python內置函數多少個
Python is the number one choice of programming language for many data scientists and analysts. One of the reasons of this choice is that python is relatively easier to learn and use. More importantly, there is a wide variety of third party libraries that ease lots of tasks in the field of data science. For instance, numpy and pandas are great data analysis libraries. Scikit-learn and tensorflow are for machine learning and data preprocessing tasks. We also have python data visualization libraries such as matplotlib and seaborn. There are many more useful libraries for data science in python ecosystem.
對于許多數據科學家和分析師來說,Python是編程語言的第一選擇。 這種選擇的原因之一是python相對易于學習和使用。 更重要的是,有各種各樣的第三方庫可以減輕數據科學領域的許多任務。 例如, numpy和pandas是出色的數據分析庫。 Scikit-learn和tensorflow用于機器學習和數據預處理任務。 我們還有python數據可視化庫,例如matplotlib和seaborn 。 在python生態系統中,還有許多用于數據科學的有用庫。
In this post, we will not talk about these libraries or frameworks. We will rather cover important built-in functions of python. Some of these functions are also used in the libraries we mentioned. There is no point in reinventing the wheel.
在本文中,我們將不討論這些庫或框架。 我們寧愿介紹重要的python內置函數。 我們提到的庫中也使用了其中一些功能。 重新發明輪子沒有意義。
Let’s start.
開始吧。
1套 (1. Set)
Set function returns a set object from an iterable (e.g. a list). Set is an unordered sequence of unique values. Thus, unlike lists, sets do not have duplicate values. One use case of sets is to remove duplicate values from a list or tuple. Let’s go over an example.
Set函數從迭代器(例如列表)返回set對象。 Set是唯一值的無序序列。 因此,與列表不同,集合不具有重復值。 集的一種用例是從列表或元組中刪除重復的值。 讓我們來看一個例子。
list_a = [1,8,5,3,3,4,4,4,5,6]
set_a = set(list_a)
print(list_a)
print(set_a)
[1, 8, 5, 3, 3, 4, 4, 4, 5, 6]
{1, 3, 4, 5, 6, 8}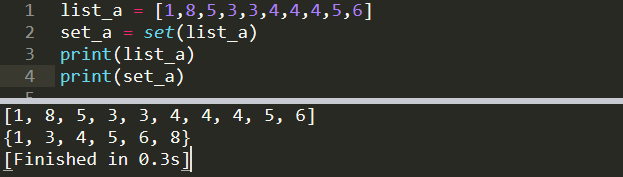
As you can see, duplicates are removed and the values are sorted. Sets are not subscriptable (because of not keeping an order) so we cannot access or modify the individual elements of a set. However, we can add elements to a set or remove elements from a set.
如您所見,將刪除重復項并對值進行排序。 集合不可下標(因為不保持順序),因此我們無法訪問或修改集合的各個元素。 但是,我們可以將元素添加到集合中 或從集合中刪除元素。
set_a.add(15)
print(set_a)
{1, 3, 4, 5, 6, 8, 15}2.列舉 (2. Enumerate)
Enumerate provides a count when working with iterables. It can be placed in a for loop or directly used on an iterable to create an enumerate object. Enumerate object is basically a list of tuples.
枚舉提供了使用可迭代對象時的計數。 可以將其放在for循環中,也可以直接在可迭代對象上使用以創建枚舉對象。 枚舉對象基本上是一個元組列表。
cities = ['Houston', 'Rome', 'Berlin', 'Madrid']
print(list(enumerate(cities)))
[(0, 'Houston'), (1, 'Rome'), (2, 'Berlin'), (3, 'Madrid')]Using with a for loop:
與for循環一起使用:
for count, city in enumerate(cities):
print(count, city)0 Houston
1 Rome
2 Berlin
3 Madrid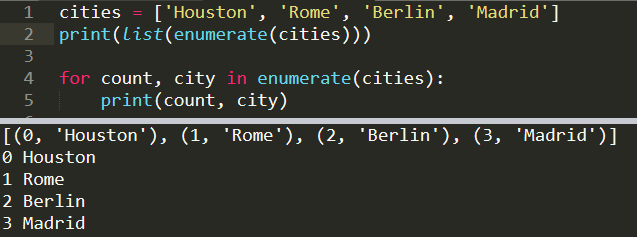
3.實例 (3. Isinstance)
Isinstance function is used to check or compare the classes of objects. It accepts an object and a class as arguments and returns True if the object is an instance of that class.
Isinstance函數用于檢查或比較對象的類。 它接受一個對象和一個類作為參數,如果該對象是該類的實例,則返回True。
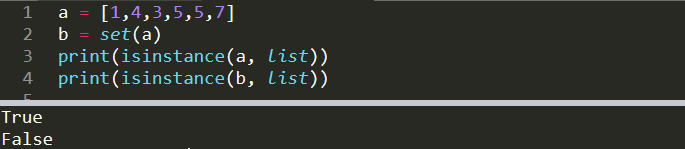
a = [1,4,3,5,5,7]
b = set(a)
print(isinstance(a, list))
print(isinstance(b, list))
True
FalseWe can access the class of an object using type function but isinstance comes in hand when doing comparisons.
我們可以使用類型函數來訪問對象的類,但是在進行比較時會使用isinstance。
4.倫 (4. Len)
Len function returns the length of an object or the number of items in an object. For instance, len can be used to check:
Len函數返回對象的長度或對象中的項目數。 例如,len可用于檢查:
- Number of characters in a string 字符串中的字符數
- Number of elements in a list 列表中的元素數
- Number of rows in a dataframe 數據框中的行數
a = [1,4,3,5,5,7]
b = set(a)
c = 'Data science'print(f'The length of a is {len(a)}')
print(f'The length of b is {len(b)}')
print(f'The length of c is {len(c)}')The length of a is 6
The length of b is 5
The length of c is 12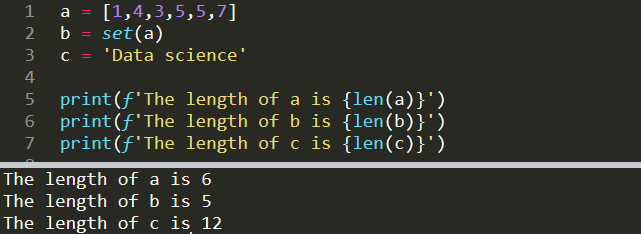
5.排序 (5. Sorted)
As the name clearly explains, sorted function is used to sort an iterable. By default, sorting is done in ascending order but it can be changed with reverse parameter.
顧名思義,sorted函數用于對Iterable進行排序。 默認情況下,排序按升序進行,但可以使用反向參數進行更改。
a = [1,4,3,2,8]print(sorted(a))
print(sorted(a, reverse=True))[1, 2, 3, 4, 8]
[8, 4, 3, 2, 1]We may need to sort a list or pandas series when doing data cleaning and processing. Sorted can also be used to sort the characters of a string but it returns a list.
進行數據清理和處理時,我們可能需要對列表或熊貓系列進行排序。 Sorted也可以用于對字符串的字符進行排序,但是它返回一個列表。
c = "science"
print(sorted(c))
['c', 'c', 'e', 'e', 'i', 'n', 's']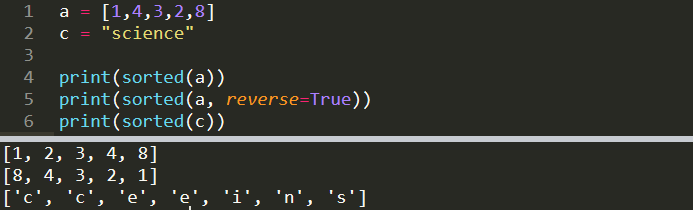
6.郵編 (6. Zip)
Zip function takes iterables as argument and returns an iterator consists of tuples. Consider we have two associated lists.
Zip函數將Iterables作為參數,并返回由元組組成的迭代器。 考慮我們有兩個關聯的列表。
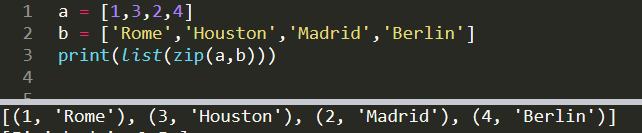
a = [1,3,2,4]
b = ['Rome','Houston','Madrid','Berlin']print(list(zip(a,b)))
[(1, 'Rome'), (3, 'Houston'), (2, 'Madrid'), (4, 'Berlin')]The iterables do not have to have the same length. The first matching indices are zipped. For instance, if list a was [1,3,2,4,5] in the case above, the output would be the same. Zip function can also take more than two iterables.
可迭代對象的長度不必相同。 首個匹配索引已壓縮。 例如,如果在上述情況下列表a為[1,3,2,4,5],則輸出將相同。 Zip函數也可以采用兩個以上的可迭代項。
7.任何和全部 (7. Any and All)
I did not want to separate any and all functions because they are kind of complement of each other. Any returns True if any element of an iterable is True. All returns True if all elements of an iterable is True.
我不想分離任何和所有功能,因為它們互為補充。 如果iterable的任何元素為True,則Any返回True。 如果iterable的所有元素均為True,則All返回True。
One typical use case of any and all is checking the missing values in a pandas series or dataframe.
任何一種情況的一個典型用例是檢查熊貓系列或數據框中的缺失值。
import pandas as pd
ser = pd.Series([1,4,5,None,9])print(ser.isna().any())
print(ser.isna().all())True
False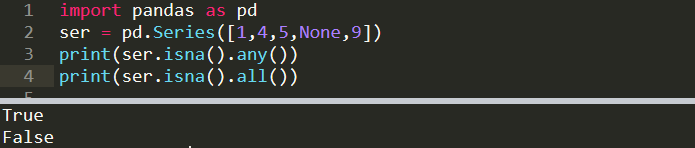
8.范圍 (8. Range)
Range is an immutable sequence. It takes 3 arguments which are start, stop, and step size. For instance, range(0,10,2) returns a sequence that starts at 0 and stops at 10 (10 is exclusive) with increments of 2.
范圍是一個不變的序列。 它接受3個參數,分別是start , stop和step size。 例如,range(0,10,2)返回一個序列,該序列從0開始并在10(不包括10)處停止,且增量為2。
The only required argument is stop. Start and step arguments are optional.
唯一需要的參數是stop。 開始和步驟參數是可選的。
print(list(range(5)))
[0, 1, 2, 3, 4]print(list(range(2,10,2)))
[2, 4, 6, 8]print(list(range(0,10,3)))
[0, 3, 6, 9]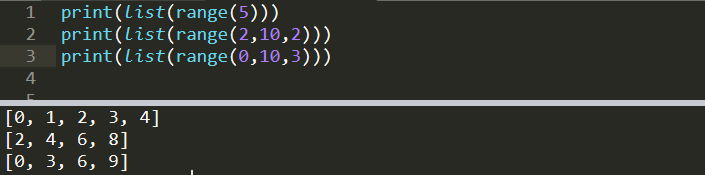
9.地圖 (9. Map)
Map function applies a function to every element of an iterator and returns an iterable.
Map函數將一個函數應用于迭代器的每個元素,并返回一個可迭代的對象。
a = [1,2,3,4,5]print(list(map(lambda x: x*x, a)))
[1, 4, 9, 16, 25]We used map function to square each element of list a. This operation can also be done with a list comprehension.
我們使用map函數對列表a的每個元素求平方。 該操作也可以通過列表理解來完成。
a = [1,2,3,4,5]
b = [x*x for x in a]
print(b)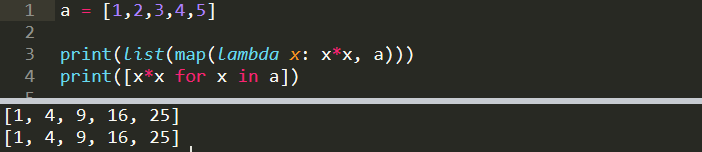
List comprehension is preferable over map function in most cases due to its speed and simpler syntax. For instance, for a list with 1 million elements, my computer accomplished this task in 1.2 seconds with list comprehension and in 1.4 seconds with map function.
在大多數情況下,列表理解比map函數更可取,因為它的速度和語法更簡單。 例如,對于具有一百萬個元素的列表,我的計算機通過列表理解在1.2秒內完成了此任務,而在使用map功能時在1.4秒內完成了此任務。
When working with larger iterables (much larger than 1 million), map is a better choice due to memory issues. Here is a detailed post on list comprehensions if you’d like to read further.
當使用較大的可迭代對象(遠大于100萬)時,由于內存問題,映射是更好的選擇。 如果您想進一步閱讀,這是有關列表理解的詳細信息。
10.清單 (10. List)
List is a mutable sequence used to store collections of items with same or different types.
列表是一個可變序列,用于存儲相同或不同類型的項目的集合。
a = [1, 'a', True, [1,2,3], {1,2}]print(type(a))
<class 'list'>print(len(a))
5a is a list that contains an integer, a string, a boolean value, a list, and a set. For this post, we are more interested in creating list with a type constructor (list()). You may have noticed that we used list() throughout this post. It takes an iterable and converts it to a list. For instance, map(lambda x: x*x, a) creates an iterator. We converted to a list to print it.
a是一個包含整數,字符串,布爾值,列表和集合的列表。 對于本文,我們對使用類型構造函數(list())創建列表更感興趣。 您可能已經注意到,本文中我們一直使用list()。 它需要一個可迭代的并將其轉換為列表。 例如,map(lambda x:x * x,a)創建一個迭代器。 我們將其轉換為列表以進行打印。
We can create a list from a range, set, pandas series, numpy array, or any other iterable.
我們可以從范圍,集合,熊貓系列,numpy數組或任何其他可迭代對象創建列表。
import numpy as npa = {1,2,3,4}
b = np.random.randint(10, size=5)
c = range(6)print(list(a))
[1, 2, 3, 4]print(list(b))
[4, 4, 0, 5, 3]print(list(c))
[0, 1, 2, 3, 4, 5]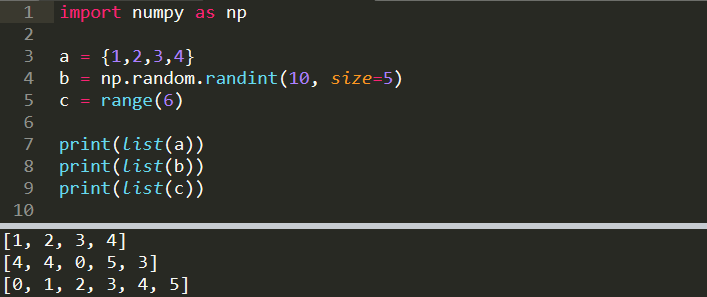
Thank you for reading. Please let me know if you have any feedback.
感謝您的閱讀。 如果您有任何反饋意見,請告訴我。
翻譯自: https://towardsdatascience.com/10-python-built-in-functions-every-data-scientist-should-know-233b302abc05
python內置函數多少個
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388328.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388328.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388328.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

C#使用TCP/IP與ModBus進行通訊

Hadoop HDFS常用命令

SAP UI 搜索分頁技術

萬彩錄屏服務器不穩定,萬彩錄屏 云服務器

針對數據科學家和數據工程師的4條SQL技巧
)
C# 讀取CAD文件縮略圖(DWG文件)

)
14.并發容器之ConcurrentHashMap(JDK 1.8版本)

modbus注意幾點

服務器虛擬化網口,服務器安裝虛擬網口

芒果云接嗎_芒果糯米飯是生產力的關鍵嗎?

hdoj4283 You Are the One

laravel-admin 開發 bootstrap-treeview 擴展包


怎么看服務器上jdk安裝位置,查看云服務器jdk安裝路徑

公司生日會生日禮物_你的生日有多受歡迎?


XebiaLabs DevOps平臺推出軟件發布風險和合規性管理功能

