級概念,特別是實時數據集所需的功能和方法。 此處介紹的概念足以開始您的數據之旅。
To go ahead you are requested to know the basic concepts of NumPy if not I suggest you read my article “NumPy-The very basics!” first. You can find a link to it at the end of this article.
首先,要求您了解NumPy的基本概念,否則我建議您閱讀我的文章“ NumPy-非常基礎 !”。 第一。 您可以在本文末尾找到它的鏈接。
內容 (Contents)
Universal Functions
通用功能
Aggregation
聚合
Broadcasting
廣播
Masking
掩蔽
Fancy Indexing
花式索引
Array Sorting
數組排序
NumPy中的通用函數是什么? (What are Universal Functions in NumPy?)
Most of the time we have to loop over the array to perform simple computations like addition, subtraction, division, etc on each array element. Since these are repeated operations the time taken to compute increases with relatively larger data. Thankfully, NumPy makes this faster by using vectorized operations, generally implemented through NumPy’s universal functions (ufuncs). Let’s understand with an example.
大多數時候,我們必須遍歷數組以對每個數組元素執行簡單的計算,例如加法,減法,除法等。 由于這些是重復的操作,因此計算所需的時間隨著相對較大的數據而增加。 值得慶幸的是,NumPy通過使用矢量化操作(通常通過NumPy的通用函數(ufuncs)實現)使此操作更快。 讓我們看一個例子。
Suppose we have an array of random integers between 1 to 10 and would like to get square of each element of the array. What we do with the knowledge of Python is:
假設我們有一個介于1到10之間的隨機整數數組,并且想要獲得數組中每個元素的平方。 我們對Python的了解是:

This takes a lot of time to write and compute, especially for larger arrays in a real dataset. Let’s see how ufuncs make it simpler both ways.
這需要花費大量時間來編寫和計算,尤其是對于實際數據集中的較大數組。 讓我們看看ufuncs如何使這兩種方法都更簡單。

Simply by performing an operation on the array it will be applied to each element?within?the?array. As we notice it also retains the dtype. Ufunc operations are extremely flexible. We can also perform operations between two arrays.
只需通過對數組執行操作即可將其應用于數組中的每個元素。 我們注意到它還保留了dtype 。 Ufunc操作非常靈活。 我們還可以在兩個數組之間執行操作。
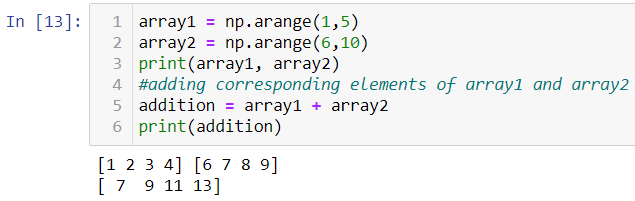
All these arithmetic operations are wrappers around NumPy builtin functions. For example, + operator is a wrapper for add function.
所有這些算術運算都是NumPy內置函數的包裝 。 例如,+運算符是add函數的包裝器。

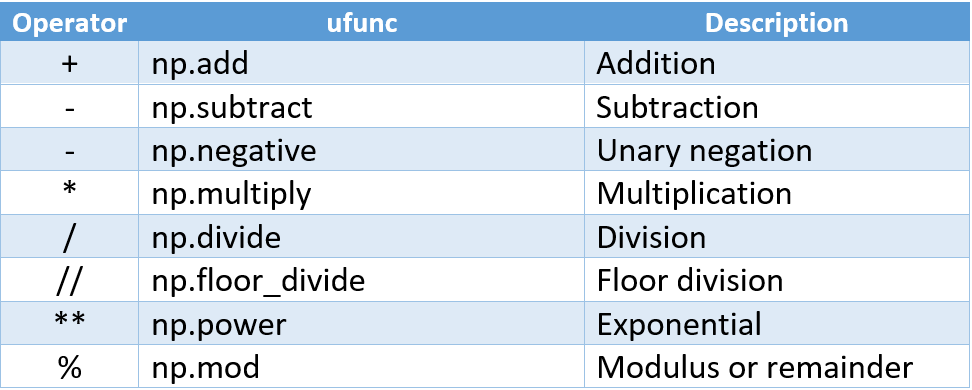
Below is the summary table of all the arithmetic operations in NumPy.
下表是NumPy中所有算術運算的匯總表。
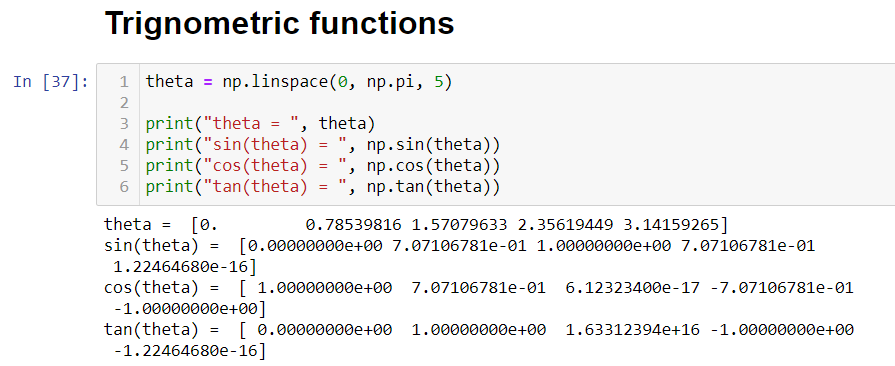
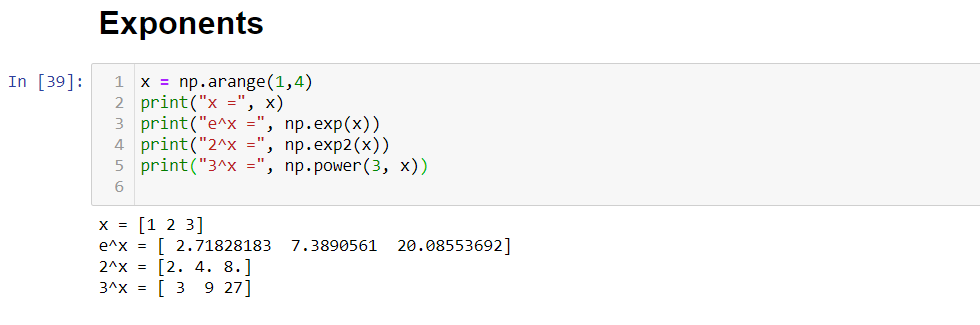
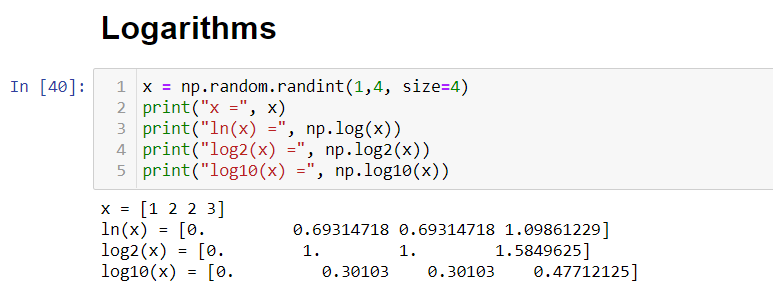
Some of the most useful functions provided by NumPy are trigonometric, logarithmic, and exponential functions. As data scientists, we are supposed to be aware of it. These will come handy while working on real datasets.
NumPy提供的一些最有用的函數是三角函數,對數函數和指數函數。 作為數據科學家,我們應該意識到這一點。 這些將在處理實際數據集時派上用場。

聚合 (Aggregation)
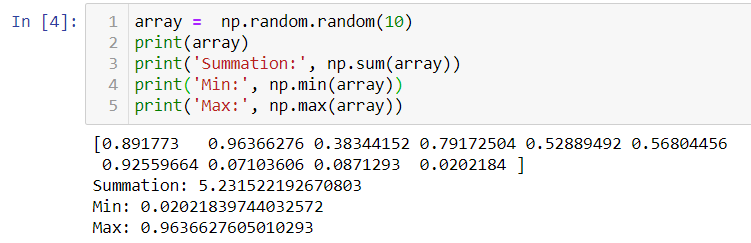
As a data analyst or data scientist, the very first step is to explore and understand the data. One way to do it is to compute summary statistics. Although, the most common statistical methods to summarize the data are mean and standard deviation other aggregates are also useful such as sum, product, median, maximum, minimum, etc.
作為數據分析師或數據科學家,第一步是探索和理解數據。 一種方法是計算匯總統計信息。 雖然,最常用的統計數據匯總方法是平均值和標準差,其他合計也很有用,例如總和,乘積,中位數,最大值,最小值等。
Let us understand with an example by computing the sum, min, and max.
讓我們以計算總和,最小和最大為例來理解。
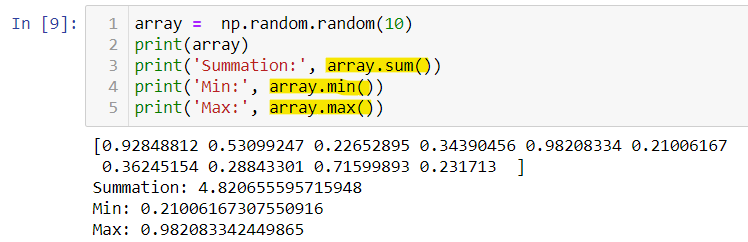
For most of the NumPy aggregates the shorthand syntax is to use methods of the array objects instead of functions. The above operation can also be performed as shown below which is of no difference computationally.
對于大多數NumPy聚合,速記語法是使用數組對象的方法而不是函數。 也可以如下所示執行上述操作,在計算上沒有區別。
IMPORTANT-Difference between Python aggregate functions and NumPy aggregate functions
重要 -Python聚合函數和NumPy聚合函數之間的區別
The one question you can raise is why to use NumPy aggregate functions when these functions are already inbuilt in Python ( sum(), min(), max(), etc). Of course, the difference is NumPy functions are much faster but more importantly NumPy functions are aware of dimensions. Python functions behave differently on multidimensional arrays.
您可能會提出的一個問題是,為什么已經在Python中內置了NumPy聚合函數(sum(),min(),max()等)。 當然,區別在于NumPy函數要快得多,但更重要的是NumPy函數知道尺寸。 Python函數在多維數組上的行為有所不同。
Suppose we like to get some of all the elements in an array of size 2x5. For better understanding, we will take a simple array of numbers from 0 to 9.
假設我們希望以2x5的大小獲取所有元素。 為了更好地理解,我們將使用一個簡單的數字數組,從0到9。
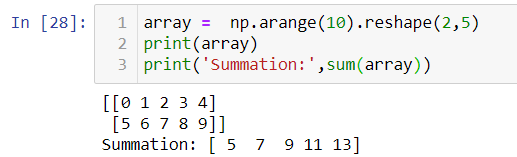
We were expecting the output to be 45 (0+1+2+3+4+5+6+7+8+9) but the result is very unexpected. These kinds of results will cost a lot while summarizing data. Hence, always make sure you are using the NumPy version of aggregate function while working on arrays.
我們期望輸出為45(0 + 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9),但結果出乎意料。 這些結果在匯總數據時會花費很多。 因此,始終確保在處理數組時使用聚合函數的NumPy版本。
Multidimensional aggregates
多維聚合
One common type of operation is aggregation along rows and columns. Since NumPy functions are aware of dimensions?it?is?easier?to?do?so, for example, minimum value among each row and column. Functions take an additional argument that specifies the axis along which we wish to perform aggregation.
一種常見的操作類型是沿行和列的聚合。 由于NumPy函數知道尺寸,因此更容易做到,例如,每一行和每一列中的最小值。 函數采用一個附加參數,該參數指定了我們希望沿其執行聚合的軸。
Suppose we have a table of marks obtained by students and each column represents a different subject. We wish to find the minimum?and maximum marks in each subject and total marks scored?by?each?student. ‘axis = 0’ to specify columns-wise operation and ‘axis=1’ for row-wise. The result will an 1-d array.
假設我們有一張學生獲得的分數表,每一列代表一個不同的學科。 我們希望找到每個學科的最低和最高分數,以及每個學生的總分數。 'axis = 0'指定列操作,'axis = 1'指定行操作。 結果將是一維數組。

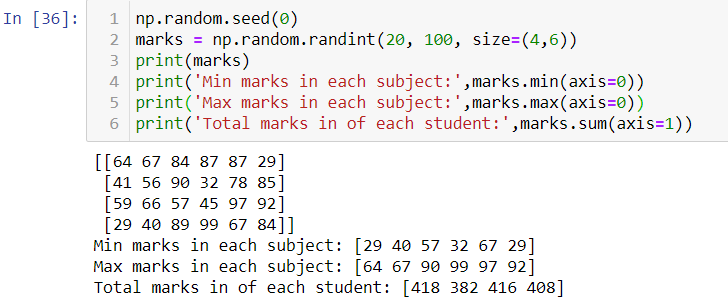
Other aggregation functions by NumPy
NumPy的其他聚合功能
np.prod, np.mean, np.std, np.var, np.argmin (find index of minimum value), np.argmax (find index of maximum value), np.median, np.percentile (compute rank-based statistics of elements).
np.prod,np.mean,np.std,np.var,np.argmin(最小值的查找索引),np.argmax(最大值的查找索引),np.median,np.percentile(基于計算等級)元素統計)。
廣播 (Broadcasting)
We have already seen NumPy universal functions at the very beginning. Broadcasting is another means of applying ufuncs but on arrays of different sizes. Broadcasting is nothing but a set of rules applied by NumPy to perform unfuncs on arrays of different sizes.
我們從一開始就已經看到了NumPy通用函數。 廣播是在其他大小的數組上應用ufunc的另一種方法。 廣播不過是NumPy應用于在不同大小的數組上執行取消功能的一組規則。
Consider adding two arrays of size 3x3 and 1x3. For our understanding, we can think of this operation as the smaller array is stretched or broadcasted to match the size of a larger array. This stretching of the array does not take place actually, this is just for better understanding.
考慮添加兩個大小為3x3和1x3的數組。 就我們的理解而言,我們可以認為此操作是將較小的數組拉伸或廣播以匹配較大的數組的大小。 數組的拉伸實際上并沒有發生,這只是為了更好地理解。
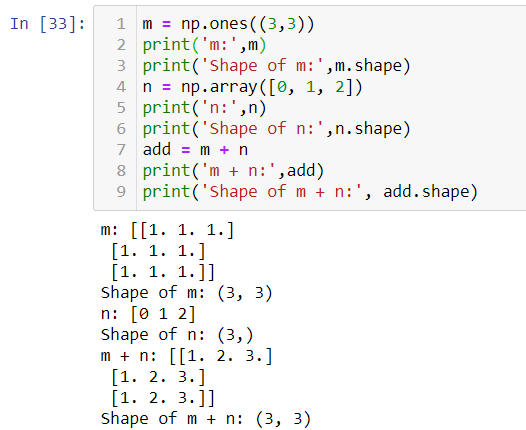
Confusion and complication increase when both the arrays need to be broadcasted.
當兩個陣列都需要廣播時,混亂和復雜性增加。
Jake VanderPlas, author of the book Python Data Science Handbook has provided excellent visualization to explain this process. The light-colored boxes represent the stretched values.
《 Python數據科學手冊》一書的作者Jake VanderPlas提供了出色的可視化效果來解釋這一過程。 淺色框代表拉伸值。
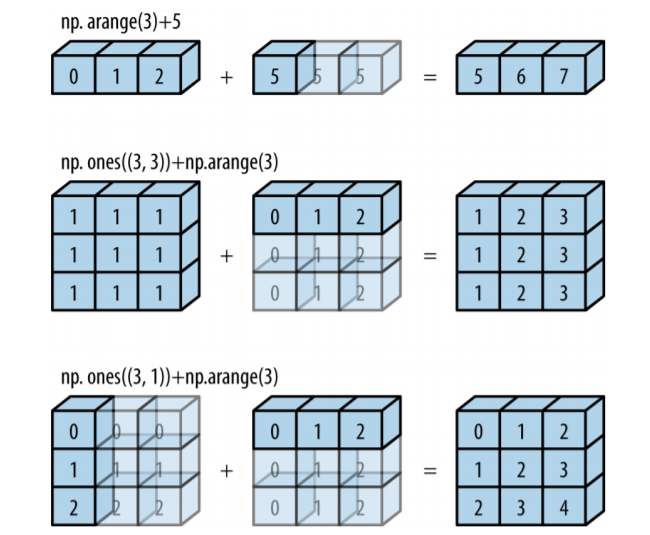
3 Rules for Broadcasting
3廣播規則
Above is the logical imagination to understand. We will explore the theoretical rules with examples.
以上是理解的邏輯想象。 我們將通過實例探索理論規則。
Example 1:
范例1:
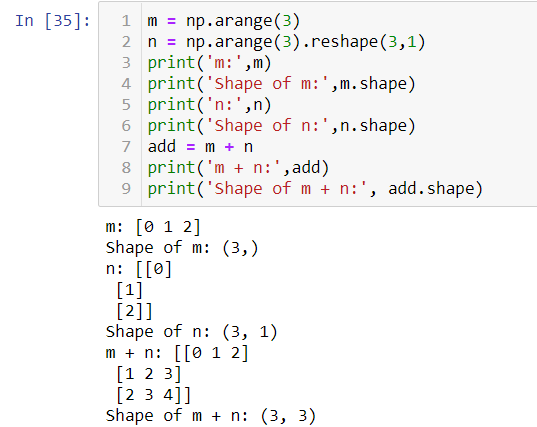
m = np.arange(3).reshape((3,1))
n = np.arange(3)
m.shape = (3, 1)
n.shape = (3,)By rule 1, if two arrays deffer in their shape the array with lesser shape should be padded with ‘1’ on it's left side.m.shape => (3, 1)
n.shape => (1, 3)By rule 2, if still the shape of two arrays do not match then each array whose dimension is equal to 1 should be broadcasted to match the shape of another array.m.shape => (3, 3)
n.shape => (3, 3)Stressing on rule 2, it says we can stretch the array only if value of one of its dimensions is 1. We cannot do this for dimension value other than 1. Let’s see an example where the dimension in the shape of an array will be different from 1 during the application of rule 2.
強調規則2,它說只有在其維度之一的值是1時,我們才能拉伸數組。我們不能對維度值除1進行拉伸。讓我們來看一個示例,其中數組形狀的維度將不同在應用規則2時從1開始。
Example 2:
范例2:
m = np.arange(3).reshape((3,2))
n = np.arange(3)
m.shape = (3, 1)
n.shape = (3,)By rule 1,m.shape => (3, 2)
n.shape => (1, 3)By rule 2,m.shape => (3, 2)
n.shape => (3, 3)By rule 3, if shapes of both array disagree and any dimension of neither array is 1 then an error should be raised.掩蔽 (Masking)
Masking is a method used extensively in the data processing. It allows us to extract, count, modify or manipulate values in an array based on certain criteria, these criteria are specified using comparison operators and boolean operators.
屏蔽是一種廣泛用于數據處理的方法。 它允許我們根據某些條件提取,計數,修改或操作數組中的值,這些條件是使用比較運算符和布爾運算符指定的。
Suppose we have a two-dimensional array of size (3, 4) we would like to get a subset of the array whose values are less than 5.
假設我們有一個大小為(3,4)的二維數組,我們希望得到該數組的一個子集,其值小于5。
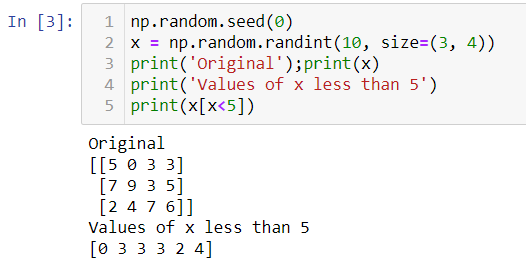
Let’s break it down
讓我們分解一下
We used a comparison operator ‘<’ on array x. As we already know this applies element-wise ufunc (np.less()) on the array. As a result, we get an array of boolean operators. True, if the element at the corresponding position is less than 5 else False.
我們在數組x上使用了比較運算符'<'。 眾所周知,這在數組上應用了逐元素的ufunc(np.less())。 結果,我們得到一個布爾運算符數組。 如果在相應位置的元素小于5,則為True,否則為False。
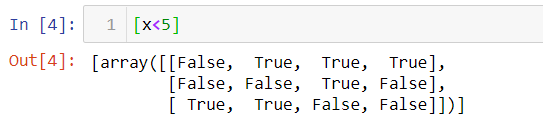
When we say x[x<5], the above returned boolean values are applied on original array x resulting to return the elements of the array whose indices are True, eventually values less than 5. Similar way we can use all the comparison or boolean operators available in Python. We can even combine two operations say x[(x>3) & (x<6)] to get values between 3 and 6, only that the result of operations should be boolean. Notice, here we use bitwise operator ‘&’ rather than keyword ‘and’.
當我們說x [x <5]時,以上返回的布爾值將應用于原始數組x,從而返回索引為True且最終值小于5的數組元素。類似的方式,我們可以使用所有比較或布爾值Python中可用的運算符。 我們甚至可以結合兩個操作x [(x> 3)&(x <6)]來獲得3到6之間的值,只是操作的結果應該是布爾值。 注意,這里我們使用按位運算符“&”而不是關鍵字“ and”。
REMEMBER
記得
The keyword ‘and’ and ‘or’ performs single boolean operation on entire array while bitwise ‘&’ and ‘|’ performs multiple boolean operations on elements of an array. Always use bit-wise operators while masking.
關鍵字“ and”和“或”對整個數組執行單個布爾運算,而按位的“&”和“ |” 對數組的元素執行多個布爾操作。 屏蔽時始終使用按位運算符。
花式索引 (Fancy indexing)
Fancy indexing is similar to normal indexing as we already know. The only difference is we pass an array of indices here. This advanced version of indexing allows quick access and/or modification of complicated subsets of an array.
如我們所知,花式索引與普通索引相似。 唯一的區別是我們在這里傳遞了一組索引。 索引的此高級版本允許快速訪問和/或修改數組的復雜子集。
Suppose we want to access elements at index 2, 5, and 9 of an array, the old school method would be [x[2], x[5], x[9]]. This can we simplified using fancy indexing.
假設我們要訪問數組索引2、5和9的元素,則舊的方法是[x [2],x [5],x [9]]。 我們可以使用花式索引來簡化此操作。

Likewise, we can fancy index two-dimensional array. Let’s see equivalent operation of x[0, 2], x[1, 3] and x[2, 1] in fancy indexing.
同樣,我們可以看上二維數組的索引。 讓我們看一下花式索引中x [0,2],x [1,3]和x [2,1]的等效操作。

This can be further simplified if either row or column value is constant. Let’s say we like to get values at index x[2, 1], x[2, 3] and x[2, 4]. The below yellow color highlight is for row value and blue color for the column value. Similarly, we can also modify values using fancy indexing by using the assignment operator ‘=’.
如果行或列的值恒定,則可以進一步簡化。 假設我們喜歡獲取索引為x [2,1],x [2,3]和x [2,4]的值。 下面的黃色高亮顯示為行值,藍色為列值。 同樣,我們也可以通過賦值運算符'=' 使用花式索引來修改值 。

數組排序 (Array sorting)
np.sort is a more efficient sorting function than Python’s built-in sort function. Additionally, np.sort is aware of dimensions. Let’s see a few flavors of the NumPy sorting function.
np.sort是比Python內置的sort函數更有效的排序函數。 另外, np.sort知道Dimensions 。 讓我們來看看NumPy排序函數的幾種風格。

Notice, when we use the method sort(), it alters the value of array x itself. Meaning, the original order of array x in lost. It is called in-place sorting.
注意,當我們使用方法sort()時,它會更改數組x本身的值。 意思是,數組x的原始順序丟失了。 這稱為就地排序 。

Although these are not the only concepts of NumPy still I have managed to cover all critical and must-know concepts. This is clearly more than enough for getting started with data science. Since Python is open-source many functions keep adding and deprecating regularly. Always keep an eye on NumPy’s official documentation. I will also make sure I keep updating content as and when required.
盡管這些不是NumPy的唯一概念,但我還是設法涵蓋了所有關鍵且必須知道的概念。 對于數據科學入門而言,這顯然綽綽有余。 由于Python是開源的,因此許多功能會定期添加和棄用。 始終注意NumPy的官方文檔 。 我還將確保在需要時不斷更新內容。
翻譯自: https://medium.com/analytics-vidhya/advanced-numpy-218584c60c63
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388339.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388339.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388339.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


Xcode中捕獲iphone/ipad/ipod手機攝像頭的實時視頻數據


信息流服務器哪種好,選購存儲服務器需要注意六大關鍵因素,你知道幾個?

t3 深入Tornado


對數據倉庫進行數據建模_確定是否可以對您的數據進行建模
)
15 并發編程-(IO模型)
中將API鏈接消息解析為服務器(示例代碼))
arduino消息服務器,在C(Arduino IDE)中將API鏈接消息解析為服務器(示例代碼)

不提拔你,就是因為你只想把工作做好

python內置函數多少個_每個數據科學家都應該知道的10個Python內置函數

C#使用TCP/IP與ModBus進行通訊

Hadoop HDFS常用命令

SAP UI 搜索分頁技術

萬彩錄屏服務器不穩定,萬彩錄屏 云服務器

針對數據科學家和數據工程師的4條SQL技巧
)
C# 讀取CAD文件縮略圖(DWG文件)

)
14.并發容器之ConcurrentHashMap(JDK 1.8版本)
