引言
? ? 最近在面試中(點擊查看:我的個人簡歷,求職意向,擇司標準),除了基礎 &? 算法 & 項目之外,經常被問到或被要求介紹和描述下自己所知道的幾種分類或聚類算法(當然,這完全不代表你將來的面試中會遇到此類問題,只是因為我的簡歷上寫了句:熟悉常見的聚類 & 分類算法而已),而我向來恨對一個東西只知其皮毛而不得深入,故寫一個有關聚類 & 分類算法的系列文章以作為自己備試之用,甚至以備將來常常回顧思考。行文雜亂,但僥幸若能對讀者起到一點幫助,則幸甚至哉。
? ? 本分類 & 聚類算法系列借鑒和參考了兩本書,一本是Tom M.Mitchhell所著的機器學習,一本是數據挖掘導論,這兩本書皆分別是機器學習 & 數據挖掘領域的開山or?杠鼎之作,讀者有繼續深入下去的興趣的話,不妨在閱讀本文之后,課后細細研讀這兩本書。除此之外,還參考了網上不少牛人的作品(文末已注明參考文獻或鏈接),在此,皆一一表示感謝(從本質上來講,本文更像是一篇讀書 & 備忘筆記)。
? ? 本分類 & 聚類算法系列暫稱之為Top 10 Algorithms in Data Mining,其中,各篇分別有以下具體內容:
- 開篇:決策樹學習Decision Tree,與貝葉斯分類算法(含期望EM,與隱馬可夫模型HMM);
- 第二篇:支持向量機通俗導論(理解SVM的三層境界)。
- 第三篇:待定...
? ? OK,全系列任何一篇文章若有任何錯誤,漏洞,或不妥之處,還請讀者們一定要隨時不吝賜教 & 指正,謝謝各位。
分類與聚類,監督學習與無監督學習
? ? 在講具體的分類和聚類算法之前,有必要講一下什么是分類,什么是聚類,以及都包含哪些具體算法或問題。
? 常見的分類與聚類算法
? ? 簡單來說,自然語言處理NLP中,我們經常提到的文本分類便就是一個分類問題,一般的模式分類方法都可用于文本分類研究。常用的分類算法包括:決策樹分類法,樸素的貝葉斯分類算法(native Bayesian classifier)、基于支持向量機(SVM)的分類器,神經網絡法,k-最近鄰法(k-nearest neighbor,kNN),模糊分類法等等(所有這些分類算法日后在本blog內都會一一陸續闡述)。
? ? 分類作為一種監督學習方法,要求必須事先明確知道各個類別的信息,并且斷言所有待分類項都有一個類別與之對應。但是很多時候上述條件得不到滿足,尤其是在處理海量數據的時候,如果通過預處理使得數據滿足分類算法的要求,則代價非常大,這時候可以考慮使用聚類算法。
? ? 而K均值(K-means clustering)聚類則是最典型的聚類算法(當然,除此之外,還有很多諸如屬于劃分法K-MEDOIDS算法、CLARANS算法;屬于層次法的BIRCH算法、CURE算法、CHAMELEON算法等;基于密度的方法:DBSCAN算法、OPTICS算法、DENCLUE算法等;基于網格的方法:STING算法、CLIQUE算法、WAVE-CLUSTER算法;基于模型的方法,本系列后續會介紹其中幾種)。
? 監督學習與無監督學習
? ? 機器學習發展到現在,一般劃分為 監督學習(supervised learning),半監督學習(semi-supervised learning)以及無監督學習(unsupervised learning)三類。舉個具體的對應例子,則是比如說,在NLP詞義消岐中,也分為監督的消岐方法,和無監督的消岐方法。在有監督的消岐方法中,訓練數據是已知的,即每個詞的語義分類是被標注了的;而在無監督的消岐方法中,訓練數據是未經標注的。
? ? 上面所介紹的常見的分類算法屬于監督學習,聚類則屬于無監督學習(反過來說,監督學習屬于分類算法則不準確,因為監督學習只是說我們給樣本sample同時打上了標簽(label),然后同時利用樣本和標簽進行相應的學習任務,而不是僅僅局限于分類任務。常見的其他監督問題,比如相似性學習,特征學習等等也是監督的,但是不是分類)。
? ? SO,說的再具體點,則是:
- 監督學習的任務是學習帶標簽的訓練數據的功能,以便預測任何有效輸入的值。監督學習的常見例子包括將電子郵件消息分類為垃圾郵件,根據類別標記網頁,以及識別手寫輸入。創建監督學習程序需要使用許多算法,最常見的包括神經網絡、Support Vector Machines (SVMs) 和 Naive Bayes 分類程序,當然,還有決策樹分類,及k-最近鄰算法。
- 無監督學習的任務是發揮數據的意義,而不管數據的正確與否。它最常應用于將類似的輸入集成到邏輯分組中。它還可以用于減少數據集中的維度數據,以便只專注于最有用的屬性,或者用于探明趨勢。無監督學習的常見方法包括K-Means,分層集群和自組織地圖。
? ? 再舉個例子,正如人們通過已知病例學習診斷技術那樣,計算機要通過學習才能具有識別各種事物和現象的能力。用來進行學習的材料就是與被識別對象屬于同類的有限數量樣本。監督學習中在給予計算機學習樣本的同時,還告訴計算各個樣本所屬的類別。若所給的學習樣本不帶有類別信息,就是無監督學習(淺顯點說:同樣是學習訓練,監督學習中,給的樣例比如是已經標注了如心臟病的,肝炎的;而無監督學習中,就是給你一大堆的樣例,沒有標明是何種病例的)。
? ? 而在支持向量機導論一書給監督學習下的定義是:當樣例是輸入/輸出對給出時,稱為監督學習,有關輸入/輸出函數關系的樣例稱為訓練數據。而在無監督學習中,其數據不包含輸出值,學習的任務是理解數據產生的過程。
第一部分、決策樹學習
1.1、什么是決策樹
? ? 咱們直接切入正題。所謂決策樹,顧名思義,是一種樹,一種依托于策略抉擇而建立起來的樹。
? ? 機器學習中,決策樹是一個預測模型;他代表的是對象屬性與對象值之間的一種映射關系。樹中每個節點表示某個對象,而每個分叉路徑則代表的某個可能的屬性值,而每個葉結點則對應從根節點到該葉節點所經歷的路徑所表示的對象的值。決策樹僅有單一輸出,若欲有復數輸出,可以建立獨立的決策樹以處理不同輸出。
? ? 從數據產生決策樹的機器學習技術叫做決策樹學習, 通俗點說就是決策樹,說白了,這是一種依托于分類、訓練上的預測樹,根據已知預測、歸類未來。
? ? 來理論的太過抽象,下面舉兩個淺顯易懂的例子:
第一個例子
? ? 套用俗語,決策樹分類的思想類似于找對象。現想象一個女孩的母親要給這個女孩介紹男朋友,于是有了下面的對話:
? ? ? 女兒:多大年紀了?
? ? ? 母親:26。
? ? ? 女兒:長的帥不帥?
? ? ? 母親:挺帥的。
? ? ? 女兒:收入高不?
? ? ? 母親:不算很高,中等情況。
? ? ? 女兒:是公務員不?
? ? ? 母親:是,在稅務局上班呢。
? ? ? 女兒:那好,我去見見。
? ? ? 這個女孩的決策過程就是典型的分類樹決策。相當于通過年齡、長相、收入和是否公務員對將男人分為兩個類別:見和不見。假設這個女孩對男人的要求是:30歲以下、長相中等以上并且是高收入者或中等以上收入的公務員,那么這個可以用下圖表示女孩的決策邏輯:
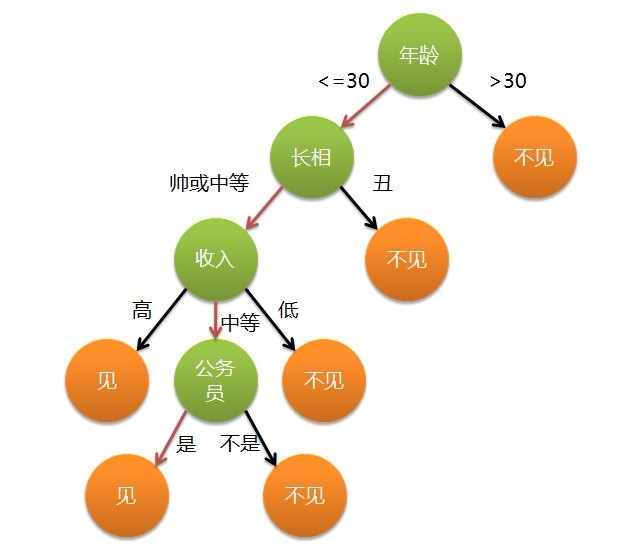
? ? 也就是說,決策樹的簡單策略就是,好比公司招聘面試過程中篩選一個人的簡歷,如果你的條件相當好比如說某985/211重點大學博士畢業,那么二話不說,直接叫過來面試,如果非重點大學畢業,但實際項目經驗豐富,那么也要考慮叫過來面試一下,即所謂具體情況具體分析、決策。但每一個未知的選項都是可以歸類到已有的分類類別中的。
第二個例子
? ? 此例子來自Tom M.Mitchell著的機器學習一書:
? ? 小王的目的是通過下周天氣預報尋找什么時候人們會打高爾夫,他了解到人們決定是否打球的原因最主要取決于天氣情況。而天氣狀況有晴,云和雨;氣溫用華氏溫度表示;相對濕度用百分比;還有有無風。如此,我們便可以構造一棵決策樹,如下(根據天氣這個分類決策這天是否合適打網球):
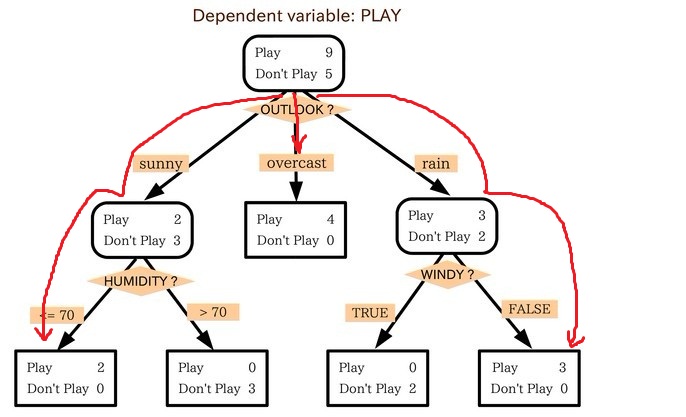
? ? 上述決策樹對應于以下表達式:
(Outlook=Sunny ^Humidity<=70)V (Outlook = Overcast)V (Outlook=Rain ^ Wind=Weak)
1.2、ID3算法
1.2.1、決策樹學習之ID3算法
? ? ID3算法是決策樹算法的一種。想了解什么是ID3算法之前,我們得先明白一個概念:奧卡姆剃刀。
- 奧卡姆剃刀(Occam's Razor, Ockham's Razor),又稱“奧坎的剃刀”,是由14世紀邏輯學家、圣方濟各會修士奧卡姆的威廉(William of Occam,約1285年至1349年)提出,他在《箴言書注》2卷15題說“切勿浪費較多東西,去做‘用較少的東西,同樣可以做好的事情’。簡單點說,便是:be simple。
? ? OK,從信息論知識中我們知道,期望信息越小,信息增益越大,從而純度越高。ID3算法的核心思想就是以信息增益度量屬性選擇,選擇分裂后信息增益(很快,由下文你就會知道信息增益又是怎么一回事)最大的屬性進行分裂。該算法采用自頂向下的貪婪搜索遍歷可能的決策樹空間。
? ? ?所以,ID3的思想便是:
- 自頂向下的貪婪搜索遍歷可能的決策樹空間構造決策樹(此方法是ID3算法和C4.5算法的基礎);
- 從“哪一個屬性將在樹的根節點被測試”開始;
- 使用統計測試來確定每一個實例屬性單獨分類訓練樣例的能力,分類能力最好的屬性作為樹的根結點測試(如何定義或者評判一個屬性是分類能力最好的呢?這便是下文將要介紹的信息增益,or 信息增益率)。
- 然后為根結點屬性的每個可能值產生一個分支,并把訓練樣例排列到適當的分支(也就是說,樣例的該屬性值對應的分支)之下。
- 重復這個過程,用每個分支結點關聯的訓練樣例來選取在該點被測試的最佳屬性。
這形成了對合格決策樹的貪婪搜索,也就是算法從不回溯重新考慮以前的選擇。
? ? 下圖所示即是用于學習布爾函數的ID3算法概要:

1.2.2、哪個屬性是最佳的分類屬性
? ? 為了精確地定義信息增益,我們先定義信息論中廣泛使用的一個度量標準,稱為熵(entropy),它刻畫了任意樣例集的純度(purity)。給定包含關于某個目標概念的正反樣例的樣例集S,那么S相對這個布爾型分類的熵為:
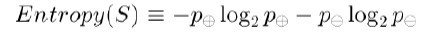
? ? 上述公式中,p+代表正樣例,比如在本文開頭第二個例子中p+則意味著去打羽毛球,而p-則代表反樣例,不去打球(在有關熵的所有計算中我們定義0log0為0)。
? ? 如果寫代碼實現熵的計算,則如下所示:
? ? 舉例來說,假設S是一個關于布爾概念的有14個樣例的集合,它包括9個正例和5個反例(我們采用記號[9+,5-]來概括這樣的數據樣例),那么S相對于這個布爾樣例的熵為:
Entropy([9+,5-])=-(9/14)log2(9/14)-(5/14)log2(5/14)=0.940。
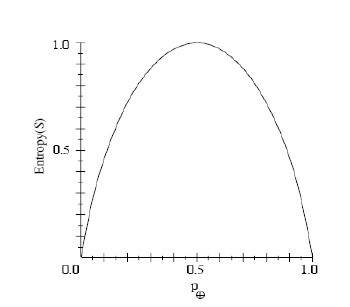
? ???Pi為子集合中不同性(而二元分類即正樣例和負樣例)的樣例的比例。
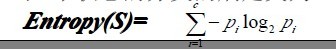
2、信息增益度量期望的熵降低
信息增益Gain(S,A)定義
? ? 已經有了熵作為衡量訓練樣例集合純度的標準,現在可以定義屬性分類訓練數據的效力的度量標準。這個標準被稱為“信息增益(information?gain)”。簡單的說,一個屬性的信息增益就是由于使用這個屬性分割樣例而導致的期望熵降低(或者說,樣本按照某屬性劃分時造成熵減少的期望)。更精確地講,一個屬性A相對樣例集合S的信息增益Gain(S,A)被定義為:

? ? 其中?Values(A)是屬性A所有可能值的集合,是S中屬性A的值為v的子集。換句話來講,Gain(S,A)是由于給定屬性A的值而得到的關于目標函數值的信息。當對S的一個任意成員的目標值編碼時,Gain(S,A)的值是在知道屬性A的值后可以節省的二進制位數。
? ? 接下來,有必要提醒讀者一下:關于下面這兩個概念?or?公式,
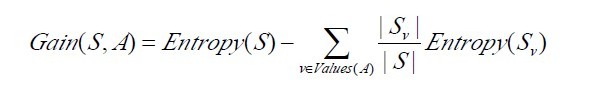
? ? 下面,舉個例子,假定S是一套有關天氣的訓練樣例,描述它的屬性包括可能是具有Weak和Strong兩個值的Wind。像前面一樣,假定S包含14個樣例,[9+,5-]。在這14個樣例中,假定正例中的6個和反例中的2個有Wind?=Weak,其他的有Wind=Strong。由于按照屬性Wind分類14個樣例得到的信息增益可以計算如下。

? ? 運用在本文開頭舉得第二個根據天氣情況是否決定打羽毛球的例子上,得到的最佳分類屬性如下圖所示:
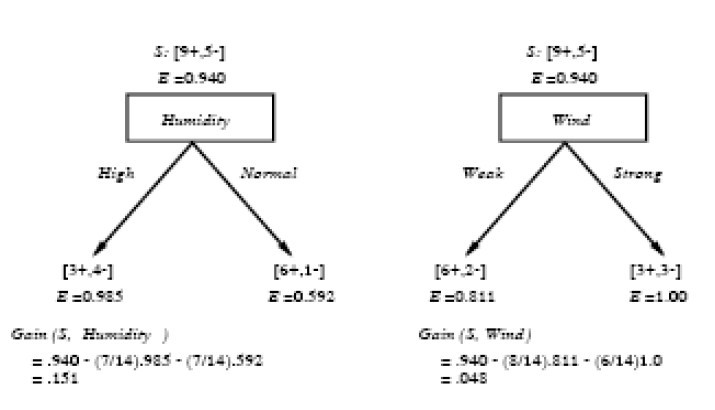
? ???在上圖中,計算了兩個不同屬性:濕度(humidity)和風力(wind)的信息增益,最終humidity這種分類的信息增益0.151>wind增益的0.048。說白了,就是在星期六上午是否適合打網球的問題訣策中,采取humidity較wind作為分類屬性更佳,決策樹由此而來。
1.2.3、ID3算法決策樹的形成
? ? OK,下圖為ID3算法第一步后形成的部分決策樹。這樣綜合起來看,就容易理解多了。1、overcast樣例必為正,所以為葉子結點,總為yes;2、ID3無回溯,局部最優,而非全局最優,還有另一種樹后修剪決策樹。下圖是ID3算法第一步后形成的部分決策樹:
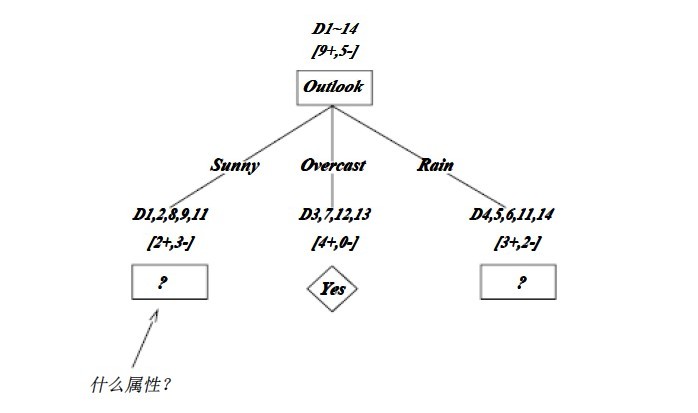
? ? 如上圖,訓練樣例被排列到對應的分支結點。分支Overcast的所有樣例都是正例,所以成為目標分類為Yes的葉結點。另兩個結點將被進一步展開,方法是按照新的樣例子集選取信息增益最高的屬性。
1.3、C4.5算法
? ? C4.5,是機器學習算法中的另一個分類決策樹算法,它是決策樹(決策樹也就是做決策的節點間的組織方式像一棵樹,其實是一個倒樹)核心算法,也是上文1.2節所介紹的ID3的改進算法,所以基本上了解了一半決策樹構造方法就能構造它。
? ? 決策樹構造方法其實就是每次選擇一個好的特征以及分裂點作為當前節點的分類條件。
? ? 既然說C4.5算法是ID3的改進算法,那么C4.5相比于ID3改進的地方有哪些呢?:
- 用信息增益率來選擇屬性。ID3選擇屬性用的是子樹的信息增益,這里可以用很多方法來定義信息,ID3使用的是熵(entropy,熵是一種不純度度量準則),也就是熵的變化值,而C4.5用的是信息增益率。對,區別就在于一個是信息增益,一個是信息增益率。
- 在樹構造過程中進行剪枝,在構造決策樹的時候,那些掛著幾個元素的節點,不考慮最好,不然容易導致overfitting。
- 對非離散數據也能處理。
- 能夠對不完整數據進行處理
? ? 針對上述第一點,解釋下:一般來說率就是用來取平衡用的,就像方差起的作用差不多,比如有兩個跑步的人,一個起點是10m/s的人、其10s后為20m/s;另一個人起速是1m/s、其1s后為2m/s。如果緊緊算差值那么兩個差距就很大了,如果使用速度增加率(加速度,即都是為1m/s^2)來衡量,2個人就是一樣的加速度。因此,C4.5克服了ID3用信息增益選擇屬性時偏向選擇取值多的屬性的不足。
C4.5算法之信息增益率
? ? OK,既然上文中提到C4.5用的是信息增益率,那增益率的具體是如何定義的呢?:
? ? 是的,在這里,C4.5算法不再是通過信息增益來選擇決策屬性。一個可以選擇的度量標準是增益比率gain?ratio(Quinlan?1986)。增益比率度量是用前面的增益度量Gain(S,A)和分裂信息度量SplitInformation(S,A)來共同定義的,如下所示:
? ? 其中,分裂信息度量被定義為( 分裂信息用來衡量屬性分裂數據的廣度和均勻):

???

? ? 其中S1到Sc是c個值的屬性A分割S而形成的c個樣例子集。注意分裂信息實際上就是S關于屬性A的各值的熵。這與我們前面對熵的使用不同,在那里我們只考慮S關于學習到的樹要預測的目標屬性的值的熵。
? ??請注意,分裂信息項阻礙選擇值為均勻分布的屬性。例如,考慮一個含有n個樣例的集合被屬性A徹底分割(譯注:分成n組,即一個樣例一組)。這時分裂信息的值為log2n。相反,一個布爾屬性B分割同樣的n個實例,如果恰好平分兩半,那么分裂信息是1。如果屬性A和B產生同樣的信息增益,那么根據增益比率度量,明顯B會得分更高。
? ??使用增益比率代替增益來選擇屬性產生的一個實際問題是,當某個Si接近S(|Si|?|S|)時分母可能為0或非常小。如果某個屬性對于S的所有樣例有幾乎同樣的值,這時要么導致增益比率未定義,要么是增益比率非常大。為了避免選擇這種屬性,我們可以采用這樣一些啟發式規則,比如先計算每個屬性的增益,然后僅對那些增益高過平均值的屬性應用增益比率測試(Quinlan?1986)。
? ? 除了信息增益,Lopez?de?Mantaras(1991)介紹了另一種直接針對上述問題而設計的度量,它是基于距離的(distance-based)。這個度量標準基于所定義的一個數據劃分間的距離尺度。具體更多請參看:Tom M.Mitchhell所著的機器學習之3.7.3節。
1.3.2、C4.5算法構造決策樹的過程
1.3.3、C4.5算法實現中的幾個關鍵步驟
? ? 在上文中,我們已經知道了決策樹學習C4.5算法中4個重要概念的表達,如下:
1.4、讀者點評
- form?Wind:決策樹使用于特征取值離散的情況,連續的特征一般也要處理成離散的(而很多文章沒有表達出決策樹的關鍵特征or概念)。實際應用中,決策樹overfitting比較的嚴重,一般要做boosting。分類器的性能上不去,很主要的原因在于特征的鑒別性不足,而不是分類器的好壞,好的特征才有好的分類效果,分類器只是弱相關。
- ?那如何提高?特征的鑒別性呢?一是設計特征時盡量引入domain?knowledge,二是對提取出來的特征做選擇、變換和再學習,這一點是機器學習算法不管的部分(我說的這些不是針對決策樹的,因此不能說是決策樹的特點,只是一些機器學習算法在應用過程中的經驗體會)。
第二部分、貝葉斯分類
昔人已乘黃鶴去,此地空余黃鶴樓;黃鶴一去不復返,白云千載空悠悠。
? ? 后便大為折服,已無什興致再提了(偶現在就是這感覺),然文章還得繼續寫。So,本文第二部分之大部分基本整理自未鵬兄之手(做了部分改動),若有任何不妥之處,還望讀者和未鵬兄海涵,謝謝。
2.1、什么是貝葉斯分類
? ?貝葉斯定理:已知某條件概率,如何得到兩個事件交換后的概率,也就是在已知P(A|B)的情況下如何求得P(B|A)。這里先解釋什么是條件概率:
??????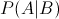 表示事件B已經發生的前提下,事件A發生的概率,叫做事件B發生下事件A的條件概率。其基本求解公式為:
表示事件B已經發生的前提下,事件A發生的概率,叫做事件B發生下事件A的條件概率。其基本求解公式為: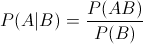 。
。
????? 貝葉斯定理之所以有用,是因為我們在生活中經常遇到這種情況:我們可以很容易直接得出P(A|B),P(B|A)則很難直接得出,但我們更關心P(B|A),貝葉斯定理就為我們打通從P(A|B)獲得P(B|A)的道路。
? ? 進一步,我們如果用P(h)來代表在沒有訓練數據前假設h擁有的初始概率,P(h)常被稱為h的先驗概率,類似,P(D)代表將要觀察的訓練數據D的先驗概率(換言之,在沒有確定某一假設成立時D的概率),下一步,以P(D|h)代表在假設h成立的情況下觀察到數據D的概率。
? ? 一般情況下,我們使用P(x|y)代表給定y時x的概率,機器學習中,我們感興趣的是P(h|D),即給定訓練數據D時h成立的概率,P(h|D)被稱為h的后驗概率,因為它反映了在看到訓練數據D后h成立的置信度。注意,后驗概率P(h|D)反映了訓練數據D的影響;相反,先驗概率P(h)是獨立于D的。
? ? 貝葉斯法則是貝葉斯方法的基礎,因為它提供了從先驗概率P(h)以及P(D)和P(D|h)計算后驗概率P(h|D)的方法。下面,直接給出貝葉斯公式:
? ? ? ? ? ? ? ? ? ??P(D|h) P(h)
? ??P(h|D)= ?? ?? ? P(D)
2.2?貝葉斯公式如何而來
? ? 貝葉斯公式是怎么來的?下面是wikipedia 上的一個例子:
一所學校里面有 60% 的男生,40% 的女生。男生總是穿長褲,女生則一半穿長褲一半穿裙子。有了這些信息之后我們可以容易地計算“隨機選取一個學生,他(她)穿長褲的概率和穿裙子的概率是多大”,這個就是前面說的“正向概率”的計算。然而,假設你走在校園中,迎面走來一個穿長褲的學生(很不幸的是你高度近似,你只看得見他(她)穿的是否長褲,而無法確定他(她)的性別),你能夠推斷出他(她)是男生的概率是多大嗎?
? ? 一些認知科學的研究表明(《決策與判斷》以及《Rationality for Mortals》第12章:小孩也可以解決貝葉斯問題),我們對形式化的貝葉斯問題不擅長,但對于以頻率形式呈現的等價問題卻很擅長。在這里,我們不妨把問題重新敘述成:你在校園里面隨機游走,遇到了 N 個穿長褲的人(仍然假設你無法直接觀察到他們的性別),問這 N 個人里面有多少個女生多少個男生。
? ? 你說,這還不簡單:算出學校里面有多少穿長褲的,然后在這些人里面再算出有多少女生,不就行了?
? ? 我們來算一算:假設學校里面人的總數是 U 個。60% 的男生都穿長褲,于是我們得到了 U * P(Boy) * P(Pants|Boy) 個穿長褲的(男生)(其中 P(Boy) 是男生的概率 = 60%,這里可以簡單的理解為男生的比例;P(Pants|Boy) 是條件概率,即在 Boy 這個條件下穿長褲的概率是多大,這里是 100% ,因為所有男生都穿長褲)。40% 的女生里面又有一半(50%)是穿長褲的,于是我們又得到了 U * P(Girl) * P(Pants|Girl) 個穿長褲的(女生)。加起來一共是 U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl) 個穿長褲的,其中有 U * P(Girl) * P(Pants|Girl) 個女生。兩者一比就是你要求的答案。
? ? 下面我們把這個答案形式化一下:我們要求的是 P(Girl|Pants) (穿長褲的人里面有多少女生),我們計算的結果是 U * P(Girl) * P(Pants|Girl) / [U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl)] 。容易發現這里校園內人的總數是無關的,兩邊同時消去U,于是得到
P(Girl|Pants) = P(Girl) * P(Pants|Girl) / [P(Boy) * P(Pants|Boy) + P(Girl) * P(Pants|Girl)]
? ? 注意,如果把上式收縮起來,分母其實就是 P(Pants) ,分子其實就是 P(Pants, Girl) 。而這個比例很自然地就讀作:在穿長褲的人( P(Pants) )里面有多少(穿長褲)的女孩( P(Pants, Girl) )。
? ? 上式中的 Pants 和 Boy/Girl 可以指代一切東西,So,其一般形式就是:
P(B|A) = P(A|B) * P(B) / [P(A|B) * P(B) + P(A|~B) * P(~B) ]
? ? 收縮起來就是:
P(B|A) = P(AB) / P(A)
? ? 其實這個就等于:
P(B|A) * P(A) = P(AB)
? ? 更進一步闡述,P(B|A)便是在條件A的情況下,B出現的概率是多大。然看似這么平凡的貝葉斯公式,背后卻隱含著非常深刻的原理。
2.3、拼寫糾正
??? 經典著作《人工智能:現代方法》的作者之一 Peter Norvig 曾經寫過一篇介紹如何寫一個拼寫檢查/糾正器的文章,里面用到的就是貝葉斯方法,下面,將其核心思想簡單描述下。
??? 首先,我們需要詢問的是:“問題是什么?”
??? 問題是我們看到用戶輸入了一個不在字典中的單詞,我們需要去猜測:“這個家伙到底真正想輸入的單詞是什么呢?”用剛才我們形式化的語言來敘述就是,我們需要求:
P(我們猜測他想輸入的單詞 | 他實際輸入的單詞)
??? 這個概率。并找出那個使得這個概率最大的猜測單詞。顯然,我們的猜測未必是唯一的,就像前面舉的那個自然語言的歧義性的例子一樣;這里,比如用戶輸入: thew ,那么他到底是想輸入 the ,還是想輸入 thaw ?到底哪個猜測可能性更大呢?幸運的是我們可以用貝葉斯公式來直接出它們各自的概率,我們不妨將我們的多個猜測記為 h1 h2 .. ( h 代表 hypothesis),它們都屬于一個有限且離散的猜測空間 H (單詞總共就那么多而已),將用戶實際輸入的單詞記為 D ( D 代表 Data ,即觀測數據),于是
P(我們的猜測1 | 他實際輸入的單詞)
??? 可以抽象地記為:
P(h1 | D)
??? 類似地,對于我們的猜測2,則是 P(h2 | D)。不妨統一記為:
P(h | D)
運用一次貝葉斯公式,我們得到:
P(h | D) = P(h) * P(D | h) / P(D)
??? 對于不同的具體猜測 h1 h2 h3 .. ,P(D) 都是一樣的,所以在比較 P(h1 | D) 和 P(h2 | D) 的時候我們可以忽略這個常數。即我們只需要知道:
P(h | D) ∝ P(h) * P(D | h) (注:那個符號的意思是“正比例于”,不是無窮大,注意符號右端是有一個小缺口的。)
??? 這個式子的抽象含義是:對于給定觀測數據,一個猜測是好是壞,取決于“這個猜測本身獨立的可能性大小(先驗概率,Prior )”和“這個猜測生成我們觀測到的數據的可能性大小”(似然,Likelihood )的乘積。具體到我們的那個 thew 例子上,含義就是,用戶實際是想輸入 the 的可能性大小取決于 the 本身在詞匯表中被使用的可能性(頻繁程度)大小(先驗概率)和 想打 the 卻打成 thew 的可能性大小(似然)的乘積。
??? 剩下的事情就很簡單了,對于我們猜測為可能的每個單詞計算一下 P(h) * P(D | h) 這個值,然后取最大的,得到的就是最靠譜的猜測。更多細節請參看未鵬兄之原文。
2.4、貝葉斯的應用
2.4.1、中文分詞
? ? 貝葉斯是機器學習的核心方法之一。比如中文分詞領域就用到了貝葉斯。浪潮之巔的作者吳軍在《數學之美》系列中就有一篇是介紹中文分詞的。這里介紹一下核心的思想,不做贅述,詳細請參考吳軍的原文。
? ? 分詞問題的描述為:給定一個句子(字串),如:
??? 南京市長江大橋
? ? 如何對這個句子進行分詞(詞串)才是最靠譜的。例如:
1. 南京市/長江大橋
2. 南京/市長/江大橋
? ? 這兩個分詞,到底哪個更靠譜呢?
? ? 我們用貝葉斯公式來形式化地描述這個問題,令 X 為字串(句子),Y 為詞串(一種特定的分詞假設)。我們就是需要尋找使得 P(Y|X) 最大的 Y ,使用一次貝葉斯可得:
P(Y|X) ∝ P(Y)*P(X|Y)
? ? ?用自然語言來說就是 這種分詞方式(詞串)的可能性 乘以 這個詞串生成我們的句子的可能性。我們進一步容易看到:可以近似地將 P(X|Y) 看作是恒等于 1 的,因為任意假想的一種分詞方式之下生成我們的句子總是精準地生成的(只需把分詞之間的分界符號扔掉即可)。于是,我們就變成了去最大化 P(Y) ,也就是尋找一種分詞使得這個詞串(句子)的概率最大化。而如何計算一個詞串:
W1, W2, W3, W4 ..
? ? 的可能性呢?我們知道,根據聯合概率的公式展開:P(W1, W2, W3, W4 ..) = P(W1) * P(W2|W1) * P(W3|W2, W1) * P(W4|W1,W2,W3) * .. 于是我們可以通過一系列的條件概率(右式)的乘積來求整個聯合概率。然而不幸的是隨著條件數目的增加(P(Wn|Wn-1,Wn-2,..,W1) 的條件有 n-1 個),數據稀疏問題也會越來越嚴重,即便語料庫再大也無法統計出一個靠譜的 P(Wn|Wn-1,Wn-2,..,W1) 來。為了緩解這個問題,計算機科學家們一如既往地使用了“天真”假設:我們假設句子中一個詞的出現概率只依賴于它前面的有限的 k 個詞(k 一般不超過 3,如果只依賴于前面的一個詞,就是2元語言模型(2-gram),同理有 3-gram 、 4-gram 等),這個就是所謂的“有限地平線”假設。
? ? ?雖然上面這個假設很傻很天真,但結果卻表明它的結果往往是很好很強大的,后面要提到的樸素貝葉斯方法使用的假設跟這個精神上是完全一致的,我們會解釋為什么像這樣一個天真的假設能夠得到強大的結果。目前我們只要知道,有了這個假設,剛才那個乘積就可以改寫成: P(W1) * P(W2|W1) * P(W3|W2) * P(W4|W3) .. (假設每個詞只依賴于它前面的一個詞)。而統計 P(W2|W1) 就不再受到數據稀疏問題的困擾了。對于我們上面提到的例子“南京市長江大橋”,如果按照自左到右的貪婪方法分詞的話,結果就成了“南京市長/江大橋”。但如果按照貝葉斯分詞的話(假設使用 3-gram),由于“南京市長”和“江大橋”在語料庫中一起出現的頻率為 0 ,這個整句的概率便會被判定為 0 。 從而使得“南京市/長江大橋”這一分詞方式勝出。
2.4.2、貝葉斯圖像識別,Analysis by Synthesis
? ? 貝葉斯方法是一個非常 general 的推理框架。其核心理念可以描述成:Analysis by Synthesis (通過合成來分析)。06 年的認知科學新進展上有一篇 paper 就是講用貝葉斯推理來解釋視覺識別的,一圖勝千言,下圖就是摘自這篇 paper :

? ? 首先是視覺系統提取圖形的邊角特征,然后使用這些特征自底向上地激活高層的抽象概念(比如是 E 還是 F 還是等號),然后使用一個自頂向下的驗證來比較到底哪個概念最佳地解釋了觀察到的圖像。
2.4.3、最大似然與最小二乘

? ? 學過線性代數的大概都知道經典的最小二乘方法來做線性回歸。問題描述是:給定平面上 N 個點,(這里不妨假設我們想用一條直線來擬合這些點——回歸可以看作是擬合的特例,即允許誤差的擬合),找出一條最佳描述了這些點的直線。
? ? 一個接踵而來的問題就是,我們如何定義最佳?我們設每個點的坐標為 (Xi, Yi) 。如果直線為 y = f(x) 。那么 (Xi, Yi) 跟直線對這個點的“預測”:(Xi, f(Xi)) 就相差了一個 ΔYi = |Yi – f(Xi)| 。最小二乘就是說尋找直線使得 (ΔY1)^2 + (ΔY2)^2 + .. (即誤差的平方和)最小,至于為什么是誤差的平方和而不是誤差的絕對值和,統計學上也沒有什么好的解釋。然而貝葉斯方法卻能對此提供一個完美的解釋。
? ? 我們假設直線對于坐標 Xi 給出的預測 f(Xi) 是最靠譜的預測,所有縱坐標偏離 f(Xi) 的那些數據點都含有噪音,是噪音使得它們偏離了完美的一條直線,一個合理的假設就是偏離路線越遠的概率越小,具體小多少,可以用一個正態分布曲線來模擬,這個分布曲線以直線對 Xi 給出的預測 f(Xi) 為中心,實際縱坐標為 Yi 的點 (Xi, Yi) 發生的概率就正比于 EXP[-(ΔYi)^2]。(EXP(..) 代表以常數 e 為底的多少次方)。
? ? 現在我們回到問題的貝葉斯方面,我們要想最大化的后驗概率是:
P(h|D) ∝ P(h) * P(D|h)
? ? 又見貝葉斯!這里 h 就是指一條特定的直線,D 就是指這 N 個數據點。我們需要尋找一條直線 h 使得 P(h) * P(D|h) 最大。很顯然,P(h) 這個先驗概率是均勻的,因為哪條直線也不比另一條更優越。所以我們只需要看 P(D|h) 這一項,這一項是指這條直線生成這些數據點的概率,剛才說過了,生成數據點 (Xi, Yi) 的概率為 EXP[-(ΔYi)^2] 乘以一個常數。而 P(D|h) = P(d1|h) * P(d2|h) * .. 即假設各個數據點是獨立生成的,所以可以把每個概率乘起來。于是生成 N 個數據點的概率為 EXP[-(ΔY1)^2] * EXP[-(ΔY2)^2] * EXP[-(ΔY3)^2] * .. = EXP{-[(ΔY1)^2 + (ΔY2)^2 + (ΔY3)^2 + ..]} 最大化這個概率就是要最小化 (ΔY1)^2 + (ΔY2)^2 + (ΔY3)^2 + .. 。 熟悉這個式子嗎?
? ? 除了以上所介紹的之外,貝葉斯還在詞義消岐,語言模型的平滑方法中都有一定應用。下節,咱們再來簡單看下樸素貝葉斯方法。
2.5、樸素貝葉斯方法
? ? 樸素貝葉斯方法是一個很特別的方法,所以值得介紹一下。在眾多的分類模型中,應用最為廣泛的兩種分類模型是決策樹模型(Decision Tree Model)和樸素貝葉斯模型(Naive Bayesian Model,NBC)。?樸素貝葉斯模型發源于古典數學理論,有著堅實的數學基礎,以及穩定的分類效率。
? ? ?同時,NBC模型所需估計的參數很少,對缺失數據不太敏感,算法也比較簡單。理論上,NBC模型與其他分類方法相比具有最小的誤差率。但是實際上并非總是如此,這是因為NBC模型假設屬性之間相互獨立,這個假設在實際應用中往往是不成立的,這給NBC模型的正確分類帶來了一定影響。在屬性個數比較多或者屬性之間相關性較大時,NBC模型的分類效率比不上決策樹模型。而在屬性相關性較小時,NBC模型的性能最為良好。
? ? 接下來,我們用樸素貝葉斯在垃圾郵件過濾中的應用來舉例說明。
2.5.1、貝葉斯垃圾郵件過濾器
? ? 問題是什么?問題是,給定一封郵件,判定它是否屬于垃圾郵件。按照先例,我們還是用 D 來表示這封郵件,注意 D 由 N 個單詞組成。我們用 h+ 來表示垃圾郵件,h- 表示正常郵件。問題可以形式化地描述為求:
P(h+|D) = P(h+) * P(D|h+) / P(D)
P(h-|D) = P(h-) * P(D|h-) / P(D)
? ? 其中 P(h+) 和 P(h-) 這兩個先驗概率都是很容易求出來的,只需要計算一個郵件庫里面垃圾郵件和正常郵件的比例就行了。然而 P(D|h+) 卻不容易求,因為 D 里面含有 N 個單詞 d1, d2, d3, .. ,所以P(D|h+) = P(d1,d2,..,dn|h+) 。我們又一次遇到了數據稀疏性,為什么這么說呢?P(d1,d2,..,dn|h+) 就是說在垃圾郵件當中出現跟我們目前這封郵件一模一樣的一封郵件的概率是多大!開玩笑,每封郵件都是不同的,世界上有無窮多封郵件。瞧,這就是數據稀疏性,因為可以肯定地說,你收集的訓練數據庫不管里面含了多少封郵件,也不可能找出一封跟目前這封一模一樣的。結果呢?我們又該如何來計算 P(d1,d2,..,dn|h+) 呢?
? ? 我們將 P(d1,d2,..,dn|h+)? 擴展為: P(d1|h+) * P(d2|d1, h+) * P(d3|d2,d1, h+) * .. 。熟悉這個式子嗎?這里我們會使用一個更激進的假設,我們假設 di 與 di-1 是完全條件無關的,于是式子就簡化為 P(d1|h+) * P(d2|h+) * P(d3|h+) * .. 。這個就是所謂的條件獨立假設,也正是樸素貝葉斯方法的樸素之處。而計算 P(d1|h+) * P(d2|h+) * P(d3|h+) * .. 就太簡單了,只要統計 di 這個單詞在垃圾郵件中出現的頻率即可。關于貝葉斯垃圾郵件過濾更多的內容可以參考這個條目,注意其中提到的其他資料。
2.6、層級貝葉斯模型

? ??層級貝葉斯模型是現代貝葉斯方法的標志性建筑之一。前面講的貝葉斯,都是在同一個事物層次上的各個因素之間進行統計推理,然而層次貝葉斯模型在哲學上更深入了一層,將這些因素背后的因素(原因的原因,原因的原因,以此類推)囊括進來。一個教科書例子是:如果你手頭有 N 枚硬幣,它們是同一個工廠鑄出來的,你把每一枚硬幣擲出一個結果,然后基于這 N 個結果對這 N 個硬幣的 θ (出現正面的比例)進行推理。如果根據最大似然,每個硬幣的 θ 不是 1 就是 0 (這個前面提到過的),然而我們又知道每個硬幣的 p(θ) 是有一個先驗概率的,也許是一個 beta 分布。也就是說,每個硬幣的實際投擲結果 Xi 服從以 θ 為中心的正態分布,而 θ 又服從另一個以 Ψ 為中心的 beta 分布。層層因果關系就體現出來了。進而 Ψ 還可能依賴于因果鏈上更上層的因素,以此類推。
第三部分、從EM算法到隱馬可夫模型(HMM)
3.1、EM?算法與基于模型的聚類
? ? ?在統計計算中,最大期望 (EM,Expectation–Maximization)算法是在概率(probabilistic)模型中尋找參數最大似然估計的算法,其中概率模型依賴于無法觀測的隱藏變量(Latent Variabl)。最大期望經常用在機器學習和計算機視覺的數據集聚(Data Clustering)領域。
? ? 通常來說,聚類是一種無指導的機器學習問題,如此問題描述:給你一堆數據點,讓你將它們最靠譜地分成一堆一堆的。聚類算法很多,不同的算法適應于不同的問題,這里僅介紹一個基于模型的聚類,該聚類算法對數據點的假設是,這些數據點分別是圍繞 K 個核心的 K 個正態分布源所隨機生成的,使用 Han JiaWei 的《Data Ming: Concepts and Techniques》中的圖:

? ? 圖中有兩個正態分布核心,生成了大致兩堆點。我們的聚類算法就是需要根據給出來的那些點,算出這兩個正態分布的核心在什么位置,以及分布的參數是多少。這很明顯又是一個貝葉斯問題,但這次不同的是,答案是連續的且有無窮多種可能性,更糟的是,只有當我們知道了哪些點屬于同一個正態分布圈的時候才能夠對這個分布的參數作出靠譜的預測,現在兩堆點混在一塊我們又不知道哪些點屬于第一個正態分布,哪些屬于第二個。反過來,只有當我們對分布的參數作出了靠譜的預測時候,才能知道到底哪些點屬于第一個分布,那些點屬于第二個分布。這就成了一個先有雞還是先有蛋的問題了。為了解決這個循環依賴,總有一方要先打破僵局,說,不管了,我先隨便整一個值出來,看你怎么變,然后我再根據你的變化調整我的變化,然后如此迭代著不斷互相推導,最終收斂到一個解。這就是 EM 算法。
? ? EM 的意思是“Expectation-Maximazation”,在這個聚類問題里面,我們是先隨便猜一下這兩個正態分布的參數:如核心在什么地方,方差是多少。然后計算出每個數據點更可能屬于第一個還是第二個正態分布圈,這個是屬于 Expectation 一步。有了每個數據點的歸屬,我們就可以根據屬于第一個分布的數據點來重新評估第一個分布的參數(從蛋再回到雞),這個是 Maximazation 。如此往復,直到參數基本不再發生變化為止。這個迭代收斂過程中的貝葉斯方法在第二步,根據數據點求分布的參數上面。
3.2、隱馬可夫模型(HMM)
? ? 大多的書籍或論文都講不清楚這個隱馬可夫模型(HMM),包括未鵬兄之原文也講得不夠具體明白。接下來,我盡量用直白易懂的語言闡述這個模型。然在介紹隱馬可夫模型之前,有必要先行介紹下單純的馬可夫模型(本節主要引用:統計自然語言處理,宗成慶編著一書上的相關內容)。
3.2.1、馬可夫模型
? ? 我們知道,隨機過程又稱隨機函數,是隨時間而隨機變化的過程。馬可夫模型便是描述了一類重要的隨機過程。我們常常需要考察一個隨機變量序列,這些隨機變量并不是相互獨立的(注意:理解這個非相互獨立,即相互之間有千絲萬縷的聯系)。
? ? 如果此時,我也搞一大推狀態方程式,恐怕我也很難逃脫越講越復雜的怪圈了。所以,直接舉例子吧,如,一段文字中名詞、動詞、形容詞三類詞性出現的情況可由三個狀態的馬爾科夫模型描述如下:
狀態s1:名詞
狀態s2:動詞
狀態s3:形容詞
假設狀態之間的轉移矩陣如下:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? s1 ? ? s2 ? ?s3
? ? ? ? ? ? ? ? ? ? ? ? s1 ? 0.3 ? ? ?0.5 ? ?0.2
? ? A = [aij] = ? ? s2 ? 0.5 ? ? ?0.3 ? ?0.2
? ? ? ? ? ? ? ? ? ? ? ? s3 ? 0.4 ? ? ?0.2 ? ? 0.4
? ? 如果在該段文字中某一個句子的第一個詞為名詞,那么根據這一模型M,在該句子中這三類詞出現順序為O="名動形名”的概率為:
? ? P(O|M)=P(s1,s2,s3,s1 | M) = P(s1) × P(s2 | s1) * P(s3 | s2)*P(s1 | s3)? ? ? ? ? ? ? ? =1* a12 * a23 * a31=0.5*0.2*0.4=0.004
? ? 馬爾可夫模型又可視為隨機的有限狀態機。馬爾柯夫鏈可以表示成狀態圖(轉移弧上有概率的非確定的有限狀態自動機),如下圖所示,

? ? 在上圖中,圓圈表示狀態,狀態之間的轉移用帶箭頭的弧表示,弧上的數字為狀態轉移的概率,初始狀態用標記為start的輸入箭頭表示,假設任何狀態都可作為終止狀態。圖中零概率的轉移弧省略,且每個節點上所有發出弧的概率之和等于1。從上圖可以看出,馬爾可夫模型可以看做是一個轉移弧上有概率的非確定的有限狀態自動機。
3.2.2、隱馬可夫模型(HMM)
? ? 在上文介紹的馬可夫模型中,每個狀態代表了一個可觀察的事件,所以,馬可夫模型有時又稱作視馬可夫模型(VMM),這在某種程度上限制了模型的適應性。而在我們的隱馬可夫模型(HMM)中,我們不知道模型所經過的狀態序列,只知道狀態的概率函數,也就是說,觀察到的事件是狀態的隨機函數,因此改模型是一個雙重的隨機過程。其中,模型的狀態轉換是不可觀察的,即隱蔽的,可觀察事件的隨機過程是隱蔽的狀態過程的隨機函數。
? ??
? ? 理論多說無益,接下來,留個思考題給讀者:N 個袋子,每個袋子中有M 種不同顏色的球。一實驗員根據某一概率分布選擇一個袋子,然后根據袋子中不同顏色球的概率分布隨機取出一個球,并報告該球的顏色。對局外人:可觀察的過程是不同顏色球的序列,而袋子的序列是不可觀察的。每只袋子對應HMM中的一個狀態;球的顏色對應于HMM 中狀態的輸出。
3.2.2、HMM在中文分詞、機器翻譯等方面的具體應用
? ??隱馬可夫模型在很多方面都有著具體的應用,如由于隱馬可夫模型HMM提供了一個可以綜合利用多種語言信息的統計框架,因此,我們完全可以講漢語自動分詞與詞性標注統一考察,建立基于HMM的分詞與詞性標注的一體化系統。
? ? 根據上文對HMM的介紹,一個HMM通常可以看做由兩部分組成:一個是狀態轉移模型,一個是狀態到觀察序列的生成模型。具體到中文分詞這一問題中,可以把漢字串或句子S作為輸入,單詞串Sw為狀態的輸出,即觀察序列,Sw=w1w2w3...wN(N>=1),詞性序列St為狀態序列,每個詞性標記ct對應HMM中的一個狀態qi,Sc=c1c2c3...cn。
? ? 那么,利用HMM處理問題問題恰好對應于解決HMM的三個基本問題:
- 估計模型的參數;
- 對于一個給定的輸入S及其可能的輸出序列Sw和模型u=(A,B,*),快速地計算P(Sw|u),所有可能的Sw中使概率P(Sw|u)最大的解就是要找的分詞效果;
- 快速地選擇最優的狀態序列或詞性序列,使其最好地解釋觀察序列。
參考文獻
- 機器學習,Tom M.Mitchhell著;
- 數據挖掘導論,[美] Pang-Ning Tan / Michael Steinbach / Vipin Kumar 著;
- 數據挖掘領域十大經典算法初探;
- 數學之美番外篇:平凡而又神奇的貝葉斯方法(本文第二部分、貝葉斯分類主要來自此文)。
- http://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html;
- 數學之美:http://www.google.com.hk/ggblog/googlechinablog/2006/04/blog-post_2507.html;
- 決策樹ID3分類算法的C++實現 & yangliuy:http://blog.csdn.net/yangliuy/article/details/7322015;
- 統計自然語言處理,宗成慶編著(本文第三部分之HMM主要參考此書);
- 推薦引擎算法學習導論;
- 支持向量機導論,[美] Nello Cristianini / John Shawe-Taylor 著;
- 一堆 Wikipedia 條目,一堆 paper ,《機器學習與人工智能資源導引》。

















![luogu P3244 [HNOI2015]落憶楓音](http://pic.xiahunao.cn/luogu P3244 [HNOI2015]落憶楓音)

