aws emr 大數據分析
Progression is continuous. Taking a flashback journey through my 25 years career in information technology, I have experienced several phases of progression and adaptation.
進步是連續的。 在我25年的信息技術職業生涯中經歷了一次閃回之旅,我經歷了發展和適應的多個階段。
From a newly hired recruit who carefully watched every single SQL command run to completion to a confident DBA who scripted hundreds of SQL’s and ran them together as batch jobs using the Cron scheduler. In the modern era I adapted to DAG tools like Oozie and Airflow that not only provide job scheduling but can to run a series of jobs as data pipelines in an automated fashion.
從新雇用的新手,他仔細地觀察每條SQL命令的執行情況,到自信的DBA,他用Cron調度程序編寫了數百個SQL腳本并將它們作為批處理作業一起運行。 在現代時代,我適應了OAGie和Airflow之類的DAG工具,這些工具不僅可以提供作業調度,還可以以自動化方式將一系列作業作為數據管道運行。
Lately, the adoption of cloud has changed the whole meaning of automation.
最近,云的采用改變了自動化的整體含義。
存儲價格便宜,計算機價格昂貴 (STORAGE is cheap, COMPUTE is expensive)
In the cloud era, we can design automation methods that were previously unheard of. I admit that cloud storage resources are getting cheaper by the day but the compute resources (high CPU and memory) are still relatively expensive. Keeping that in mind, wouldn’t it be super cool if DataOps can help us save on compute costs. Let’s find out how this can be done:
在云時代,我們可以設計以前聞所未聞的自動化方法。 我承認云存儲資源一天比一天便宜,但是計算資源(高CPU和內存)仍然相對昂貴。 記住這一點,如果DataOps可以幫助我們節省計算成本,那豈不是超級酷。 讓我們找出如何做到這一點:
Typically, we run data pipelines as follows:
通常,我們按以下方式運行數據管道:
Data collection at regular time intervals (daily, hourly or by the minute) saved to storage like S3. This is usually followed up by data processing jobs using permanently spawned distributed computing clusters like EMR.
按固定的時間間隔(每天,每小時或每分鐘)收集數據,并像S3一樣保存到存儲中。 接下來通常是使用永久生成的分布式計算集群(如EMR)進行數據處理作業。
Pros: Processing Jobs run on a schedule. Permanent cluster can be utilized for other purposes like querying using Hive, streaming workloads etc.
優點:處理作業按計劃運行。 永久群集可以用于其他目的,例如使用Hive查詢,流式處理工作負載等。
Cons: There can be a delay between the time data arrives vs. when it gets processed. Compute resources may not be optimally utilized. There may be under utilization at times, therefore wasting expensive $$$
缺點:數據到達與處理之間可能會有延遲。 計算資源可能沒有得到最佳利用。 有時可能利用率不足,因此浪費了昂貴的$$$
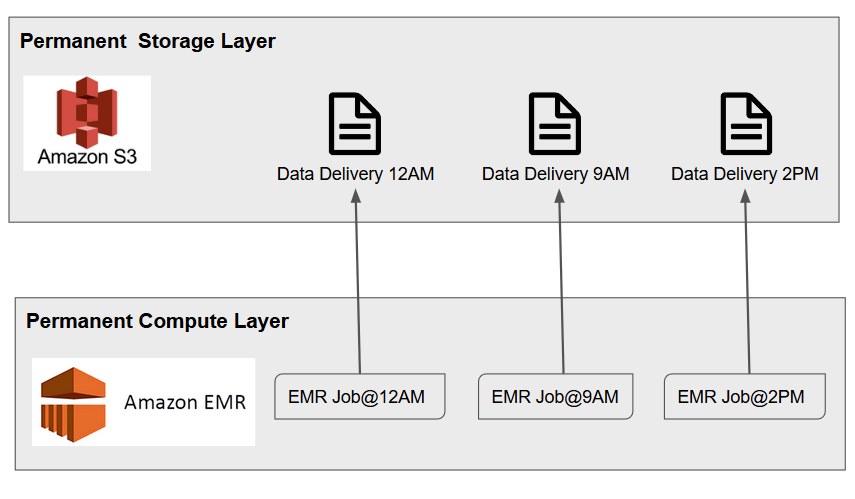
Here is an alternative that can help achieve the right balance between operation and costs. This method may not apply to all use cases, but if it does then rest assured it will save you a lot of $$$.
這是可以幫助在運營和成本之間實現適當平衡的替代方法。 此方法可能不適用于所有用例,但是如果可以放心使用,則可以節省很多資金。
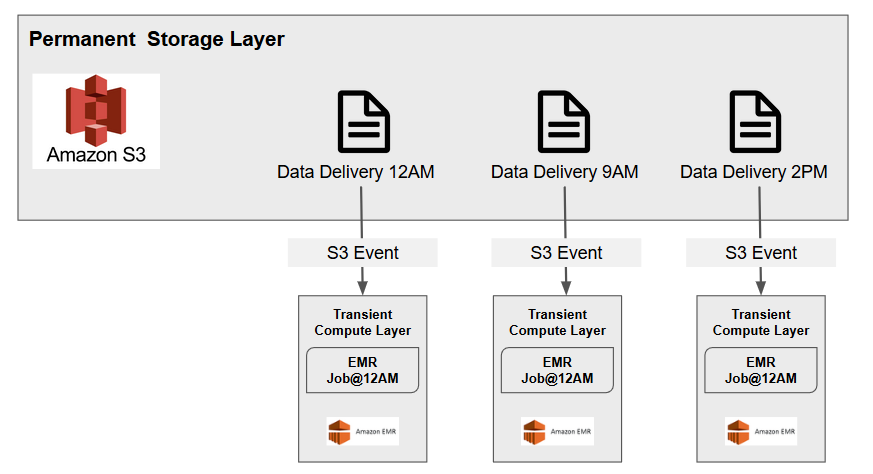
In this method the storage layer stays pretty much the same, except an event notification is added to the storage that invokes a Lambda function when new data arrives. In turn the Lambda function invokes the creation of a transient EMR cluster for data processing. A transient EMR cluster is a special type of cluster that deploys, runs the data processing job and then self-destructs.
在這種方法中,存儲層幾乎保持不變,只是事件通知被添加到存儲中,該通知在新數據到達時調用Lambda函數。 Lambda函數進而調用瞬態EMR集群的創建以進行數據處理。 臨時EMR群集是一種特殊類型的群集,它可以部署,運行數據處理作業,然后自毀。
Pros: Processing jobs can start as soon as the data is available. No waits. Compute resources optimally utilized. Only pay for what you use and save $$$.
優點:數據可用后即可開始處理作業。 沒有等待。 計算最佳利用的資源。 只需支付您使用的費用,即可節省$$$。
Cons: Cluster cannot be utilized for other purposes like querying using Hive, streaming workloads etc.
缺點:群集不能用于其他目的,例如使用Hive查詢,流工作負載等。
Here is how the entire process is handled technically:
這是技術上處理整個過程的方式:
Assume the data files are delivered to s3://<BUCKET>/raw/files/renewable/hydropower-consumption/<DATE>_<HOUR>
假設數據文件已傳遞到s3:// <BUCKET> / raw / files / renewable / hydropower-consumption / <DATE> _ <HOUR>
Clone my git repo:
克隆我的git repo:
$ git clone https://github.com/mkukreja1/blogs.gitCreate a new S3 Bucket for running the demo. Remember to change the bucket name since S3 bucket name are globally unique.
創建一個新的S3存儲桶以運行演示。 請記住要更改存儲桶名稱,因為S3存儲桶名稱是全局唯一的。
$ S3_BUCKET=lambda-emr-pipeline #Edit as per your bucket name$ REGION='us-east-1' #Edit as per your AWS region$ JOB_DATE='2020-08-07_2PM' #Do not Edit this$ aws s3 mb s3://$S3_BUCKET$ aws s3 cp blogs/lambda-emr/emr.sh s3://$S3_BUCKET/bootstrap/$ aws s3 cp blogs/lambda-emr/hydropower-processing.py s3://$S3_BUCKET/spark/Create a role for the Lambda Function
為Lambda函數創建角色
$ aws iam create-role --role-name trigger-pipeline-role --assume-role-policy-document file://blogs/lambda-emr//lambda-policy.json$ aws iam attach-role-policy --role-name trigger-pipeline-role --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole$ aws iam attach-role-policy --role-name trigger-pipeline-role --policy-arn arn:aws:iam::aws:policy/AmazonElasticMapReduceFullAccessCreate the Lambda Function in AWS
在AWS中創建Lambda函數
$ ROLE_ARN=`aws iam get-role --role-name trigger-pipeline-role | grep Arn |sed 's/"Arn"://' |sed 's/,//' | sed 's/"//g'`;echo $ROLE_ARN$ cat blogs/lambda-emr/trigger-pipeline.py | sed "s/YOUR_BUCKET/$S3_BUCKET/g" | sed "s/YOUR_REGION/'$REGION'/g" > lambda_function.py$ zip trigger-pipeline.zip lambda_function.py$ aws lambda delete-function --function-name trigger-pipeline$ LAMBDA_ARN=` aws lambda create-function --function-name trigger-pipeline --runtime python3.6 --role $ROLE_ARN --handler lambda_function.lambda_handler --timeout 60 --zip-file fileb://trigger-pipeline.zip | grep FunctionArn | sed -e 's/"//g' -e 's/,//g' -e 's/FunctionArn//g' -e 's/: //g' `;echo $LAMBDA_ARN$ aws lambda add-permission --function-name trigger-pipeline --statement-id 1 --action lambda:InvokeFunction --principal s3.amazonaws.comFinally, let's create the S3 event notification. This notification will invoke the Lambda function above.
最后,讓我們創建S3事件通知。 此通知將調用上面的Lambda函數。
$ cat blogs/lambda-emr/notification.json | sed "s/YOUR_LAMBDA_ARN/$LAMBDA_ARN/g" | sed "s/\ arn/arn/" > notification.json$ aws s3api put-bucket-notification-configuration --bucket $S3_BUCKET --notification-configuration file://notification.json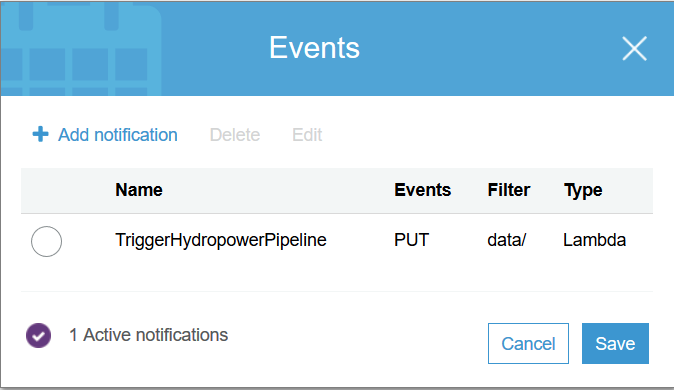
Let's kick off the process by copying data to S3
讓我們開始將數據復制到S3的過程
$ aws s3 rm s3://$S3_BUCKET/curated/ --recursive
$ aws s3 rm s3://$S3_BUCKET/data/ --recursive$ aws s3 sync blogs/lambda-emr/data/ s3://$S3_BUCKET/data/If everything ran OK you should be able to see a running Cluster in EMR with Status=Starting
如果一切正常,您應該可以在Status = Starting的 EMR中看到正在運行的集群

After some time the EMR cluster should change to Status=Terminated.
一段時間后,EMR群集應更改為Status = Terminated。

To check if the Spark program was successful check the S3 folder as below:
要檢查Spark程序是否成功,請檢查S3文件夾,如下所示:
$ aws s3 ls s3://$S3_BUCKET/curated/2020-08-07_2PM/
2020-08-10 17:10:36 0 _SUCCESS
2020-08-10 17:10:35 18206 part-00000-12921d5b-ea28-4e7f-afad-477aca948beb-c000.snappy.parquetMoving into the next phase of Data Engineering and Data Science automation of data pipelines is becoming a critical operation. If done correctly it carries a potential for streamlining not only operations but resource costs as well.
進入數據工程和數據科學的下一階段,數據管道自動化已成為一項關鍵操作。 如果做得正確,它不僅可以簡化運營,還可以簡化資源成本。
Hope you gained some valuable insights from the article above. Feel free to contact me if you need further clarifications and advice.
希望您從上面的文章中獲得了一些有價值的見解。 如果您需要進一步的說明和建議,請隨時與我聯系。
翻譯自: https://towardsdatascience.com/dataops-fully-automated-low-cost-data-pipelines-using-aws-lambda-and-amazon-emr-c4d94fdbea97
aws emr 大數據分析
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388343.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388343.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388343.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


聯想r630服務器開啟虛擬化,整合虛擬化 聯想萬全R630服務器上市

Iphone屏幕旋轉

先進的NumPy數據科學


Xcode中捕獲iphone/ipad/ipod手機攝像頭的實時視頻數據


信息流服務器哪種好,選購存儲服務器需要注意六大關鍵因素,你知道幾個?

t3 深入Tornado


對數據倉庫進行數據建模_確定是否可以對您的數據進行建模
)
15 并發編程-(IO模型)
中將API鏈接消息解析為服務器(示例代碼))
arduino消息服務器,在C(Arduino IDE)中將API鏈接消息解析為服務器(示例代碼)

不提拔你,就是因為你只想把工作做好

python內置函數多少個_每個數據科學家都應該知道的10個Python內置函數

C#使用TCP/IP與ModBus進行通訊

Hadoop HDFS常用命令

SAP UI 搜索分頁技術

萬彩錄屏服務器不穩定,萬彩錄屏 云服務器
