線程池的優點
1、線程是稀缺資源,使用線程池可以減少創建和銷毀線程的次數,每個工作線程都可以重復使用。
2、可以根據系統的承受能力,調整線程池中工作線程的數量,防止因為消耗過多內存導致服務器崩潰。
線程池的創建
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler) corePoolSize:線程池核心線程數量
maximumPoolSize:線程池最大線程數量
keepAliverTime:當活躍線程數大于核心線程數時,空閑的多余線程最大存活時間
unit:存活時間的單位
workQueue:存放任務的隊列
handler:超出線程范圍和隊列容量的任務的處理程序
線程池的實現原理
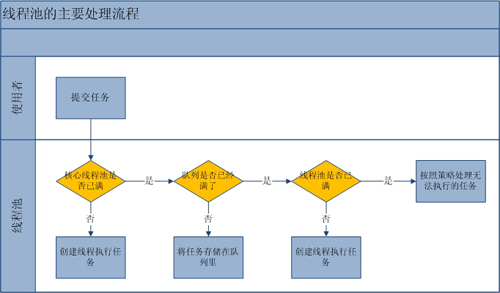
提交一個任務到線程池中,線程池的處理流程如下:
1、判斷線程池里的核心線程是否都在執行任務,如果不是(核心線程空閑或者還有核心線程沒有被創建)則創建一個新的工作線程來執行任務。如果核心線程都在執行任務,則進入下個流程。
2、線程池判斷工作隊列是否已滿,如果工作隊列沒有滿,則將新提交的任務存儲在這個工作隊列里。如果工作隊列滿了,則進入下個流程。
3、判斷線程池里的線程是否都處于工作狀態,如果沒有,則創建一個新的工作線程來執行任務。如果已經滿了,則交給飽和策略來處理這個任務。
??
線程池的源碼解讀
1、ThreadPoolExecutor的execute()方法
?
1 public void execute(Runnable command) {2 if (command == null)3 throw new NullPointerException();//如果線程數大于等于基本線程數或者線程創建失敗,將任務加入隊列4 if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {//線程池處于運行狀態并且加入隊列成功5 if (runState == RUNNING && workQueue.offer(command)) {6 if (runState != RUNNING || poolSize == 0)7 ensureQueuedTaskHandled(command);8 }//線程池不處于運行狀態或者加入隊列失敗,則創建線程(創建的是非核心線程)9 else if (!addIfUnderMaximumPoolSize(command))//創建線程失敗,則采取阻塞處理的方式
10 reject(command); // is shutdown or saturated
11 }
12 }?
2、創建線程的方法:addIfUnderCorePoolSize(command)
?
1 private boolean addIfUnderCorePoolSize(Runnable firstTask) {2 Thread t = null;3 final ReentrantLock mainLock = this.mainLock;4 mainLock.lock();5 try {6 if (poolSize < corePoolSize && runState == RUNNING)7 t = addThread(firstTask);8 } finally {9 mainLock.unlock();
10 }
11 if (t == null)
12 return false;
13 t.start();
14 return true;
15 }?
我們重點來看第7行:
?
1 private Thread addThread(Runnable firstTask) {2 Worker w = new Worker(firstTask);3 Thread t = threadFactory.newThread(w);4 if (t != null) {5 w.thread = t;6 workers.add(w);7 int nt = ++poolSize;8 if (nt > largestPoolSize)9 largestPoolSize = nt;
10 }
11 return t;
12 }?
這里將線程封裝成工作線程worker,并放入工作線程組里,worker類的方法run方法:
?
public void run() {try {Runnable task = firstTask;firstTask = null;while (task != null || (task = getTask()) != null) {runTask(task);task = null;}} finally {workerDone(this);}}?
worker在執行完任務后,還會通過getTask方法循環獲取工作隊里里的任務來執行。
我們通過一個程序來觀察線程池的工作原理:
1、創建一個線程
?
1 public class ThreadPoolTest implements Runnable2 {3 @Override4 public void run()5 {6 try7 {8 Thread.sleep(300);9 }
10 catch (InterruptedException e)
11 {
12 e.printStackTrace();
13 }
14 }
15 }?
2、線程池循環運行16個線程:
?
1 public static void main(String[] args)2 {3 LinkedBlockingQueue<Runnable> queue =4 new LinkedBlockingQueue<Runnable>(5);5 ThreadPoolExecutor threadPool = new ThreadPoolExecutor(5, 10, 60, TimeUnit.SECONDS, queue);6 for (int i = 0; i < 16 ; i++)7 {8 threadPool.execute(9 new Thread(new ThreadPoolTest(), "Thread".concat(i + "")));
10 System.out.println("線程池中活躍的線程數: " + threadPool.getPoolSize());
11 if (queue.size() > 0)
12 {
13 System.out.println("----------------隊列中阻塞的線程數" + queue.size());
14 }
15 }
16 threadPool.shutdown();
17 }?
執行結果:
?
線程池中活躍的線程數: 1
線程池中活躍的線程數: 2
線程池中活躍的線程數: 3
線程池中活躍的線程數: 4
線程池中活躍的線程數: 5
線程池中活躍的線程數: 5
----------------隊列中阻塞的線程數1
線程池中活躍的線程數: 5
----------------隊列中阻塞的線程數2
線程池中活躍的線程數: 5
----------------隊列中阻塞的線程數3
線程池中活躍的線程數: 5
----------------隊列中阻塞的線程數4
線程池中活躍的線程數: 5
----------------隊列中阻塞的線程數5
線程池中活躍的線程數: 6
----------------隊列中阻塞的線程數5
線程池中活躍的線程數: 7
----------------隊列中阻塞的線程數5
線程池中活躍的線程數: 8
----------------隊列中阻塞的線程數5
線程池中活躍的線程數: 9
----------------隊列中阻塞的線程數5
線程池中活躍的線程數: 10
----------------隊列中阻塞的線程數5
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task Thread[Thread15,5,main] rejected from java.util.concurrent.ThreadPoolExecutor@232204a1[Running, pool size = 10, active threads = 10, queued tasks = 5, completed tasks = 0]at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2047)at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:823)at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1369)at test.ThreadTest.main(ThreadTest.java:17)?
從結果可以觀察出:
1、創建的線程池具體配置為:核心線程數量為5個;全部線程數量為10個;工作隊列的長度為5。
2、我們通過queue.size()的方法來獲取工作隊列中的任務數。
3、運行原理:
??????剛開始都是在創建新的線程,達到核心線程數量5個后,新的任務進來后不再創建新的線程,而是將任務加入工作隊列,任務隊列到達上線5個后,新的任務又會創建新的普通線程,直到達到線程池最大的線程數量10個,后面的任務則根據配置的飽和策略來處理。我們這里沒有具體配置,使用的是默認的配置AbortPolicy:直接拋出異常。
當然,為了達到我需要的效果,上述線程處理的任務都是利用休眠導致線程沒有釋放!!!
RejectedExecutionHandler:飽和策略
當隊列和線程池都滿了,說明線程池處于飽和狀態,那么必須對新提交的任務采用一種特殊的策略來進行處理。這個策略默認配置是AbortPolicy,表示無法處理新的任務而拋出異常。JAVA提供了4中策略:
1、AbortPolicy:直接拋出異常
2、CallerRunsPolicy:只用調用所在的線程運行任務
3、DiscardOldestPolicy:丟棄隊列里最近的一個任務,并執行當前任務。
4、DiscardPolicy:不處理,丟棄掉。
我們現在用第四種策略來處理上面的程序:
?
?
1 public static void main(String[] args)2 {3 LinkedBlockingQueue<Runnable> queue =4 new LinkedBlockingQueue<Runnable>(3);5 RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardPolicy();6 7 ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, queue,handler);8 for (int i = 0; i < 9 ; i++)9 {
10 threadPool.execute(
11 new Thread(new ThreadPoolTest(), "Thread".concat(i + "")));
12 System.out.println("線程池中活躍的線程數: " + threadPool.getPoolSize());
13 if (queue.size() > 0)
14 {
15 System.out.println("----------------隊列中阻塞的線程數" + queue.size());
16 }
17 }
18 threadPool.shutdown();
19 }?
?
執行結果:
?
線程池中活躍的線程數: 1
線程池中活躍的線程數: 2
線程池中活躍的線程數: 2
----------------隊列中阻塞的線程數1
線程池中活躍的線程數: 2
----------------隊列中阻塞的線程數2
線程池中活躍的線程數: 2
----------------隊列中阻塞的線程數3
線程池中活躍的線程數: 3
----------------隊列中阻塞的線程數3
線程池中活躍的線程數: 4
----------------隊列中阻塞的線程數3
線程池中活躍的線程數: 5
----------------隊列中阻塞的線程數3
線程池中活躍的線程數: 5
----------------隊列中阻塞的線程數3
這里采用了丟棄策略后,就沒有再拋出異常,而是直接丟棄。在某些重要的場景下,可以采用記錄日志或者存儲到數據庫中,而不應該直接丟棄。
設置策略有兩種方式:
1、
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardPolicy();ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, queue,handler);2、
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, queue);threadPool.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());Executor框架的兩級調度模型
在HotSpot VM的模型中,JAVA線程被一對一映射為本地操作系統線程。JAVA線程啟動時會創建一個本地操作系統線程,當JAVA線程終止時,對應的操作系統線程也被銷毀回收,而操作系統會調度所有線程并將它們分配給可用的CPU。
在上層,JAVA程序會將應用分解為多個任務,然后使用應用級的調度器(Executor)將這些任務映射成固定數量的線程;在底層,操作系統內核將這些線程映射到硬件處理器上。
Executor框架類圖
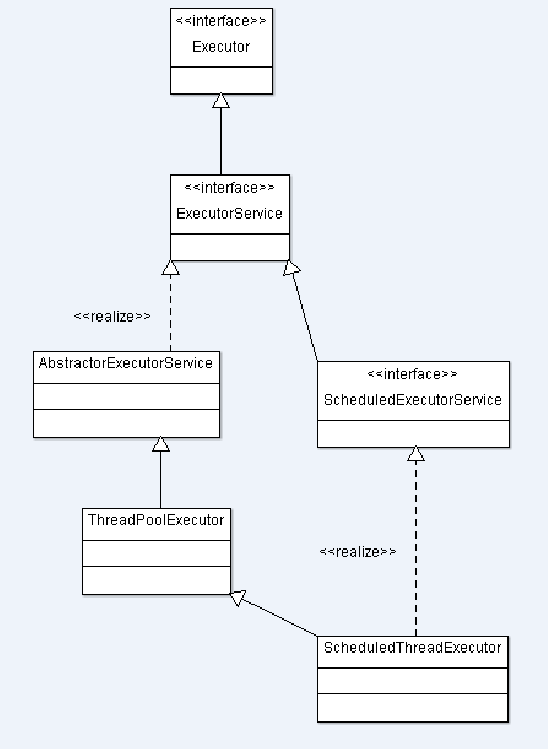
在前面介紹的JAVA線程既是工作單元,也是執行機制。而在Executor框架中,我們將工作單元與執行機制分離開來。Runnable和Callable是工作單元(也就是俗稱的任務),而執行機制由Executor來提供。這樣一來Executor是基于生產者消費者模式的,提交任務的操作相當于生成者,執行任務的線程相當于消費者。
1、從類圖上看,Executor接口是異步任務執行框架的基礎,該框架能夠支持多種不同類型的任務執行策略。
public interface Executor {void execute(Runnable command);
}Executor接口就提供了一個執行方法,任務是Runnbale類型,不支持Callable類型。
2、ExecutorService接口實現了Executor接口,主要提供了關閉線程池和submit方法:
?
public interface ExecutorService extends Executor {List<Runnable> shutdownNow();boolean isTerminated();<T> Future<T> submit(Callable<T> task);}?
另外該接口有兩個重要的實現類:ThreadPoolExecutor與ScheduledThreadPoolExecutor。
其中ThreadPoolExecutor是線程池的核心實現類,用來執行被提交的任務;而ScheduledThreadPoolExecutor是一個實現類,可以在給定的延遲后運行任務,或者定期執行命令。
在上一篇文章中,我是使用ThreadPoolExecutor來通過給定不同的參數從而創建自己所需的線程池,但是在后面的工作中不建議這種方式,推薦使用Exectuors工廠方法來創建線程池
這里先來區別線程池和線程組(ThreadGroup與ThreadPoolExecutor)這兩個概念:
a、線程組就表示一個線程的集合。
b、線程池是為線程的生命周期開銷問題和資源不足問題提供解決方案,主要是用來管理線程。
Executors可以創建3種類型的ThreadPoolExecutor:SingleThreadExecutor、FixedThreadExecutor和CachedThreadPool
a、SingleThreadExecutor:單線程線程池
ExecutorService threadPool = Executors.newSingleThreadExecutor();public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}我們從源碼來看可以知道,單線程線程池的創建也是通過ThreadPoolExecutor,里面的核心線程數和線程數都是1,并且工作隊列使用的是無界隊列。由于是單線程工作,每次只能處理一個任務,所以后面所有的任務都被阻塞在工作隊列中,只能一個個任務執行。
b、FixedThreadExecutor:固定大小線程池
ExecutorService threadPool = Executors.newFixedThreadPool(5);public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}這個與單線程類似,只是創建了固定大小的線程數量。
c、CachedThreadPool:無界線程池
ExecutorService threadPool = Executors.newCachedThreadPool();public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}無界線程池意味著沒有工作隊列,任務進來就執行,線程數量不夠就創建,與前面兩個的區別是:空閑的線程會被回收掉,空閑的時間是60s。這個適用于執行很多短期異步的小程序或者負載較輕的服務器。
Callable、Future、FutureTash詳解
Callable與Future是在JAVA的后續版本中引入進來的,Callable類似于Runnable接口,實現Callable接口的類與實現Runnable的類都是可以被線程執行的任務。
三者之間的關系:
Callable是Runnable封裝的異步運算任務。
Future用來保存Callable異步運算的結果
FutureTask封裝Future的實體類
1、Callable與Runnbale的區別
a、Callable定義的方法是call,而Runnable定義的方法是run。
b、call方法有返回值,而run方法是沒有返回值的。
c、call方法可以拋出異常,而run方法不能拋出異常。
2、Future
Future表示異步計算的結果,提供了以下方法,主要是判斷任務是否完成、中斷任務、獲取任務執行結果
?
1 public interface Future<V> {2 3 boolean cancel(boolean mayInterruptIfRunning);4 5 boolean isCancelled();6 7 boolean isDone();8 9 V get() throws InterruptedException, ExecutionException;
10
11 V get(long timeout, TimeUnit unit)
12 throws InterruptedException, ExecutionException, TimeoutException;
13 }?
3、FutureTask<V>
可取消的異步計算,此類提供了對Future的基本實現,僅在計算完成時才能獲取結果,如果計算尚未完成,則阻塞get方法。
public class FutureTask<V> implements RunnableFuture<V>public interface RunnableFuture<V> extends Runnable, Future<V>FutureTask不僅實現了Future接口,還實現了Runnable接口,所以不僅可以將FutureTask當成一個任務交給Executor來執行,還可以通過Thread來創建一個線程。
Callable與FutureTask
定義一個callable的任務:
?
1 public class MyCallableTask implements Callable<Integer>2 {3 @Override4 public Integer call()5 throws Exception6 {7 System.out.println("callable do somothing");8 Thread.sleep(5000);9 return new Random().nextInt(100);
10 }
11 }?
?
1 public class CallableTest2 {3 public static void main(String[] args) throws Exception4 {5 Callable<Integer> callable = new MyCallableTask();6 FutureTask<Integer> future = new FutureTask<Integer>(callable);7 Thread thread = new Thread(future);8 thread.start();9 Thread.sleep(100);
10 //嘗試取消對此任務的執行
11 future.cancel(true);
12 //判斷是否在任務正常完成前取消
13 System.out.println("future is cancel:" + future.isCancelled());
14 if(!future.isCancelled())
15 {
16 System.out.println("future is cancelled");
17 }
18 //判斷任務是否已完成
19 System.out.println("future is done:" + future.isDone());
20 if(!future.isDone())
21 {
22 System.out.println("future get=" + future.get());
23 }
24 else
25 {
26 //任務已完成
27 System.out.println("task is done");
28 }
29 }
30 }?
執行結果:
callable do somothing
future is cancel:true
future is done:true
task is done這個DEMO主要是通過調用FutureTask的狀態設置的方法,演示了狀態的變遷。
a、第11行,嘗試取消對任務的執行,該方法如果由于任務已完成、已取消則返回false,如果能夠取消還未完成的任務,則返回true,該DEMO中由于任務還在休眠狀態,所以可以取消成功。
future.cancel(true);b、第13行,判斷任務取消是否成功:如果在任務正常完成前將其取消,則返回true
System.out.println("future is cancel:" + future.isCancelled());c、第19行,判斷任務是否完成:如果任務完成,則返回true,以下幾種情況都屬于任務完成:正常終止、異常或者取消而完成。
??? 我們的DEMO中,任務是由于取消而導致完成。
System.out.println("future is done:" + future.isDone());d、在第22行,獲取異步線程執行的結果,我這個DEMO中沒有執行到這里,需要注意的是,future.get方法會阻塞當前線程, 直到任務執行完成返回結果為止。
System.out.println("future get=" + future.get());Callable與Future
?
public class CallableThread implements Callable<String>
{@Overridepublic String call()throws Exception{System.out.println("進入Call方法,開始休眠,休眠時間為:" + System.currentTimeMillis());Thread.sleep(10000);return "今天停電";}public static void main(String[] args) throws Exception{ExecutorService es = Executors.newSingleThreadExecutor();Callable<String> call = new CallableThread();Future<String> fu = es.submit(call);es.shutdown();Thread.sleep(5000);System.out.println("主線程休眠5秒,當前時間" + System.currentTimeMillis());String str = fu.get();System.out.println("Future已拿到數據,str=" + str + ";當前時間為:" + System.currentTimeMillis());}
}?
執行結果:
進入Call方法,開始休眠,休眠時間為:1478606602676
主線程休眠5秒,當前時間1478606608676
Future已拿到數據,str=今天停電;當前時間為:1478606612677這里的future是直接扔到線程池里面去執行的。由于要打印任務的執行結果,所以從執行結果來看,主線程雖然休眠了5s,但是從Call方法執行到拿到任務的結果,這中間的時間差正好是10s,說明get方法會阻塞當前線程直到任務完成。
通過FutureTask也可以達到同樣的效果:
?
?
public static void main(String[] args) throws Exception{ExecutorService es = Executors.newSingleThreadExecutor();Callable<String> call = new CallableThread();FutureTask<String> task = new FutureTask<String>(call);es.submit(task);es.shutdown();Thread.sleep(5000);System.out.println("主線程等待5秒,當前時間為:" + System.currentTimeMillis());String str = task.get();System.out.println("Future已拿到數據,str=" + str + ";當前時間為:" + System.currentTimeMillis());}?
以上的組合可以給我們帶來這樣的一些變化:
如有一種場景中,方法A返回一個數據需要10s,A方法后面的代碼運行需要20s,但是這20s的執行過程中,只有后面10s依賴于方法A執行的結果。如果與以往一樣采用同步的方式,勢必會有10s的時間被浪費,如果采用前面兩種組合,則效率會提高:
1、先把A方法的內容放到Callable實現類的call()方法中
2、在主線程中通過線程池執行A任務
3、執行后面方法中10秒不依賴方法A運行結果的代碼
4、獲取方法A的運行結果,執行后面方法中10秒依賴方法A運行結果的代碼
這樣代碼執行效率一下子就提高了,程序不必卡在A方法處。
筆記 : 2.創建并配置package)
















![[十二省聯考2019]皮配](http://pic.xiahunao.cn/[十二省聯考2019]皮配)

