對數據倉庫進行數據建模
Some data sets are just not meant to have the geospatial representation that can be clustered. There is great variance in your features, and theoretically great features as well. But, it doesn’t mean is statistically separable.
某些數據集并不意味著具有可以聚類的地理空間表示。 您的功能差異很大,理論上也很棒。 但是,這并不意味著在統計上是可分離的。
那么,我什么時候停止? (So, WHEN DO I STOP?)
Always Visualize your data based on the class label you are trying to predict
始終根據您要預測的類標簽可視化數據
columns_pairplot = x_train.select_dtypes(include=['int', 'float']).join(y_train)
sns.pairplot(columns_pairplot, hue = 'readmitted')
plt.show()The distribution of different classes is almost exact. Of course, it is an imbalanced dataset. But, notice how the spread of the classes overlaps as well?
不同類別的分布幾乎是準確的。 當然,它是一個不平衡的數據集。 但是,注意這些類的傳播也是如何重疊的嗎?
2. Apply the t-SNE visualization
2.應用t-SNE可視化
t-SNE is “t-distributed stochastic neighbor embedding”. It maps higher dimensional data to 2-D space. This approximately preserves the nearness of the samples.
t-SNE是“ t分布隨機鄰居嵌入”。 它將高維數據映射到二維空間。 這大致保持了樣品的接近性。
You might need to apply different learning rates to find the best one for your dataset. Usually, try values between 50 and 200.
您可能需要應用不同的學習率才能為數據集找到最佳學習率 。 通常,請嘗試輸入介于50和200之間的值。
Hyper-parameter, perplexity balances the importance t-SNE gives to local and global variability of the data. It is a guess on the number of close neighbors each point has. Use values between 5–50. Higher, if there are more data points. Perplexity value should not be more than the number of data points.
超參數, 困惑度平衡了t-SNE對數據局部和全局可變性的重要性。 這是對每個點的近鄰數量的猜測。 使用5-50之間的值。 如果有更多數據點,則更高 。 困惑度值不應大于數據點的數量。
NOTE: Axis to t-SNE plot are not interpretable. They will be different every time t-SNE is applied
注意:軸到t-SNE圖是無法解釋的。 每次應用t-SNE時它們都會不同
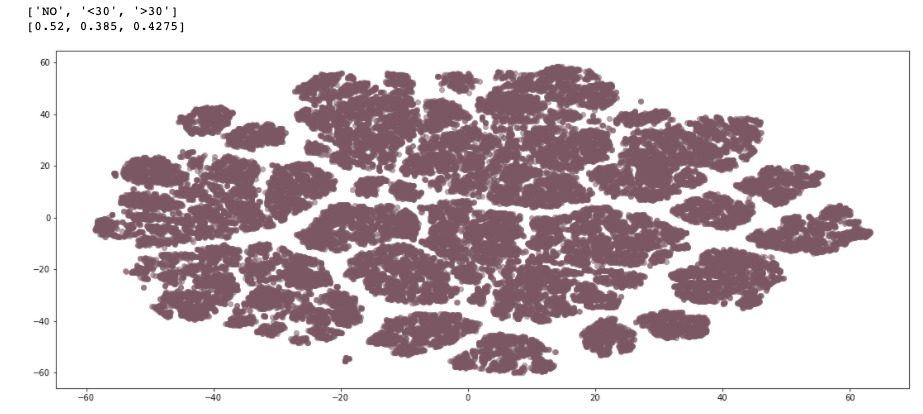
Hmm, let’s look a bit more- tweak some hyperparameters.
嗯,讓我們再看一下-調整一些超參數。
# reduce dimensionality with t-sne
tsne = TSNE(n_components=2, verbose=1, perplexity=50, n_iter=1000, learning_rate=50)
tsne_results = tsne.fit_transform(x_train)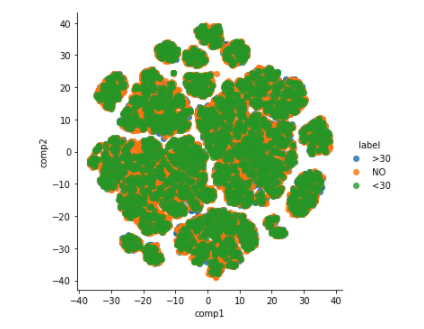
Do you see how the clusters can not be separated! I should have stopped here! But, I could not get myself out of the rabid hole. [YES WE ALL GO DOWN THAT SOMETIMES].
您是否看到群集無法分離! 我應該在這里停下來! 但是,我無法擺脫困境。 [是的,我們有時會倒下]。
3. Multi-Class Classification
3.多類別分類
We already know from above that the decision boundaries are non-linear. So, we can use an SVC (Support Vector Classifier with RBF Kernel)
從上面我們已經知道決策邊界是非線性的。 因此,我們可以使用SVC (帶有RBF內核的支持向量分類器)
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCVsvc_model = SVC() ## default kernel - RBF
parameters = {'C':[0.1, 1, 10], 'gamma':[0.00001, 0.0001, 0.001, 0.01, 0.1]}
searcher = GridSearchCV(svc_model, param_grid = parameters, n_jobs= 4, verbose = 2, return_train_score= True)
searcher.fit(x_train, y_train)
# Report the best parameters and the corresponding scoreTrain Score: 0.59Test Score: 0.53F1 Score: 0.23Precision Score: 0.24
火車得分:0.59測試得分:0.53F1得分:0.23精度得分:0.24
So, I should have stopped earlier…It is always good to have an understanding of your data before you try to over-tune and complicate the model in the hopes of better results. Good Luck!
因此,我應該早點停下來……在您嘗試過度調整模型并使模型復雜化以期獲得更好的結果之前,最好先了解您的數據。 祝好運!
翻譯自: https://towardsdatascience.com/determine-if-your-data-can-be-modeled-e619d65c13c5
對數據倉庫進行數據建模
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388332.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388332.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388332.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
)
15 并發編程-(IO模型)
中將API鏈接消息解析為服務器(示例代碼))
arduino消息服務器,在C(Arduino IDE)中將API鏈接消息解析為服務器(示例代碼)

不提拔你,就是因為你只想把工作做好

python內置函數多少個_每個數據科學家都應該知道的10個Python內置函數

C#使用TCP/IP與ModBus進行通訊

Hadoop HDFS常用命令

SAP UI 搜索分頁技術

萬彩錄屏服務器不穩定,萬彩錄屏 云服務器

針對數據科學家和數據工程師的4條SQL技巧
)
C# 讀取CAD文件縮略圖(DWG文件)

)
14.并發容器之ConcurrentHashMap(JDK 1.8版本)

modbus注意幾點

服務器虛擬化網口,服務器安裝虛擬網口

芒果云接嗎_芒果糯米飯是生產力的關鍵嗎?

hdoj4283 You Are the One

laravel-admin 開發 bootstrap-treeview 擴展包


怎么看服務器上jdk安裝位置,查看云服務器jdk安裝路徑
